day33:进程锁&事件&进程队列&进程间共享数据
目录
锁:Lock
1.锁的基本概念
上锁和解锁是一对,只上锁不解锁会发生死锁现象(代码阻塞,不往下执行了)
互斥锁 : 互斥锁是进程之间的互相排斥,谁先抢到这个锁资源就先使用,后抢到后使用
2.锁的基本用法
# 创建一把锁
lock = Lock()
# 上锁
lock.acquire()
# 连续上锁不解锁是死锁
lock.acquire() # error print("厕所中...") # 解锁
lock.release()
print("执行程序 ... ")
对上面代码的一波分析:因为上锁后又解锁,所以最后一行的执行程序...可以打印出
但是如果连续上两把锁,解一把锁,则会产生死锁状态。无法打印后面的执行程序...
3.模拟12306抢票软件
# 读写数据库中的票数
def wr_info(sign, dic=None):
if sign == "r":
with open("ticket.txt", mode="r", encoding="utf-8") as fp:
dic = json.load(fp)
return dic elif sign == "w":
with open("ticket.txt", mode="w", encoding="utf-8") as fp:
json.dump(dic, fp) # 抢票方法
def get_ticket(person):
# 获取数据库中实际的票数
dic = wr_info("r")
print(dic) # 模拟一下网络延迟
time.sleep(0.5) # 判断票数
if dic["count"] > 0:
print("%s抢到票了" % (person))
dic["count"] -= 1
wr_info("w", dic)
else:
print("%s没有抢到这张票" % (person)) def run(person, lock):
# 查看剩余票数
dic = wr_info("r")
print("%s 查询票数: %s" % (person, dic["count"])) # 上锁
lock.acquire()
# 开始抢票
get_ticket(person)
lock.release() if __name__ == "__main__":
lock = Lock()
lst = ["Fly", "Hurt", "Mojo", "Snow", "1dao", "770", "JieJ", "139", "Gemini", "SK"]
for i in lst:
p = Process(target=run, args=(i, lock))
p.start()
运行结果如下图所示
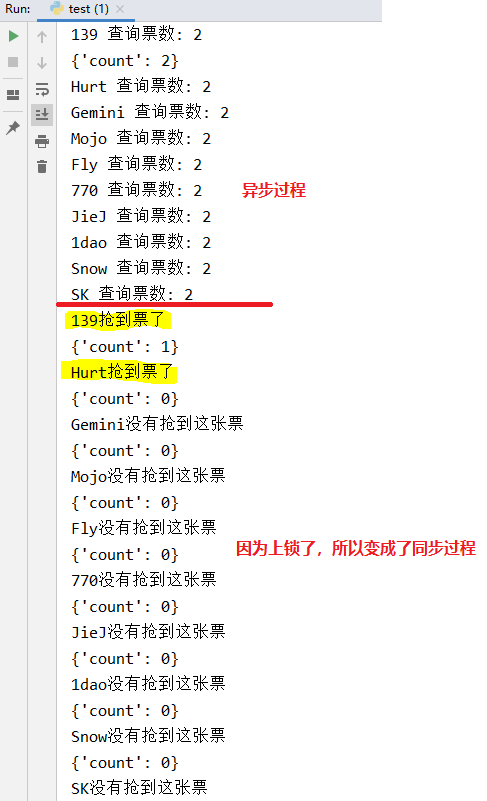
代码分析:
创建进程的时候,仍然是异步并发,
在执行到上锁时,多个进程之间变成了同步程序.
先来的先上锁,先执行,后来的进程后上锁,后执行
信号量:Semaphone
信号量 Semaphore 本质上就是锁,只不过可以控制上锁的数量
1.Semaphore的基本用法
sem = Semaphore(4) # 锁的数量为4
sem.acquire()
sem.acquire()
sem.acquire()
sem.acquire()
