如何使用ModelBox快速提升AI应用性能?
摘要:在开发初期开发者往往聚焦在模型的精度上,性能关注较少,但随着业务量不断增加,AI应用的性能往往成为瓶颈,此时对于没有性能优化经验的开发者来说往往需要耗费大量精力做优化性能,本文为开发者介绍一些常用的优化方法和经验。
本文分享自华为云社区《如何使用ModelBox快速提升AI应用性能》,作者: panda。
随着AI技术和计算能力的发展,越来越多的开发者学会用tensorflow、pytorch等引擎训练模型并开发成AI应用以解决各种生产问题。在开发初期开发者往往聚焦在模型的精度上,性能关注较少,但随着业务量不断增加,AI应用的性能往往成为瓶颈,此时对于没有性能优化经验的开发者来说往往需要耗费大量精力做优化性能,本文为开发者介绍一些常用的优化方法和经验。本文首先介绍什么是AI应用性能优化,以及常用的性能优化手段,然后介绍华为云ModelBox开源框架,最后结合实际业务为例,详细讲解如何利用ModelBox框架进行快速的性能优化以及背后的原理。
一、AI应用常用性能优化方法
1、什么是AI应用性能优化
什么是AI应用性能优化? AI应用性能优化是保证结果正确的情况下,提升AI推理应用执行效率。AI应用性能优化的目的一般分为两方面:一方面可以提升用户体验,如门禁系统刷脸场景,对推理时延比较敏感,识别速度直接影响用户感官,再比如自动驾驶场景,对时延要求非常高;另一方面可以降低硬件成本,相同的硬件设备可以支撑更多的业务,当部署节点数具备一定规模时,节省的硬件成本就相当可观了。
如何去衡量性能的好坏?我们通常使用吞吐量和时延来衡量。 吞吐量在不同场景也有不同衡量指标,比如图片请求场景,一般使用qps作为吞吐量的指标,即每秒种处理的请求个数。在视频流场景,则一般使用视频并发路数来衡量。 时延是指数据输入到结果输出中间的处理时间差。正常来讲吞吐量越大越好,时延越小越好,在不同场景对吞吐量和时延的要求不一样, 对于某些时延不敏感的场景,我们可以牺牲时延来提升吞吐量。所以我们在做性能优化前需要先明确优化指标是吞吐量还是时延。
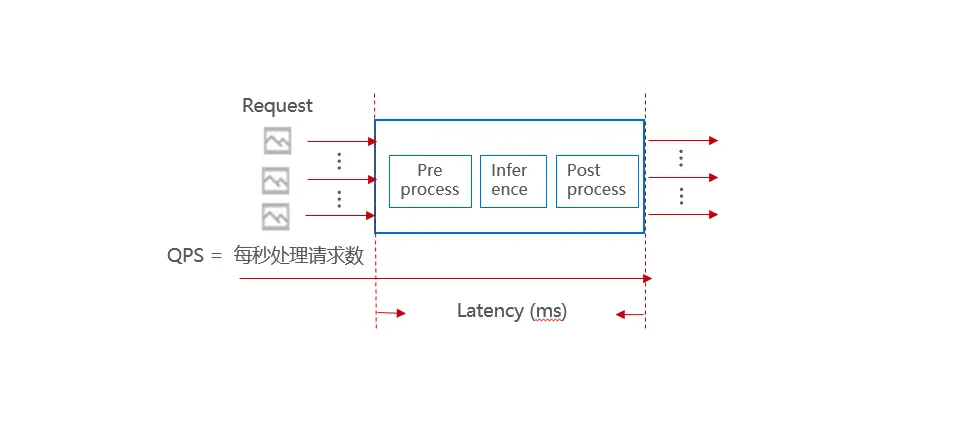
另外除此之外,在性能优化过程中,还需要重点关注一些系统资源指标,如内存、显存、CPU占用率、GPU占用率等。这些指标可以帮忙我们辅助判断当前资源使用情况,为我们做性能优化提供思路,如GPU利用率较低时,就需要针对性想办法充分利用GPU资源。
2、AI应用性能优化方法
一个AI应用可以分为模型和工程逻辑,AI应用的优化我们也可以从上到下进行划分,其中应用流程优化和应用工程优化为工程方面的优化,模型编译优化和模型算法优化则为模型优化。
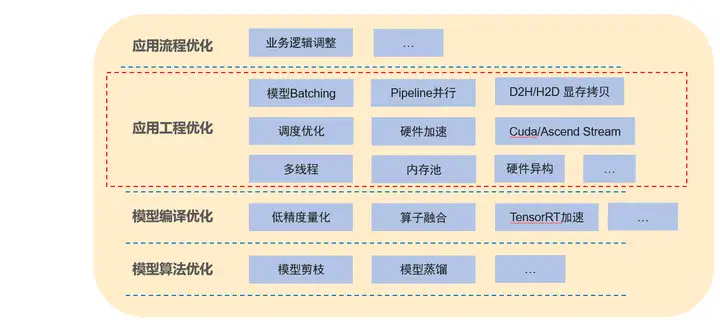
应用流程优化:主要是对业务逻辑进行调整,减少一些不必要的操作以到达性能提升的效果,业务逻辑的优化有时是最快捷最有效的,往往会有事半功倍的效果。但需要具体场景具体分析。
应用工程优化:主要是软件工程方面的优化,如多线程、内存池、硬件加速等等, 对上层 ,此外模型batching也是最常见的优化手段,通过共享队列组batch以充分利用模型的batching性能。方法较通用。ModelBox框架提供的主要为应用工程优化能力。
模型编译优化:常用手段有低精度量化、混合精度等、算子融合等,此类优化会影响模型精度。
模型算法优化:对模型结构进行优化,减少模型计算量,如模型剪枝、模型蒸馏等,需要重新训练。
本文重点介绍AI应用工程优化的常用手段,常用优化手段如下:
