[OpenCV实战]50 用OpenCV制作低成本立体相机
本文主要讲述利用OpenCV制作低成本立体相机以及如何使用OpenCV创建3D视频,准确来说是模仿双目立体相机,我们通常说立体相机一般是指双目立体相机,就是带两个摄像头的那种(目就是指眼睛,双目就是两只眼睛),这种双目摄像机模仿人的视觉,所以应用很广泛(主要是工业机器人视觉)。双目摄像机也广泛应用于无人驾驶,比如特斯拉、图森未来,小鹏汽车在自家的无人驾驶汽车上都安载了立体相机,双目和多目的都有。另外双目视觉加上深度学习还蛮好水论文的。本文主要说的是低成本,实际上没人这样干,有专门的双目立体相机,已经非常成熟了,但是原理大差不差。专门的工业级双目立体相机价格大概5000多左右,家用的或者用来玩的最低1000能买到,有些双目立体摄像机还自带深度学习算法,所以本文看看就好。
文章目录
本文主要参考
Making A Low-Cost Stereo Camera Using OpenCV和
双目视觉之空间坐标计算。
本文所有代码见:
- github: OpenCV-Practical-Exercise
- gitee(备份,主要是下载速度快): OpenCV-Practical-Exercise-gitee
1 相关介绍
1.1 背景
我们通常都使用下图所示的红青色3D眼镜来体验3D效果。它是如何工作的?当屏幕只是平面时,我们如何体验3D效果?这些是使用立体摄像机设置捕获的。

在[OpenCV实战]49 对极几何与立体视觉初探文章中,我们了解了立体相机以及如何将其用于帮助计算机感知深度。在本文中,我们学习如何创建自己的立体相机,并了解如何将其用于创建3D视频。具体来说包括立体相机的创建,立体相机的校准以及自定义3D视频,主要是讲立体相机的校准。
1.2 创建双目立体相机
立体摄像头设置通常包含两个相同的摄像头,它们以固定的距离隔开。工业级标准立体摄像机设置使用一对相同的摄像机。说白了这里你需要一个自己的立体相机(双目立体相机),你可以买,也可以自己创造一个。但是保持两个摄像机严格固定和平行。关于立体相机型号可以看看3D Camera Survey。关于立体相机的原理见 深度相机原理揭秘–双目立体视觉。
如果是自己弄台双目立体相机,也不是不行。反正很多人也这样干。你可以看用文章DIY 3D立体相机的帖子整理用摄像头来自己搭建双目立体相机。或者也可以通过两部手机搭建双目立体相机,详情见低成本DIY拍摄3D照片的相机和如何用两台傻瓜相机制作自己的3D相机。反正最终弄出来的结果如下图所示:

如果是高精度双目视觉应用的话,stereolabs家的zed系列相机,毕竟工业级双目相机的搭建技术含量很高,不是随便就能弄好的,国内在这一块相对比较薄弱。下图就是zed系列某部立体相机的真容,4000多一点,百度的图片。

