【深入浅出 Yarn 架构与实现】3-3 Yarn Application Master 编写
本篇文章继续介绍 Yarn Application 中 ApplicationMaster 部分的编写方法。
一、Application Master 编写方法
上一节讲了 Client 提交任务给 RM 的全流程,RM 收到任务后,由 ApplicationsManager 向 NM 申请 Container,并根据 Client 提供的 ContainerLaunchContext 启动 ApplicationMaster。
本篇代码已上传 Github:
Github - MyApplicationMaster
一)整体流程
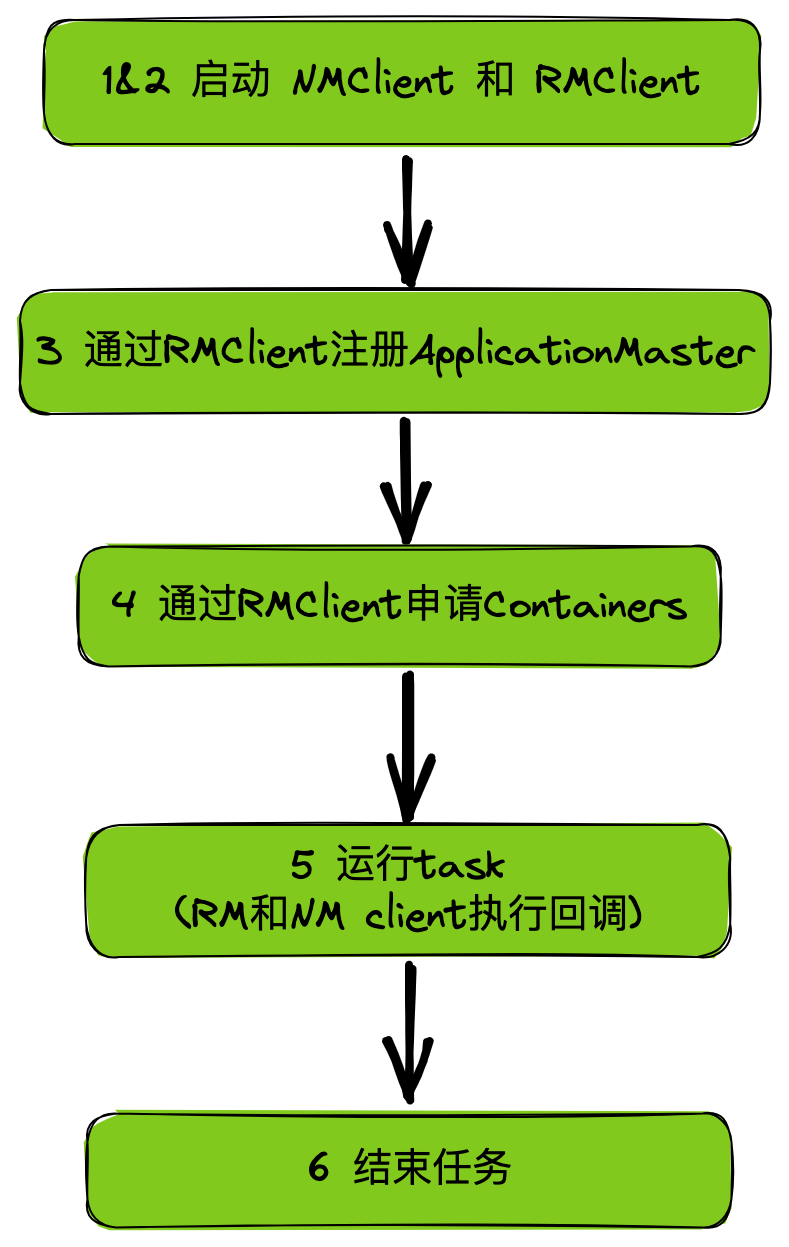
1&2、启动 NMClient 和 RMClient
在 AM 中需要分别启动 NMClient 和 RMClient 进行通信。
两个客户端中都注册了我们自定义的 eventHandler,将会在后面进行介绍。
在 amRMClient 中会定义 AM 向 RM 定时发送心跳的间隔。(在 RM 中会有心跳容忍时间,注意不要超过 RM 配置的时间)
// logInformation();
Configuration conf = new Configuration();
// 1 create amRMClient
// 第一个参数是心跳时间 ms
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, new RMCallbackHandler());
amRMClient.init(conf);
amRMClient.start();
// 2 Create nmClientAsync
amNMClient = new NMClientAsyncImpl(new NMCallbackHandler());
amNMClient.init(conf);
amNMClient.start();
3、向 RM 注册 ApplicationMaster
// 3 register with RM and this will heart beating to RM
RegisterApplicationMasterResponse response = amRMClient
.registerApplicationMaster(NetUtils.getHostname(), -1, "");
4、申请 Containers
首先需要从 response 中确认资源池剩余资源,然后再根据需求申请 container
// 4 Request containers
response.getContainersFromPreviousAttempts();
// 4.1 check resource
long maxMem = response.getMaximumResourceCapability().getMemorySize();
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
// 4.2 request containers base on avail resource
for (int i = 0; i < numTotalContainers.get(); i++) {
ContainerRequest containerAsk = new ContainerRequest(
//100*10M + 1vcpu
Resource.newInstance(100, 1), null, null,
