【实时数仓】Day05-ClickHouse:入门、安装、数据类型、表引擎、SQL操作、副本、分片集群
一、ClickHouse入门
1、介绍
是一个开源的列式存储数据库(DBMS)
使用C++编写
用于在线分析查询(OLAP)
能够使用SQL查询实时生成分析数据报告
2、特点
(1)列式存储
比较:
行式存储适用于查询某条记录的信息
列式存储适用于查询所有人的信息
好处:
聚合、计数、求和等统计操作优
同列数据类型易选择更优的压缩算法,提高了压缩比重
节省存储空间并利于缓存
(2)DBMS的功能
标准SQL大部分语法,DDM、DML、函数、用户管理、权限管理、数据备份与恢复
(3)引擎多样化
根据需求可以选择不同的引擎,例如合并树、日志、接口和其他四大类共二十多种引擎。
(4)高吞吐写入能力
采用类似LSM Tree的结构,数据写入后语在后台压缩
导入时数据append写,压缩时也是顺序写回磁盘
顺序写充分利用了磁盘吞吐能力
能够达到相当于 50W-200W 条/s 的写入速度
(5)数据分区与线程级并行
划分为多个partition,partition又被分为多个index索引粒度,多个核心各处理一部分实现并行处理
单条查询就能充分利用所有CPU
但不适合多条查询,不适用于高qps的查询业务
二、ClickHouse的安装
1、准备工作
关闭防火墙
取消打开文件数限制
同步操作
安装依赖
取消SELINUX(伪文件系统,是一个权限白名单原则)
2、单机安装
创建目录
同步安装文件
安装所有的rpm文件:sudo rpm -ivh *.rpm | sudo rpm -qa|grep clickhouse
修改配置文件中的listen_host,让其他服务器访问,并分发配置文件
启动server:systemctl start clickhouse-server
关闭开机自启:systemctl disable clickhouse-server
client连接: clickhouse-client -m
三、数据类型
1、整型
Int8、16、32、64
UInt8、16、32、64
场景:个数、数量、id
2、浮点型
Float32、64
计算时会引起四舍五入误差
场景:数据值小、不涉及统计运算、精度要求不高
3、布尔型
无专门类型,可以使用UInt8,取值为0/1
4、Decimal类型
可以保持精度的有符号浮点数
Decimal32(s)、64、128
s表示小数位数
场景:金额、利率等需要保证小数点精度的场景
5、字符串
String:任意长度字符串
FixString(N):固定长度字符串,小于n会在末尾添加空字节,较少使用
场景:名称、文字描述
6、枚举类型
Enum8 和 Enum16
Enum8使用'String' = Int8对描述
例如创建一个枚举Enum8('hello' = 1, 'world' = 2) 类型的列
CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog;
只能存储hello或world
插入元素:INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello');
转换整形查询:SELECT CAST(x, 'Int8') FROM t_enum;
场景:对于状态字段是一种空间优化+数据约束
会存在维护成本或数据丢失的问题
7、时间类型
Date:年月日
Datetime:年月日时分秒
Datetime64:年月日时分秒亚秒,如20:50:10.66
8、数组Array(T)
不推荐多维数组
创建方式1-使用 array 函数:SELECT array(1, 2) AS x, toTypeName(x) ;
创建方式2-使用方括号:SELECT [1, 2] AS x, toTypeName(x);
四、表引擎
1、表引擎的概念
创建表时显式声明,名称区分大小写
决定如何存储表的数据,包括
存储方式和位置、在哪写,在哪读
如何支持哪些查询
并发数据访问
索引的使用
是否支持多线程
数据复制参数
2、TinyLog
以列文件的形式保存到磁盘,无索引,没有并发控制
保存少量数据的小表