当你有了立体相机,你需要进行立体标定(stereo calibration)以搭建自己的视觉系统,为什么要这要做后面会说到。本文只是简单的讲一讲相关原理,会提供图像,自己也不需要有双目相机,看看就好。至于更详细的双目视觉系统搭建可以看看文章一起搭建双目视觉系统。
2 相机立体标定与校正
2.1 立体标定重要性
为了理解立体标定的重要性,我们提供了没有立体标定的图像,如下图所示,然后生成视差图。

生成的视差图如下图所示:

我们观察到,使用未校准的立体相机设置生成的视差图非常嘈杂且不准确。为什么会这样?根据[OpenCV实战]49 对极几何与立体视觉初探里提到的,相应的关键点应具有相等的Y坐标,以简化点对应搜索。如下图所示,当我们在几个对应点之间绘制匹配线时,我们观察到这些线不是完全水平的。

下图显示了相应的关键点具有相等的Y坐标的立体图像,以及使用这些图像生成的视差图。我们观察到,与前一张相比,现在的视差图噪声更低。

仅当摄像机平行时才可能出现上图这种情况。但是实际过程中,两部摄像机不可能完全平行,或者我们想要达到基本平行需要耗费大量的时间来调整摄像机。所以我们可以用另外一种方式,无需物理调整摄像机,而是在软件方面体标定并校正摄像机。下图说明了立体标定与校准的过程。如下图所示,这个想法是在平行于穿过光学中心的线的公共平面上重新投影两个图像。这样可以确保相应的点具有相同的Y坐标,并且仅通过水平平移进行关联。具体原理见双目立体标定。这些东西不是一句两句就能说清楚,只要有这个东西就好了。
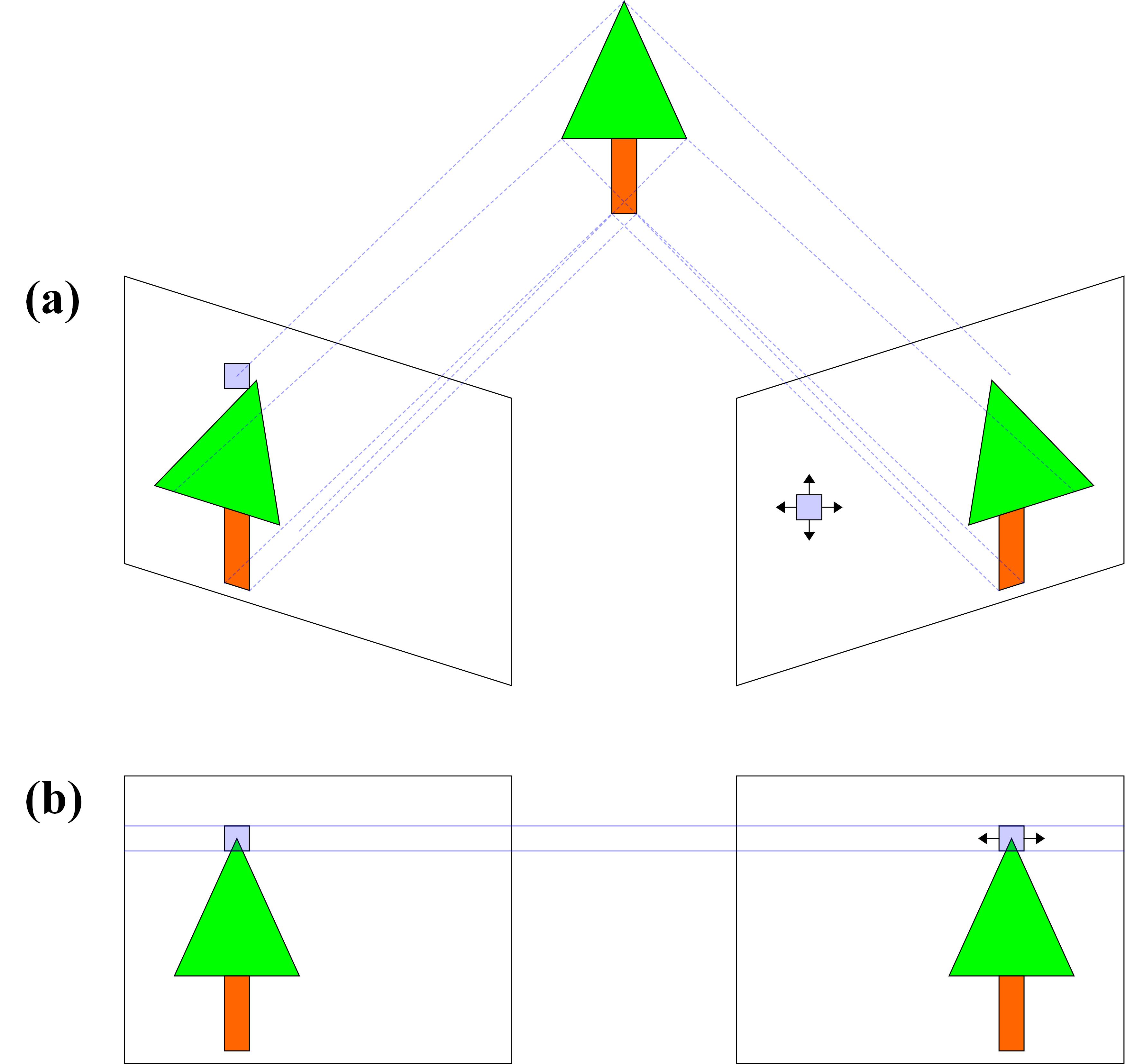
2.2 相机立体标定和校正的步骤
整个过程如下所示:
- 使用标准OpenCV校正方法校准单个相机 。
- 确定两个摄像机之间的转换关系。
- 使用前面步骤中获得的参数和OpenCV的stereoCalibrate方法,应用于两个图像的变换以进行立体校正。
- 使用OpenCV的initUndistortRectifyMap方法找到未失真和已校正图像对所需的映射。
- 将此映射应用于原始图像,以校正未失真图像。
这一些步骤就是相机标定中的张正友标定法,数学原理详解相机标定之张正友标定法数学原理详解。这里面会涉及到一系列的OpenCV函数,详细使用见双目视觉之空间坐标计算。总体相机立体标定过程由图表示如下所示:
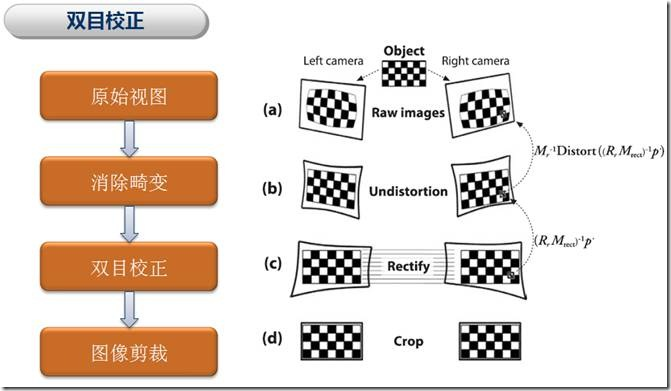
以下几节具体步骤可以跳过不看,直接看代码calibrate.cpp/calibrate.py!
