使用LabVIEW实现基于pytorch的DeepLabv3图像语义分割
前言
今天我们一起来看一下如何使用LabVIEW实现语义分割。
一、什么是语义分割
图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,例如让计算机在输入下面左图的情况下,能够输出右图。语义在语音识别中指的是语音的意思,在图像领域,语义指的是图像的内容,对图片意思的理解,比如下图的语义就是一个人牵着四只羊;分割的意思是从像素的角度分割出图片中的不同对象,对原图中的每个像素都进行标注,比如下图中浅黄色代表人,蓝绿色代表羊。语义分割任务就是将图片中的不同类别,用不同的颜色标记出来,每一个类别使用一种颜色。常用于医学图像,卫星图像,无人车驾驶,机器人等领域。

如何做到将像素点上色呢?
语义分割的输出和图像分类网络类似,图像分类类别数是一个一维的one hot 矩阵。例如:三分类的[0,1,0]。语义分割任务最后的输出特征图是一个三维结构,大小与原图类似,其中通道数是类别数,每个通道所标记的像素点,是该类别在图像中的位置,最后通过argmax 取每个通道有用像素 合成一张图像,用不同颜色表示其类别位置。 语义分割任务其实也是分类任务中的一种,他不过是对每一个像素点进行细分,找到每一个像素点所述的类别。 这就是语义分割任务啦~
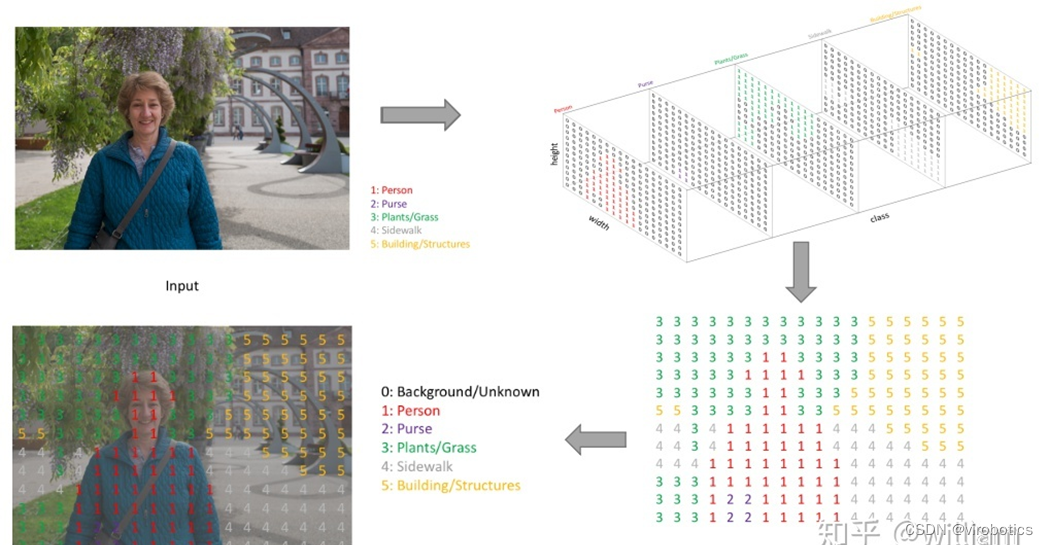
二、什么是deeplabv3
DeepLabv3是一种语义分割架构,它在DeepLabv2的基础上进行了一些修改。为了处理在多个尺度上分割对象的问题,设计了在级联或并行中采用多孔卷积的模块,通过采用多个多孔速率来捕获多尺度上下文。此外,来自 DeepLabv2 的 Atrous Spatial Pyramid Pooling模块增加了编码全局上下文的图像级特征,并进一步提高了性能。
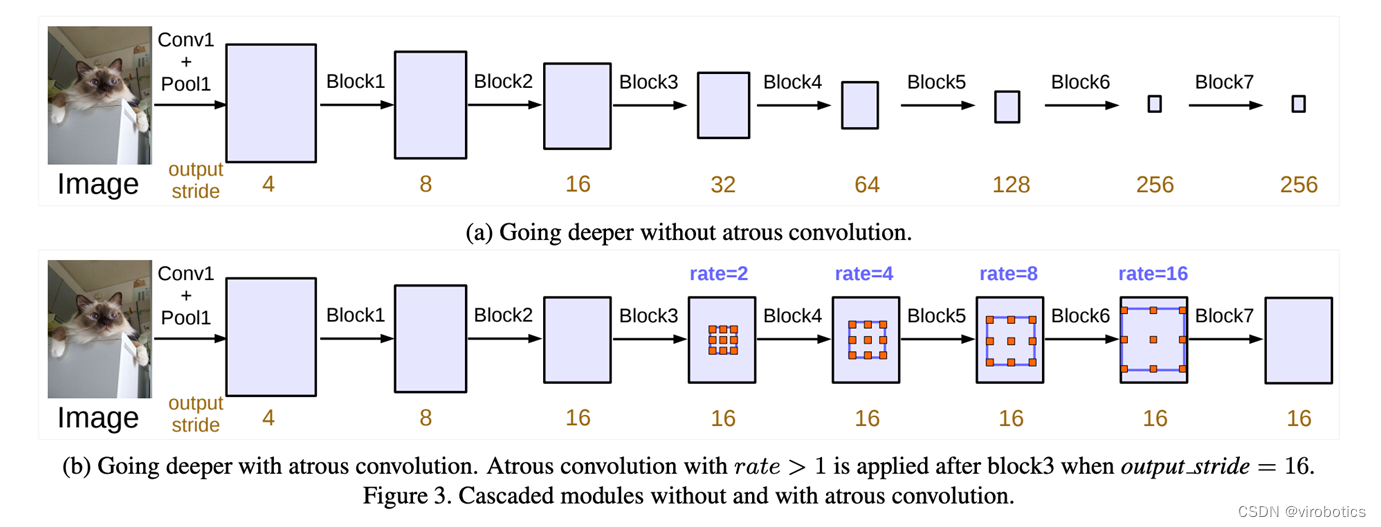
三、LabVIEW调用DeepLabv3实现图像语义分割
1、模型获取及转换
安装pytorch和torchvision
获取torchvision中的模型:deeplabv3_resnet101(我们获取预训练好的模型):
original_model = models.segmentation.deeplabv3_resnet101(pretrained=True)
转onnx


