Nebula Graph 在网易游戏业务中的实践
{kind=link}

当游戏上知识图谱,网易游戏是如何应对大规模图数据的管理问题,Nebula Graph 又是如何帮助网易游戏落地游戏内复杂的图的业务呢?在本文,我们来一探究竟。
游戏中的图数据
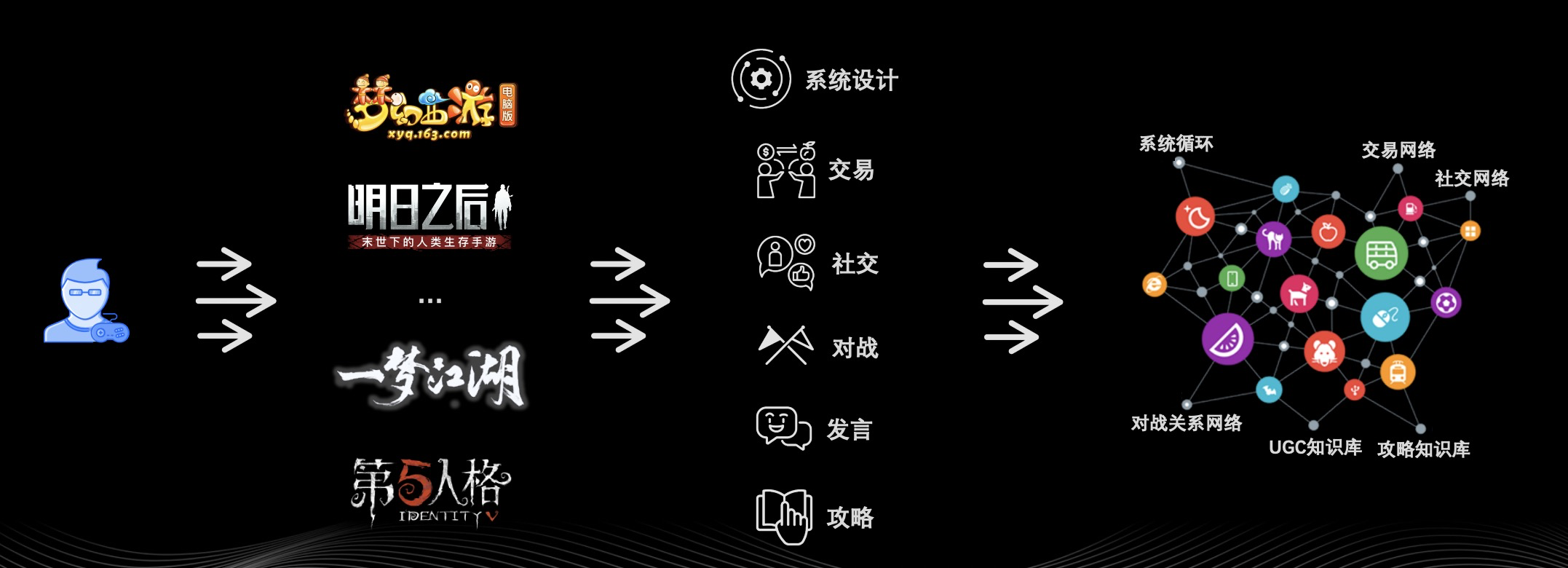
目前网易游戏大部分的产品都是在线游戏,作为国际领先的头部游戏厂商,网易所吸引的在线玩家数量也是众多的,那么大量的玩家登录我们的游戏势必产生大量各种操作性数据。
如上图中间显示的交易数据——玩家可以购买商城里的物品,或者直接购买其他玩家的物品;社交数据——加好友、点赞、刷礼物等等,有些游戏中还会存在婚姻系统。此外,还有常见的对战系统、发言系统——玩家在频道内发表自己的见解,或者是整理自己的游戏经验变成游戏攻略。
对游戏设计和开发人员而言,各个游戏内的系统都需要保证资源可以在系统内部正常的循环和流转,以保证游戏生态的平稳运行,我们称之为系统循环。系统设计的话,它会产生系统循环图,交易会产生交易网络,社交会产生社交网络,对战会产生对战关系网络,发言会产生 UGC 知识库,产出攻略则会形成攻略知识库。
这些丰富多样的图数据就是游戏中无处不在的图。
简单来感受下网易游戏玩家在游戏中感受到的图:
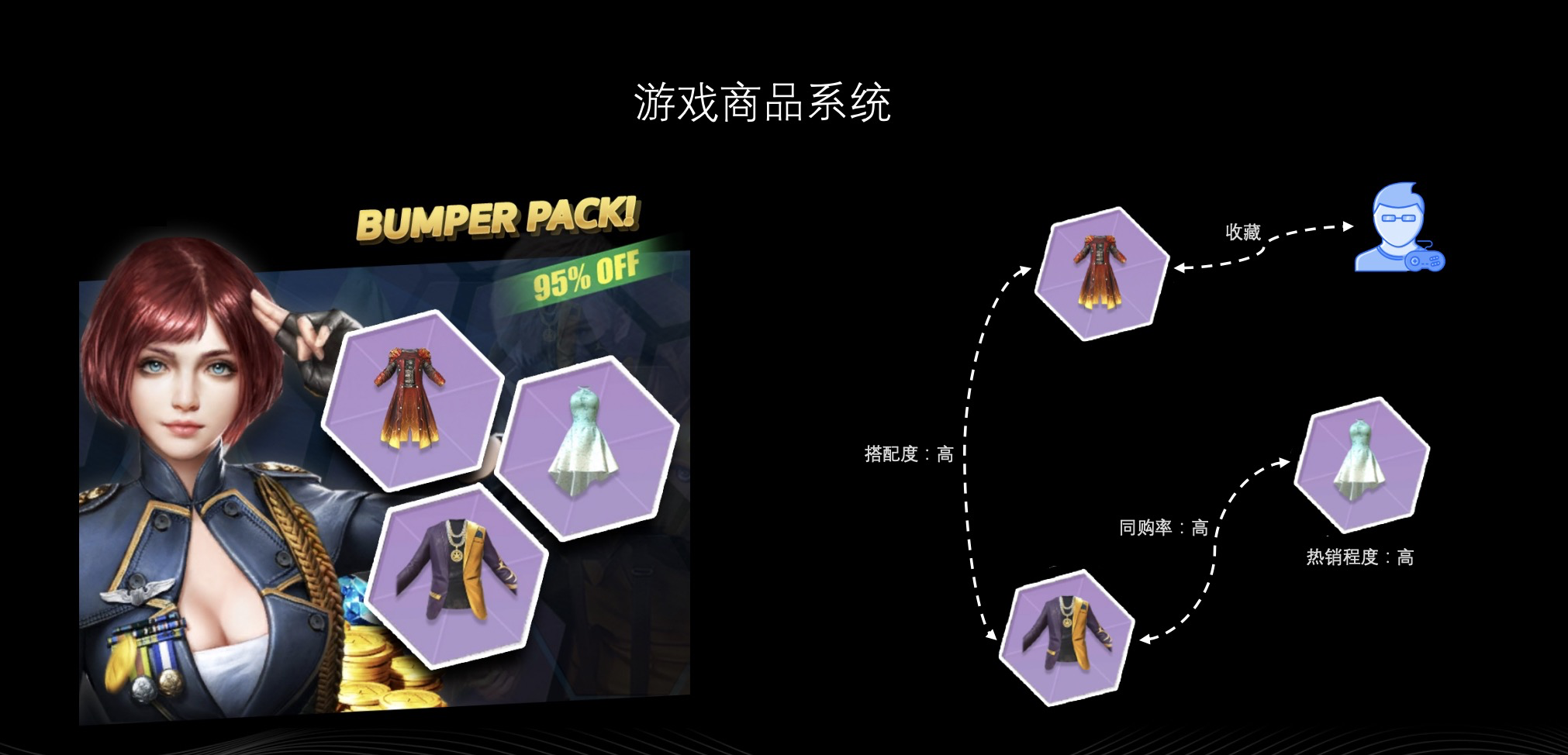
上图是某款游戏的商品系统,不知道 Nebula 的小伙伴有没有喜欢收集皮肤,可能你玩的游戏中会推送一些皮肤礼包,礼包里会有若干件皮肤,但你想过没有礼包里的皮肤是随机选取的吗?肯定不是,作为游戏制作方自然希望把好看的皮肤进行搭配,将不同玩家喜欢的皮肤放在一起推送给玩家。这时候,各个皮肤之间、皮肤与玩家之间便会产生联系。像上图右边的例子,玩家可能表达过对某件皮肤的喜欢,而它又和另一件皮肤比较搭,此时搭配第三件皮肤,从第三件皮肤的销售情况中了解到,它与先前的两件皮肤有比较高的同时购买率,那么,这个时候通过图结构可将这三件皮肤进行关联,形成礼包推送给玩家,此时玩家对礼包的接受度和可能喜爱程度会更高。
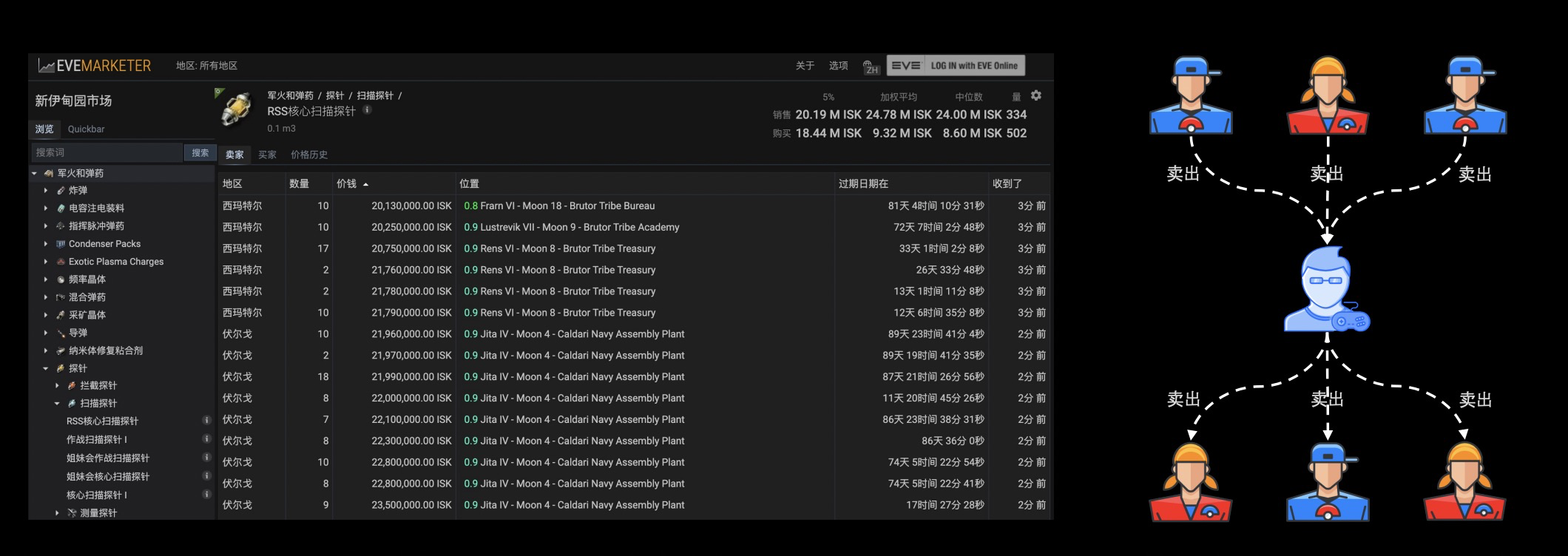
上图是某款游戏里的交易系统,网易旗下的有些游戏非常注重资源的流通性,玩家可以采集各种资源,并且销售给其他玩家来获取利益。此外,玩家也可以选择做一名中间商,直接倒卖资源,赚取差价。一般来说,游戏制造方都鼓励玩家进行这种主动的资源交换,因为这会维持游戏生态的繁荣和稳定之余给玩家带去实际收益。但不能忽略的是当中存在非法交易,这些非法交易玩家会成立黑色的组织工作室,盗取他人的账号,或者欺骗他人,将游戏内的资源转移给组织控制的黑产账号,再在黑产账号里面销赃,去攫取非法收益。像这种破坏其他玩家游戏体验和游戏生态的行为,游戏制作方一直在进行高压的打击。
刚说到非法交易的黑产链路,当中识别黑产销赃账号便是打击非法交易的关键。像上图右侧所示,它是个黑色账号的交易行为形成的特殊图结构,一般来说黑色账号会过多地从其他玩家那里以低于市场的价格来获取大量资源,又转手卖出去,以这样的图结构进行辅助判断,再结合其他的防黑产识别方式,就可以对黑产、黑色账号进行比较精确的识别。
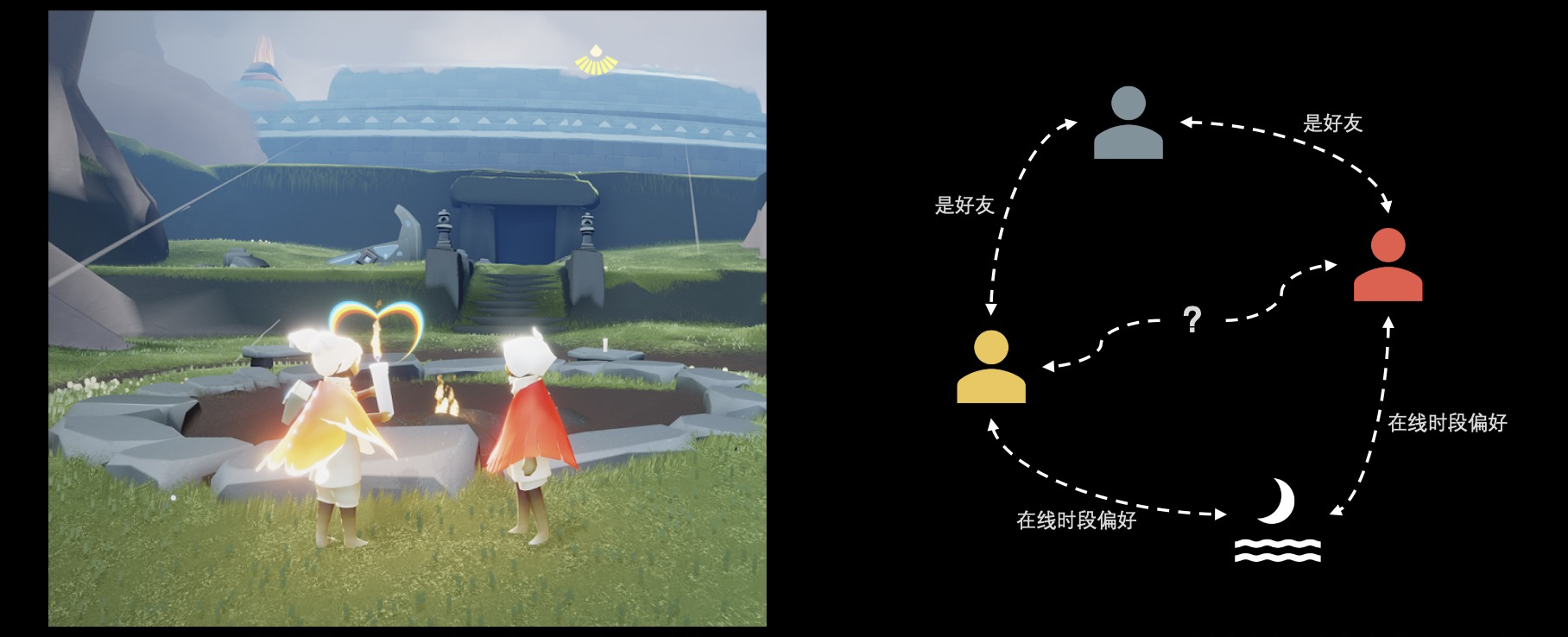
再看社交系统,简单来说社交系统就是撮合原本陌生的人相互认识,再通过互动交流让他们产生深厚的友情甚至爱情。那么,怎么撮合陌生人认识便是关键,像上图的小黄和小红,互相不认识。假如他们在游戏内有一个甚至多个共同好友,此外,他们偏好的游戏在线时段也一致都喜欢大半夜上线开黑。这个时候,基于这样的图结构,大家心中应该已经有了简单的答案:应该撮合小黄和小红相互认识。