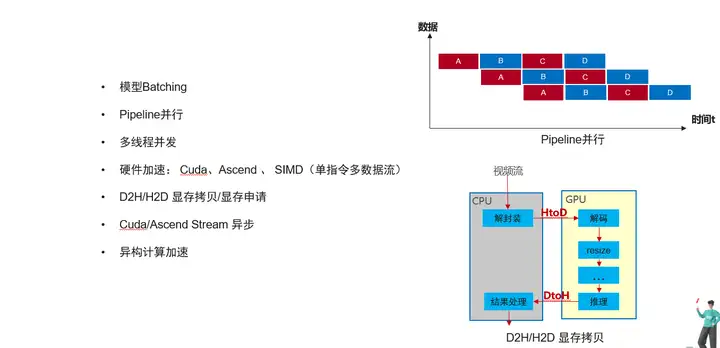
模型Batching: 原理主要是将多次推理数据合并成一批数据进行GPU推理,相比单数据推理,batching推理可以降低Gpu Kernel Launch次数,充分利用多个GPU计算单元并发计算,从而提高整体吞吐量。 一次推理的数据个数叫Batchsize,Batchsize不一定是越大越好,往往和模型结构的稀疏程度有关系 ,所以需要具体模型具体分析。
Pipeline并行:将业务的处理划分为几个阶段,通过流水线的方式让不同数据并行起来。如下图所示,同一时间数据1在执行操作C的同时,数据2在执行操作B,数据3在执行操作A。
多线程并发:某个操作单线程处理成为瓶颈时,可以采用多线程并发执行。但一般还需要对多线程执行的结果做保序操作。
硬件加速:使用硬件的加速能力如Cuda、Ascend 、 SIMD等,与此同时硬件的加速会带来额外的主机到硬件设备的内存拷贝开销。
显存拷贝/显存申请: 不同与内存,硬件上显存的拷贝和申请耗时较长,频繁的申请和拷贝会影响整体性能,可以通过显存池的管理减少内存申请的时间,还可以调整业务逻辑,尽量减少HtoD,DtoH的拷贝次数。
Cuda/Ascend Stream 异步: 基于cuda或者ascend硬件时,可以使用带Stream的异步接口进行加速。
异构计算加速:可以使用多个或者多种硬件进行加速,如使用多GPU进行推理,再比如使用cpu+gpu多硬件同时推理,并且能做到负载均衡。
以上这些常用的应用工程优化需要根据当前业务瓶颈合理选择。同时上述方法的实现实现往往需要耗费大量工作,同时对软件能力要求较高。为此华为云开源了ModelBox框架,集成了上述优化手段,能够帮忙开发者快速提升性能。
二、ModelBox开源框架介绍
1、什么ModelBox开源框架
一个典型场景AI算法的商用落地除了模型训练外,还需要进行视频图片解码、HTTP服务、预处理、后处理、多模型复杂业务串联、运维、打包等工程开发,往往需要耗费比模型训练多得多的时间,同时算法的性能和可靠性通常随开发人员的工程能力水平高低而参差不齐,严重影响AI算法的上线效率。
ModelBox是一套专门为AI开发者提供的易于使用,高效,高扩展的AI推理开发框架,它可以帮助AI开发者快速完成从模型文件到AI推理应用的开发和上线工作,降低AI算法落地门槛,同时带来AI应用的高稳定性和极致性能。ModelBox是一套易用、高效、高扩展的AI推理开发框架,帮助开发者快速完成算法工程化,并带来高性能,一次开发端边云部署等好处。ModelBox框架当前已经开源,可详见https://modelbox-ai.com。
ModelBox框架主要特点有:
- 高效推理运行性能:集成常用应用工程优化手段,高效的智能调度引擎,相比原生推理框架性能成倍提升。
- 全场景灵活开发模式:支持图编排模式、SDK模式、Serving模式等多种适用方式,适用于新业务快速开发、业务迁移、单模型推理等不同开发场景。
- 一次开发端边云部署:屏蔽底层操作系统、加速硬件、推理框架差异,一份代码端边云部署。
- 支撑多语言开发:支持C++、Python两种语言开发。
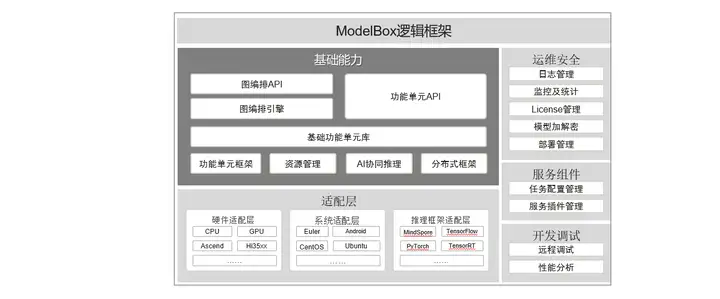