如create table t_tinylog ( id String, name String) engine=TinyLog;
3、Memory
以未压缩的形式保存到内存中,服务重启数据就会消失
读写操作不会相互阻塞【不需要进行同步互斥】,不支持索引,但简单查询性能高>10G/s
适用于高性能要求且对数据量要求不大(最多一亿行数据)的场景
4、MergeTree-合并树引擎
*MergeTree是ClickHouse最强大的引擎
支持索引和分区
其中最重要的三个参数包括
engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
(1)partition by--分区,不填则只使用一个分区
分区(降低扫描范围,优化查询范围)
列文件+索引文件+表定义文件会保存到不同的分区中
分区后,涉及分区的查询,会以分区为单位进行并行处理
数据写入与数据合并:先写入临时分区,某个时刻后,自动执行合并操作,合并到已有分区中。
也可以使用optimize手动执行:hadoop102 :) optimize table t_order_mt final;
(2)primary key 主键
ClickHouse中的主键,只提供了数据的一级索引,但这并不是唯一约束
主键的目的是查询语句中的where条件
通过主键进行二分查找,能够对应到index granularity-索引粒度,避免了全表扫描
索引粒度,指的是稀疏索引这种两个相邻索引对应数据的间隔,MergeTree 默认是 8192
好处是可以利用很少的索引数据,定位更多的数据,代价是只能定位到第一行,在对应的块内顺序扫描。
【分块查找中的索引表和顺序表】
(3)order by(必选)
设定按哪些字段讲数据进行有序保存
不设计主键时,按照order by的字段进行处理
要求:主键必须是 order by 字段的前缀字段
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)
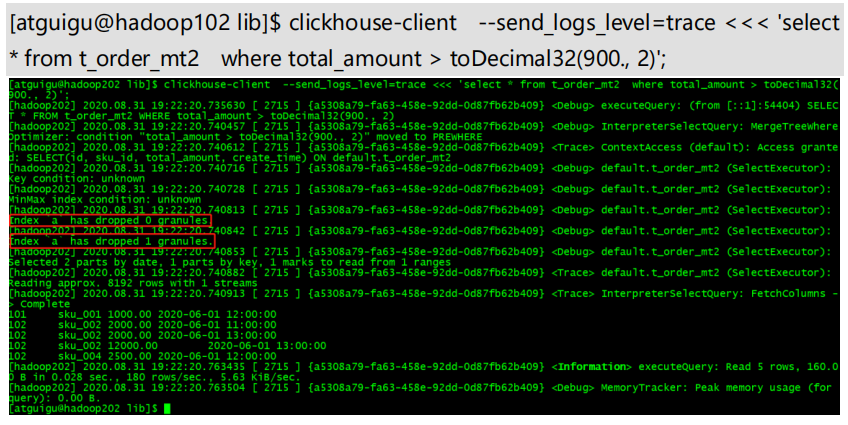
(4)二级索引
使用二级索引需要增加设置(是否使用实验性的二级索引):set allow_experimental_data_skipping_indices=1;
例如:
total_amount Decimal(16,2),
INDEX a total_amount TYPE minmax GRANULARITY 5
GRANULARITY N 是设定二级索引对于一级索引粒度的粒度
为非主键字段的查询发挥作用
(5)数据TTL-数据生命周期,存活时间
TTL 即 Time To Live,可以管理数据或者列生命周期的功能
【a】列级别 TTL
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND
手动合并,查看效果 到期后,指定的字段数据归 0
【b】表级别TTL
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND; -- 是数据会在 create_time 之后 10 秒丢失
判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间周期包括:SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR
5、ReplacingMergeTree
存储特性完全继承 MergeTree,但添加了一个去重的功能
MergeTree的主键是没有唯一约束的功能
而ReplacingMergeTree可以处理掉重复的数据
去重时机:后台合并时去重,无法预判时间
去重范围:只能执行分区内部的去重,不能执行跨分区的去重;适用于在后台清理重复数据,但无法保证没有重复数据出现
案例演示:建表engine = ReplacingMergeTree(create_time)-重复数据保留版本字段大的,插入后执行手动合并OPTIMIZE TABLE t_order_rmt FINAL;
结论:只有合并才能去重、去重不能跨分区