Priority.newInstance(0));
amRMClient.addContainerRequest(containerAsk);
}
5、运行任务
将在 RMCallbackHandler 中的 onContainersAllocated 回调函数中处理,并在其中调用 NMCallbackHandler 的方法,执行对应的 task。
(RMCallbackHandler、NMCallbackHandler将在后面进行详细介绍。)
// RMCallbackHandler
public void onContainersAllocated(List<Container> containers) {
for (Container c : containers) {
log.info("Container Allocated, id = " + c.getId() + ", containerNode = " + c.getNodeId());
// LaunchContainerTask 实现在下面
exeService.submit(new LaunchContainerTask(c));
}
}
private class LaunchContainerTask implements Runnable {
@Override
public void run() {
// ……
// 发送事件交给 nm 处理
amNMClient.startContainerAsync(container, ctx);
}
}
6、结束任务
当全部子任务完成后,需要做收尾工作,将 amNMClient 和 amRMClient 停止。
while(numTotalContainers.get() != numCompletedContainers.get()){
try{
Thread.sleep(1000);
log.info("waitComplete" +
", numTotalContainers=" + numTotalContainers.get() +
", numCompletedConatiners=" + numCompletedContainers.get());
} catch (InterruptedException ex){}
}
log.info("ShutDown exeService Start");
exeService.shutdown();
log.info("ShutDown exeService Complete");
amNMClient.stop();
log.info("amNMClient stop Complete");
amRMClient.unregisterApplicationMaster(FinalApplicationStatus.SUCCEEDED, "dummy Message", null);
log.info("unregisterApplicationMaster Complete");
amRMClient.stop();
log.info("amRMClient stop Complete");
二)NMClient 和 RMClient Callback Handler 编写
1、RMCallbackHandler
本质是个 eventHandler,对事件库不熟悉的同学可以翻之前的文章「2-3 Yarn 基础库 - 服务库与事件库」进行学习。
其会处理 Container 启动、停止、更新等事件。
收到不同的事件时,会执行相应的回调函数。这里仅给出两个函数的实现。
思考:之前版本中(2.6之前)还是实现 CallbackHandler 接口,为何后面改为了抽象类?
