系统评价——数据包络分析DEA的R语言实现(七)
数据包络分析(Data envelopment analysis,DEA)是运筹学中用于测量决策部门生产效率的一种方法,它是基于相对效率发展的崭新的效率评估方法。 详细来说,通过使用数学规划模型,计算决策单元相对效率,从而评价各个决策单元。每个决策单元(Decision Making Units,DMU)都可以看作为相同的实体,各 DMU 有相同的输入、输出。综合分析输入、输出数据,DEA 可得出各个 DMU 的综合效率,据此定级排队 DMU,确定有效(即相对效率最高)DMU,挖掘其他 DMU非有效的程度和缘由。DEA 模型有多种类型,最具代表性有CCR 模型,BCC模型。CCR 模型基于规模报酬不变的假设,而BCC模型则基于规模报酬可变的假设,二者各有侧重,可以选择结合两个方法同时展开数据分析。

一、数据包络分析法
数据包络分析 (DEA) 是由美国著名运筹学家 A.Charnes (查恩斯) 、W.W.Cooper (库铂) 、E.Rhodes (罗兹) 于 1978 年首先提出,在相对效率评价概念基础上发展起来的一种非参数检验方法。在 DEA 中,受评估的单位或组织被称为决策单元 (简称 DMU) 。DEA 通过选取决策单元的多项投入和产出数据,利用线性规划,以最优投入与产出作为生产前沿,构建数据包络曲线。其中,有效点会位于前沿面上,效率值标定为1;无效点则会位于前沿面外, 并被赋予一个大于\(\theta\) 但小于 1 的相对的效率值指标。
1.1 CCR 模型
CCR 模型可计算规模报酬不变情况下的资源配置效率。假设我们要计算一组\(n\)个决策单元(DMU),它可能是企业、政府部门、学校或医院等。假设每一个DMU有\(m\)种投入,记为\(x_i\),投入权重表示为\(v_i\);每一个DMU有\(s\)种产出,记为\(y_r\),产出权重表示为\(u_r\)。首先,我们简单推导一下 CCR 模型,以第 \(j_0\)个决策单元的效率指数为目标,以所有决策单元的效率为约束,我们可以得到以下模型:
& \max h_{j_0}=\frac{\sum_{r=1}^s u_r y_{r j_0}}{\sum_{i=1}^m v_i x_{i j_0}} \\
& \text { s.t. } \frac{\sum_{r=1}^s u_r y_{r j}}{\sum_{i=1}^m v_i x_{i j}} \leq 1, j=1,2, \ldots n \\
& u \geq 0, v \geq 0 \\
&
\end{aligned}
\]
其中, \(x_{i j}\) 表示第 \(j\) 个决策单元对第 \(i\) 种投入要素的投放总量,而 \(y_{r j}\) 则表示第 \(j\) 个决策单元中 第 \(r\) 种产品的产出总量, \(v_i\) 和 \(u_r\) 分别指第 \(i\) 种类型投入与第 \(r\) 种类型产出的权重系数。
令 \(w=\frac{1}{v^T x_0} v, \mu=\frac{1}{v^T x_0} u\) ,经 Charnes-Cooper 变换,可变为如下线性规划模型:
\max h_{j_0}=\mu^T y_0 \\
\text { s.t. } w^T x_j-\mu^T y_j \geq 0, j=1,2, \ldots n \\
w^T x_0=1 \\
w \geq 0, \mu \geq 0
\end{gathered}
\]
在上述规划的对偶规划中我们引入松弛变量\(s^{+}\)和剩余变量\(s^{-}\) ,松弛变量表示达到最优配置需要减少的投入量,剩余变量表示达到最优配置需要增加的产出量。由此,不等式约束会变为等式约束,模型可以简化为:
\min \theta \\
\text { s.t. } \sum_{j=1}^n \lambda_j y_j+s^{+}=\theta x_0 \\
\sum_{j=1}^n \lambda_j y_j-s^{-}=\theta y_0 \\
\lambda_j \geq 0, j=1,2, \ldots n \\
s^{+} \geq 0, s^{-} \leq 0
\end{gathered}
\]
我们能够用 CCR 模型判定技术有效和规模有效是否同时成立:
若满足 \(\theta^*=1\) 且 \(s^{*+}=0, s^{*-}=0\) ,则决策单元为 DEA 有效,决策单元的经济活动同时为 技术有效和规模有效;
若满足 \(\theta^*=1\) ,但至少某个投入或者产出大于 0 ,则决策单元为弱 DEA 有效,决策单元的经 济活动不是同时为技术有效和规模有效;
若满足 \(\theta^*<1\) ,决策单元不是 DEA 有效,经济活动既不是技术有效,也不是规模有效。
1.2 BCC 模型
CCR 模型是在规模报酬不变的前提下所得到的,但是技术创新的规模报酬是不固定的,现实中存在的不平等竞争也会导致某些决策单元不能以最佳规模运行,于是 Banker,Charnes 和 Cooper 在 1984 年对之前仅讨论固定规模效益的 DEA 分析进行了扩展,提出了 BCC 模型。BCC 模型考虑到在可变规模收益 (VRS) 情况,即当有的决策单元不是以最佳的规模运行时,技术效益 (Technology efficiency,TE) 的测度会受到规模效率 (Scale efficiency,SE) 的影响。
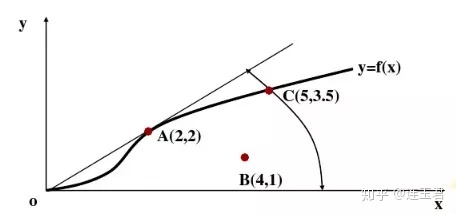
以上图为例,位于生产函数曲线 f(x) 上的点 A 与点 C 都是技术有效,位于 f(x) 曲线内的点 B 则不是技术有效。由于点 A 还位于生产函数曲线的拐点,A 还是规模有效点。然而点 C 位于规模收益递减区域,因此它不是规模有效。BCC 模型正是要讨论位于这种生产状况的决策单元。因此,在构建 BCC 模型时,我们需要假设规模报酬可变,对 CCR 模型的约束条件进行简单的改进,增加凸性假设条件:\(\sum \lambda_j=1,j=1,2,...,n\),即可得:
\min \theta \\
\text { s.t. } \sum_{j=1}^n \lambda_j y_j+s^{+}=\theta x_0 \\
\sum_{j=1}^n \lambda_j y_j-s^{-}=\theta y_0 \\
\sum\lambda_j =1, j=1,2, \ldots n \\
s^{+} \geq 0, s^{-} \leq 0
\end{gathered}
\]
我们可以对数据同时做 CCR 模型和 BCC 模型的 DEA 分析来评判决策单元的规模效率 (SE)。如果决策单元 CCR 和 BCC 的技术效益存在差异,则表明此决策单元规模无效,并且规模无效效率可以由 BCC 模型的技术效益和 CCR 模型的技术效益之间的差异计算出来。
1.3 DEA相关术语
数据包络分析法(DEA)是针对多投入和多产出的问题,利用线性规划的方法,对具有可比性的同类型单位进行相对有效性评价的一种数量分析方法。先解释一下几个基础概念:
技术效率:指在保持决策单元投入不变的情况下,实际产出同理想产出的比值。
规模报酬:规模报酬是要说明,当生产要素同时增加了一倍,如果产量的增加正好是一倍,称之为规模报酬不变(-),如果产量增加多于一倍,则称之为规模报酬递增(irs),进而,如果产量增加少于一倍,就称为规模报酬递减(drs)。
决策单元(DMU):就是效率评价的对象,可以理解为一个将一定“投入”转化为一定“产出”的实体。此文中,DMU就是每个楼盘。
生产可能集:我们用\(X=\{x_1,x_2,...,x_m\}\) 来表示每个决策单元生产过程的投入向量,维度为\(n\),代表有\(n\)种类型的投入变量;用\(Y=\{y_1,y_2,...,y_s\}\) 来表示每个决策单元生产过程的产出向量,维度为\(s\),代表有\(s\)种类型的产出变量。则简写之,我们可以使用\((X,Y)\)来表示DMU的整个生产活动。\(T=(X,Y)\)代表投入为\(X\),产出为\(Y\)的所有可能的生产活动的集合。
DEA强有效:任何一项投入的数量都无法减少,除非减少产出的数量或者增加其他至少一种投入的数量;任何一项产出的数量都无法增加,除非增加投入的数量或减少其他至少一种产出的数量。
DEA弱有效:无法等比例减少各项投入的数量,除非减少产出的数量;无法等比例增加各项产出的数量,除非增加投入的数量。这种情况下,虽然不能等比例减少投入或增加产出,但某一项或几项(但不是全部)投入可能减少,所以称为弱有效。