6、SummingMergeTree
不查询明细,只关心以维度进行汇总聚合的场景
原因:查询时,临时聚合的开销比较大,SummingMergeTree是一种可以预聚合的引擎
案例: engine =SummingMergeTree(total_amount)-以指定的列作为汇总数据列,order by的列作为维度列
其他列顺序保留第一行,不在一个分区的数据不会被聚合
建议:去掉唯一主键、流水号,所有字段都是维度列
查询:select * from 表名,而不是查询指定的列
五、SQL操作
基本支持sql语句,只介绍不一致的地方
1、Insert
2、Update 和 Delete
可以看做Mutation 查询,是Alter的一种
与OLTP数据库不同,Mutation是一种很重的操作,并且不支持事务
重的原因:修改删除会放弃原有分区,重建新分区,所以尽量做批量变更,而不是频繁小数据的操作
语法:alter table t_order_smt delete/update
执行:分两步,先对新增数据新建分区,把旧分区打上失效标记;触发分区合并时,删除旧数据,释放磁盘空间
3、查询操作
支持子查询、CTE(Common Table Expression 公用表表达式 with 子句)、join
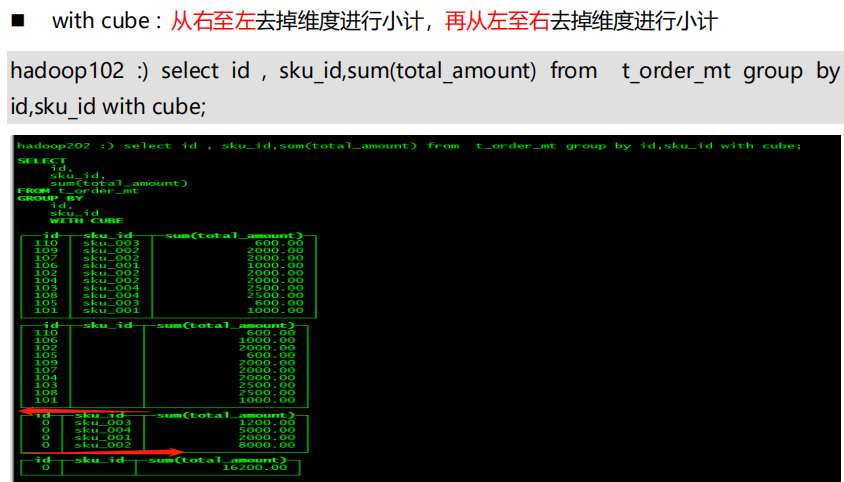
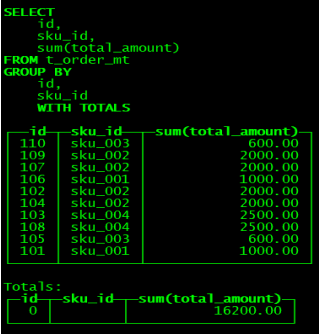
GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计
with rollup:从右至左去掉维度进行小计
with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计
4、alter操作
新增字段:alter table tableName add column newcolname String after col1;
修改字段类型:alter table tableName modify column newcolname String;
删除字段:alter table tableName drop column newcolname;
5、导出数据
clickhouse-client --query "select * from t_order_mt where create_time='2020-06-01 12:00:00'" --format CSVWithNames> /opt/module/data/rs1.csv1
六、副本
保障数据高可用性
1、写入流程

2、配置步骤
启动集群
102的/etc/clickhouse-server/config.d目录下创建xml配置文件
同步到其他节点
config.xml中增加<include_from>,包含创建的配置文件
同步、启动、分别建表(副本只能同步数据,不能同步表结构)
engine =ReplicatedMergeTree('/clickhouse0225/table/01/t_order_rep','rep_102')
七、分片集群
副本无法解决横向扩容的问题
解决数据水平切分需要使用分片,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来
1、集群写入流程

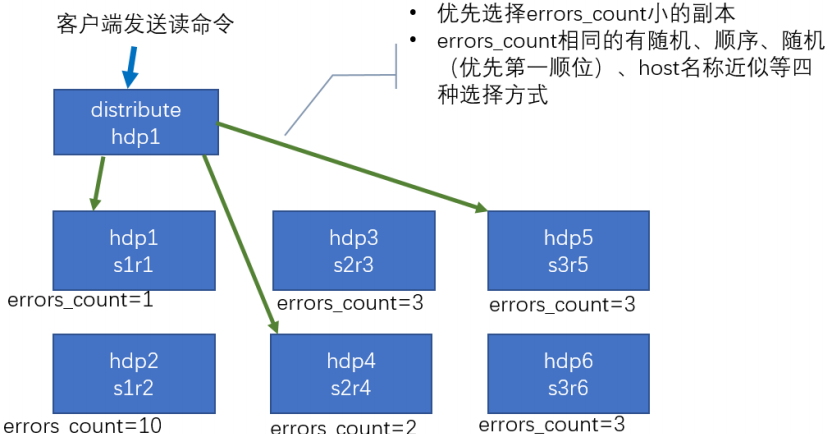
2、集群读取流程
3、配置参考
4、配置三节点版本集群及副本(2 个分片,只有第一个分片有副本)

【实时数仓】Day05-ClickHouse:入门、安装、数据类型、表引擎、SQL操作、副本、分片集群的更多相关文章
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- Clickhouse实时数仓建设
1.概述 Clickhouse是一个开源的列式存储数据库,其主要场景用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告.今天,笔者就为大家介绍如何使用Clickhouse来构建实 ...