A:对原接口有了扩展增加了方法 onContainersUpdated。推测是因为避免使用接口继承。
private class RMCallbackHandler extends AMRMClientAsync.AbstractCallbackHandler {
@Override
public void onContainersCompleted(List<ContainerStatus> statuses) {
for (ContainerStatus status : statuses) {
log.info("Container completed: " + status.getContainerId().toString()
+ " exitStatus=" + status.getExitStatus());
if (status.getExitStatus() != 0) {
log.error("Container return error status: " + status.getExitStatus());
log.warn("Need rerun container!");
// do something restart container
continue;
}
ContainerId containerId = status.getContainerId();
runningContainers.remove(containerId);
numCompletedContainers.addAndGet(1);
}
}
@Override
// 这里在 container 中启动相应的 task
public void onContainersAllocated(List<Container> containers) {
for (Container c : containers) {
log.info("Container Allocated, id = " + c.getId() + ", containerNode = " + c.getNodeId());
// LaunchContainerTask 实现在下面
exeService.submit(new LaunchContainerTask(c));
}
}
// 其他方法实现……
}
private class LaunchContainerTask implements Runnable {
Container container;
public LaunchContainerTask(Container container) {
this.container = container;
}
@Override
public void run() {
LinkedList<String> commands = new LinkedList<>();
commands.add("sleep " + sleepSeconds.addAndGet(1));
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(null, null, commands, null, null, null);
// 这里去执行 amNMClient 的回调
amNMClient.startContainerAsync(container, ctx);
}
}
2、NMCallbackHandler
定义 nm container 需要执行的各种事件处理。
private class NMCallbackHandler extends NMClientAsync.AbstractCallbackHandler {
@Override
public void onContainerStarted(ContainerId containerId, Map<String, ByteBuffer> allServiceResponse) {
log.info("Container Stared " + containerId.toString());
}
// ……
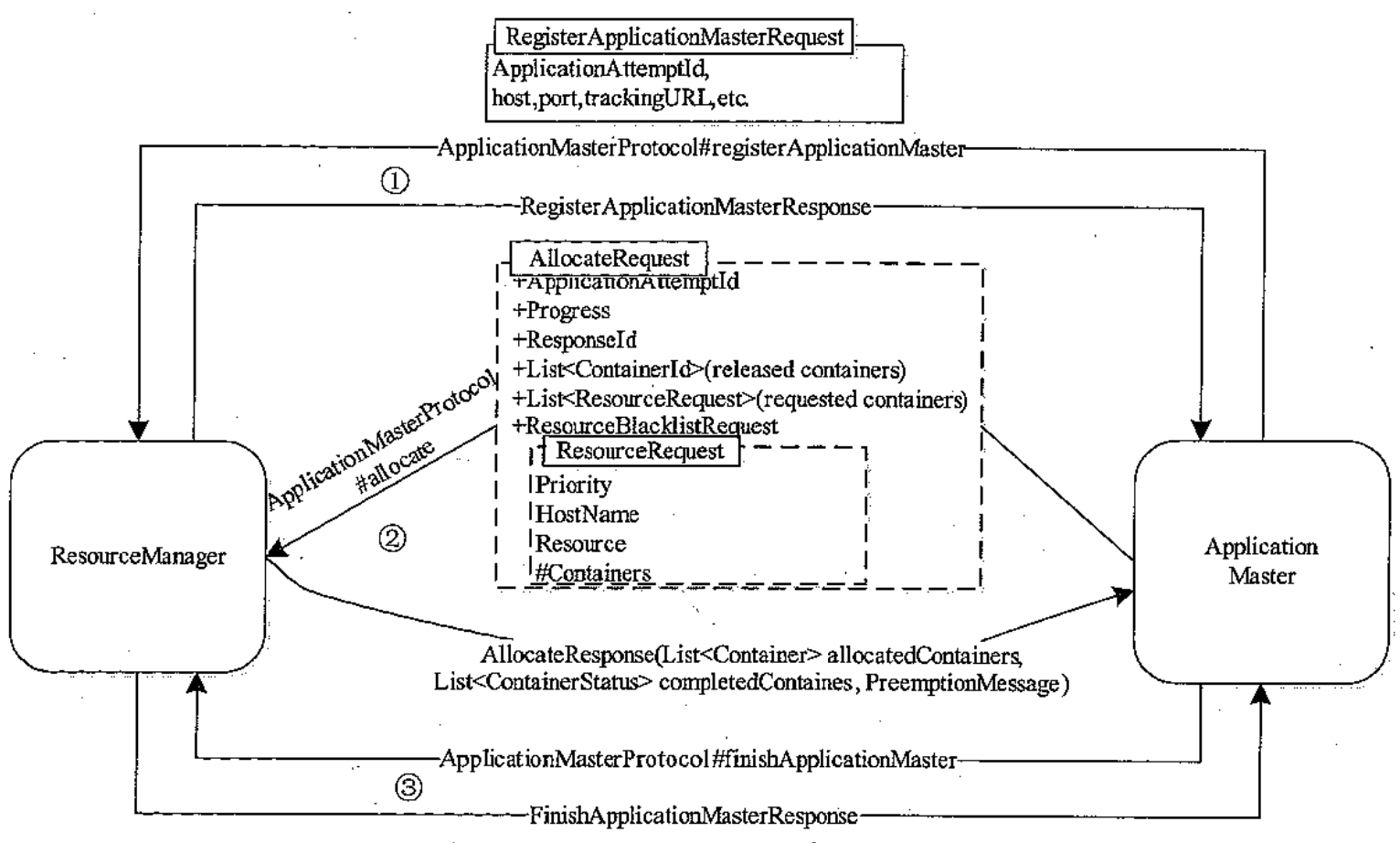
三)涉及的通信协议
AM 与 RM
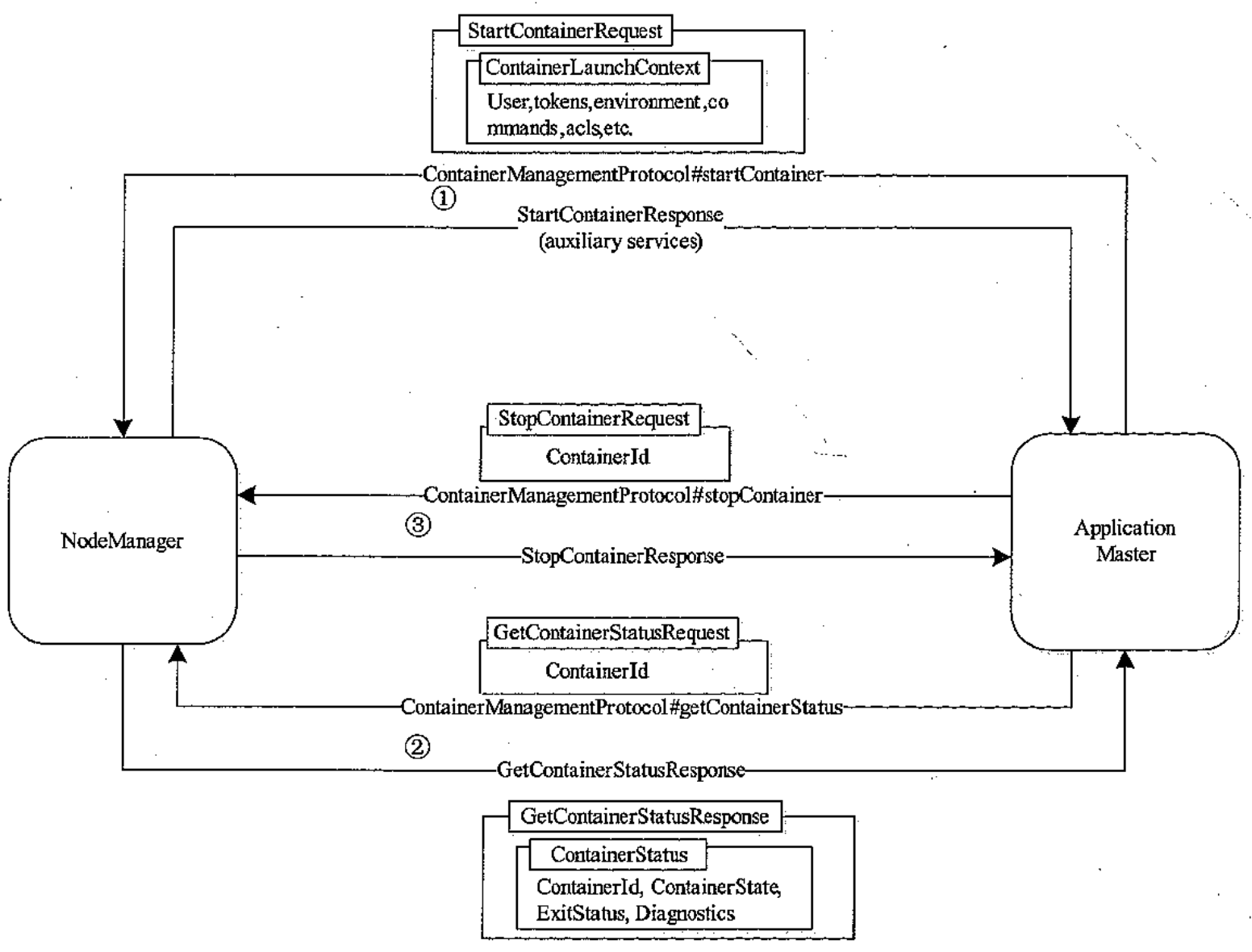
AM 与 NM
二、小结
至此我们学习了编写 Yarn Application 的整体流程和实现方法,相信各位同学对其有了更深的认识。之后可以从 hadoop 提供的 DistributedShell 入手,再到其他框架(Hive、Flink)等探究工业级框架是如何提交 Application 的。