# sem.acquire() # 上第五把锁出现死锁状态.
print("执行相应的操作")
sem.release()
2.模拟KTV房间唱歌
def ktv(person, sem):
sem.acquire()
print("%s进入了ktv,正在唱歌" % (person))
# 开始唱歌,唱一段时间
time.sleep(random.randrange(3, 7)) # 3 4 5 6
print("%s离开了ktv,唱完了" % (person))
sem.release() if __name__ == "__main__":
sem = Semaphore(4)
lst = ["Fly", "Hurt", "1dao", "Mojo", "Snow", "770", "Giao", "SK", "139", "Gemini"]
for i in lst:
p = Process(target=ktv, args=(i, sem))
p.start()
运行结果如下图所示
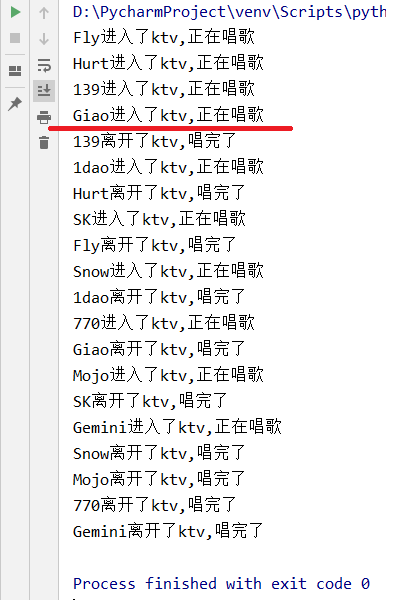
代码分析:
Semaphore 可以设置上锁的数量
同一时间最多允许几个进程上锁
创建进程的时候,是异步并发
执行任务的时候,遇到锁会变成同步程序.
事件:Event
1.Event中的基本方法
阻塞事件:
e = Event()生成事件对象e
e.wait()动态给程序加阻塞 , 程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值是False]
如果是True 不加阻塞
如果是False 加阻塞
控制这个属性的值:
set()方法 将这个属性的值改成True
clear()方法 将这个属性的值改成False
is_set()方法 判断当前的属性是否为True (默认上来是False)
2.Event的基本语法
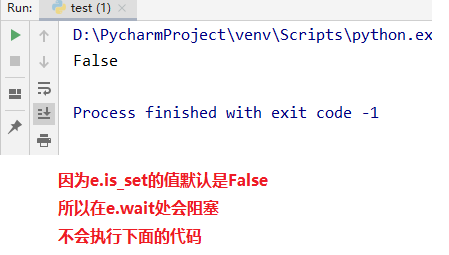
1.小试牛刀
e = Event()
print(e.is_set()) # 默认是False状态
e.wait()
print("程序运行中 ... ")
运行结果如下图所示
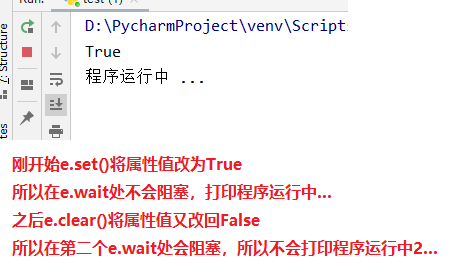
2.is_set=True
e = Event()
e.set() # 将内部成员属性值由False -> True
print(e.is_set())
e.wait()
print("程序运行中 ... ") e.clear() # 将内部成员属性值由True => False
e.wait()
print("程序运行中2 ... ")
运行结果如下图所示
3.wait里加参数
e = Event()
# wait参数 可以写时间 wait(3) 代表最多等待3秒钟
e.wait(3)
print("程序运行中3 ... ")
3.模拟经典红绿灯效果
def traffic_light(e):
print("红灯亮")
while True:
if e.is_set():
# 绿灯状态,亮1秒钟
time.sleep(1)
print("红灯亮")
e.clear()