游戏中还有对战匹配系统,MOBA(英文全称:Multiplayer Online Battle Arena)可能是大家常玩的一种游戏类型。玩过这类游戏的玩家应该深有体会,MOBA 里面匹配到的队友水平对单场游戏体验发挥着至关重要的作用。那么,怎么给玩家匹配到更可能“不坑”的队友,让玩家开心地推塔对线呢?像上图,为什么会将蓝色玩家和红色玩家匹配到一起游戏呢?当中的产品逻辑也许是蓝色玩家的偏好位置是下路,红色玩家的偏好位置是辅助,这两个位置是绝佳的搭配。而他们又恰好在先前的某次游戏里组过队并且获胜了,加上他们又处于同一段位水平。这个时候,根据这样的图结构提示,把小蓝和小红匹配到一起,他们俩在一起的游戏体验想必也不会太差。
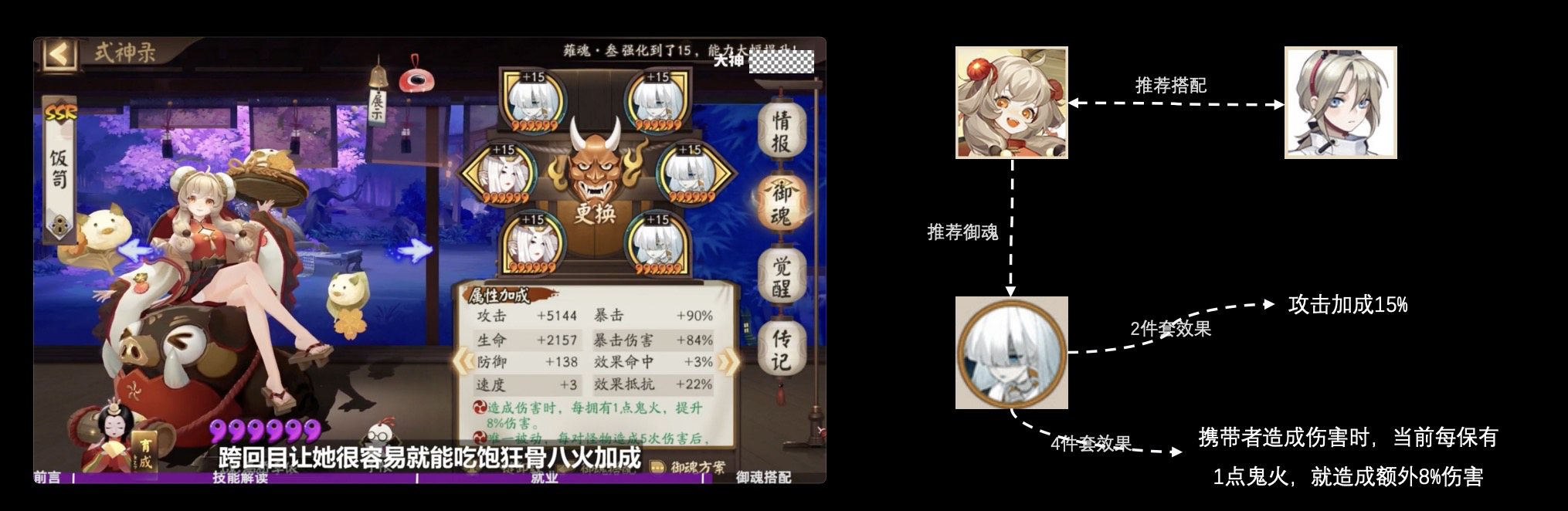
最后,来看一下游戏的攻略系统,当前大多游戏的攻略是由游戏运营人员或者游戏社区内的 KOL,主动去输出、整理到各类游戏平台。他们产出的游戏攻略质量其实都很高,但因为内容发布渠道比较分散,不易被玩家简单地浏览、查询,造成攻略的资源浪费。假如我们对这些攻略进行专家知识采集或者说知识抽取,形成攻略知识库,把攻略知识库接入游戏内的提示、问答模块。当玩家产生疑问遇到困难时,像上图那样,如果玩家不知道怎么给饭笥搭配御魂或者其他式神进行对战,这时候游戏系统可以根据攻略图结构直接给出饭笥的搭配式神和御魂,并基于这个子图进一步扩展,给出搭配式神和御魂的其他的信息以便玩家获得更好的游戏体验。
数据即服务
经过上面的例子,想必大家对网易游戏的各类图数据形式有了一定了解。在百款网易游戏的持续迭代更新下以及新游戏产品的上线的情况下,势必会产生非常大规模的图数据,那我们团队是如何管理这样大规模的图数据,又是如何将这些数据利用好,将数据转化有效服务的呢?在接下来这部分将会进行介绍。
在网易游戏内部管理海量游戏数据,不得不先提到诺亚平台,本次分享介绍的图数据管理和图服务也是站在诺亚平台巨人的肩膀上进行的。
网易·诺亚平台
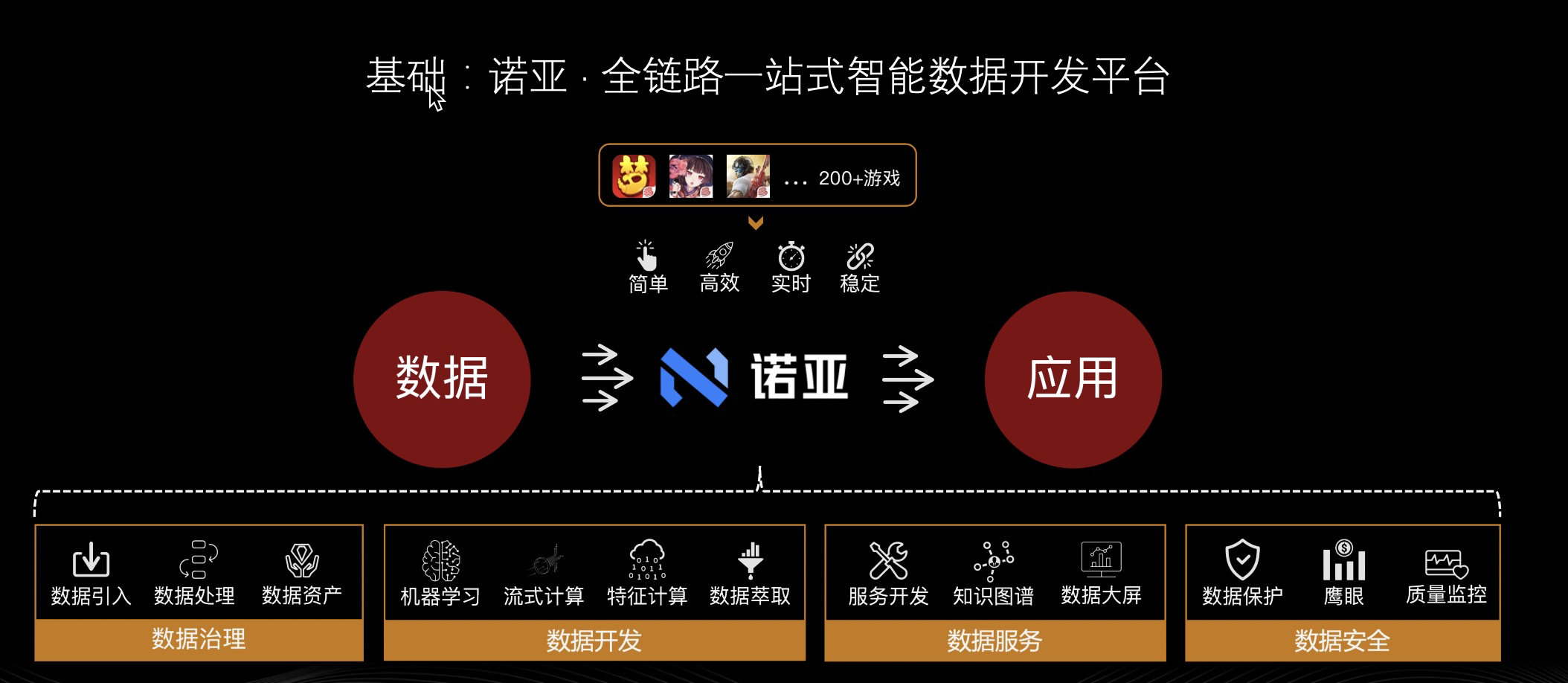
诺亚作为网易游戏数据中台的核心开发引擎,已经给公司内超过 200 款产品提供像上图所示的数据治理、数据开发、数据服务、数据安全等广泛而有深度的数据支撑。像数据治理它会有数据引入、数据处理、数据资产等模块;数据开发包含机器学习、流式计算、特征计算、数据萃取;数据服务的话,会有服务开发、数据大屏、知识图谱,这个是我们接下来会介绍的重点;数据安全的话,有数据保护、鹰眼、质量监控等各种各样的子功能、子模块。这些模块不仅提高了数据开发的效率和质量,还为产品开拓了新的业务形式。像大规模的在线游戏图数据管理工作,基于全链路一站式的智能数据开发平台诺亚,也在短时间体验到了它的高效。
技术选型
下面,进入喜闻乐见的“鞭打” JanusGraph 环节。
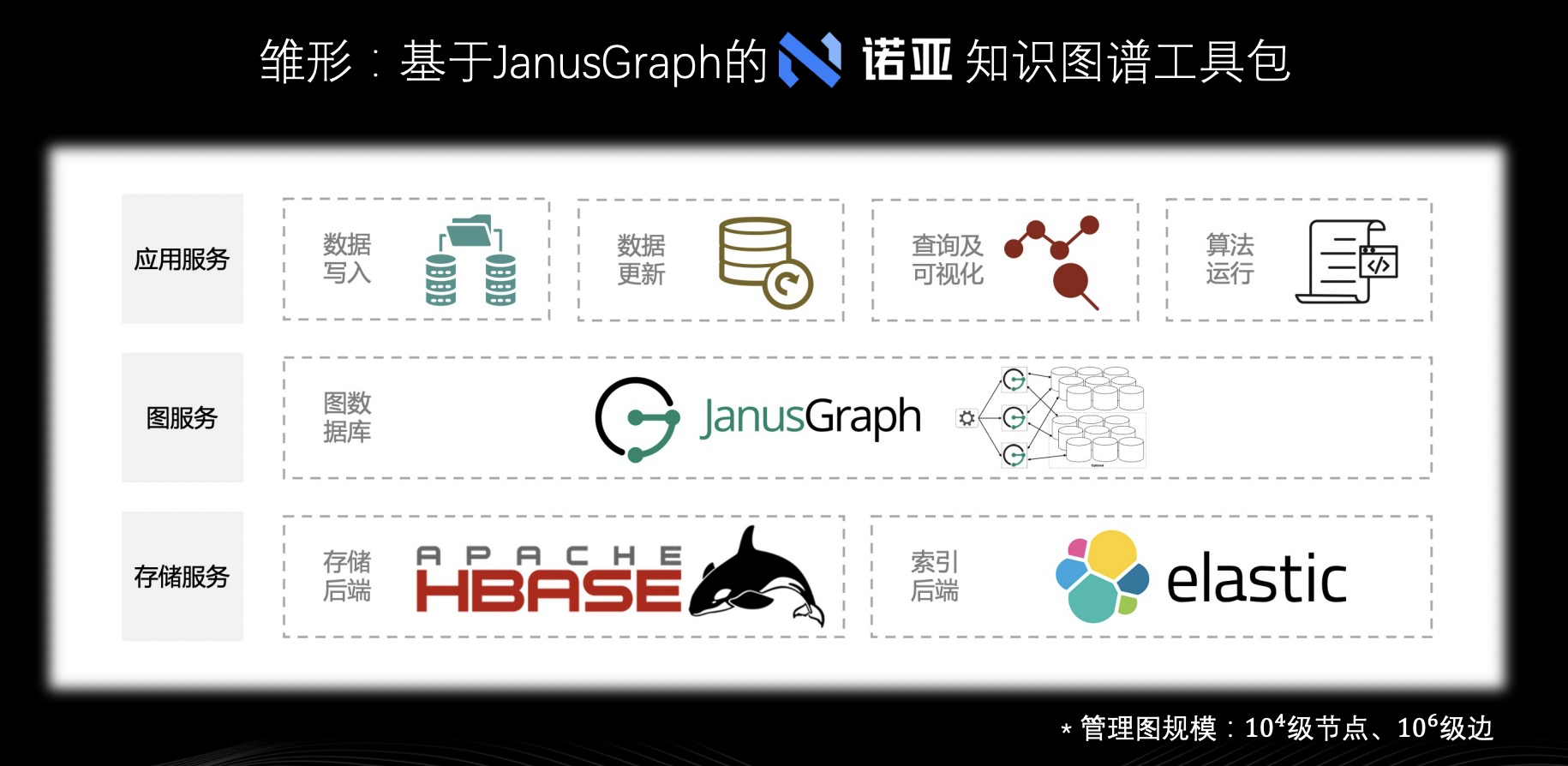
在图数据的管理和服务方面,一开始网易游戏并不是采用 Nebula Graph,而是 JanusGraph。想必很多用 JanusGraph 的技术团队都没有绕过一个坎,就是 JanusGraph 和它的衍生品。其实网易游戏也一样,在网易游戏图实践的初期因为图规模并不大,大约在 10^4 个节点和 10^6 条边量级。在这种小规模图数据的探索的阶段,网易游戏基于 JanusGraph 搭建如上图所示架构的知识图谱工具包。之所以叫做工具包,是因为系统架构比较简单,存储后端选用 HBase,索引后端选用 Elasticsearch。基于这种后端上层搭建 JanusGraph,再基于 JanusGraph 封装应用服务。这个工具包主要支撑图数据的写入,图数据的定时、定量更新,查询和可视化以及算法运行需求。