参考文章:
Hadoop Doc: Writing an ApplicationMaster (AM)
《Hadoop 技术内幕 - 深入解析 Yarn 结构设计与实现原理》第四章
【深入浅出 Yarn 架构与实现】3-3 Yarn Application Master 编写的更多相关文章
- 【深入浅出 Yarn 架构与实现】3-1 Yarn Application 流程与编写方法
本篇学习 Yarn Application 编写方法,将带你更清楚的了解一个任务是如何提交到 Yarn ,在运行中的交互和任务停止的过程.通过了解整个任务的运行流程,帮你更好的理解 Yarn 运作方式 ...
- 【深入浅出 Yarn 架构与实现】2-1 Yarn 基础库概述
了解 Yarn 基础库是后面阅读 Yarn 源码的基础,本节对 Yarn 基础库做总体的介绍.并对其中使用的第三方库 Protocol Buffers 和 Avro 是什么.怎么用做简要的介绍. 一. ...
- 【深入浅出 Yarn 架构与实现】2-2 Yarn 基础库 - 底层通信库 RPC
RPC(Remote Procedure Call) 是 Hadoop 服务通信的关键库,支撑上层分布式环境下复杂的进程间(Inter-Process Communication, IPC)通信逻辑, ...
- 【深入浅出 Yarn 架构与实现】2-3 Yarn 基础库 - 服务库与事件库
一个庞大的分布式系统,各个组件间是如何协调工作的?组件是如何解耦的?线程运行如何更高效,减少阻塞带来的低效问题?本节将对 Yarn 的服务库和事件库进行介绍,看看 Yarn 是如何解决这些问题的. 一 ...
- 【深入浅出 Yarn 架构与实现】2-4 Yarn 基础库 - 状态机库
当一个服务拥有太多处理逻辑时,会导致代码结构异常的混乱,很难分辨一段逻辑是在哪个阶段发挥作用的. 这时就可以引入状态机模型,帮助代码结构变得清晰. 一.状态机库概述 一)简介 状态机由一组状态组成: ...
- 【深入浅出 Yarn 架构与实现】1-1 设计理念与基本架构
一.Yarn 产生的背景 Hadoop2 之前是由 HDFS 和 MR 组成的,HDFS 负责存储,MR 负责计算. 一)MRv1 的问题 耦合度高:MR 中的 jobTracker 同时负责资源管理 ...