else:
# 红灯状态,亮1秒钟
time.sleep(1)
print("绿灯亮")
e.set() def car(e,i):
# not False => True => 目前是红灯,小车在等待
if not e.is_set():
print("car%s 在等待" % (i))
# 加阻塞
e.wait()
print("car%s 通行了" % (i)) # 不关红绿灯,一直跑
"""
if __name__ == "__main__":
e = Event()
# 创建交通灯对象
p1 = Process(target=traffic_light,args=(e,))
p1.start() # 创建车对象
for i in range(1,21):
time.sleep(random.randrange(0,2)) # 0 1
p2 = Process(target=car,args=(e,i))
p2.start()
""" # 当所有小车都跑完之后,把红绿灯收拾起来,省电
if __name__ == "__main__":
lst = []
e = Event()
# 创建交通灯对象
p1 = Process(target=traffic_light,args=(e,)) # 设置红绿灯为守护进程
p1.daemon = True
p1.start() # 创建车对象
for i in range(1,21):
time.sleep(random.randrange(0,2)) # 0 1
p2 = Process(target=car,args=(e,i))
p2.start()
lst.append(p2) # 让所有的小车都通行之后,在结束交通灯
for i in lst:
i.join() print("程序结束 ... ")
运行结果如下图所示
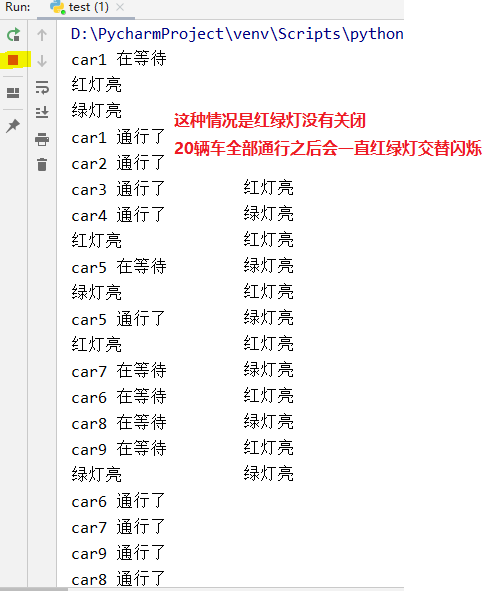
那么怎样才能做到,当20辆车已经通行之后,停止红绿灯的交替闪烁呢?
# 当所有小车都跑完之后,把红绿灯收拾起来,省电
if __name__ == "__main__":
lst = []
e = Event()
# 创建交通灯对象
p1 = Process(target=traffic_light, args=(e,)) # 设置红绿灯为守护进程
p1.daemon = True
p1.start() # 创建车对象
for i in range(1, 21):
time.sleep(random.randrange(0, 2)) # 0 1
p2 = Process(target=car, args=(e, i))
p2.start()
lst.append(p2) # 让所有的小车都通行之后,在结束交通灯
for i in lst:
i.join() print("程序结束 ... ")
运行结果如下图所示
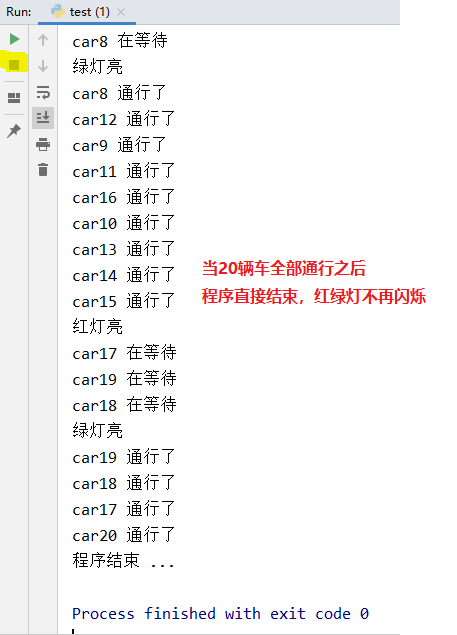
代码分析:
1.设置p1交通信号灯为deamon守护进程,当主进程结束,守护进程-红绿灯进程也结束
2.i.join:当所有小车都通行之后,再结束交通信号灯进程
进程队列:Queue
什么是队列?