1 def get_pytorch_onnx_model(original_model):
2 # define the directory for further converted model save
3 onnx_model_path = dirname
4 # define the name of further converted model
5 onnx_model_name = "deeplabv3_resnet101.onnx"
6
7 # create directory for further converted model
8 os.makedirs(onnx_model_path, exist_ok=True)
9
10 # get full path to the converted model
11 full_model_path = os.path.join(onnx_model_path, onnx_model_name)
12
13 # generate model input
14 generated_input = Variable(
15 torch.randn(1, 3, 448, 448)
16 )
17
18 # model export into ONNX format
19 torch.onnx.export(
20 original_model,
21 generated_input,
22 full_model_path,
23 verbose=True,
24 input_names=["input"],
25 output_names=["output",'aux'],
26 opset_version=11
27 )
28
29 return full_model_path
完整获取及模型转换python代码如下:
1 import os
2 import torch
3 import torch.onnx
4 from torch.autograd import Variable
5 from torchvision import models
6 import re
7
8 dirname, filename = os.path.split(os.path.abspath(__file__))
9 print(dirname)
10
11 def get_pytorch_onnx_model(original_model):
12 # define the directory for further converted model save
13 onnx_model_path = dirname
14 # define the name of further converted model
15 onnx_model_name = "deeplabv3_resnet101.onnx"
16
17 # create directory for further converted model
18 os.makedirs(onnx_model_path, exist_ok=True)
19
20 # get full path to the converted model
21 full_model_path = os.path.join(onnx_model_path, onnx_model_name)
22
23 # generate model input
24 generated_input = Variable(
25 torch.randn(1, 3, 448, 448)
26 )
27
28 # model export into ONNX format
29 torch.onnx.export(
30 original_model,
31 generated_input,
32 full_model_path,
33 verbose=True,
34 input_names=["input"],
35 output_names=["output",'aux'],
36 opset_version=11
37 )
38
39 return full_model_path
40
41
42 def main():
43 # initialize PyTorch ResNet-101 model
44 original_model = models.segmentation.deeplabv3_resnet101(pretrained=True)
45
46 # get the path to the converted into ONNX PyTorch model
47 full_model_path = get_pytorch_onnx_model(original_model)
48 print("PyTorch ResNet-101 model was successfully converted: ", full_model_path)
49
50
51 if __name__ == "__main__":
52 main()
我们会发现,基于pytorch的DeepLabv3模型获取和之前的mask rcnn模型大同小异。
2、关于deeplabv3_resnet101
我们使用的模型是:deeplabv3_resnet101,该模型返回两个张量,与输入张量相同,但有21个classes。输出[“out”]包含语义掩码,而输出[“aux”]包含每像素的辅助损失值。在推理模式中,输出[‘aux]没有用处。因此,输出“out”形状为(N、21、H、W)。我们在转模型的时候设置H,W为448,N一般为1;
我们的模型是基于VOC2012数据集 VOC2012数据集分为20类,包括背景为21类,分别如下:
人 :人
动物:鸟、猫、牛、狗、马、羊
车辆:飞机、自行车、船、巴士、汽车、摩托车、火车
室内:瓶、椅子、餐桌、盆栽植物、沙发、电视/监视器