- 【深入浅出 Yarn 架构与实现】1-2 搭建 Hadoop 源码阅读环境
本文将介绍如何使用 idea 搭建 Hadoop 源码阅读环境.(默认已安装好 Java.Maven 环境) 一.搭建源码阅读环境 一)idea 导入 hadoop 工程 从 github 上拉取代码 ...
- Spark on Yarn 架构解析
. 一.Hadoop Yarn组件介绍: 我们都知道yarn重构根本的思想,是将原有的JobTracker的两个主要功能资源管理器 和 任务调度监控 分离成单独的组件.新的架构使用全局管理所有应用程序 ...
- Yarn集群的搭建、Yarn的架构和WordCount程序在集群提交方式
一.Yarn集群概述及搭建 1.Mapreduce程序运行在多台机器的集群上,而且在运行是要使用很多maptask和reducertask,这个过程中需要一个自动化任务调度平台来调度任务,分配资源,这 ...
- Yarn架构详解
Yarn架构介绍Yarn/MRv2最基本的想法是将原JobTracker主要的资源管理和job调度/监视功能分开作为两个单独的守护进程.有一个全局的ResourceManager(RM)和每个Appl ...
随机推荐
- Python之创建数据库及功能示例样本
创建数据库实例 import pymysql db= pymysql.connect(host="localhost",user="root",password ...
- APICloud如何对接大牛直播SDK
随着apicloud的普及,越来越多的用户苦于apicloud下没有一款真正靠谱低延迟的rtmp/rtsp直播播放器苦恼. 鉴于此,大牛直播SDK携手apicloud资深版主,推出apicloud对接 ...
- windows清理必看
清理缓存 代码如下 介绍此文件夹都是缓存文件全选删除即可 ctrl+A全选shift+del强制删除(不会添加到回收站) %temp% 找到C盘右击属性选择想要删除的文件进行清理即可 清理完点击清理系 ...
- 阿色全息脑图,及制作软件AHMM
阿色全息脑图 AHMM 全息脑图是按照大系统观原理开发的新型思维工具,用于升维思考. 让您以系统的观点看待世界,专注系统的结构信息--全息,抓住事物的本质,透过表象和数据发现规律. 世间每项事物都是一 ...
- Windows打印服务器上无法删除打印机
这几天遇到了一个问题,在Windows 2008的打印服务器上的打印机无法删除.具体表现是可以在设备和打印机里删除打印机,然后刷新一下,它们又出来了.这些打印机早就不存在了,并且这些打印机的图标呈半透 ...
- 视频结构化 AI 推理流程
「视频结构化」是一种 AI 落地的工程化实现,目的是把 AI 模型推理流程能够一般化.它输入视频,输出结构化数据,将结果给到业务系统去形成某些行业的解决方案. 换个角度,如果你想用摄像头来实现某些智能 ...
- K8s 上的分布式存储集群搭建(Rook/ceph)
转载自:https://mp.weixin.qq.com/s/CdLioTzU4oWI688lqYKXUQ 1 环境准备 1.1 基础环境 3台配置一致的虚拟机 虚拟机配置:4c 8g 虚拟机操作系统 ...
- 连接Vue.js作为前端,Fastapi作为后端
项目结构 ├── main.py └── templates └── home.html 环境安装 pip install fastapi[all] pip install jinja2 Backen ...
- KVM里安装不是原装的winxp系统镜像
从网上下载的winxp系统镜像,虽然是iso格式的,但是里面的内容是如下情况的 因此安装的话,需要采取如下步骤 1.添加一个光驱引导,挂载一个iso格式的pe 2.再添加一个光驱,挂载iso格式的wi ...
- 使用coverlet统计单元测试的代码覆盖率
单元测试是个好东西, 可以在一定程度上兜底 虽然写单元测试这件事情非常麻烦 但是好的单元测试可以显著提高代码质量, 减少bug, 避免无意中的修改导致其他模块出错 写测试用例的过程中, 靠人力去确保所 ...