2.2.1 单个相机校正
在执行立体标定之前,我们会对两个相机分别进行标定。但是,如果OpenCV的stereoCalibrate()方法可以对两个相机中的每一个进行校正,为什么还要分别标定相机呢?
这是因为由于要计算的参数很多(较大的参数空间),并且在诸如角点检测和近似点之类的步骤中累积了错误。这增加了迭代方法偏离正确解决方案的机会。因此,我们分别计算摄像机参数,并仅使用stereoCalibrate()方法来查找立体相机之间的对应关系。
代码如下,主要讲的是提取角点,然后去除畸形点,最后分别对每个相机进行校正。
所谓角点检测如下图所示,左图是原图,右图是角点检测的可视化结果,我们所需要提取就是角点,然后进行相机校正。

C++
// Creating vector to store vectors of 3D points for each checkerboard image
// 创建vector以存储每个棋盘图像的3D点矢量
std::vector<std::vector<cv::Point3f> > objpoints;
// Creating vector to store vectors of 2D points for each checkerboard image
// 创建vector以存储每个棋盘图像的2D点矢量
std::vector<std::vector<cv::Point2f> > imgpointsL, imgpointsR;
// Defining the world coordinates for 3D points
// 定义三维点的世界坐标
std::vector<cv::Point3f> objp;
// 初始化点,cv::Point3f(j, i, 0)保存的是x,y,z坐标。
for (int i{ 0 }; i < CHECKERBOARD[1]; i++)
{
for (int j{ 0 }; j < CHECKERBOARD[0]; j++)
{
objp.push_back(cv::Point3f(j, i, 0));
}
}
// Extracting path of individual image stored in a given directory
// 提取存储在给定目录中的单个图像的路径
std::vector<cv::String> imagesL, imagesR;
// Path of the folder containing checkerboard images
// 包含棋盘图像的文件夹的路径
// pathL和pathR分别为两个摄像头在多个时刻拍摄的图像
std::string pathL = "./data/stereoL/*.png";
std::string pathR = "./data/stereoR/*.png";
// 提取两个文件夹 所有的图像
cv::glob(pathL, imagesL);
cv::glob(pathR, imagesR);
cv::Mat frameL, frameR, grayL, grayR;
// vector to store the pixel coordinates of detected checker board corners
// 用于存储检测到的棋盘角点的像素坐标的向量
std::vector<cv::Point2f> corner_ptsL, corner_ptsR;
bool successL, successR;
// Looping over all the images in the directory
// 遍历目录中的所有图像
for (int i{ 0 }; i < imagesL.size(); i++)
{
// 提取同一时刻分别用两个摄像头拍到的照片
frameL = cv::imread(imagesL[i]);
cv::cvtColor(frameL, grayL, cv::COLOR_BGR2GRAY);
frameR = cv::imread(imagesR[i]);
cv::cvtColor(frameR, grayR, cv::COLOR_BGR2GRAY);
// Finding checker board corners
// 寻找棋盘图的内角点位置
// If desired number of corners are found in the image then success = true
// 如果在图像中找到所需的角数,则success=true
// 具体函数使用介绍见https://blog.csdn.net/h532600610/article/details/51800488
successL = cv::findChessboardCorners(
grayL,
cv::Size(CHECKERBOARD[0], CHECKERBOARD[1]),
corner_ptsL);
// cv::CALIB_CB_ADAPTIVE_THRESH | cv::CALIB_CB_FAST_CHECK | cv::CALIB_CB_NORMALIZE_IMAGE);
successR = cv::findChessboardCorners(
grayR,
cv::Size(CHECKERBOARD[0], CHECKERBOARD[1]),
corner_ptsR);
// cv::CALIB_CB_ADAPTIVE_THRESH | cv::CALIB_CB_FAST_CHECK | cv::CALIB_CB_NORMALIZE_IMAGE);
// 如果检测到所需的角点个数,则细化像素坐标并将其显示在棋盘格图像上
if ((successL) && (successR))
{
// TermCriteria定义迭代算法终止条件的类
// 具体使用见 https://www.jianshu.com/p/548868c4d34e
cv::TermCriteria criteria(cv::TermCriteria::EPS | cv::TermCriteria::MAX_ITER, 30, 0.001);
// refining pixel coordinates for given 2d points.