队列特点: 先进先出,后进后出
1.put() 往队列里放值
q = Queue()
# 1.put 往队列中放值
q.put(100)
q.put(101)
q.put(102)
2.get() 从队列里取值
# 2.get 从队列中取值
res = q.get()
print(res)
res = q.get()
print(res)
res = q.get()
print(res)
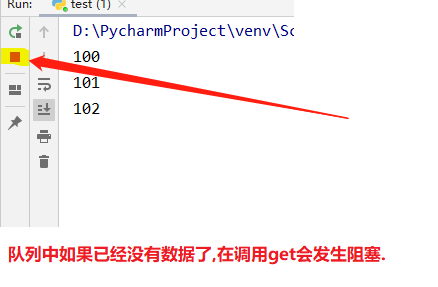
3.队列中如果已经没有数据了,在调用get会发生阻塞.
res = q.get()
print(res)
执行结果如下图所示
4.get_nowait 拿不到数据就报错
get_nowait 存在系统兼容性问题[windows]好用 [linux]不好用 不推荐
res = q.get_nowait()
print(res)

当然,我们可以使用try捕获到这个错误
try:
res = q.get_nowait()
print(res)
except queue.Empty:
pass
5.设置队列的长度
q2 = Queue(4)
q2.put(200)
q2.put(201)
q2.put(202)
q2.put(203)
# 如果超过了队列的指定长度,在继续存值会出现阻塞现象
# q2.put(204) # 超出长度会阻塞
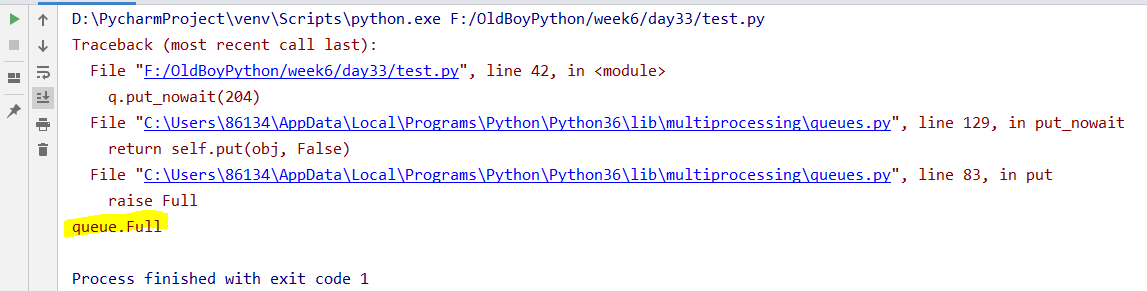
6.put_nowait() 非阻塞版本的put,超出长度后,直接报错
q = Queue(3)
q.put(100)
q.put(101)
q.put(102)
q.put_nowait(204) # 超出队列长度,直接报错
同样,我们可以使用try捕获异常
try:
q2.put_nowait(205)
except queue.Full:
pass
7.进程之间的数据共享
def func(q3):
# 2.子进程获取数据
res = q3.get()
print(res) # 3.子进程存数据
q3.put("马生平") if __name__ == "__main__":
q3 = Queue()
p = Process(target=func, args=(q3,))
p.start() # 1.主进程添加数据
q3.put("王凡") # 为了等待子进程把数据放到队列中,需要加join
p.join() # 4.主进程获取数据
res = q3.get()
print(res) print("主程序结束 ... ")
生产者和消费者模型
1.基本模型
def consumer(q,name):
while True:
food = q.get()
time.sleep(random.uniform(0.1,1))
print("%s 吃了一个%s" % (name,food)) # 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 打印生产的数据
print("%s 生产了 %s%s" % (name,food,i))
# 存储生产的数据
q.put(food + str(i)) if __name__ == "__main__":
q = Queue()
# 消费者
p1 = Process(target=consumer,args=(q,"宋云杰"))
# 生产者
p2 = Process(target=producer,args=(q,"马生平","黄瓜")) p1.start()
p2.start()
2.优化版
# 消费者模型
def consumer(q,name):
while True:
food = q.get()
if food is None:
break
time.sleep(random.uniform(0.1,1))
print("%s 吃了一个%s" % (name,food)) # 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 打印生产的数据
print("%s 生产了 %s%s" % (name,food,i))
# 存储生产的数据
q.put(food + str(i)) if __name__ == "__main__":
q = Queue()
# 消费者
p1 = Process(target=consumer,args=(q,"宋云杰"))
# 生产者
p2 = Process(target=producer,args=(q,"马生平","黄瓜")) p1.start()
p2.start() # 在生产者生产完所有数据之后,在队列的末尾添加一个None
p2.join()
# 添加None
q.put(None)
优化版和普通版有什么不同呢?