ModolBox框架采用图编排的方式开发业务,将应用执行逻辑通过有向图的方式表达出来,而图上的每个节点叫做ModelBox功能单元,是应用的基本组成部分,也是ModelBox的执行单元。在ModelBox中,内置了大量的高性能基础功能单元库,开发者可以直接复用这些功能单元减少开发工作。除内置功能单元外,ModelBox支持功能单元的自定义开发,支持的功能单元形式多样,如C/C++动态库、Python脚本、模型+模型配置文件等。除此之外,ModolBox提供了运维安全、开发调试等配套的组件用于快速服务化。
ModolBox逻辑架构如下图:
ModelBox提供了两个开发模式:标准模式和SDK模式。
标准模式:这种模式下AI应用的主入口由ModelBox进程管理,应用的全部逻辑承载编排在流程图中,开发者首先通过流程图配置文件描述整个应用的数据处理过程,然后实现流程图中缺少的功能单元,完成整个应用。此模式优点是并发度高,性能好,配套组件丰富,缺点是需要把全部业务逻辑拆分为图,在存量复杂业务场景切换工作量大。
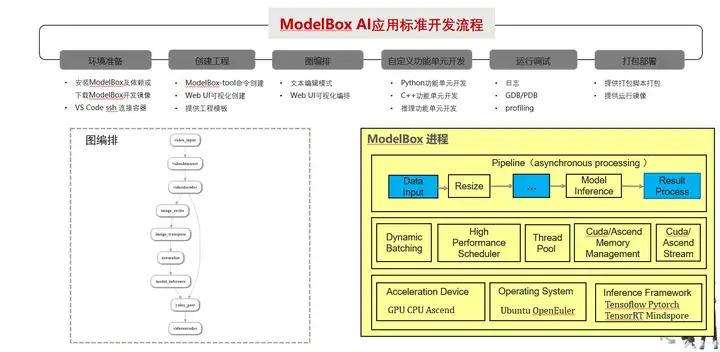
SDK模式:这种模式下,开发者业务进程通过ModelBox SDK提供的API管理流程图的初始化、启动及数据交互, 此模式可以选择性的将部分逻辑切换为ModelBox图编排。优点是改动少,优化工作量少,可以逐步优化。缺点相对于标准模式只能获得部分性能收益。
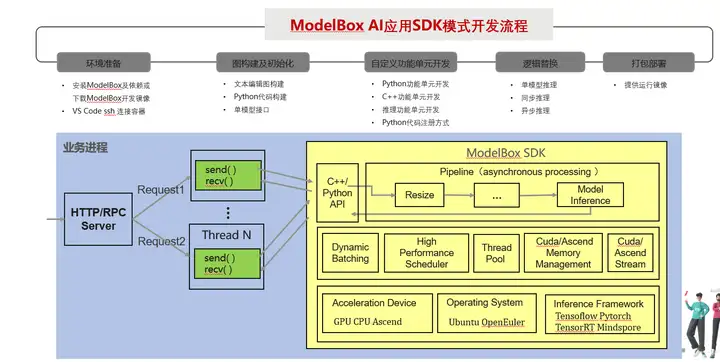
两种模式适用于不同场景。标准模式适用于整体业务逻辑清晰,比较容易通过流程图方式表达的场景,和新开发业务场景。SDK模式适用场景于应用逻辑不能全部进入流程图中,控制逻辑较为复杂的场景;已有业务迁移场景等。本文后续讲解的AI应用性能优化实践主要通过SDK模式进行优化。
三、AI应用性能优化实践
1、图像分类业务介绍
下面以一个图像分类的AI应用为样例,介绍如何使用ModelBox框架进行性能优化。
该业务原始代码使用Python语言开发,采用flask框架作为Http Server提供Restful API 对输入图像进行识别分类,模型为ResNet101网络,训练引擎为tensorflow 。具体业务逻辑和性能情况如下图所示:
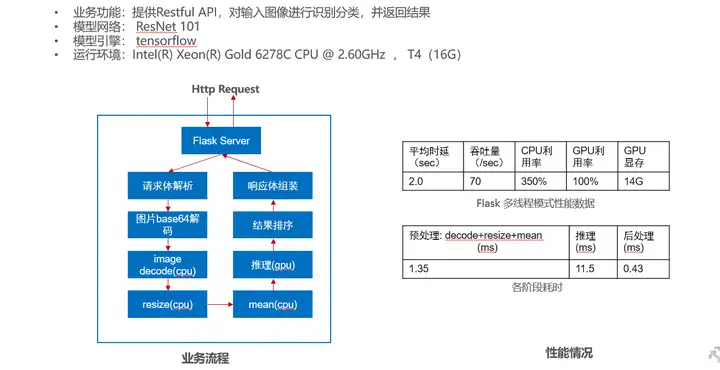
从当前业务场景和性能测试情况看,推理阶段耗时占比大,导致整体性能较差。对照前面讲解的AI应用软件工程优化方法,我们可以从以下几个方面尝试做优化:
1)一次请求携带一张图片,只能单batch推理,多个请求多次单bacth推理,算然gpu利用率100%,但效率低,可通过模型batching优化推理性能。
2)如果模型推理时间优化后,预处理、推理、后处理可以通过pipeline并发优化。
3)图片decode、resize、mean等cpu的预处理操作可以通过cuda、多线程加速
我们使用ModelBox框架可以快速尝试上述模型和预处理优化,测试效果。
2、模型推理优化
我们首先尝试使用ModelBox 框架SDK API优化模型推理部分性能,针对纯模型优化,ModelBox 提供了Model接口,只需几行代码即可完成优化。
1) 环境准备
下载tensorflow引擎的ModelBox开发镜像。下载方法可见ModelBox文档,在代码中引入modelbox包,设置日志级别。
# modelbox
import modelbox
modelbox.set_log_level(modelbox.Log.Level.DEBUG)
2) 配置推理功能单元
新建classify_infer.toml配置文件,根据模型实际情况填写模型配置,如模型文件路径、推理引擎类型、输入Tensor名称、输出Tensor名称等。配置如下:
# 基础配置
[base]
name = "classify_infer" # 功能单元名称
device = "cuda" # 功能单元运行的设备类型,cpu,cuda,ascend等。
version = "0.0.1" # 功能单元组件版本号
description = "description" # 功能单元功能描述信息
entry = "../model/resnet_v1_101.pb" # 模型文件路径
type = "inference" #推理功能单元时,此处为固定值
virtual_type = "tensorflow" # 指定推理引擎, 可以时tensorflow, tensorrt, atc
[config]
plugin = "" # 推理引擎插件
# 输入端口描述
[input]
[input.input1] # 输入端口编号,格式为input.input[N]
name = "input" # 输入端口名称
# 输出端口描述
[output]
[output.output1] # 输出端口编号,格式为output.output[N]
name = "resnet_v1_101/predictions/Softmax" # 输出端口名称
3) 模型初始化
在业务初始化阶段使用Model接口进行模型推理实例初始化,接口如下:
modelbox.Model(path, node_name, batch_size, device_type, device_id)
输入参数说明:
path: 推理功能单元配置文件路径,即classify_infer.toml路径
node_name:实例名称
batch_size:一次batching推理的batchsize最大值,当不足时,采用动态batch。
device_type:加速硬件类型,可取值cuda、cpu、ascend等,也可设置多硬件,如” cuda:0,1,2;cpu:0” 等
device_id:单加速类型时,加速设备号
Model实例初始化成功后启动,同时注释掉原有tensorflow不再使用的代码,初始化代码如下:
def __init__(self)
...
# modelbox
self.model = modelbox.Model("/home/code/image_classify/classify_infer/", "classify_infer", ["input"], ["resnet_v1_101/predictions/Softmax"], 8, "cuda", "0")
self.model.start()
4) 模型推理替换
使用Model.infer 接口替换掉原始tensorflow的session.run接口,接口说明如下:
output = model.infer([input_port1_data, input_port2_data, … ])
输入参数说明:
input_port1_data、 input_port2_data : 模型每个输入Tensor数据
输出参数说明:
output: 模型的推理结果列表,,可以通过下标获取每个Tensor输出结果。结果类型为modelbox::Buffer,通常需要通过numpy接口转换numpy类型进行后处理。
具体代码修改如下:
def process(self, img_file):
image = self.preprocess(img_file)
...