3、LabVIEW opencv dnn调用 deeplabv3 实现图像语义分割(deeplabv3_opencv.vi)
deeplabv3模型可以使用OpenCV dnn去加载的,也可以使用onnxruntime加载推理,所以我们分两种方式给大家介绍LabVIEW调用deeplabv3实现图像语义分割。
opencv dnn 调用onnx模型并选择

图像预处理 最终还是采用了比较中规中矩的处理方式

执行推理

后处理并实现实例分割 因为后处理内容较多,所以直接封装为了一个子VI, deeplabv3_postprocess.vi,因为Labview没有专门的切片函数,所以会稍慢一些,所以接下来还会开发针对后处理和矩阵有关的函数,加快处理结果。
整体的程序框架如下:

语义分割结果如下:

4、LabVIEW onnxruntime调用 deeplabv3实现图像语义分割 (deeplabv3_onnx.vi)
整体的程序框架如下:

语义分割结果如下:

5、LabVIEW onnxruntime调用 deeplabv3 使用TensorRT加速模型实现图像语义分割(deeplabv3_onnx_camera.vi)

如上图所示,可以看到可以把人和背景完全分割开来,使用TensorRT加速推理,速度也比较快。
四、deeplabv3训练自己的数据集
训练可参考:https://github.com/pytorch/vision
总结
以上就是今天要给大家分享的内容。大家可关注微信公众号: VIRobotics,回复关键字:DeepLabv3图像语义分割源码 获取本次分享内容的完整项目源码及模型。
如果有问题可以在评论区里讨论,提问前请先点赞支持一下博主哦,如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群:705637299。
如果文章对你有帮助,欢迎关注、点赞、收藏
使用LabVIEW实现基于pytorch的DeepLabv3图像语义分割的更多相关文章
- 笔记:基于DCNN的图像语义分割综述
写在前面:一篇魏云超博士的综述论文,完整题目为<基于DCNN的图像语义分割综述>,在这里选择性摘抄和理解,以加深自己印象,同时达到对近年来图像语义分割历史学习和了解的目的,博古才能通今!感 ...
- 使用Keras基于RCNN类模型的卫星/遥感地图图像语义分割
遥感数据集 1. UC Merced Land-Use Data Set 图像像素大小为256*256,总包含21类场景图像,每一类有100张,共2100张. http://weegee.vision ...
- 【Keras】基于SegNet和U-Net的遥感图像语义分割
上两个月参加了个比赛,做的是对遥感高清图像做语义分割,美其名曰"天空之眼".这两周数据挖掘课期末project我们组选的课题也是遥感图像的语义分割,所以刚好又把前段时间做的成果重新 ...
- 笔记︱图像语义分割(FCN、CRF、MRF)、论文延伸(Pixel Objectness、)
图像语义分割的意思就是机器自动分割并识别出图像中的内容,我的理解是抠图- 之前在Faster R-CNN中借用了RPN(region proposal network)选择候选框,但是仅仅是候选框,那 ...
- 基于FCN的图像语义分割
语义图像分割的目标在于标记图片中每一个像素,并将每一个像素与其表示的类别对应起来.因为会预测图像中的每一个像素,所以一般将这样的任务称为密集预测.(相对地,实例分割模型是另一种不同的模型,该模型可以区 ...
- 图像语义分割出的json文件和原图,用plt绘制图像mask
1.弱监督 由于公司最近准备开个新项目,用深度学习训练个能够自动标注的模型,但模型要求的训练集比较麻烦,,要先用ffmpeg从视频中截取一段视频,在用opencv抽帧得到图片,所以本人只能先用语义分割 ...