生产前沿面:对于生产可能集\((X,Y)\in T\),如果不存在\(Y^{'} \geq Y,\quad (X,Y^{'})\in T\),则称\((X,Y)\)为有效生产活动,此投入产出对应一个前沿,由众多“有效生产”构成的凸包即为前沿。(自己通俗的理解)对于给定的生产要素和产出价格,选择要素投入的最优组合和产出的最优组合,即投入成本最小、产出收益最大的组合。它所对应的生产函数所描述的生产可能性边界就是生产前沿面。
上述数据包络分析模型都是从投入方向建构的,还可以建立产出方向的模型(感兴趣的读者可参看数据包络分析--综合的双目标数据包络分析模型),从框架思想上是一致的。投入导向模型的思想是“按比例减少投入的数量,而不改变产出的数量”;产出导向模型的思想是“在不改变投入数量的情况下,按比例扩大产出数量”。后面常常将DEA效率分为:
综合效率Overall Efficiency(OE) 是CCR模型的最优解
技术效率Technical Efficiency(TE) 是BCC模型的最优解
规模效率Scale Efficiency (SE) 可以通过(OE)除以(TE)来计算。
| 项 | 说明 |
|---|---|
| 综合效率值θ | 用于判断DEA是否有效(即有效性分析),数字1则‘DEA有效’,反之小于1则‘非DEA有效’ |
| 规模效率值 | 该值等于1则说明规模收益不变(最优状态),该值小于1说明规模收益递增(规模过小可扩大规模增加效益),该值大于1说明规模收益递减(规模过大可减少规模增加效益)。 |
| 投入冗余 | 投入过多,需要减少多少才更优(松驰变量S-) |
| 产出不足 | 产出过少,需要增加多少才更优(松驰变量S+) |
1.4 Bootstrap-DEA法
Simar和Wilson等人提出了可以对DEA估计值进行纠偏、估计置信区间及说明显著性水平的Bootsrap-DEA方法。该方法的主要思路是:利用Bootstrap的思想对原始样本进行重复的抽样,构造大量的Bootstrap样本数据,从而得到大量的Bootstrap效率值,通过Bootstrap效率值的经验分布来构造置信区间等去进行统计推断。真实的效率值、DEA估计效率值及Bootstrap效率值三者之间的关系如下:DEA估计效率值是对原始样本的真实效率值的估计量,Bootstrap效率值是基于大量模拟Bootstrap样本对DEA估计效率值的估计及纠偏。
二、数据包络分析的R函数
#下载及加载安装包
install.packages("rDEA")
library(rDEA)
2.1 CCR和BCC模型
Data envelopment analysis scores
#调用用法
dea(XREF, YREF, X, Y, W=NULL, model, RTS="variable")
#所用参数Arguments
XREF
所有决策单元的输入矩阵:a matrix of inputs for observations used for constructing the frontier.
YREF
所有决策单元的输出矩阵:a matrix of outputs for observations used for constructing the frontier.
X
要评价的决策单元的输入矩阵。
Y
要评价的决策单元的输出矩阵。
W
a matrix of input prices for observations, for which DEA scores are estimated in cost-minimization model, W=NULL for input- and output-oriented models。
model
模型选择:可以设为 "input" for input-oriented;"output" for output-oriented; "costmin" for cost-minimization model。
RTS
规模收益选择:RTS can be "constant";"variable" or "non-increasing"。
#输出值
thetaOpt
a vector of DEA scores in input- or output-oriented model, thetaOpt is in (0,1).
gammaOpt
a vector of DEA scores in cost-minimization model.