# 对image进行推理,batch为1
# infer_output = self.sess.run(self.output,feed_dict={self.input: np.expand_dims( image,0 )})
# probabilities = infer_output[0, 0:]
#modelbox
output_list = self.model.infer([image.astype(np.float32)])
output_buffer = output_list[0]
probabilities = np.array(output_buffer)
...
self.postprocess(probabilities, resp)
至此,推理的优化代码已修改完毕,进行功能调试后,即可对性能进行测试。通过还可以通过ModelBox 性能Profiling工具进行性能数据打点分析推理执行性能详细情况,具体使用方法可见官方文档。前面我们讲到bacth_size并不是越大越好,我们可以通过调整bacth_size参数测试性能情况。该业务实测数据如下:
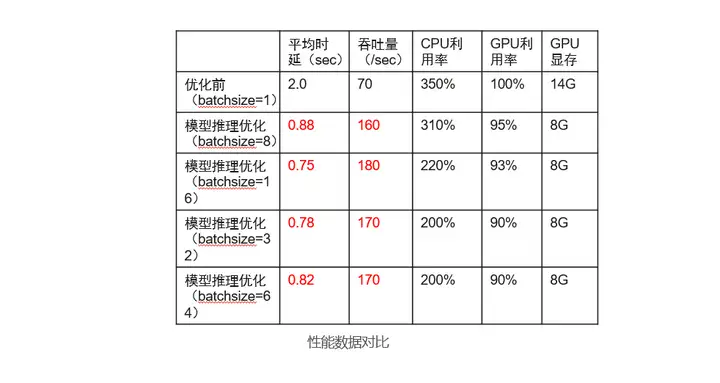
我们可以看到性能优化效果十分明显,吞吐量整体提升257%,同时在batch_size 为8时性能最佳。至此,模型推理优化完成, 为啥经过简单几行代码即可完成性能的显著提升呢? 我们可以看看下图:
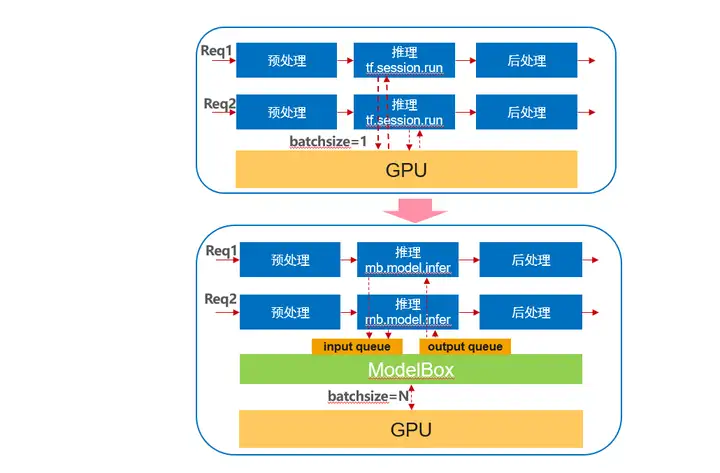
优化前每个请求单独处理, 每次推理一份数据,使用ModelBox后,会有单独ModelBox线程和队列将多个线程的推理请求合并,通过bacthing推理一组数据。
推理模型切换到ModelBox后,除了收获性能收益外,还可以获得如下收益: 软硬件引擎适配能力, 修改到其他引擎或者硬件无需修改代码,只需要修改模型配置文件即可; 多卡、多硬件能力:可以通过配置至此单进程多卡,或者多类型硬件异构能力。
3、预处理优化
模型优化完成后,如果瓶颈转移到模型预处理,我们还可以通过ModelBox对AI应用的预处理进行优化。下面介绍下如果通过ModelBox SDK API进行推理加预处理优化。
1) 构造流程图
基于上一章节推理优化步骤的环境准备、配置推理功能单元后,我们需要将预处理和推理流程构造为ModelBox流程图。 原始业务逻辑中:图片解码、resize、mean、推理 以上这些操作都是相对耗时,并且通过GPU加速的。本次我们对上述操作进行流程图构建如下:
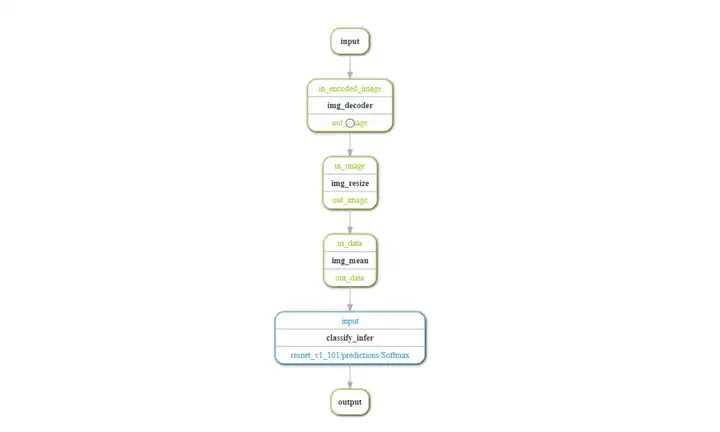
代码层面,ModelBox可以通过两种方式构建流程图:
a)通过图配置文件构建
创建graph.toml, 并编写配置文件如下:
[driver]
skip-default = false
dir=["/home/code/image_classify/classify_infer/"] # path for user c++ flowuint, python flowuint, infer flowunit
[profile]
profile=false
trace=false
dir="/home/code/image_classify/test/"
[log]
level="INFO"
[graph]
format = "graphviz"
graphconf = '''digraph weibo_sample {
queue_size=64
batch_size=8
input[type=input, device=cpu]
img_decoder[type=flowunit, flowunit=image_decoder, device=cpu, deviceid=0,batch_size=8]
img_resize[type=flowunit, flowunit=resize, device=cpu, deviceid=0, image_height=224, image_width=224,batch_size=18]
img_mean[type=flowunit, flowunit=mean, device=cpu, deviceid=0, mean="123.68,116.78,103.94",batch_size=8]
classify_infer[type=flowunit, flowunit=classify_infer, device=cuda, deviceid="1",batch_size=16]
output[type=output, device=cpu]