// 细化给定2D点的像素坐标,cornerSubPix用于亚像素角点检测
// 具体参数见https://blog.csdn.net/guduruyu/article/details/69537083
cv::cornerSubPix(grayL, corner_ptsL, cv::Size(11, 11), cv::Size(-1, -1), criteria);
cv::cornerSubPix(grayR, corner_ptsR, cv::Size(11, 11), cv::Size(-1, -1), criteria);
// Displaying the detected corner points on the checker board
// drawChessboardCorners用于绘制棋盘格角点的函数
cv::drawChessboardCorners(frameL, cv::Size(CHECKERBOARD[0], CHECKERBOARD[1]), corner_ptsL, successL);
cv::drawChessboardCorners(frameR, cv::Size(CHECKERBOARD[0], CHECKERBOARD[1]), corner_ptsR, successR);
// 保存数据以供后续使用
// 保存三维点数据
objpoints.push_back(objp);
// 保存角点信息
imgpointsL.push_back(corner_ptsL);
imgpointsR.push_back(corner_ptsR);
}
//cv::imshow("ImageL", frameL);
//cv::imshow("ImageR", frameR);
//cv::waitKey(0);
}
// 关闭所有窗口
cv::destroyAllWindows();
// 通过传递已知三维点(objpoints)的值和检测到的角点(imgpoints)的相应像素坐标来执行相机校准
// mtxL,mtxR为内参数矩阵, distL和distR为畸变矩阵
// R_L和R_R为旋转向量,T_L和T_R为位移向量
cv::Mat mtxL, distL, R_L, T_L;
cv::Mat mtxR, distR, R_R, T_R;
cv::Mat new_mtxL, new_mtxR;
// Calibrating left camera
// 校正左边相机
// 相机标定函数
// 函数使用见https://blog.csdn.net/u011574296/article/details/73823569
cv::calibrateCamera(objpoints,
imgpointsL,
grayL.size(),
mtxL,
distL,
R_L,
T_L);
// 去畸变,优化相机内参,这一步可选
// getOptimalNewCameraMatrix函数使用见https://www.jianshu.com/p/df78749b4318
new_mtxL = cv::getOptimalNewCameraMatrix(mtxL,
distL,
grayL.size(),
1,
grayL.size(),
0);
// Calibrating right camera
// 校正右边相机
cv::calibrateCamera(objpoints,
imgpointsR,
grayR.size(),
mtxR,
distR,
R_R,
T_R);
new_mtxR = cv::getOptimalNewCameraMatrix(mtxR,
distR,
grayR.size(),
1,
grayR.size(),
0);
Python
# Set the path to the images captured by the left and right cameras
pathL = "./data/stereoL/"
pathR = "./data/stereoR/"
print("Extracting image coordinates of respective 3D pattern ....\n")
# Termination criteria for refining the detected corners
# 细化检测角点的终止准则
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
objp = np.zeros((9 * 6, 3), np.float32)
objp[:, :2] = np.mgrid[0:9, 0:6].T.reshape(-1, 2)
img_ptsL = []
img_ptsR = []
obj_pts = []
# 处理每一张图
for i in tqdm(range(1, 28)):
imgL = cv2.imread(pathL + "img%d.png" % i)
imgR = cv2.imread(pathR + "img%d.png" % i)
imgL_gray = cv2.imread(pathL + "img%d.png" % i, 0)
imgR_gray = cv2.imread(pathR + "img%d.png" % i, 0)
outputL = imgL.copy()
outputR = imgR.copy()
retR, cornersR = cv2.findChessboardCorners(outputR, (9, 6), None)
retL, cornersL = cv2.findChessboardCorners(outputL, (9, 6), None)
if retR and retL:
obj_pts.append(objp)
cv2.cornerSubPix(imgR_gray, cornersR, (11, 11), (-1, -1), criteria)
cv2.cornerSubPix(imgL_gray, cornersL, (11, 11), (-1, -1), criteria)
cv2.drawChessboardCorners(outputR, (9, 6), cornersR, retR)
cv2.drawChessboardCorners(outputL, (9, 6), cornersL, retL)
# cv2.imshow('cornersR',outputR)
# cv2.imshow('cornersL',outputL)
# cv2.waitKey(0)
img_ptsL.append(cornersL)
img_ptsR.append(cornersR)
print("Calculating left camera parameters ... ")
# Calibrating left camera
# 校正左边相机
retL, mtxL, distL, rvecsL, tvecsL = cv2.calibrateCamera(obj_pts, img_ptsL, imgL_gray.shape[::-1], None, None)
hL, wL = imgL_gray.shape[:2]
new_mtxL, roiL = cv2.getOptimalNewCameraMatrix(mtxL, distL, (wL, hL), 1, (wL, hL))
print("Calculating right camera parameters ... ")
# Calibrating right camera
# 校正右边相机
retR, mtxR, distR, rvecsR, tvecsR = cv2.calibrateCamera(obj_pts, img_ptsR, imgR_gray.shape[::-1], None, None)
hR, wR = imgR_gray.shape[:2]
new_mtxR, roiR = cv2.getOptimalNewCameraMatrix(mtxR, distR, (wR, hR), 1, (wR, hR))
2.2.2 使用固定的固有参数执行立体标定
校准摄像机后,我们将它们传递给stereoCalibrate方法,我们还传递两个相机捕获的3D点和相应的2D像素坐标,用于计算相机间的转换关系。这样实现了立体标定,代码如下:
C++
// Here we fix the intrinsic camara matrixes so that only Rot, Trns, Emat and Fmat
// are calculated. Hence intrinsic parameters are the same.