运行结果如下图所示

JoinableQueue
1.前戏
上面的生产者-消费者模型只是针对于一个生产者和一个消费者
那如果是多个生产者和多个消费者呢?
2.JoinableQueue基本语法
put 存储
get 获取
task_done
join
task_done 和 join 配合使用的
队列中 1 2 3 4 5
put 一次 内部的队列计数器加1
get 一次 通过task_done让队列计数器减1
join函数,会根据队列计数器来判断是阻塞还是放行
队列计数器 = 0 , 意味着放行
队列计数器 != 0 , 意味着阻塞
jq =JoinableQueue()
jq.put("a") # 向队列中存储一个a 并且队列计数器会加1
print(jq.get()) # 取出队列的a并打印
jq.task_done() # 通过task_done让队列计数器减1,此时队列计数器为0
jq.join() # 队列计数器为0,放行,打印下面的内容
print("finish")
3.用JoinableQueue优化生产者-消费者模型
def consumer(q, name):
while True:
food = q.get()
time.sleep(random.uniform(0.1, 1))
print("%s 吃了一个%s" % (name, food))
# 当队列计数器减到0的时,意味着进程队列中的数据消费完毕
q.task_done() # 生产者模型
def producer(q, name, food):
for i in range(5):
time.sleep(random.uniform(0.1, 1))
# 打印生产的数据
print("%s 生产了 %s%s" % (name, food, i))
# 存储生产的数据
q.put(food + str(i)) if __name__ == "__main__":
q = JoinableQueue()
# 消费者
p1 = Process(target=consumer, args=(q, "宋云杰"))
p3 = Process(target=consumer, args=(q, "李博伦"))
# 生产者
p2 = Process(target=producer, args=(q, "马生平", "黄瓜")) # 设置p1消费者为守护进程
p1.daemon = True
p3.daemon = True
p1.start()
p2.start()
p3.start() # 把所有生产者生产的数据存放到进程队列中
p2.join()
# 为了保证消费者能够消费完所有数据,加上队列.join
# 当队列计数器减到0的时,放行,不在阻塞,程序彻底结束.
q.join()
print("程序结束 ... ")
运行结果如下图所示

Manager:进程之间共享数据
def work(data,lock):
# 1.正常写法
# 上锁
lock.acquire()
# 修改数据
data["count"] -= 1
# 解锁
lock.release()
# 2.使用with语法可以简化上锁和解锁两步操作
with lock:
data[0] += 1
if __name__ == "__main__":
lst = []
lock = Lock()
m = Manager()
data = m.dict( {"count":20000} )
data = m.list( [1,2,3] )
for i in range(50):
p = Process(target=work,args=(data,lock))
p.start()
lst.append(p)
# 确保所有进程执行完毕之后,在向下执行,打印数据,否则报错.
for i in lst:
i.join()
print(data)
day33:进程锁&事件&进程队列&进程间共享数据的更多相关文章
- Swoole 中使用 Table 内存表实现进程间共享数据
背景 在多进程模式下进程之间的内存是相互隔离的,在一个工作进程中的全局变量和超全局变量,在另一个工作进程中是无法读取和操作的. 如果只有一个工作进程,则不存在进程隔离问题,可以使用全局变量和超全局变量 ...
- python 进程间共享数据 (二)
Python中进程间共享数据,除了基本的queue,pipe和value+array外,还提供了更高层次的封装.使用multiprocessing.Manager可以简单地使用这些高级接口. Mana ...
- python 进程间共享数据 (一)
def worker(num, mystr, arr): num.value *= 2 mystr.value = "ok" for i in range(len(arr)): a ...
- 【转】VC 利用DLL共享区间在进程间共享数据及进程间广播消息
1.http://blog.csdn.net/morewindows/article/details/6702342 在进程间共享数据有很多种方法,剪贴板,映射文件等都可以实现,这里介绍用DLL的共享 ...
- 使用DLL在进程间共享数据
0x01 DLL在进程间共享数据理论 1.可以在Dll中使用#pragma data_seg建立共享类型的数据段将需要共享的数据分离出来,放置在一个独立的数据段里,并把该段的属性设置为共享,从而实现不 ...