input -> img_decoder:in_encoded_image
img_decoder:out_image -> img_resize:in_image
#input -> img_resize:in_image
img_resize:out_image -> img_mean:in_data
img_mean:out_data -> classify_infer:input
classify_infer:"resnet_v1_101/predictions/Softmax" -> output
}
'''
配置文件编写后通过ModelBox Flow接口加载并运行:
def __init__(self)
...
# modelbox
self.flow = modelbox.Flow()
self.flow.init("/home/code/image_classify/graph/image_classify.toml")
self.flow.start_run()
b)通过代码构建
通过FlowGraphDesc对象构建流程图,并加载运行。
def __init__(self)
...
# modelbox
self.graph_desc = modelbox.FlowGraphDesc()
self.graph_desc.set_drivers_dir(["/home/code/image_classify/classify_infer/"])
self.graph_desc.set_queue_size(64)
self.graph_desc.set_batch_size(8)
input = self.graph_desc.add_input("input")
img_decoder = self.graph_desc.add_node("image_decoder", "cpu",input)
img_resize = self.graph_desc.add_node("resize", "cpu", ["image_height=224", "image_width=224"],img_decoder)
img_mean = self.graph_desc.add_node("mean", "cpu",["mean=123.68,116.78,103.94" ], img_resize)
classify_infer = self.graph_desc.add_node("classify_infer", "cuda", ["batch_size=32"], img_mean)
self.graph_desc.add_output("output", classify_infer)
self.flow = modelbox.Flow()
self.flow.init(self.graph_desc)
self.flow.start_run()
需要说明的是,本业务需要优化的功能单元图片解码、resize、mean都是ModelBox预置功能单元,并且支持硬件加速,如果不在预置库中时,可以通过功能单元注册接口注册为功能单元。
不管哪种方式,我们都可以通过配置调整每个功能单元的batch_size、queue_size、设备类型,设备ID等功能参数来调整执行策略。如通过设置device=cuda则指定改功能单元通过GPU加速,batch_size=8, 则表示一次处理8个数据,queue_size =32 ,则代表非功能单元会使用queue_size/batch_size = 4个线程同时并行计算。
2) 业务逻辑替换
将原有预处理和推理的代码替换为ModelBox Flow的运行接口。
def process(self, img_file):
# image = self.preprocess(img_file)
# 对image进行推理,batch为1
# infer_output = self.sess.run(self.output,feed_dict={self.input: np.expand_dims( image,0 )})
# probabilities = infer_output[0, 0:]
#modelbox
stream_io = self.flow.create_stream_io()
buffer = stream_io.create_buffer(img_file)
stream_io.send("input", buffer)
output_buffer = stream_io.recv("output")
probabilities = np.array(output_buffer)
...