// 在这里,我们修正了固有的camara矩阵,以便只计算Rot、Trns、Emat和Fmat。因此内在参数是相同的。
cv::Mat Rot, Trns, Emat, Fmat;
int flag = 0;
flag |= cv::CALIB_FIX_INTRINSIC;
// This step is performed to transformation between the two cameras and calculate Essential and Fundamenatl matrix
// 同时标定两个摄像头,函数介绍见https://www.cnblogs.com/zyly/p/9373991.html
cv::stereoCalibrate(objpoints,
imgpointsL,
imgpointsR,
new_mtxL,
distL,
new_mtxR,
distR,
grayR.size(),
Rot,
Trns,
Emat,
Fmat,
flag,
cv::TermCriteria(cv::TermCriteria::MAX_ITER + cv::TermCriteria::EPS, 30, 1e-6));
Python
print("Stereo calibration .....")
flags = 0
flags |= cv2.CALIB_FIX_INTRINSIC
# Here we fix the intrinsic camara matrixes so that only Rot, Trns, Emat and Fmat are calculated.
# Hence intrinsic parameters are the same
criteria_stereo = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 立体标定
# This step is performed to transformation between the two cameras and calculate Essential and Fundamenatl matrix
retS, new_mtxL, distL, new_mtxR, distR, Rot, Trns, Emat, Fmat = cv2.stereoCalibrate(obj_pts,
img_ptsL,
img_ptsR,
new_mtxL,
distL,
new_mtxR,
distR,
imgL_gray.shape[::-1],
criteria_stereo,
flags)
2.2.3 立体校正
使用相机间的内外参数,和转换关系参数,就能够进行立体校正。立体校正运用旋转使两个相机图像面都在同一平面上,stereoRectify方法还能返回新坐标空间中的投影矩阵。关于投影矩阵这是个相机几何学的基础概念,具体见Projection Matrices。代码如下:
C++
cv::Mat rect_l, rect_r, proj_mat_l, proj_mat_r, Q;
// Once we know the transformation between the two cameras we can perform stereo rectification
// 一旦我们知道两个摄像机之间的变换,我们就可以进行立体校正
// stereoRectify同时校正两个摄像机,函数介绍见https://www.cnblogs.com/zyly/p/9373991.html
cv::stereoRectify(new_mtxL,
distL,
new_mtxR,
distR,
grayR.size(),
Rot,
Trns,
rect_l,
rect_r,
proj_mat_l,
proj_mat_r,
Q,
1);
Python
# 立体校正
# Once we know the transformation between the two cameras we can perform stereo rectification
# StereoRectify function
rectify_scale = 1 # if 0 image croped, if 1 image not croped
rect_l, rect_r, proj_mat_l, proj_mat_r, Q, roiL, roiR = cv2.stereoRectify(new_mtxL, distL, new_mtxR, distR,
imgL_gray.shape[::-1], Rot, Trns,
rectify_scale, (0, 0))
2.2.4 获得未失真的校正立体图像对所需的映射
由于我们假设摄像机是固定的,因此无需再次计算变换。因此,我们计算将立体图像对转换为未失真的校正立体图像对的映射,并将其存储以备将来使用。
C++
// Use the rotation matrixes for stereo rectification and camera intrinsics for undistorting the image
// Compute the rectification map (mapping between the original image pixels and
// their transformed values after applying rectification and undistortion) for left and right camera frames
// 根据相机单目标定得到的内参以及stereoRectify计算出来的值来计算畸变矫正和立体校正的映射变换矩阵
cv::Mat Left_Stereo_Map1, Left_Stereo_Map2;
cv::Mat Right_Stereo_Map1, Right_Stereo_Map2;
// 函数介绍见https://www.cnblogs.com/zyly/p/9373991.html
cv::initUndistortRectifyMap(new_mtxL,
distL,
rect_l,
proj_mat_l,
grayR.size(),
CV_16SC2,
Left_Stereo_Map1,
Left_Stereo_Map2);
cv::initUndistortRectifyMap(new_mtxR,
distR,
rect_r,
proj_mat_r,
grayR.size(),
CV_16SC2,
Right_Stereo_Map1,
Right_Stereo_Map2);
// 保存校正信息
cv::FileStorage cv_file = cv::FileStorage("data/params_cpp.xml", cv::FileStorage::WRITE);
cv_file.write("Left_Stereo_Map_x", Left_Stereo_Map1);
cv_file.write("Left_Stereo_Map_y", Left_Stereo_Map2);
cv_file.write("Right_Stereo_Map_x", Right_Stereo_Map1);
cv_file.write("Right_Stereo_Map_y", Right_Stereo_Map2);
cv_file.release();
Python
# Use the rotation matrixes for stereo rectification and camera intrinsics for undistorting the image
# Compute the rectification map (mapping between the original image pixels and
# their transformed values after applying rectification and undistortion) for left and right camera frames
Left_Stereo_Map = cv2.initUndistortRectifyMap(new_mtxL, distL, rect_l, proj_mat_l,
imgL_gray.shape[::-1], cv2.CV_16SC2)
Right_Stereo_Map = cv2.initUndistortRectifyMap(new_mtxR, distR, rect_r, proj_mat_r,
imgR_gray.shape[::-1], cv2.CV_16SC2)
print("Saving paraeters ......")