- 【实时数仓】Day01-数据采集层:数仓分层、实时需求、架构分析、日志数据采集(采集到指定topic和落盘)、业务数据采集(MySQL-kafka)、Nginx反向代理、Maxwell、Canel
一.数仓分层介绍 1.实时计算与实时数仓 实时计算实时性高,但无中间结果,导致复用性差 实时数仓基于数据仓库,对数据处理规划.分层,目的是提高数据的复用性 2.电商数仓的分层 ODS:原始日志数据和业 ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 更强大的实时数仓构建能力!分析型数据库PostgreSQL 6.0新特性解读
阿里云 AnalyticDB for PostgreSQL 为采用MPP架构的分布式集群数据库,完备支持SQL 2003,部分兼容Oracle语法,支持PL/SQL存储过程,触发器,支持标准数据库事务 ...
- 大数据之Hudi + Kylin的准实时数仓实现
问题导读:1.数据库.数据仓库如何理解?2.数据湖有什么用途?解决什么问题?3.数据仓库的加载链路如何实现?4.Hudi新一代数据湖项目有什么优势? 在近期的 Apache Kylin × Apach ...
- 实时数仓(二):DWD层-数据处理
目录 实时数仓(二):DWD层-数据处理 1.数据源 2.用户行为日志 2.1开发环境搭建 1)包结构 2)pom.xml 3)MykafkaUtil.java 4)log4j.properties ...
随机推荐
- 搭建Elasitc stack集群需要注意的日志问题
文章转载自:https://blog.csdn.net/u013613428/article/details/84943577 {{uploading-image-736853.png(uploadi ...
- PAT (Basic Level) Practice 1032 挖掘机技术哪家强 分数 20
为了用事实说明挖掘机技术到底哪家强,PAT 组织了一场挖掘机技能大赛.现请你根据比赛结果统计出技术最强的那个学校. 输入格式: 输入在第 1 行给出不超过 105 的正整数 N,即参赛人数.随后 N ...
- 关于AWS-EC2或者多个资源的tag的批量添加-基于Resource Groups & Tag Editor 和 命令处理
今天收到一个请求,需要对公司所有的ec2-添加上两个成本IO标签,因为机器太多了 想到了如下两种方案去批量处理 方案一:利用aws的 [Management Tools]下的 Resource Gro ...
- P3919 【模板】可持久化线段树 1(可持久化数组)
还是用主席树来做(因为提到不同的版本),这时候的主席树不是以权值为下标的,就是普通的线段树,维护范围1~n,i存的是a[ ]中的数. 1 #include <bits/stdc++.h> ...
- 不允许还有Java程序员不了解BlockingQueue阻塞队列的实现原理
我们平时开发中好像很少使用到BlockingQueue(阻塞队列),比如我们想要存储一组数据的时候会使用ArrayList,想要存储键值对数据会使用HashMap,在什么场景下需要用到Blocking ...
- 记录一次成功反混淆脱壳及抓包激活app全过程
记录一次成功反混淆脱壳及抓包激活app全过程 前言 近期接到一个需求,要对公司之前开发的一款app进行脱壳.因为该app是两年前开发的,源代码文件已经丢失,只有加壳后的apk文件,近期要查看其中一 ...
- 使用python获取window注册表值的方法
提供regfullpath的方法,可以自行封装个regpath的函数import loggingimport pywintypes import win32apiimport win32con def ...
- Jquery中Trigger()方法
1. $(selector).trigger(event,[param1,param2,...]) 方法触发被选元素标签的指定事件类型 为元素边赋值为true,并触发元素标签的change方法 $(' ...
- 如何kill一条TCP连接?
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处. 简介 如果你的程序写得有毛病,打开了很多TCP连接,但一直没有关闭,即常见的连接泄露场景,你可能想要在排查问题的过程中, ...
- rocky8删除/etc/fstab 和/boot/所有文件,通过光盘救援模式恢复
rocky8删除/etc/fstab 和/boot/所有文件,通过光盘救援模式恢复 mkdir /rootdir 先通过df和lsblk确定那个分区是根,如果确定不了,就先挂载一个分区,查看里边的文件 ...