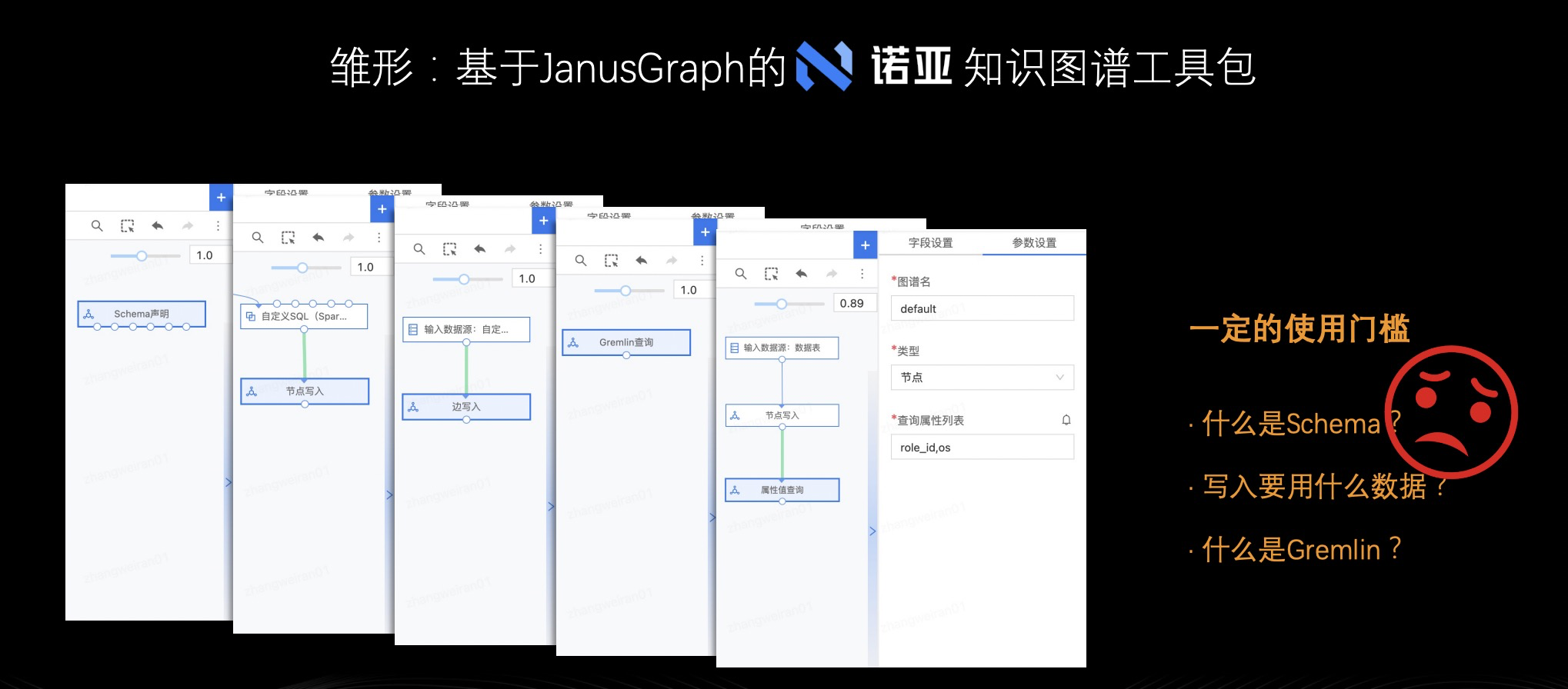
工具包包含各类节点,一个节点是一个基础操作的封装。比如说,你要创建一个知识图谱。首先是要声明图谱的结构,也就是 Schema,而诺亚平台封装 Schema 声明算子、节点写入算子、边写入算子(对应上图从左至右三张截图);在查询方面,诺亚封装了 JanusGraph 查询语言 Gremlin 算子;此外,网易游戏还开发自定义查询算子,比如你可以传入节点 ID 然后输出它的属性值。整个工具包的流程是用户在诺亚平台导入数据,连接(调用)各类算子后算子给出对应执行结果或者执行操作,某种程度上工具包满足了当时诺亚平台用户的需求。但,工具包其实是存在使用门槛:
- 了解 Schema:未接触知识图谱的用户对 Schema 不了解,不明白“什么是图谱的结构?”、“我为什么要设计图谱的结构?”、“我怎么去设计 Schema?”
- 数据正确写入:原始数据可能是数据表或者文本,如何组织数据才能顺利地写入到图里面;
- 图谱使用经验:用户可能没有图谱的使用经验,更不会用图数据库,这种情况下他可能不了解 Gremlin、查询语句也不会写,那么他就查不了数据;
以上都是知识图谱工具包的使用门槛问题。

此外,这个这个知识图谱工具包所用的可视化的组件为 GitHub 上开源的 janusgraph-visualization 。部署到服务器之后,如上图所示,顶部输入框中输入 Gremlin 查询语句,再填上服务器信息,系统会返回查询结果(上图左下角为返回数据)和查询结果示意图(上图蓝色球状图)。和之前说到的工具包基础操作封装类似,其实可视化组建这块也有使用门槛问题:第一个问题和节点使用类似,用户可能不会写 Gremlin。第二个问题,仔细查看上图左下角的结果返回数据,它诗歌结构化数据,给用户的信息启示性不足。最后一个问题,浏览器崩溃问题。所以,这套可视化系统的执行效率其实并不高。
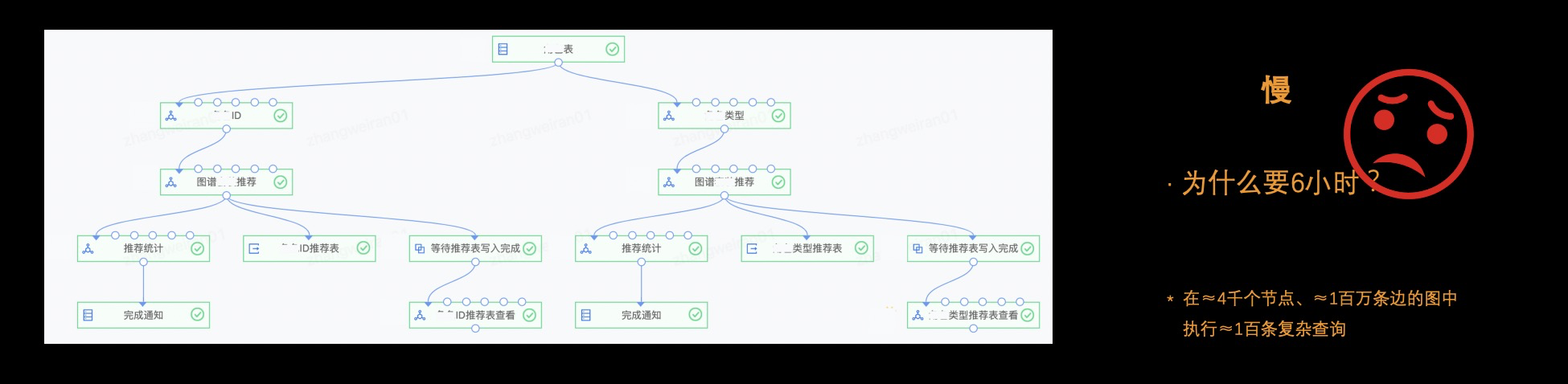
此外,这个知识图谱工具包封装了个性化算子,比如我们封装了用知识图谱实现推荐业务的常用逻辑,用户可以直接调用算子来实现推荐。但因为工具包底层依赖 JanusGraph,用过 JanusGraph 的小伙伴可能也有体会,它的执行速度会非常的慢。如上图所示,在 4,000 个节点和 100 万条边的图中去执行 100 条略复杂的查询,就要花费 6 个小时的时间,这种执行效率是不可接受的。
基于上述原因,经过一轮探索实践,JanusGraph 支撑的知识图谱工具包难以满足上层业务需求。简单来说:能用但门槛高,而且有硬伤,加上网易游戏图数据规模又越来越大,这种情况下难以支撑业务。又经过一段时间的调研探索,遇到了 Nebula Graph。基于 Nebula Graph 的特性,网易游戏对知识图谱基础设施和底层架构进行了重构。
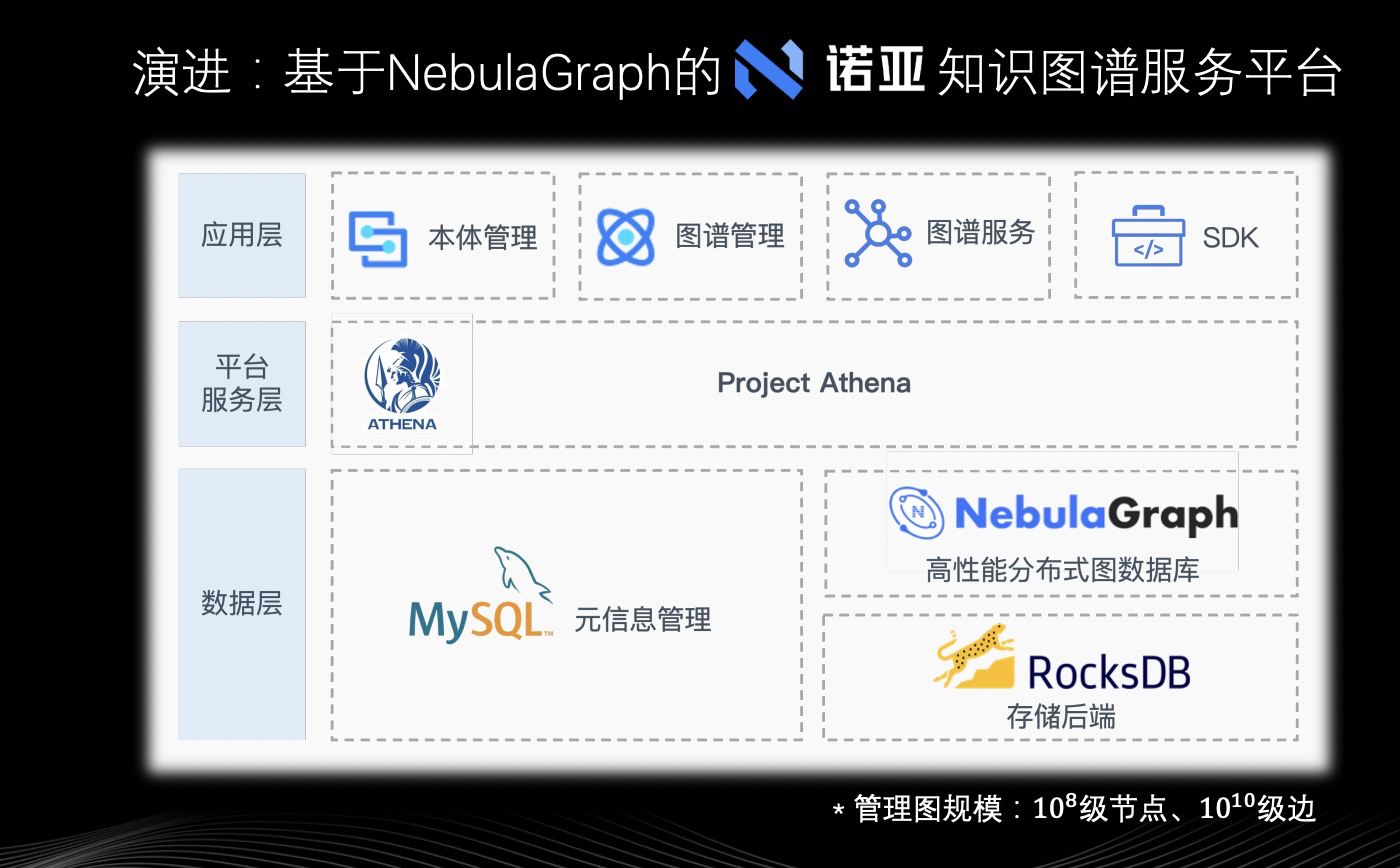
上图所示,存储后端选用 Nebula Graph 默认的 RocksDB,基于 Nebula Graph 上层封装知识图谱平台 Athena,Athena 中的元数据会在下层数据层的 MySQL 进行管理。在平台服务层 Athena 上面进一步抽象封装应用层,将之前知识图谱工具中的 Schema、点边写入、查询等等操作封装成应用形式,对应到上图的本体管理、图谱管理、图谱服务。为了方便业务拓展、快速落地,上层应用层还封装了 SDK。得益于 Nebula Graph 的高性能和新架构,网易游戏目前有了更强的图管理能力,目前图规模在 10^8 级别的点和 10^10 级别边。