cv_file = cv2.FileStorage("data/params_py.xml", cv2.FILE_STORAGE_WRITE)
cv_file.write("Left_Stereo_Map_x", Left_Stereo_Map[0])
cv_file.write("Left_Stereo_Map_y", Left_Stereo_Map[1])
cv_file.write("Right_Stereo_Map_x", Right_Stereo_Map[0])
cv_file.write("Right_Stereo_Map_y", Right_Stereo_Map[1])
cv_file.release()
3 自定义3D视频
3.1 3D眼镜如何工作?
校准完我们的DIY立体相机后,我们就可以创建3D视频了。但是,在我们了解如何制作3D视频之前,必须了解3D眼镜的工作原理。我们使用双目视觉系统感知世界。我们的眼睛处于横向不同的位置。因此,它们捕获的信息不同。那么我们的左眼和右眼捕获的信息之间有什么区别?
例如将你的手机放在你的面前正中处,闭上左眼只用右眼观察手机和闭上右眼只用左眼观察手机,你会发现手机的相对水平位置是不同的。这种位置差异称为水平视差。现在,将手机靠近您并重复相同的实验。您现在观察到了哪些变化?与对象相对应的水平视差增加。因此,物体的视差越高,它越近。这是我们如何使用我们的双眼视觉系统来感知深度的原因。
我们可以通过使用称为体视学stereoscopy的方法,分别向每只眼睛人工呈现两个不同的图像来模拟这种视。最初,对于3D电影,人们是通过使用红色和青色的滤镜对每只眼睛的图像进行编码来实现的。他们使用了红青色3D眼镜,以确保两个图像均到达预期的眼睛。这创造了深度的幻觉。用这种方法产生的立体效果称为立体3D。因此,这些图像被称为立体影片,并且眼镜被称为立体3D眼镜。
3.2 创建自定义3D视频
我们了解了当使用立体3D眼镜观看时,立体图像对如何转换为立体3D图像以产生深度的幻觉。我们可以使用立体相机设置来捕获多张相机图像,并为每个相机图像对创建一个立体图像。然后,我们将所有连续的立体图像保存为视频,这就是我们制作3D视频的方式!
要注意所使用的两个摄像头必须经过章节2的摄像头校正,本章节所生产的视频必须使用3D眼镜~~~
代码如下:
C++
#include <opencv2/opencv.hpp>
#include <opencv2/calib3d/calib3d.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <stdio.h>
#include <iostream>
int main()
{
// Check for left and right camera IDs
// 左右视频id
std::string CamL_id{ "data/stereoL.mp4" }, CamR_id{ "data/stereoR.mp4" };
// 打开视频
cv::VideoCapture camL(CamL_id), camR(CamR_id);
cv::Mat Left_Stereo_Map1, Left_Stereo_Map2;
cv::Mat Right_Stereo_Map1, Right_Stereo_Map2;
// 打开校正文件
cv::FileStorage cv_file = cv::FileStorage("data/params_cpp.xml", cv::FileStorage::READ);
cv_file["Left_Stereo_Map_x"] >> Left_Stereo_Map1;
cv_file["Left_Stereo_Map_y"] >> Left_Stereo_Map2;
cv_file["Right_Stereo_Map_x"] >> Right_Stereo_Map1;
cv_file["Right_Stereo_Map_y"] >> Right_Stereo_Map2;
cv_file.release();
// 检测视频是否存在
// Check if left camera is attched
if (!camL.isOpened())
{
std::cout << "Could not open camera with index : " << CamL_id << std::endl;
return -1;
}
// Check if right camera is attached
if (!camL.isOpened())
{
std::cout << "Could not open camera with index : " << CamL_id << std::endl;
return -1;
}
cv::Mat frameL, frameR;
for (size_t i{ 0 }; i < 100000; i++)
{
camL >> frameL;
camR >> frameR;
cv::Mat Left_nice, Right_nice;
// 简单重映射图像
// 函数使用见https://blog.csdn.net/qq_42887760/article/details/86513649
cv::remap(frameL,
Left_nice,
Left_Stereo_Map1,
Left_Stereo_Map2,
cv::INTER_LANCZOS4,
cv::BORDER_CONSTANT,
0);
cv::remap(frameR,
Right_nice,
Right_Stereo_Map1,
Right_Stereo_Map2,
cv::INTER_LANCZOS4,
cv::BORDER_CONSTANT,
0);