XOpt
the matrix of optimal values of inputs, only returned for cost-minimization model.
lambda
the matrix of values for constraint coefficients in the corresponding linear optimization problem, lambda >=0.
lambda_sum
the vector for sum of constraint coefficients in the corresponding linear optimization problem, lamdba_sum=1 for variable returns-to-scale, lambda_sum <=1 for non-increasing returns-to-scale.
2.2 Bootstrap DEA模型
Bias-corrected data envelopment analysis
#模型调用函数
dea.robust (X, Y, W=NULL, model, RTS="variable", B=1000, alpha=0.05, bw="bw.ucv", bw_mult=1)
三、案例分析
基于DEA法分析医院医疗服务效绩分析。输入样本数据至矩阵(matrix)中,将数据分成两组,一组是投入,一组是产出。这里的案例中\(x\)是指投入input,\(y\)指产出output;\(x\)分别为医生数,护士数,其他人员数;\(y\)为门急诊人次数,出院次数。
3.1 经典DEA模型的分析
library(rDEA)
#10家医院的3个输入和2个输出数据
X<-matrix(c(887,277,326,504,365,312,358,329,404,423,1090,252,475,524,543,469,340,329,260,1021,1086,366,380,559,314,236,171,325,291,766),ncol=3)
Y<-matrix(c(1683441,556126,1001634,953445,809861,276522,837199,408298,175363,581887,59423,39967,19712,15142,18665,19910,19624,28140,18269,29626),ncol=2)
#模型选择和应用
dea_model1 = dea(XREF=X, YREF=Y, X=X, Y=Y, model="input", RTS="constant")
dea_model2 = dea(XREF=X, YREF=Y, X=X, Y=Y, model="input", RTS="variable")
dea_model3 = dea(XREF=X, YREF=Y, X=X, Y=Y, model="output", RTS="constant")
dea_model4 = dea(XREF=X, YREF=Y, X=X, Y=Y, model="output", RTS="variable")
#解释说明
#model="input", RTS="constant"指投入导向-报酬不变
#model="output", RTS="variable"指产出导向-报酬可变
dea_model1$thetaOpt
dea_model2$thetaOpt
dea_model3$thetaOpt
dea_model4$thetaOpt
不变规模收益计算结果对应CCR模型;可变规模收益对应BCC模型
| 决策单元 | dea_model1.thetaOpt(投入-不变) | dea_model2.thetaOpt(投入-可变) | dea_model3.thetaOpt(产出-不变) | dea_model4.thetaOpt(产出-可变) |
|---|---|---|---|---|
| A | 0.72 | 1.00 | 0.72 | 1.00 |
| B | 1.00 | 1.00 | 1.00 | 1.00 |
| C | 1.00 | 1.00 | 1.00 | 1.00 |
| D | 0.77 | 0.83 | 0.77 | 0.90 |
| E | 0.83 | 0.90 | 0.83 | 0.86 |
| F | 0.76 | 1.00 | 0.76 | 1.00 |
| G | 1.00 | 1.00 | 1.00 | 1.00 |
| H | 0.79 | 0.92 | 0.79 | 0.79 |
| I | 0.57 | 1.00 | 0.57 | 1.00 |
| J | 0.59 | 0.66 | 0.59 | 0.69 |
从上表可知,投入-不变和产出-不变模型的计算结果相同,四种模型有效值都在生产前沿面上的决策单元有B、C和G,这样的评价结果可供决策单元的决策者参考,寻找改善企业效率的途径。
3.2 Bootstrap DEA模型的分析
# 运行 2000 迭代 bootstrap DEA模型分析
di = dea.robust(X=X, Y=Y, model="input", RTS="constant", B=2000)