Nebula Graph 物理部署
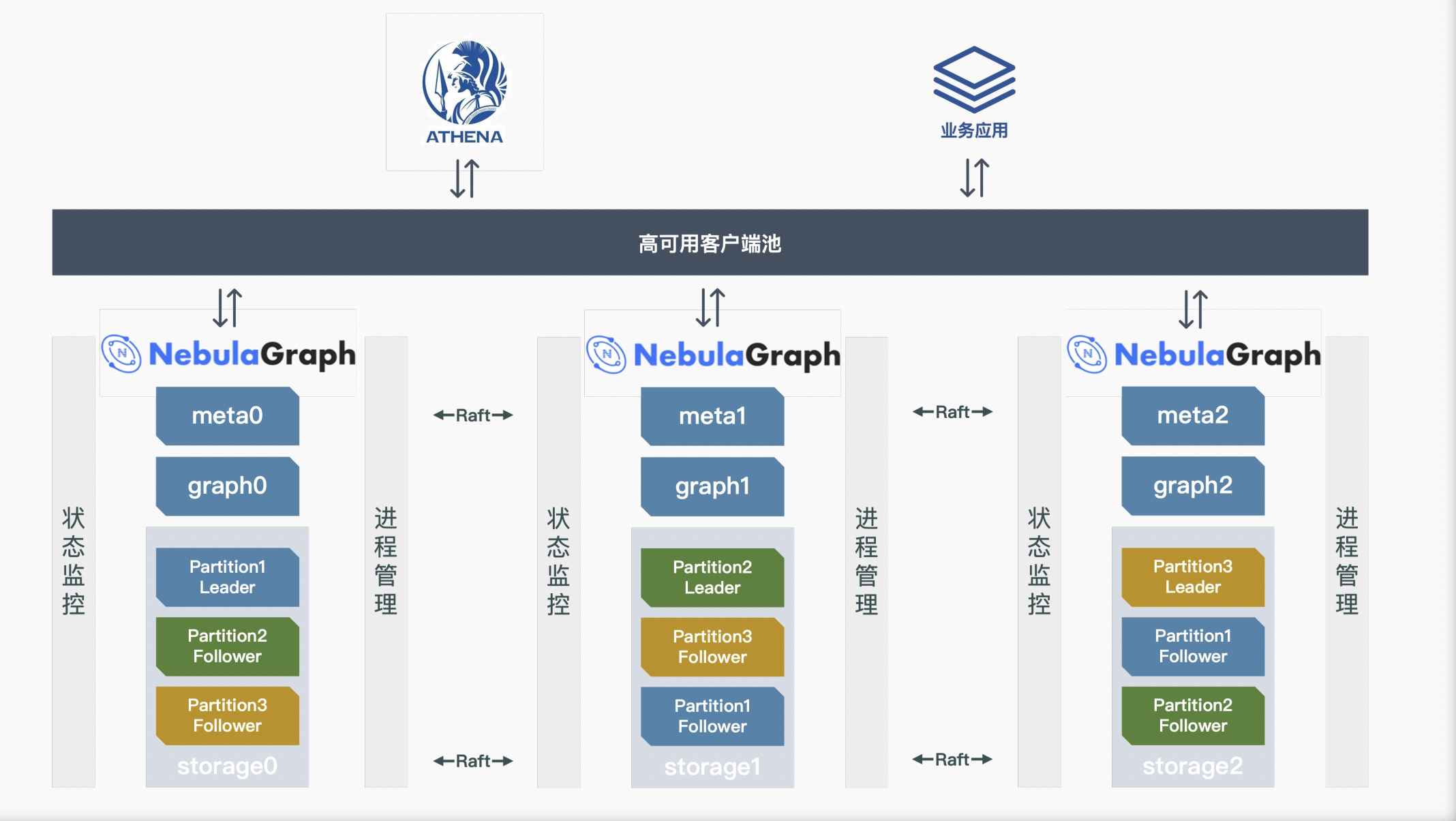
Nebula Graph 的部署结构如上图所示,网易游戏这边仅用了 3 台物理机器部署,便能管理上述的级别的图规模。除了常规的服务部署之外,还增加了定制化服务状态监控和进程管理模块。之所以新增这两个服务的原因是网易游戏搭建这套系统时,Nebula Graph 版本为 v2.0.1,该版本不具备内存水位管理(这个功能在 v2.5.0 开始支持),所以宕机不能自动恢复。加入状态监控和进程监控之后,宕机可以自动恢复。此外,网易游戏这边还进一步封装了 Nebula Java 客户端变成高可用客户端池,里面内置自动重连、冲突检测等等功能。这里客户端池只起到隔离作用,上层才是前面提到的知识图谱平台服务,以及其他的业务应用。
基于这样的部署结构,网易游戏的知识图谱业务也有了较稳定的运行状态。
性能对比:Nebula Graph v.s. JanusGraph
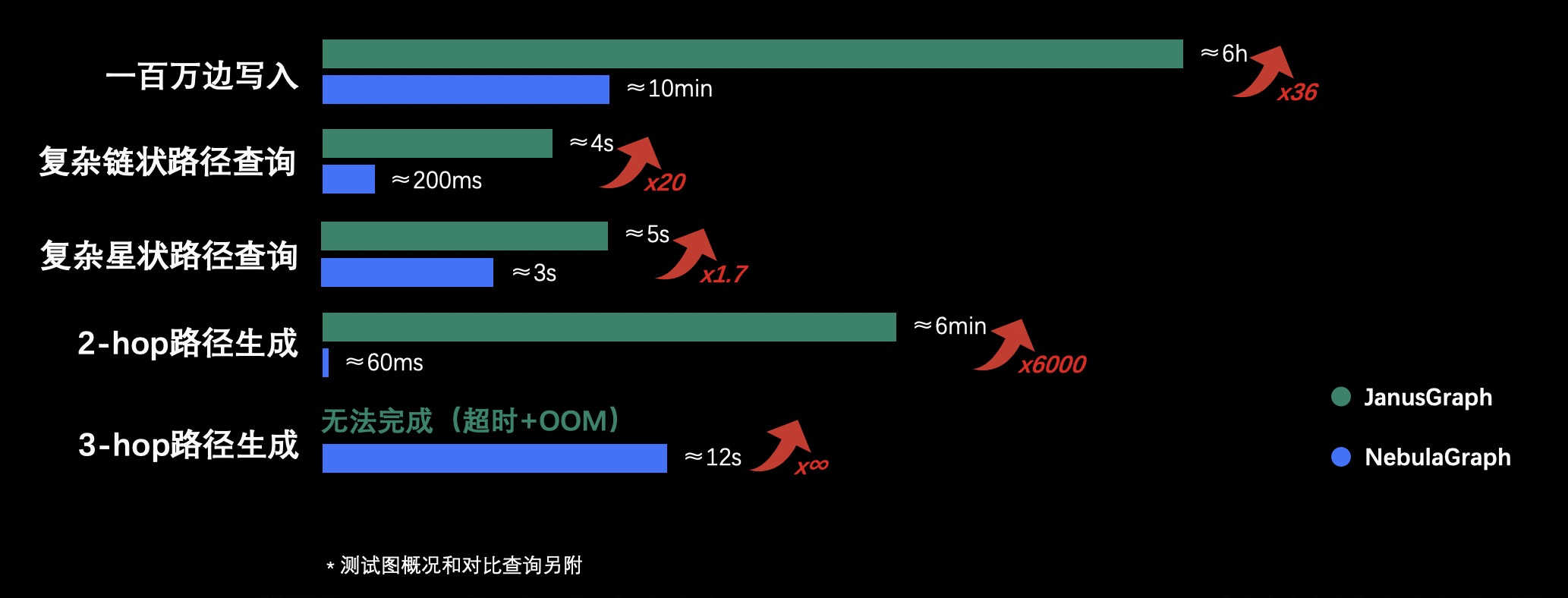
经过底层的存储后端重构(用 Nebula Graph 代替 JanusGraph)之后,我们最直观的体验便是快、非常快。像上面的性能对比,100 万条边数据的写入性能在原来基于 JanusGraph 架构下,大概需要 6 个小时。切换到 Nebula Graph 架构后,缩短到 10 分钟左右,性能提高 33~40 倍。
而复杂链状路径查询,即一个点连另一个点,再连另一个点这样一条链的查询。这种查询 JanusGraph 架构大概需要 4 秒,而 Nebula Graph 缩短到 200 毫秒,性能提升 20 倍的样子。
而复杂形状路径查询,就是一个点出去,经过另一个点,然后再回到这个点,再从另一个方向出去经过另一个点,这样路径查询。使用 Nebula Graph 之后也有了明显的性能提升,从 5 秒降低到 3 秒,性能提升大约 2 倍左右。
性能提升比较明显的点是在路径生成上,两跳 2-hop 路径生成经查询测试,JanusGraph 架构在 6 分钟左右,而 Nebula Graph 只用 60 毫秒,性能提升 6,000 倍。三跳 3-hop 的路径生成,JanusGraph 是超时 + OOM(这里我们设置了超时阈值为半个小时),Nebula Graph 的话在 12 秒内跑出结果,这也是比较大的性能提升。
低门槛使用知识图谱
单纯图数据库性能快的话,其实对我们而言用处并不大,前面提到过怎么简单地建立图、使用图数据,才是用户最常面对的门槛。
本体管理模块
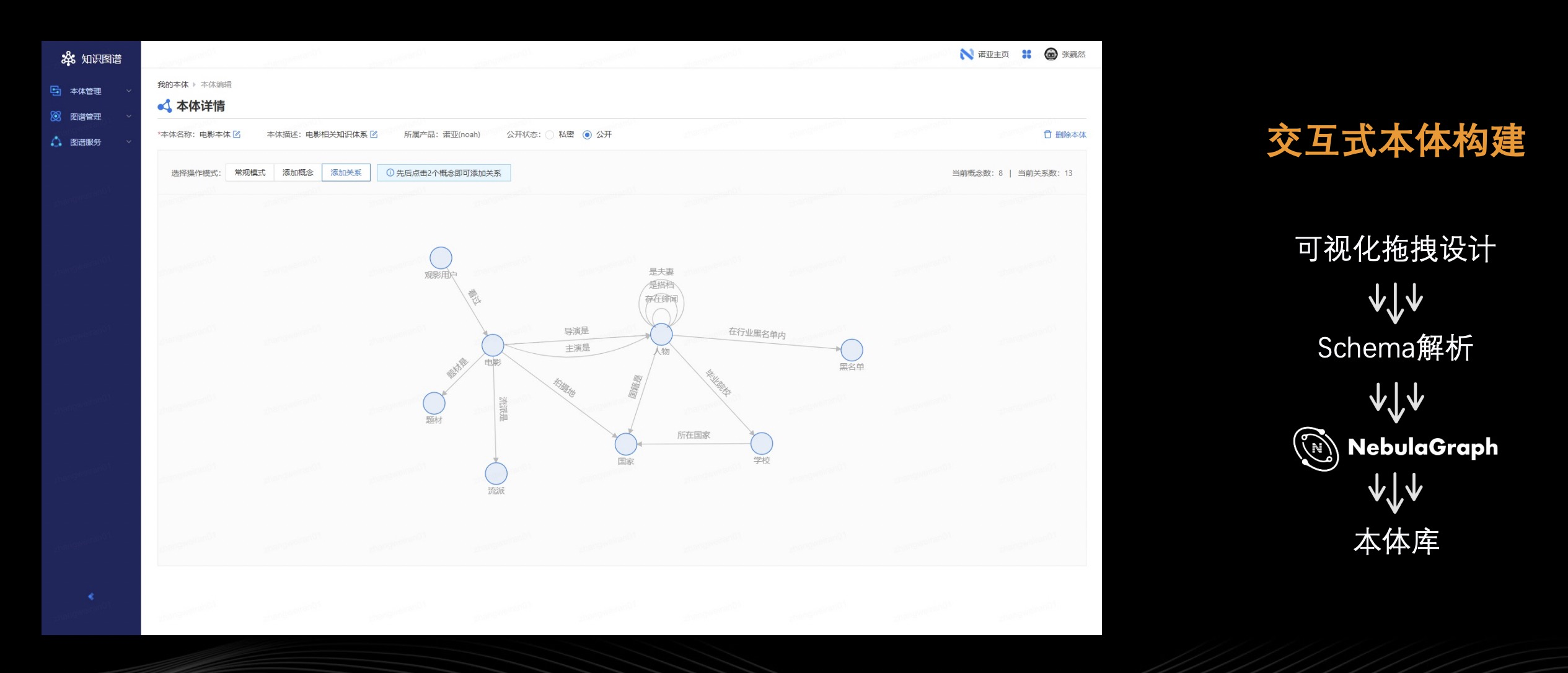
基于先前知识图谱工具包积累的探索经验,我们在诺亚平台开发了知识图谱服务平台,目前有本体管理、图谱管理、图谱服务三大功能,极大地降低了知识图谱的使用门槛,提高了使用体验。得益于 Nebula Graph 的高性能,知识图谱服务平台能以较高性能稳定运行,以服务封装的产品。首先,看下本体管理,主要用于解决 Schema 设计问题。用户可能并不清楚怎么去设计 Schema,更甚者他不知道什么是 Schema。即便用户知晓何为 Schema,他怎么去执行设计思路也是一个问题,难道让他直接去编辑创建语句吗?