cv::Mat Left_nice_split[3], Right_nice_split[3];
std::vector<cv::Mat> Anaglyph_channels;
// 分离通道
cv::split(Left_nice, Left_nice_split);
cv::split(Right_nice, Right_nice_split);
Anaglyph_channels.push_back(Left_nice_split[0]);
Anaglyph_channels.push_back(Left_nice_split[1]);
Anaglyph_channels.push_back(Right_nice_split[2]);
cv::Mat Anaglyph_img;
// 组合为3D图像
cv::merge(Anaglyph_channels, Anaglyph_img);
cv::imshow("Anaglyph image", Anaglyph_img);
cv::waitKey(1);
}
return 0;
}
Python
import numpy as np
import cv2
CamL_id = "data/stereoL.mp4"
CamR_id = "data/stereoR.mp4"
CamL = cv2.VideoCapture(CamL_id)
CamR = cv2.VideoCapture(CamR_id)
print("Reading parameters ......")
cv_file = cv2.FileStorage("data/params_py.xml", cv2.FILE_STORAGE_READ)
Left_Stereo_Map_x = cv_file.getNode("Left_Stereo_Map_x").mat()
Left_Stereo_Map_y = cv_file.getNode("Left_Stereo_Map_y").mat()
Right_Stereo_Map_x = cv_file.getNode("Right_Stereo_Map_x").mat()
Right_Stereo_Map_y = cv_file.getNode("Right_Stereo_Map_y").mat()
cv_file.release()
while True:
retR, imgR = CamR.read()
retL, imgL = CamL.read()
if retL and retR:
imgR_gray = cv2.cvtColor(imgR, cv2.COLOR_BGR2GRAY)
imgL_gray = cv2.cvtColor(imgL, cv2.COLOR_BGR2GRAY)
Left_nice = cv2.remap(imgL, Left_Stereo_Map_x, Left_Stereo_Map_y, cv2.INTER_LANCZOS4, cv2.BORDER_CONSTANT, 0)
Right_nice = cv2.remap(imgR, Right_Stereo_Map_x, Right_Stereo_Map_y, cv2.INTER_LANCZOS4, cv2.BORDER_CONSTANT, 0)
output = Right_nice.copy()
output[:, :, 0] = Right_nice[:, :, 0]
output[:, :, 1] = Right_nice[:, :, 1]
output[:, :, 2] = Left_nice[:, :, 2]
# output = Left_nice+Right_nice
output = cv2.resize(output, (700, 700))
cv2.namedWindow("3D movie", cv2.WINDOW_NORMAL)
cv2.resizeWindow("3D movie", 700, 700)
cv2.imshow("3D movie", output)
cv2.waitKey(1)
else:
break
4 参考
- Making A Low-Cost Stereo Camera Using OpenCV
- [OpenCV实战]49 对极几何与立体视觉初探
- 3D Camera Survey
- 深度相机原理揭秘–双目立体视觉
- DIY 3D立体相机的帖子整理
- 低成本DIY拍摄3D照片的相机
- 如何用两台傻瓜相机制作自己的3D相机
- zed系列相机
- 一起搭建双目视觉系统
- 双目立体标定
- 双目视觉之空间坐标计算
- 相机标定之张正友标定法数学原理详解
- Projection Matrices
[OpenCV实战]50 用OpenCV制作低成本立体相机的更多相关文章
- [OpenCV实战]48 基于OpenCV实现图像质量评价
本文主要介绍基于OpenCV contrib中的quality模块实现图像质量评价.图像质量评估Image Quality Analysis简称IQA,主要通过数学度量方法来评价图像质量的好坏. 本文 ...
- [OpenCV实战]47 基于OpenCV实现视觉显著性检测
人类具有一种视觉注意机制,即当面对一个场景时,会选择性地忽略不感兴趣的区域,聚焦于感兴趣的区域.这些感兴趣的区域称为显著性区域.视觉显著性检测(Visual Saliency Detection,VS ...
- [OpenCV实战]44 使用OpenCV进行图像超分放大
图像超分辨率(Image Super Resolution)是指从低分辨率图像或图像序列得到高分辨率图像.图像超分辨率是计算机视觉领域中一个非常重要的研究问题,广泛应用于医学图像分析.生物识别.视频监 ...