# robust estimates of technical efficiency for each hospital对每家医院的技术效率的稳健估计
di$theta_hat_hat #效率值
di$bias #偏差(误)
di$theta_ci_low #置信区间下限
di$theta_ci_high #置信区间上限
| 决策单元 | dea_model1.thetaOpt(效率值) | di.theta_hat_hat(纠偏后效率值) | di.bias(偏差) | di.theta_ci_low(下限) | di.theta_ci_high (上限) |
|---|---|---|---|---|---|
| A | 0.72 | 0.59 | 0.13 | 0.48 | 0.74 |
| B | 1.00 | 0.70 | 0.30 | 0.42 | 1.16 |
| C | 1.00 | 0.78 | 0.22 | 0.59 | 1.03 |
| D | 0.77 | 0.65 | 0.12 | 0.55 | 0.80 |
| E | 0.83 | 0.68 | 0.15 | 0.55 | 0.86 |
| F | 0.76 | 0.66 | 0.09 | 0.59 | 0.81 |
| G | 1.00 | 0.68 | 0.32 | 0.40 | 1.15 |
| H | 0.79 | 0.66 | 0.13 | 0.55 | 0.88 |
| I | 0.57 | 0.48 | 0.09 | 0.40 | 0.63 |
| J | 0.59 | 0.49 | 0.10 | 0.41 | 0.63 |
从上表可知,各决策单元的效率都有所调整,可比较其排名的变化,大多数决策单元的效率都有改进的空间。
3.3 练习案例数据
有13家航空公司(DMUs)以3个输入和2个输出来估计效率。输入数据包括载客量、燃油和员工数量,输出数据包括旅客人数和货运数量。
| DMU | Aircraft | Fuel | Employee | Passenger | Freight |
|---|---|---|---|---|---|
| (fleet size) | (gallons) | (units) | (passenger-miles) | (ton-miles) | |
| A | 109 | 392 | 8259 | 23756 | 870 |
| B | 115 | 381 | 9628 | 24183 | 1359 |
| C | 767 | 2673 | 70923 | 163483 | 12449 |
| D | 90 | 282 | 9683 | 10370 | 509 |
| E | 461 | 1608 | 40630 | 99047 | 3726 |
| F | 628 | 2074 | 47420 | 128635 | 9214 |
| G | 81 | 75 | 7115 | 11962 | 536 |
| H | 153 | 458 | 10177 | 32436 | 1462 |
| I | 455 | 1722 | 29124 | 83862 | 6337 |
| J | 103 | 400 | 8987 | 14618 | 785 |
| K | 547 | 1217 | 34680 | 99636 | 6597 |
| L | 560 | 2532 | 51536 | 135480 | 10928 |
| M | 423 | 1303 | 32683 | 74106 | 4258 |
数据来源:数据包络分析(DEA)及Python实现
总结
DEA 作为评估组织绩效的管理工具已经得到了相当大的关注,它被广泛用于评估银行、航空公司、医院、大学和制造业等公共部门和私营部门的效率中。数据包络分析DEA是一种多指标投入和产出评价的研究方法,其应用数学规划模型计算比较决策单元(DMU)之间的相对效率,对评价对象做出评价。数据包络分析其本质原理是通过DMU 的输入和输出数据进行综合分析,得出每个DMU效率的相对指标,然后将所有DMU效率指标排序,确定相对有效的DMU,同时还可以用投影方法指出非DEA有效或者弱DEA有效的原因,以及应该改进的方向和程度,为管理人员提供管理决策信息。
参考资料
系统评价——数据包络分析DEA的R语言实现(七)的更多相关文章
- 数学建模 数据包络分析(DEA) Lingo实现
model: sets: dmu/../:lambda; !决策单元; inw/../:s1; !投入变量集; outw/../:s2; !产出变量集; inv(inw, dmu):x; !投入数据; ...
- R语言&页游渠道分析(转)
对着满屏的游戏后台数据,需要快速了解数据特征,一种茫然无从下手的感觉? 本文在游戏后台数据中,如何通过R语言快速的了解游戏后台的数据特征,以及统计各个数据之间的相关系数,并通过相关图来发现其中相关系数 ...
- R语言︱常用统计方法包+机器学习包(名称、简介)
一.一些函数包大汇总 转载于:http://www.dataguru.cn/thread-116761-1-1.html 时间上有点过期,下面的资料供大家参考基本的R包已经实现了传统多元统计的很多功能 ...