因此,我们对 Schema 设计进行封装抽象成本体构建模块。这个模块采用了交互式,通过简单地拖拽(把概念拖进来,把关系拖进来)来实现用户的本体设计,即所见即所得,他怎么拖拽组件就得到怎么样的本体。根据用户设计的图结构将当中 Schema 进行解析,写入到 Nebula Graph 中,至此,本体构建完成。构建完成的本体会存储在本体库,因为图结构具备一定通用型可作为复用资源。所以,在本体管理模块将本体资源放到本体库中,供所有的用户共享使用创建自己的知识图谱库。
图谱管理
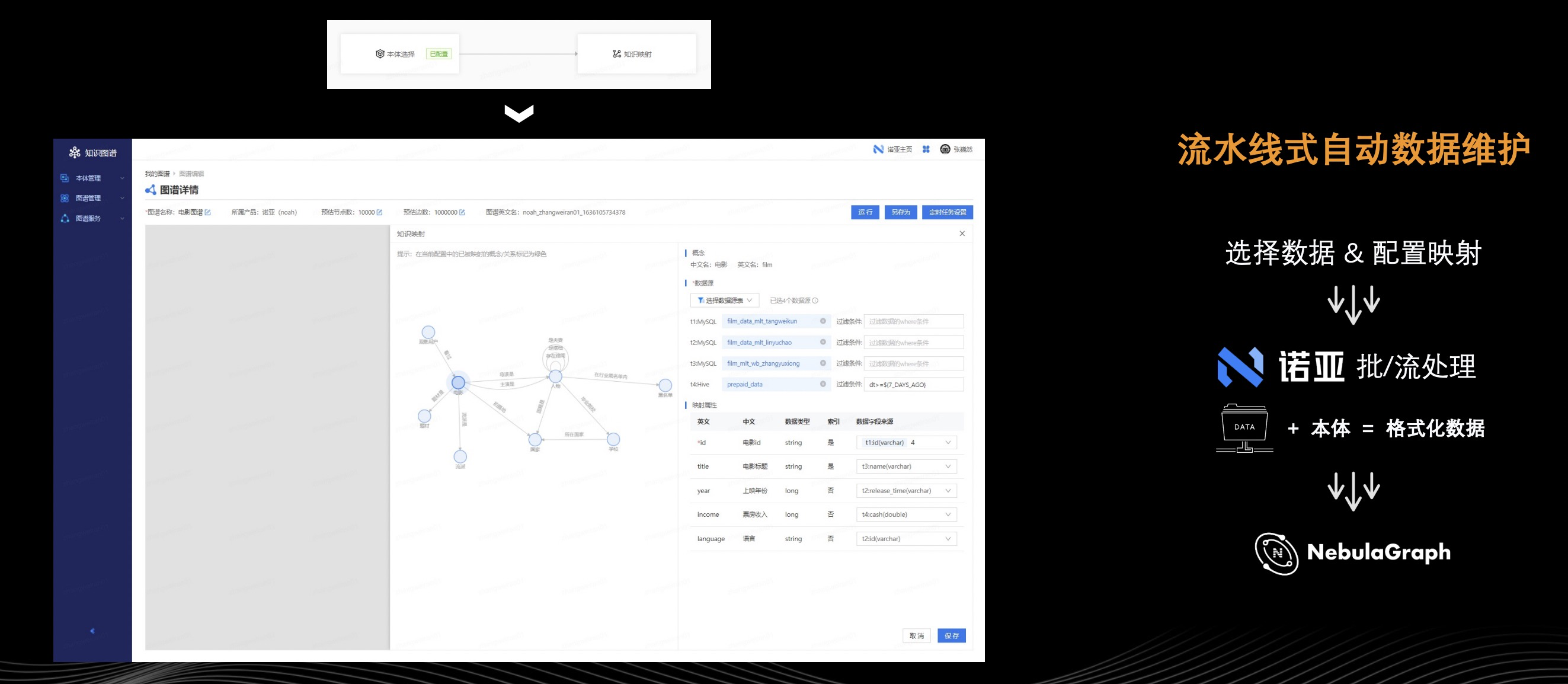
设计好的图谱结构,如何写入数据、定时地维护图谱里面的数据,这里我们抽象出了图谱管理模块。
首先,用户要在图谱管理模块选择所用本体,选择完成后进入知识映射环节。知识映射简单来说,就是 Schema 和数据的映射。用户完成本体选择(概念选择、关系选择)后,可以从各个数据源,比如 MySQL、Hive 中选择所需数据并配置过滤条件,这样用户就为刚才设计的本体(概念属性或者是关系属性)指定属性值来自哪张表的哪个字段。举个例子,用户他选择电影标题属性值来自 t3 数据表的 name 字段,点击上图蓝色框的【运行】按钮,这时候 t3 的 names 值将会直接写入电影概念下节点的参考属性。这个网易知识图谱团队称之为流水线,即自动数据维护。自动数据维护服务还支持配置定时运行任务,假如用户的数据是 T+1 更新就可以配置每天运行,这样每天更新的数据会自动刷到图谱中。
可视化查询
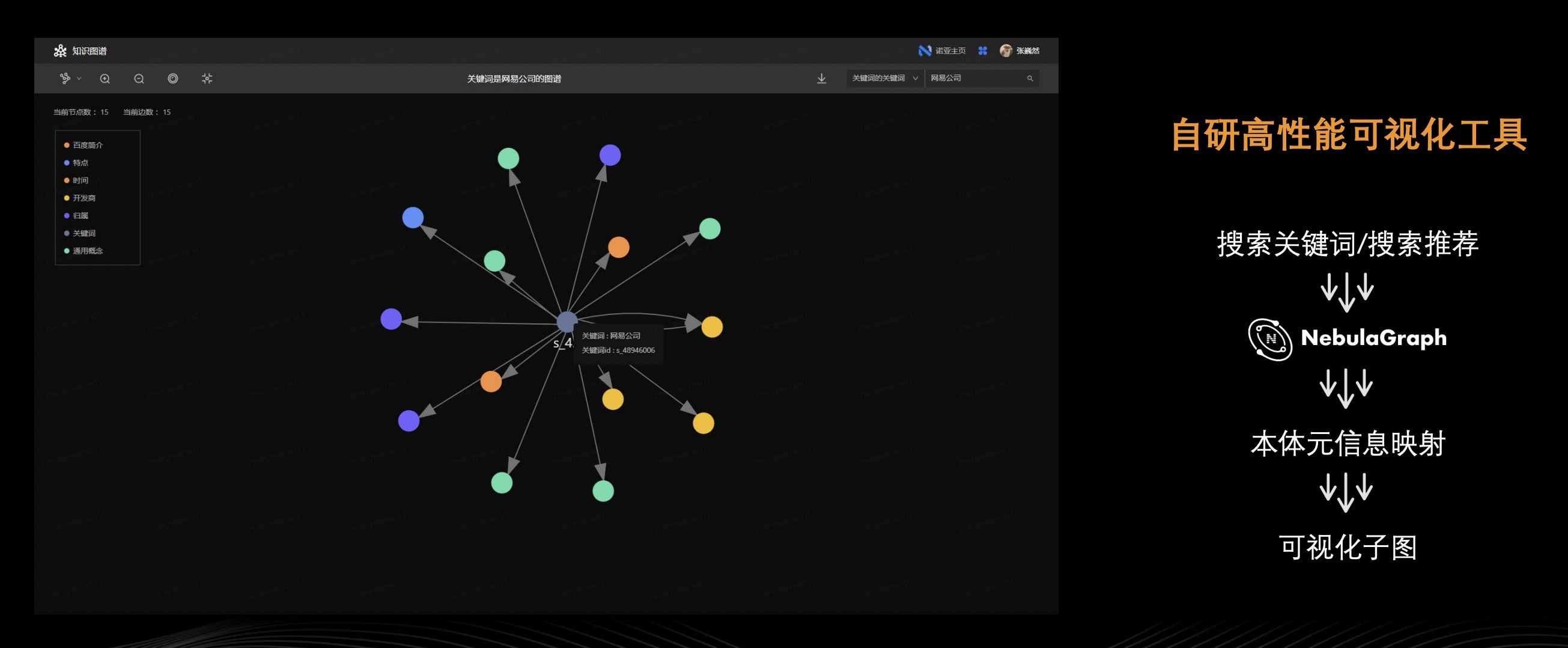
上面讲完了 Schema 构建和数据写入,那用户怎么查询图数据呢?答案是我们针对这个问题自研了一个高性能的可视化工具。
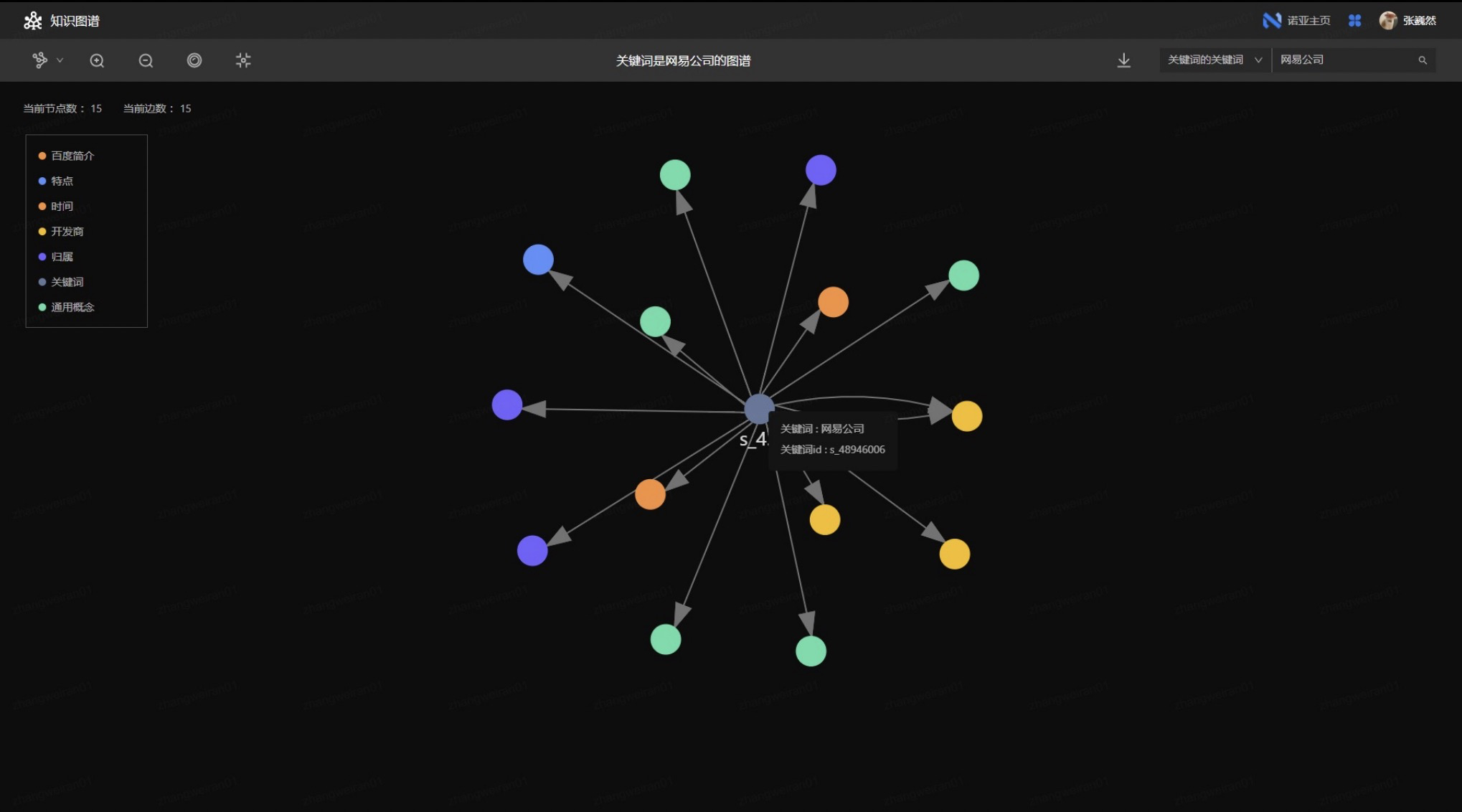
上图右上角为“关键词的关键词”选择框,示意用户可以去搜索关键词。这里的关键词对应 Nebula Graph 中某个节点的 tag 属性,比如:电影的名字。在画布中选择关键词之后,填入“十面埋伏”点击【搜索】,系统会将用户的搜索意图转化为 Nebula Graph 中的查询语句并执行,找到匹配的中心节点,再获取该节点的一跳子图,将其结果返回给知识图谱平台。最后,把子图的数据同本体库中的本体结构进行映射,最终刷到可视化画布上,呈现搜索结果的示意图 。此外,这个可视化系统还支持点击子图中的其他节点,展示其一跳子图,也支持规则过滤数据、高亮可视化结果。
说完功能性,为什么说这套系统是高性能呢?这套可视化工具在符合网易游戏内部的数据形式之余,也具备高性能:无论是点击搜索还是查看一跳子图,都能在较短时间刷新画面呈现结果,多节点的情况下也不会造成卡顿。
可配置服务
配置式推荐理由服务
上面说的内容大多为知识图谱维护,基于数据即服务的理念,网易游戏封装了知识图谱服务,用户可直接配置用上知识图谱提供的能力。
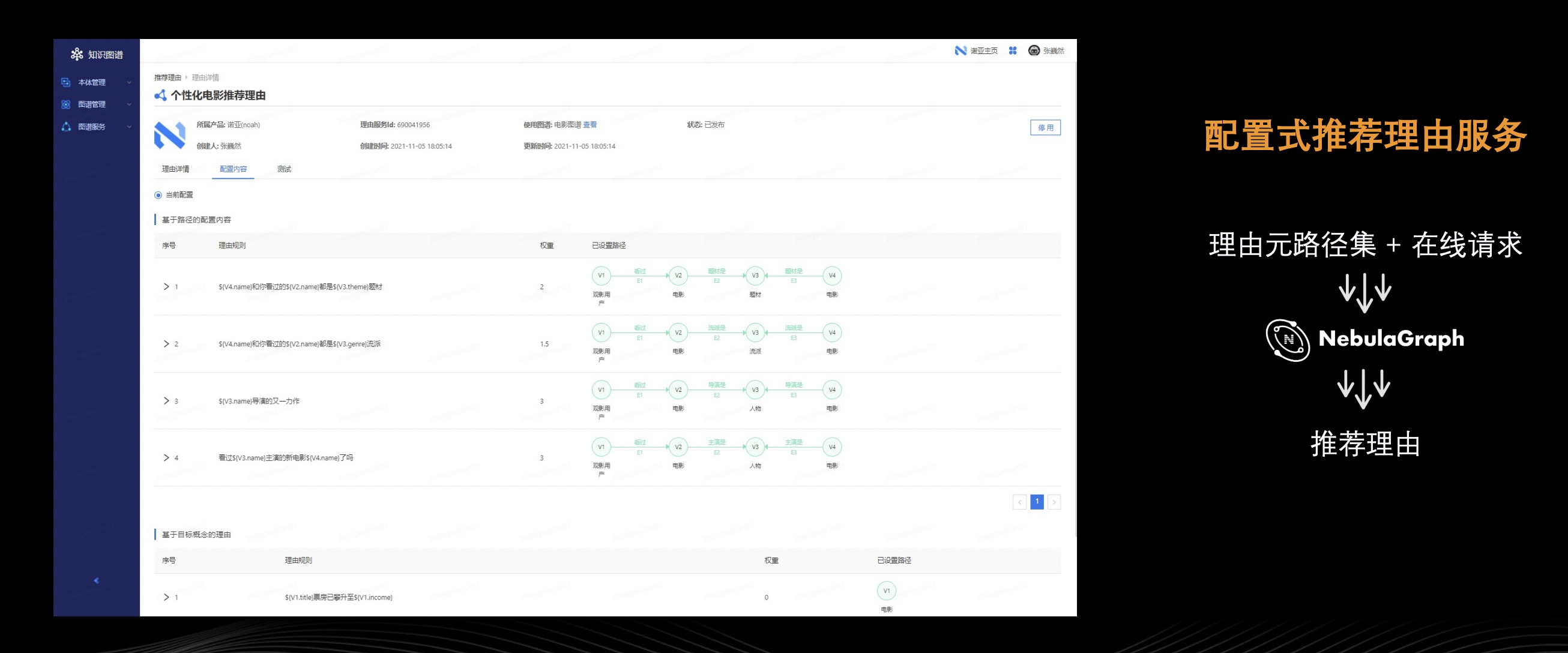
这里讲下何为推荐理由?推荐理由就是用户可在知识图谱本体结构中配置路线,比如上图的绿色部分,观影用户 v1 看过电影 v2,v2 的题材是 v3,而 v3 同样是电影 v4 的题材,这个路径便可变成配置的理由规则:推荐电影 v4 的理由是它的题材同你之前看过的电影 v2。对应到 Nebula Graph 中的查询便是看 v1 和 v4 之间是否存在该条路径,满足的话就像其题材属性值填充到理由规则中,比如十面埋伏和英雄都是中国题材电影这种理由。当然不同的节点可能满足多种理由规则,比如上图下方所示的 v1(这里用十面埋伏来代指)的票房已经攀升到 xx 亿这样的理由规则,而这个理由对应到 Nebula Graph 中到查询操作便是查找票房属性值。
推荐理由服务的好处是什么呢?一,用户不需要写查询实现以及维护 meta path 查询通过简单的配置形式即可获得推荐理由;二,支持任意来源的在线请求,举个例子:用户可使用逻辑黑箱、算法黑箱生成推荐结果同步给理由服务,理由服务依据指定的图谱返回具体的推荐理由,将黑箱推荐白箱化。