- [OpenCV实战]45 基于OpenCV实现图像哈希算法
目前有许多算法来衡量两幅图像的相似性,本文主要介绍在工程领域最常用的图像相似性算法评价算法:图像哈希算法(img hash).图像哈希算法通过获取图像的哈希值并比较两幅图像的哈希值的汉明距离来衡量两幅 ...
- [OpenCV实战]46 在OpenCV下应用图像强度变换实现图像对比度均衡
本文主要介绍基于图像强度变换算法来实现图像对比度均衡.通过图像对比度均衡能够抑制图像中的无效信息,使图像转换为更符合计算机或人处理分析的形式,以提高图像的视觉价值和使用价值.本文主要通过OpenCV ...
- [OpenCV实战]20 使用OpenCV实现基于增强相关系数最大化的图像对齐
目录 1 背景 1.1 彩色摄影的一个简短而不完整的历史 1.2 OpenCV中的运动模型 2 使用增强相关系数最大化(ECC)的图像对齐 2.1 findTransformECC在OpenCV中的示 ...
- [OpenCV实战]16 使用OpenCV实现多目标跟踪
目录 1 背景介绍 2 基于MultiTracker的多目标跟踪 2.1 创建单个对象跟踪器 2.2 读取视频的第一帧 2.3 在第一帧中确定我们跟踪的对象 2.4 初始化MultiTrackerer ...
- [OpenCV实战]25 使用OpenCV进行泊松克隆
目录 1 Seamless Cloning实现 1.1 Seamless Cloning实例 1.2 正常克隆(NORMAL_CLONE)与混合克隆(MIXED_CLONE) 1.2.1 Normal ...
- [OpenCV实战]28 基于OpenCV的GUI库cvui
目录 1 cvui的使用 1.1 如何在您的应用程序中添加cvui 1.2 基本的"hello world"应用程序 2 更高级的应用 3 代码 4 参考 有很多很棒的GUI库,例 ...
随机推荐
- jsp页面重定向后地址栏controller名重复而导致报404错误
今天做ssm项目时遇到了这种错误 看看代码: 无关代码省略... 22 <body> 23 <div id="container"> 24 <ifra ...
- SpringBoot(七) - Redis 缓存
1.五大基本数据类型和操作 1.1 字符串-string 命令 说明 set key value 如果key还没有,那就可以添加,如果key已经存在了,那会覆盖原有key的值 get key 如果ke ...
- HTML+CSS基础知识(4)简单的广告界面
文章目录 1.网页实例 1.1 代码 1.2 测试效果 1.网页实例 1.1 代码 css样式 /* 清除页面样式 */ *{ margin:0; padding: 0; } /* 统一页面的样式 * ...
- 2流高手速成记(之四):SpringBoot整合redis及mongodb
最近很忙,好不容易才抽出了时间,咱们接上回 上次我们主要讲了如何通过SpringBoot快速集成mybatis/mybatis-plus,以实现业务交互中的数据持久化,而这一切都是基于关系型数据库(S ...
- 斑马打印机二维码标签制作(.prn文件)基础简单快速上手
在工厂生产中,经常需要一线员工在电脑上输入订单号的情况.订单号往往很长,手输容易出错,并且浪费时间,所以常常使用扫码枪扫描二维码的方式输入订单号,本篇就是记录斑马打印机.prn标签模板的制作和使用. ...
- nrf52——DFU升级USB/UART升级方式详解(基于SDK开发例程)
摘要:在前面的nrf52--DFU升级OTA升级方式详解(基于SDK开发例程)一文中我测试了基于蓝牙的OTA,本文将开始基于UART和USB(USB_CDC_)进行升级测试. 整体升级流程: 整个过程 ...
- 【lwip】08-ARP协议一图笔记及源码实现
目录 前言 8.1 IP地址与MAC地址 8.2 ARP协议简介 8.3 ARP协议报文 8.4 ARP缓存表 8.4.1 ARP缓存表简介 8.4.2 LWIP中的缓存表 8.4.3 ARP缓存表数 ...
- LabVIEW+OpenVINO在CPU上部署新冠肺炎检测模型实战
前言 之前博客:[YOLOv5]LabVIEW+OpenVINO让你的YOLOv5在CPU上飞起来给大家介绍了在LabVIEW上使用openvino加速推理,在CPU上也能感受丝滑的实时物体识别.那我 ...
- Sqlite 安装操作使用
一.什么是 SQLite 数据库 SQLite 是嵌入式SQL数据库引擎.与大多数其他 SQL 数据库不同,SQLite 没有单独的服务器进程.SQLite 直接读取和写入普通磁盘文件.具有多个表,索 ...
- 阿里云 ACK 接入观测云
简介 容器服务 Kubernetes 版(简称 ACK)提供高性能可伸缩的容器应用管理能力,支持企业级容器化应用的全生命周期管理.2021 年成为国内唯一连续三年入选 Gartner 公共云容器报告的 ...