- 使用 WM_COPYDATA 在进程间共享数据
开发中有时需要进程间传递数据,比如对于只允许单实例运行的程序,当已有实例运行时,再次打开程序,可能需要向当前运行的实例传递信息进行特殊处理.对于传递少量数据的情况,最简单的就是用SendMessage ...
- 进程间共享数据Manager
一.前言 进程间的通信Queue()和Pipe(),可以实现进程间的数据传递.但是要使python进程间共享数据,我们就要使用multiprocessing.Manager. Manager()返回的 ...
- 【C++】DLL内共享数据区在进程间共享数据(重要)
因项目需要,需要在DLL中共享数据,即DLL中某一变量只执行一次,在运行DLL中其他函数时该变量值不改变:刚开始想法理解错误,搜到了DLL进程间共享数据段,后面发现直接在DLL中定义全局变量就行,当时 ...
- windows核心编程之进程间共享数据
有时候我们会遇到window进程间共享数据的需求,例如说我想知道系统当前有多少某个进程的实例. 我们能够在程序中定义一个全局变量.初始化为0.每当程序启动后就加1.当然我们我们能够借助第三方介质来储存 ...
- Python multiprocessing.Manager介绍和实例(进程间共享数据)
Python中进程间共享数据,处理基本的queue,pipe和value+array外,还提供了更高层次的封装.使用multiprocessing.Manager可以简单地使用这些高级接口. Mana ...
随机推荐
- 如何卸载cad 2022?怎么把cad 2022彻底卸载删除干净重新安装的方法【转载】
标题:cad 2022重新安装方法经验总结,利用卸载清理工具完全彻底排查删除干净cad 2022各种残留注册表和文件.cad 2022显示已安装或者报错出现提示安装未完成某些产品无法安装的问题,怎么完 ...
- ubuntu安装软件报依赖关系错误
1.环境 Distributor ID: UbuntuDescription: Ubuntu 20.04.1 LTSRelease: 20.04Codename: focal 2.安装 报错 3.解决 ...
- echarts图表自适应屏幕/浏览器窗口大小
昨天完成echarts柱状图的生成,突然发现在项目中还有个小缺陷,当柱状图完成渲染之后,放大缩小浏览器窗口echarts柱状图宽度没有随之改变. 接昨天的代码做了小调整: setTimeout(fun ...
- 关于VScode里TS文件内引入插件没有提示内置属性和方法这件事
前几天使用VScode + Vue + Vite + Ts开发项目 由于自己手残 把VScode设置文件的代码做了一些修改 导致TS文件引入的插件没有提示了!! 几经折腾下 终于靠自己解决了! 不多说 ...
- FHAdmin实战获取shell
又是一个愉快的摸鱼的一天,闲来无事去逛先知社区突然看到了一篇名为shrio权限实战绕过的文章(https://xz.aliyun.com/t/8311),这时不禁突然 回想起来之前看到过的一个微信公众 ...
- npm proxy问题
检查你的电脑是否需要配置代理,如果不需要可以将代理禁用: npm config set proxy false 如果是需要配置代理服务的: 开启代理 npm config set proxy true ...
- java: javacTask: 源发行版 8 需要目标发行版 1.8
idea同一工作空间中不同工程使用不同的jkd版本.在本地idea同时使用jdk1.7和jdk1.8,不同的java工程使用不同的jdk版本,但是在java代码编译时报错,其报错信息为:[java: ...
- html、css、js 压缩或混淆方法
普通的压缩代码的方法包括在线工具和服务器打包处理,有一个共同的痛点是:压缩后的代码无法还原成原始的带有注释的源代码.正如大家所知,在源代码中调试Bug事半功倍.在线工具HCJCompress(ihon ...
- 前端程序员需要了解的MySQL
数据库的基本概念 数据库(database)是用来组织.存储和管理数据的仓库.对数据库中的数据可以进行增删改查操作.市面上常见的数据库有: MySQL(使用最广泛.流行度最高的开源免费数据库 Comm ...
- Android笔记--常用布局
线性布局--LinearLayout 线性布局的方向 orientation属性值:若为horizontal,内部视图在水平方向从左往右排列 若为vertical,内部视图在垂直方向从上往下排列 如果 ...