配置式社交网络服务
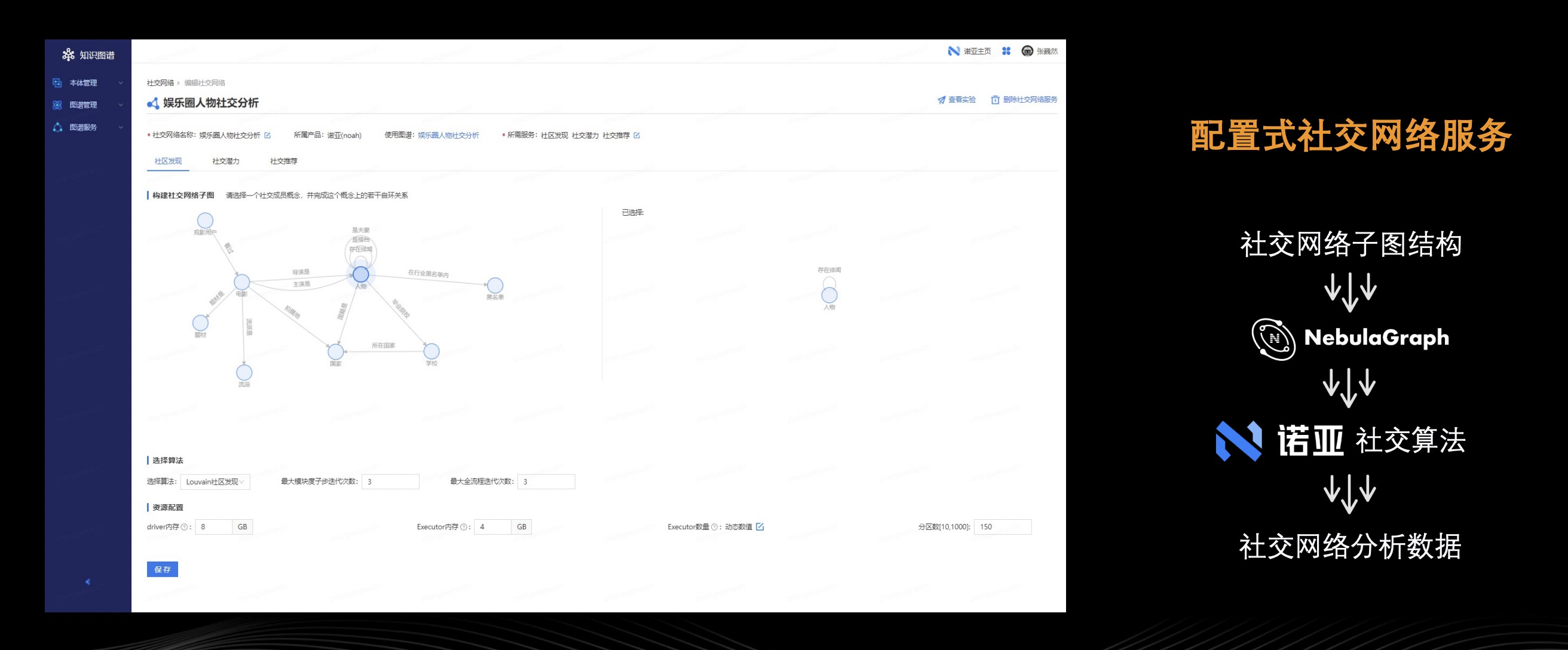
这个部分讲下社交网络服务,上文提到游戏内存在社交网络。分析具体的业务场景时,发现需要基于知识图谱进行图计算,比如社区发现,因此这里将社交网络进行了服务化封装。
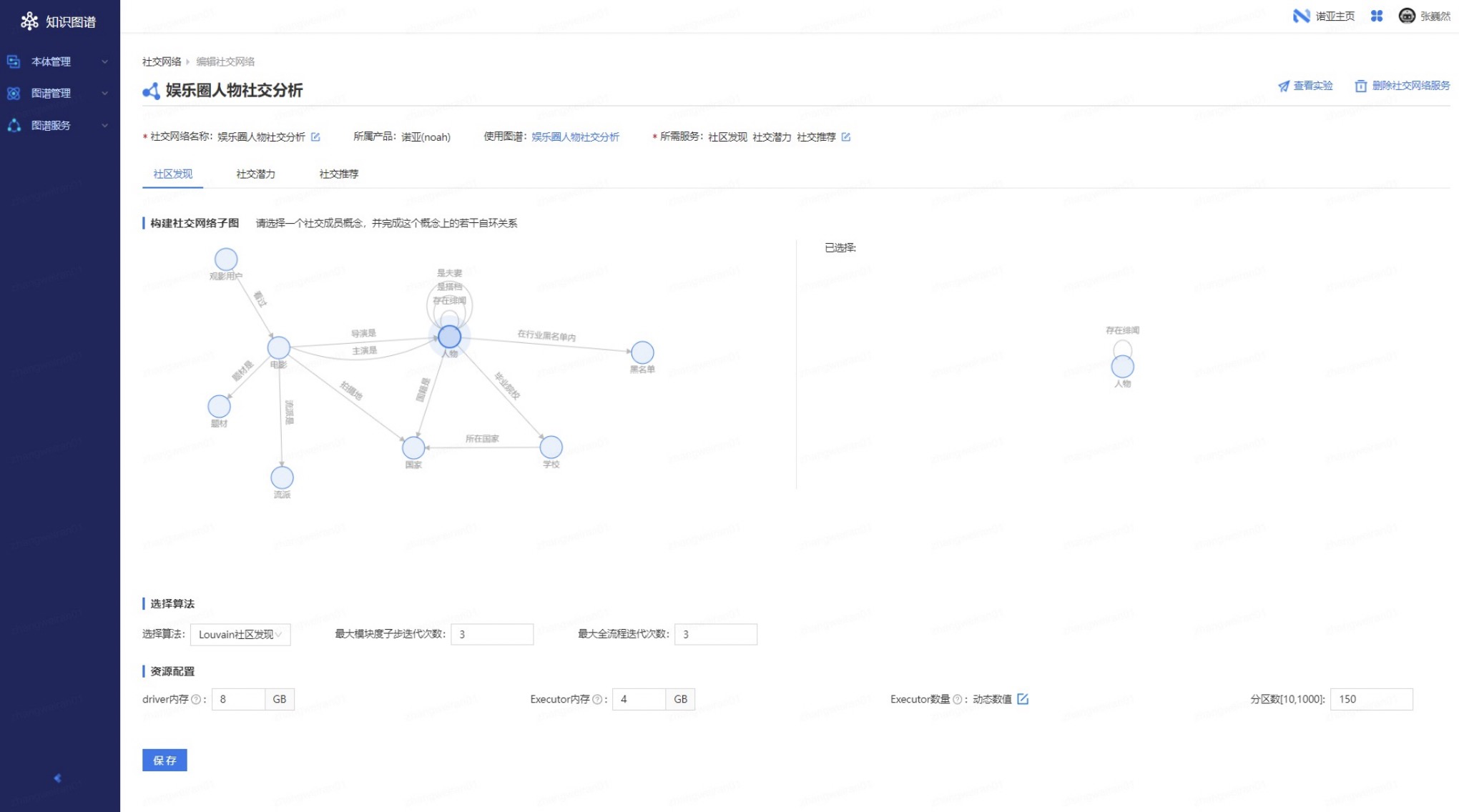
用户在本体结构上选择社交网络子图,所谓的社交网络子图就是社交网络中核心的成员是谁,比如说这个图里选择的人物。此外,你还可以选若干个社交关系,上图右侧所示的自环关系“绯闻”,这样便是一个社交子图结构。再选择社交算法(上图下方功能区域)填入算法参数,点击【运行】。这样社交网络的分析或者说计算流程,会被解析成诺亚平台上的一个实验,进行运行,运行完成后,用户在 Web 界面可看到社区发现、社区潜力、社交推荐的结果。
配置式知识表示服务
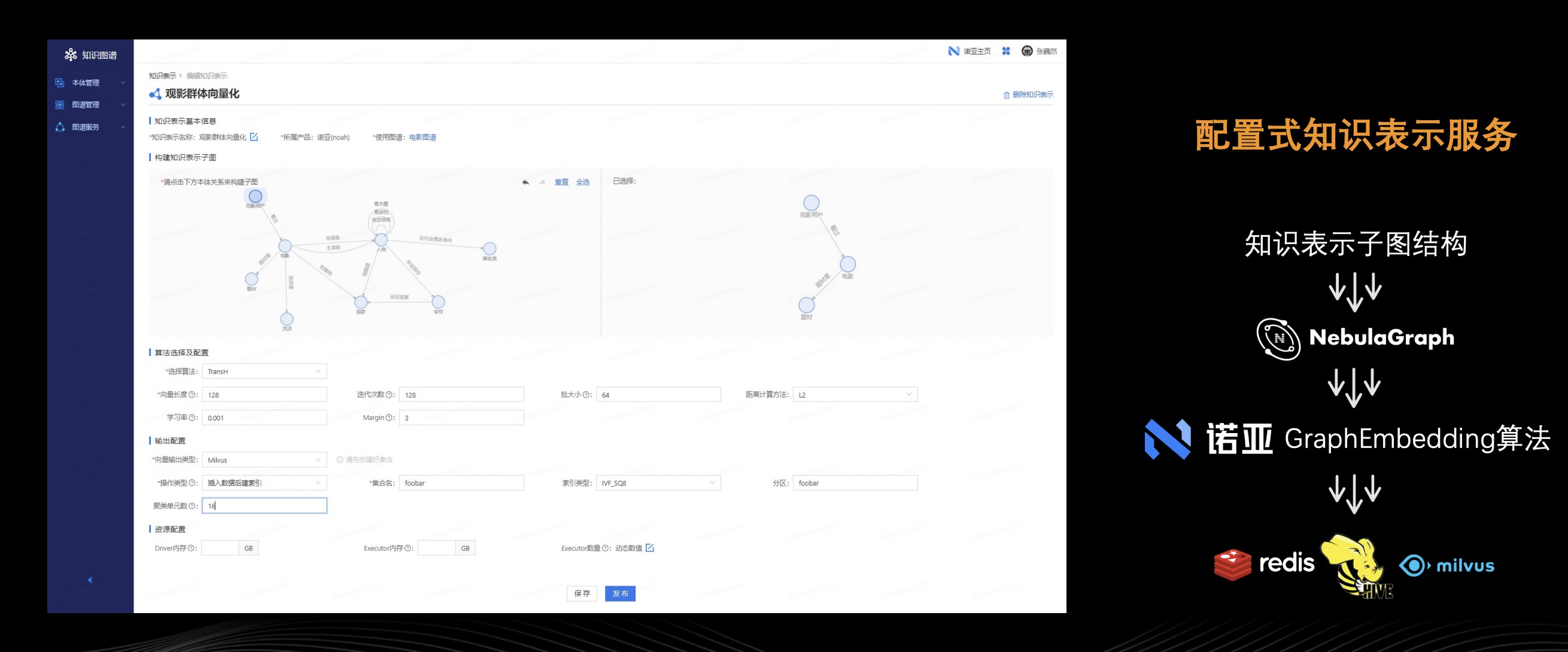
知识表示服务可将图谱中的点边通过图结构关系映射成向量。熟悉算法同学工作的人可能知道,他们需要编写 PyTorch / TensorFlow 等等代码,用到一个知识表示就需要写一套代码,而且代码行数也不少。其实这当中存在通用性需求,诺亚知识图谱平台将通用型需求进行抽象封装成配置式知识表示服务便能大大地节省时间,提高效率。
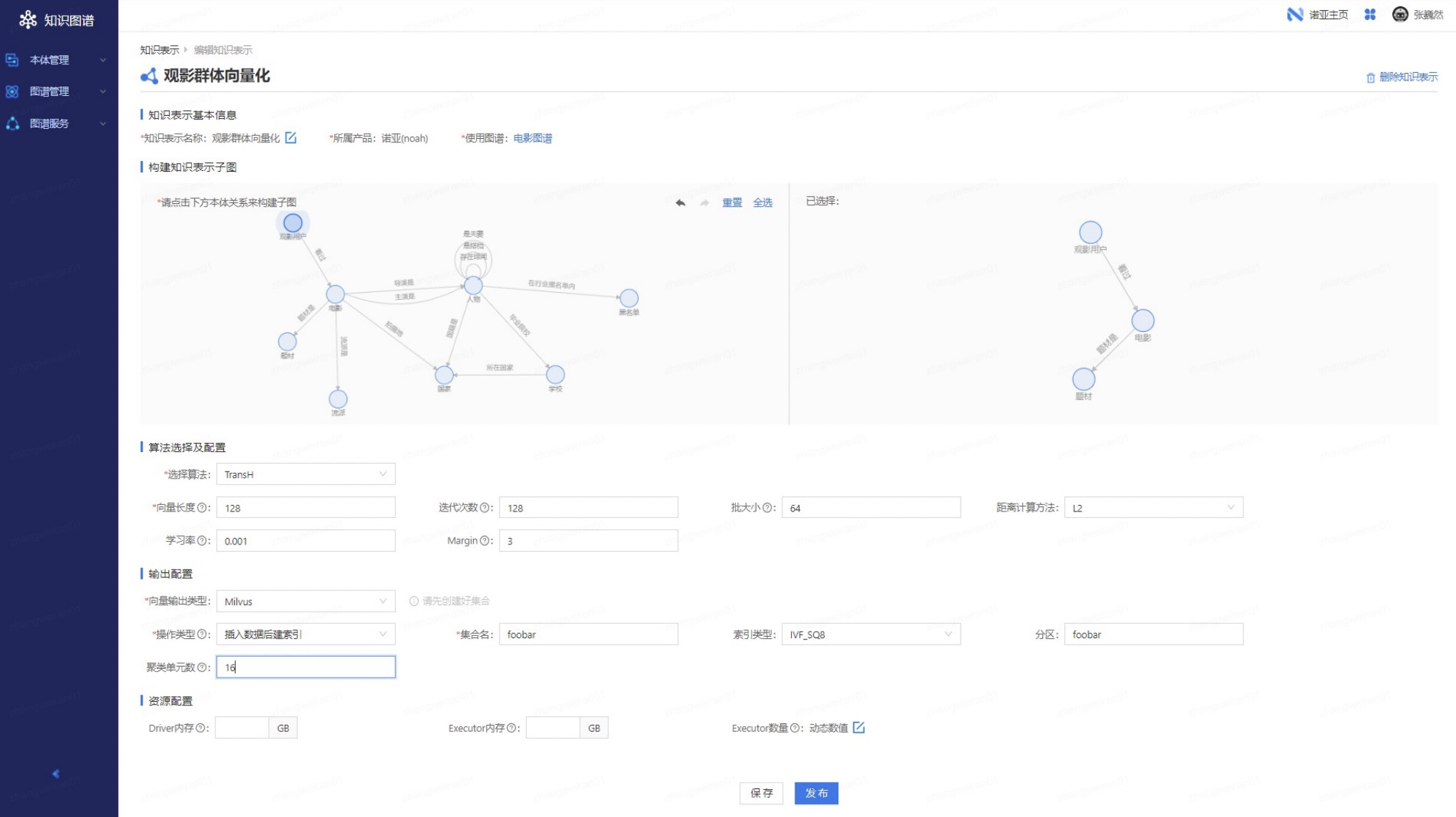
如上图所示,首先还是选子图结构,确定知识图谱中哪些概念节点、哪些关系边即将被系统映射成向量。再选择知识调试算法,上图便是选择了 TransH,再选择算法参数:向量长度、迭代次数等等。接着配置运行结果存放在什么地方(输出类型),比如存放在 Redis、Hive、Milvus 中,选择输出类型后配置输出源对应参数。最后,点击【发布】运行即可。同上面的服务一样,这个知识表示配置会被转化成知识学习实验去读取 Nebula Graph 中的图数据,再放到诺亚上面去计算知识表示算法,最终根据用户的配置输出到 Redis / Hive / Milvus 中,这样算法工程师就可以非常方便地在离线实验或者在线业务中调用知识表示向量了。
配置式推荐服务
同上文的推荐理由类似,也是 meta path 思路,用户在知识图谱结构上面配置多个 meta path,比如看过什么电影、电影导演是谁、影片类型是国产片还是美国片,以及电影主演在不在行业黑名单,关联上述 meta path,点击【发布】运行。同上面的其他服务类似,系统到 Nebula Graph 中读取图数据,查看结果中有哪些电影满足上面的复合查询。
知识图谱在游戏中的应用
在这个章节,简单分享下网易游戏基于诺亚平台封装的知识图谱服务落地了哪些图谱业务形式和知识图谱应用。

做算法的同学可能对 RippleNet 比较熟悉,网易游戏的 RippleNet 实践是基于商品数据构造知识图谱,在其上层开发 RippleNet 实验给用户进行个性化推荐,比如:感兴趣的商品、独享折扣等等。此外,因为用到了知识图谱,之前提到的配置式推荐理由可以给出一些推荐理由。这样,业务落地之后,游戏的购买率和单位流量代币回收较之前都有了提升。

第二个例子,基于 meta path 的商品套装推荐。这里的套装什么概念?比如,麦当劳点单的套餐,便是个典型的套装。它之所以是一个套装,是因为你吃汉堡可能会渴,就需要喝可乐,所以汉堡和可乐会是一个套装。套用这个思路到游戏中,游戏里给玩家推荐皮肤套装,当中的商品应当是搭配的,比如头饰、上衣、光环的颜色搭配。想象下,绿色的头饰搭配红色的头发再加一个红色光环,或者其他奇奇怪怪的色彩搭配,是很影响游戏体验的。在没有诺亚知识图谱服务平台之前,想做出一个搭配的套装需要借助运营同学或者设计同学的人力资源,手工依赖人的经验和审美进行设计,这相当低效。
有了知识图谱服务平台之后,将套装设计专家知识抽象成 meta path 模板,比如:头饰和上衣,再用 meta path 进行计算返回套装,设计出来的套装搭配度非常高。此外,在提升人效的同时也提高了购买率。