self.postprocess(probabilities, resp)
send()输入参数说明: 图的输入端口名称,输入buffer
recv()输出参数说明: output: 图的输出buffer
至此,预处理加推理的优化代码已修改完毕,进行功能调试后,即可对性能进行测试。同样可以通过ModelBox 性能Profiling工具进行性能分析。我们分别设置预处理全为cpu、 预处理全为gpu进行性能测试,测试结果如下:
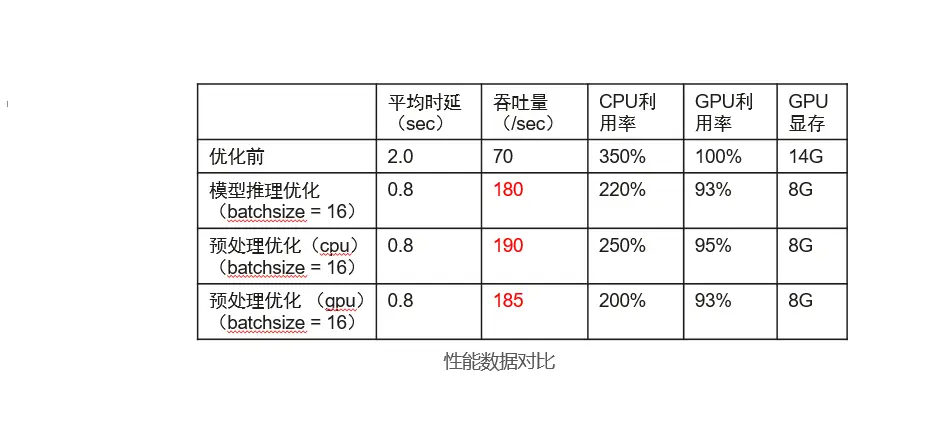
可以看到同为batchsize为16时,通过预处理性能较纯模型推理优化性能有提升,同时全为cpu预处理时反而比gpu预处理性能好。这是因为一方面cpu预处理采用了多线程并发处理,另一方面GPU预处理抢占了GPU资源,影响了推理速度,从而影响整体性能。所以并不推荐所有操作都使用硬件加速,需要具体场景具体分析,保证资源计算的合理分配。
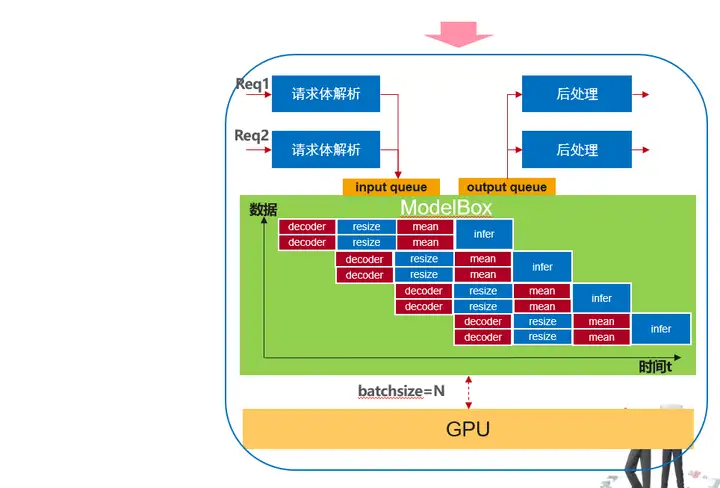
通过ModelBox优化后的数据执行情况如上,优化收益主要如下:
1、流程图每个节点都是独立线程执行,多个数据通过pipeline并行
2、除推理功能单元外,其他cpu预处理采用多线程执行,每个功能单元线程数可以灵活配置
3、不仅推理,其他功能单元的执行也可以是采用多硬件异构加速
AI应用的性能优化是一个循序渐进的过程,并不是所有方法都有效,开发者需要结果自身业务具体问题具体分析,才能到达事半功倍的效果。经过实际业务的优化实践,希望大家对如果使用ModeBox框架优化AI应用性能有一些初步了解,同时也能理解优化原理。如果对ModelBox感兴趣可以进入ModelBox官网详细了解。
如何使用ModelBox快速提升AI应用性能?的更多相关文章
- 提升AI智能化水平,打造智慧新体验
内容来源:华为开发者大会2021 HMS Core 6 AI技术论坛,主题演讲<提升AI智能化水平,打造智慧新体验>. 演讲嘉宾:沈波,华为消费者AI与智慧全场景ML Kit产品总监 今天 ...
- psutil 是因为该包能提升 memory_profiler 的性能
python 性能分析入门指南 一点号数据玩家昨天 限时干货下载:添加微信公众号"数据玩家「fbigdata」" 回复[7]免费获取[完整数据分析资料!(包括SPSS.SAS.SQ ...
- 如何从软硬件层面提升 Android 动画性能?