- CRF图像语义分割
看了Ladicky的文章Associative Hierarchical CRFs for Object Class Image Segmentation,下载他主页的代码,文章是清楚了,但代码的RE ...
- 推荐一些用CRF做图像语义分割的资源
原文地址:http://blog.sina.com.cn/s/blog_5309cefc01014nri.html 首先是code,以前找了很多,但发现比较好用的有: 1. Matlab版的UGM:h ...
- 基于 PyTorch 和神经网络给 GirlFriend 制作漫画风头像
摘要:本文中我们介绍的 AnimeGAN 就是 GitHub 上一款爆火的二次元漫画风格迁移工具,可以实现快速的动画风格迁移. 本文分享自华为云社区<AnimeGANv2 照片动漫化:如何基于 ...
随机推荐
- 2022-08-15 - 初识MySQL
MySQL数据库 数据库 数据库,又称为Database,简称DB.数据库就是一个文件集合. 顾名思义:是一个存储数据的仓库,实际上就是一堆文件,这些文件中存储了具有特定格式的数据,可以很方便的对里面 ...
- iOS去广告最简单方案!+以图搜漫
iOS去广告 ️推荐 | 通过下载.安装.启用(一般默认启用)描述文件,即可实现通过私人dns来达到全系统的广告拦截.隐私保护功能 ️注意: 限 iOS 14 及以上版本系统使用 复制链接需在 saf ...
- MySQL索引知识点&面试常见问题
来源:BiggerBoy 作者:北哥 原文链接:https://mp.weixin.qq.com/s/fucHvdRK5wRrDfBOo6IBGw 大家好我是北哥,今天整理了MySQL索引相关的知识点 ...
- 自定义View3-水波纹扩散(仿支付宝咻一咻)实现代码、思想
PS:自定义view篇-水波纹实现 效果:水波纹扩散 场景:雷达.按钮点击效果.搜索等 实现:先上效果图,之前记得支付宝有一个咻一咻,当时就是水波纹效果,实现起来一共两步,第一画内圆,第二画多个外圆, ...
- 在hyper-v虚拟机中安装并配置linux
虽然都是自己写的,还是贴个原文链接吧,如果文章里的图片错乱了,可能就是我贴错了,去看原文吧. 多图警告 WSL2真香? WSL2相比于WSL1前者更类似于虚拟机,配合上Windoes Terminal ...
- Python入门系列(十)一篇学会python文件处理
文件处理 在Python中处理文件的关键函数是open()函数.有四种不同的方法(模式)来打开一个文件 "r" - 读取 - 默认值.打开一个文件进行读取,如果文件不存在则出错. ...
- KingbaseES 数据库软件卸载
关键字: KingbaseES.卸载 一.安装后检查 在安装完成后,可以通过以下几种方式进行安装正确性验证: 1. 查看安装日志,确认没有错误记录; 2. 查看开始菜单: 查看应用程序菜单中是否安 ...
- KingbaseES sys_prewarm 扩展
Oracle 在查询数据 可以通过cache hint 所访问的数据cache 到数据库buffer,对于KingbaseES,如何将数据加载到cache 了?sys_prewarm 扩展插件可以实现 ...
- 学习ASP.NET Core Blazor编程系列二——第一个Blazor应用程序(下)
学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应用程序(上) 学习ASP.NET Core Blazor编程系 ...
- C语言001--hello world编译详解
1.编写hello.c程序,并编译运行 book@100ask:~/linux/c01$ cat hello.c -n 1 #include <stdio.h> 2 3 int main( ...