第三个是社交网络,网易游戏用知识表示 TransH 算法来向量化社交网络里面的玩家。向量化之后,我们可以对数据进行下一步操作。举个例子,用相似度做相似玩家的召回或者集合,这里的集合可能是工会或者说组织,可在召回成功后推荐给其他相似玩家。在社交推荐系统的帮助下,游戏中申请率和成功率有了提高。
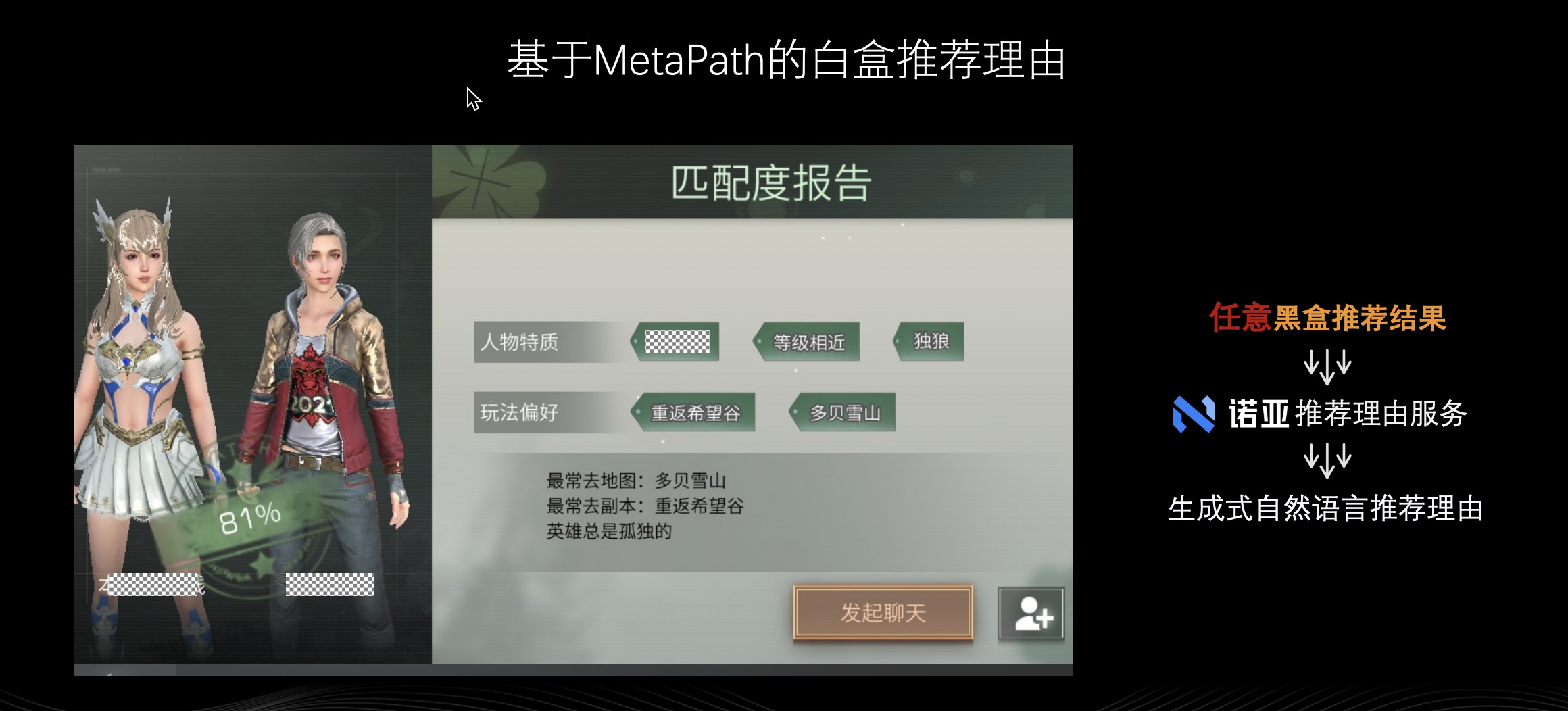
上面配置式推荐理由服务中讲到过黑箱白箱化,基于 metapath 的白盒推荐理由。像上图所示的好友匹配,初期好友推荐会给出一个匹配度,这里的数值可能是 81%。但是作为玩家或许会很困惑,为什么是 81%,这个数值和这个用户推荐结果是怎么来的?系统为什么把这个人推给我?而基于 metapath 的白盒推荐理由则能很好地解决这个问题。将黑箱推荐理由输入到诺亚知识图谱服务平台上,利用知识图谱匹配推荐理由。以上面的例子为例,系统可以给出女玩家和男玩家之前都去过多贝雪山、常去重返希望谷副本…等等理由,这样被推荐的用户接受推荐结果的可能性便大大提升了。
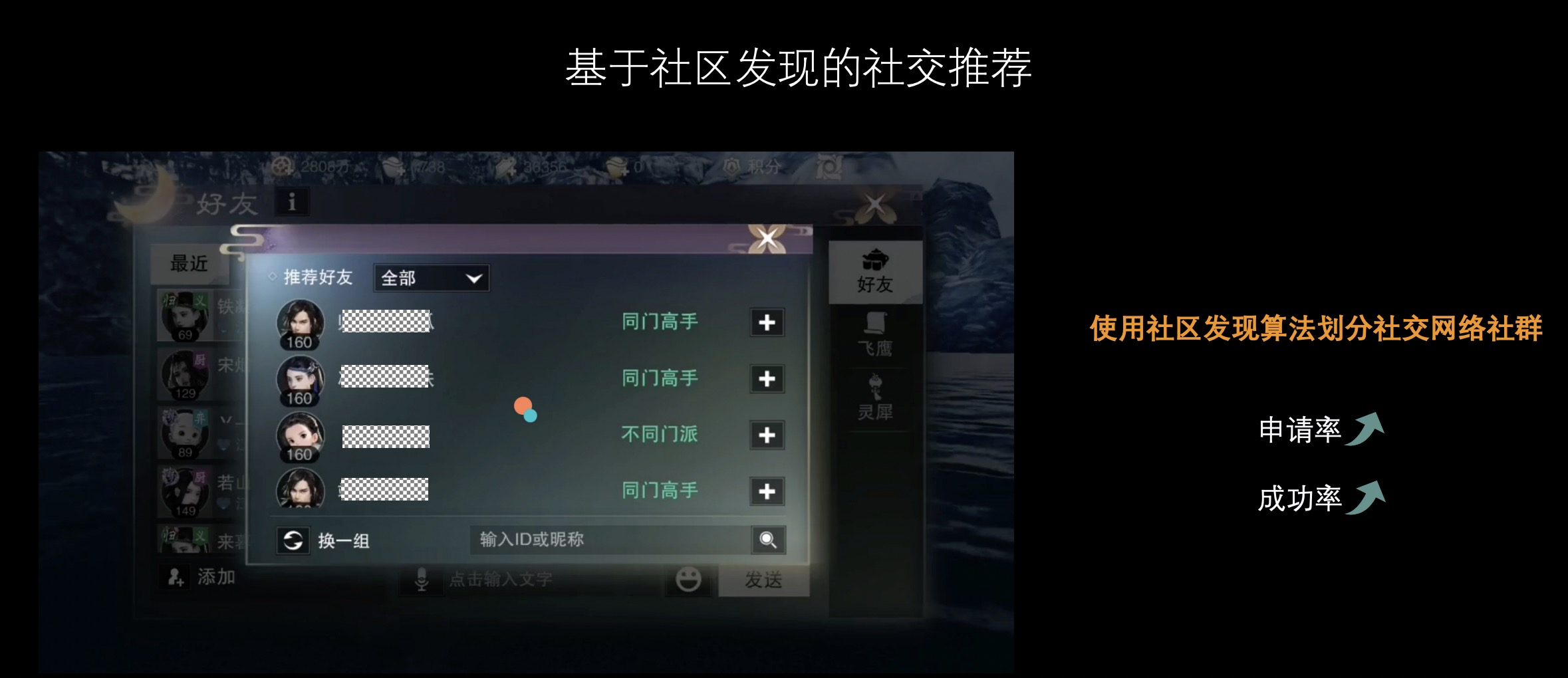
还是一个社交场景,有了社交网络数据,系统便可基于数据进行社区发现算法计算,像上面便是直接把同社区内召回的玩家经过简单的过滤后推荐给其他玩家,这里好友申请率和申请成功概率也有一定的提高。

再来看看基于 meta path 的社交推荐,有了知识图谱难以避免会涉及专家知识。专家知识在很多场景下,是非常硬核的东西因为它可以取得非常好的效果。像社交推荐业务,就直接将先前积累的社交推荐经验,比如同时段游玩、标签分值类似的玩家放在一起抽象成知识图谱上的 meta path 模板。利用这样 meta path 模板,在线请求传入玩家数据后,在 Nebula Graph 中在线实时计算结果并返回对应推荐玩家。这样,社交好友申请率和申请成功率也会有很大提升。
展望
- 更加完备的知识图谱平台能力:简单高效地支撑更多复杂图数据管理和服务需求;
- 更加丰富的知识图谱业务形式:探索更多有意思、有价值的知识图谱业务;
- 更加深入的 Nebula Graph 社区参与程度。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
{kind=link}
Nebula Graph 在网易游戏业务中的实践的更多相关文章
- Java线程池实现原理及其在美团业务中的实践
本文转载自Java线程池实现原理及其在美团业务中的实践 导语 随着计算机行业的飞速发展,摩尔定律逐渐失效,多核CPU成为主流.使用多线程并行计算逐渐成为开发人员提升服务器性能的基本武器.J.U.C提供 ...
- Java线程池实现原理及其在美团业务中的实践(转)
转自美团技术团队:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html 随着计算机行业的飞速发展,摩尔定律逐 ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- Neo4j 导入 Nebula Graph 的实践总结
摘要: 主要介绍如何通过官方 ETL 工具 Exchange 将业务线上数据从 Neo4j 直接导入到 Nebula Graph 以及在导入过程中遇到的问题和优化方法. 本文首发于 Nebula 论坛 ...
- 分布式图数据库 Nebula Graph 中的集群快照实践
1 概述 1.1 需求背景 图数据库 Nebula Graph 在生产环境中将拥有庞大的数据量和高频率的业务处理,在实际的运行中将不可避免的发生人为的.硬件或业务处理错误的问题,某些严重错误将导致集群 ...
- Nebula Graph 技术总监陈恒:图数据库怎么和深度学习框架进行结合?
引子 Nebula Graph 的技术总监在 09.24 - 09.30 期间同开源中国·高手问答的小伙伴们以「图数据库的设计和实践」为切入点展开讨论,包括:「图数据库的存储设计」.「图数据库的计算设 ...