若是有人问如何解决动画性能不佳的问题,Dan Lew Codes 总会反问:你是否使用了硬件层? 动画放映过程中每帧画面可能都要重绘.如果使用视图层,,渲染过的视图可以存入离屏缓存以待将来重用,而无需 ...
- jQuery 做好七件事帮你提升jQuery的性能
1. Append Outside of Loops 凡是触及到DOM都是有代价的.如果你向DOM当中附加大量的元素,你会想一次性将它们全部附加进来,而不是分多次进行.当在循环当中附加元素就会产生一个 ...
- 多实例gpu_MIG技术快速提高AI生产率
多实例gpu_MIG技术快速提高AI生产率 Ride the Fast Lane to AI Productivity with Multi-Instance GPUs 一.平台介绍 NVIDIA安培 ...
- 使用OPCache提升PHP的性能
对于 PHP 这样的解释型语言来说,每次的运行都会将所有的代码进行一次加载解析,这样一方面的好处是代码随时都可以进行热更新修改,因为我们不需要编译.但是这也会带来一个问题,那就是无法承载过大的访问量. ...
- 提升VMware虚拟机性能招数
在VMware虚拟机(VMware Workstation或VMware Server)中我们可以同时运行多个Guest OS,当同时在同一Host OS中运行多台虚拟机时势必会严重影响到Host O ...
- 网站seo新手快速提升自己的技巧
第一.找自身的问题 大多数从业者都有下面两个严重的问题: 1.过于放大SEO的重要性每个人,都有自大的习惯,地位越NB往往越把自己认知的一切当做真理,其实有可能那只是井口那巴掌大的一片天.在网络营销中 ...
- 如何提升 CSS 选择器性能
CSS 选择器性能损耗来自? CSS选择器对性能的影响源于浏览器匹配选择器和文档元素时所消耗的时间,所以优化选择器的原则是应尽量避免使用消耗更多匹配时间的选择器.而在这之前我们需要了解CSS选择器匹配 ...
- UI小白如何快速提升自己
作为一名经历过UI学习的过来人,这些观点是自己在整个学习的过程中总结的. 希望可以对大家有所帮助,可以让刚开始接触UI的人少走弯路吧,话不多说. 快速进入主题. 那么UI小白到底如何快速提成自己呢 ...
随机推荐
- 域名+端口号 访问minio服务问题
业务上需要用到分布式文件服务,选择了minio作为文件服务的组件,搭建好服务后使用IP+端口号(http://xx.xx.xx.xx:9001)的形式访问在所有环境下都没有问题. 上线部署时出于正规和 ...
- 第九篇:vue条件语句
好家伙,终于有个简单了的 v-if 条件判断 <div id="app"> <p v-if="seen">现在你看到我了</ ...
- 第二章 Kubernetes快速入门
一.四组基本概念 Pod/Pod控制器: Name/Namespace: Label/Label选择器: Service/Ingress. 二.Pod/Pod控制器 2.1 Pod Pod是K8S里能 ...
- Vmware虚拟主机访问外网设置
本手册使用10.4.7.0/24网段 重点在于虚拟主机的网关和宿主机上的Vmnet8的IP和虚拟网络编辑器的NET网关保持一致 1.设置宿主机网络适配器 选择允许Vmware网络共享 配置VMnet8 ...
- CDH6.2.0安装并使用基于HBase的Geomesa
1. 查看CDH 安装的hadoop 和 hbase 对应的版本 具体可以参考以下博客: https://www.cxyzjd.com/article/spark_Streaming/10876290 ...
- 如何写成高性能的代码(一):巧用Canvas绘制电子表格
一.什么是Canvas Canvas是HTML5的标签,是HTML5的一种新特性,又称画板.顾名思义,我们可以将其理解为一块画布,支持在上面绘制矩形.圆形等图形或logo等. 需要注意的是,与其他标签 ...
- 查询nginx访问日志中访问次数最多的前10个IP地址
cat log | cut -d ' ' -f 1 | sort | uniq -c | sort -nr | awk '{print $0}' | head -n 10
- 动态存储管理实战:GlusterFS
文件转载自:https://www.orchome.com/1284 本节以GlusterFS为例,从定义StorageClass.创建GlusterFS和Heketi服务.用户申请PVC到创建Pod ...
- 15_abstract,static,final
一. abstract 1. 抽象类 被abstract修饰的类,称为抽象类 抽象类意为不够完整的类.不够具体的类 抽象类对象无法独立存在,即不能new对象,但可以声明引用 作用: 可被子类继承,提供 ...
- Redis学习(1)---Redis概述
什么是NoSQL 概述 NoSQL:Not Only SQL,意思不仅仅是SQL,它是属于非关系型数据库.那什么是关系型数据库?数据结构是一种有行有列的数据库. NoSQL数据库是为了解决高并发.高可 ...