- R语言常用包汇总
转载于:https://blog.csdn.net/sinat_26917383/article/details/50651464?locationNum=2&fps=1 一.一些函数包大汇总 ...
- R语言的前世今生(转)
最近因病休养在家,另外也算是正式的离开Snack Studio.终于有了大把可以自由支配的时间.可以自主的安排.最近闲暇的时间总算是恶补了不少前段时间行业没有时间关注的新事物.看着行业里引领潮流的东西 ...
- R语言简单入门
一.运行R语言可以做哪些事? 1.探索性数据分析(将数据绘制图表) 2.统计推断(根据数据进行预测) 3.回归分析(对数据进行拟合分析) 4.机器学习(对数据集进行训练和预测) 5.数据产品开发 二. ...
- 统计计算与R语言的资料汇总(截止2016年12月)
本文在Creative Commons许可证下发布. 在fedora Linux上断断续续使用R语言过了9年后,发现R语言在国内用的人逐渐多了起来.由于工作原因,直到今年暑假一个赴京工作的机会与一位统 ...
- R语言各种假设检验实例整理(常用)
一.正态分布参数检验 例1. 某种原件的寿命X(以小时计)服从正态分布N(μ, σ)其中μ, σ2均未知.现测得16只元件的寿命如下: 159 280 101 212 224 379 179 264 ...
- R语言-单一变量分析
R语言简介: R语言是一门专用于统计分析的语言,有大量的内置函数和第三方库来制作基于数据的表格 准备工作 安装R语言 https://cran.rstudio.com/bin/windows/base ...
- R语言-文本挖掘
---恢复内容开始--- 案例1:对主席的新年致辞进行分词,绘制出词云 掌握jieba分词的用法 1.加载包 library(devtools) library(tm) library(jiebaR) ...
随机推荐
- 配置IDE
1.使用的ide Visual Studio Code 2.
- win10 wampserver升级 php7.0至 php7.2
1.去官网下载php7.2 下载地址: https://windows.php.net/download#php-7.0 2.下载安装 visual c++ 2017 或 visual c++ 20 ...
- python-文件内容操作
1.按文件中数据的组织形式把文件分为文本文件和二进制文件两类. 文本文件:文本文件存储的是常规字符串,由若干文本行组成,通常每行以换行符'\n'结尾.常规字符串是指记事本或其他文本编辑器能正常显示.编 ...
- Linux目录结构说明与基本操作
Linux系统目录如下: 详细说明如下: Linux系统文件与目录的基本操作: 一.显示文件内容命令--cat.more.less.head.tail. 1.cat命令 该命令的主要功能是用来显示文件 ...
- wait_event_interruptible() 等待队列
在Linux驱动程序中,可以使用等待队列(Wait Queue)来实现阻塞进程的唤醒. 1.定义"等待队列头部" wait_queue_head_t my_queue; wait_ ...
- JAVA 学习打卡 day3
2022-04-25 22:53:16 1.运算符 表达式是由操作数与运算符所组成Java中的语句有很多种形式,表达式就是其中一种形式.表达式是由操作数与运算符所组成,操作数可以是常量.变量也可以是方 ...
- SqlServer 不能收缩 ID 为 %s 的数据库中 ID 为 %s 的文件,因为它正由其他进程收缩或为空。
SQLServer数据库通常都不建议进行SHRINKFILE操作,因为SHRINKFILE不当会造成一定的性能问题. 但是当进行了某些操作(例如某个超大的日志类型表转成分区表切换了数据文件),数据库某 ...
- Asp.net zero项目框架和配置
- 替换yum源
1.yum源进行备份 进入到yum源的配置文件中 执行命令如下:cd /etc/yum.repos.d 将yum源进行备份:mv Centos-Base.repo Centos-Base.repo.b ...
- 字符串练习2 最长抑或路径(01trie树)
题目链接在这里:P4551 最长异或路径 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 是一道比较经典的问题,对于异或问题经常会使用01trie树来解决. 当然01trie树只是用 ...