- 分布式图数据库 Nebula Graph 的 Index 实践
导读 索引是数据库系统中不可或缺的一个功能,数据库索引好比是书的目录,能加快数据库的查询速度,其实质是数据库管理系统中一个排序的数据结构.不同的数据库系统有不同的排序结构,目前常见的索引实现类型如 B ...
- 图数据库对比:Neo4j vs Nebula Graph vs HugeGraph
本文系腾讯云安全团队李航宇.邓昶博撰写 图数据库在挖掘黑灰团伙以及建立安全知识图谱等安全领域有着天然的优势.为了能更好的服务业务,选择一款高效并且贴合业务发展的图数据库就变得尤为关键.本文挑选了几款业 ...
- GraphX 在图数据库 Nebula Graph 的图计算实践
不同来源的异构数据间存在着千丝万缕的关联,这种数据之间隐藏的关联关系和网络结构特性对于数据分析至关重要,图计算就是以图作为数据模型来表达问题并予以解决的过程. 一.背景 随着网络信息技术的飞速发展,数 ...
随机推荐
- Spring中的属性注入注解
@Inject使用 JSR330规范实现的 默认按照类型注入 如果需要按照名称注入,@Inject需要和@Name一起使用 @Resource JSR250规范实现的,需要导入不同的包 @Resour ...
- 6U VPX i7 刀片计算机
一.产品概述 该产品是一款基于第三代Intel i7双核四线程(或四核八线程)的高性能6U VPX刀片式计算机.产品提供了可支持全网状交换的高速数据通道,其中P1,P2各支持4个PCIe x4 Gen ...
- Solution -「ARC 101E」「AT 4352」Ribbons on Tree
\(\mathcal{Description}\) Link. 给定一棵 \(n\) 个点的树,其中 \(2|n\),你需要把这些点两两配对,并把每对点间的路径染色.求使得所有边被染色的方案数 ...
- PHP获取用户IP地址
PHP获取访问者IP地址 这是一段 PHP 代码,演示了如何获得来访者的IP address. <?php//打印出IP地址:echo (GetIP());function GetIP() / ...
- [LeetCode]28.实现strStr()(Java)
原题地址: implement-strstr 题目描述: 实现 strStr() 函数. 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字 ...
- 突然发现,npm里request依赖包已经弃用,怎么办?
摘要:在npm官网查看了request依赖包的当前状态,果然在2020年就被弃用了. 本文分享自华为云社区<npm里request依赖包已经弃用?致敬并调研替代方案!>,作者: gentl ...
- tip1:学习使用mybatis中使用mysql数据库的基本操作
1.查看mysql服务是否启动: 2.root用户链接数据库:mysql -u root -p,随后输入正确的密码即可. 3.root用户创建数据库: 4.查看已建数据库:show databases ...
- 图文并茂详解 NAT 协议!
什么是 NAT 协议 我们的计算机要想访问互联网上的信息,就需要一个地址,而且这个地址是大家(其他主机)所认可的,是公共的,这个地址也叫做公有 IP 地址. 与之相对的,除了公有 IP 地址外,还有私 ...
- 由浅入深--第一个MyBatis程序
话不多说,马上开始我们的第一个Mybatis程序: 第一个程序,当然要参考MyBatis的官网文档来搞,地址如下:https://mybatis.org/mybatis-3/zh/getting-st ...
- journactl日志查看命令-渐入佳境
--作者:飞翔的小胖猪 --创建时间:2021年2月27日 内容 journalctl是systemd统一管理所有unit(服务)的启动日志.可以通过journalctl一个命令查看所有日志. 所有用 ...