Iceberg 数据治理及查询加速实践
数据治理
Flink 实时写入 Iceberg 带来的问题
在实时数据源源不断经过 Flink 写入的 Iceberg 的过程中,Flink 通过定时的 Checkpoint 提交 snapshot commit 操作到 Iceberg,将已写入到 Iceberg 的数据文件通过 Snapshot 组织暴露出来。如果不对流实时写入 Iceberg 的文件进行治理,久而久之 Iceberg 下的小文件会越来越多,Snapshot 版本也越来越多,查询速度大打折扣。
数据治理方案
基于上述问题,我们需要对 Iceberg 的元数据和数据文件定期进行治理。治理方向主要有俩点:
- 清理快照
- 合并小文件
因为我们查询引擎用 Trino,于是我们选用 Trino 对 Iceberg 进行优化。
Trino-Iceberg Connetor 提供了优化方法:
-- 清理快照
ALTER TABLE test_table EXECUTE remove_orphan_files(retention_threshold => '7d')
-- 合并小文件
ALTER TABLE test_table EXECUTE optimize(file_size_threshold => '10MB')
使用 Trino SQL 便可以对 Iceberg 表进行优化,很方便。我们基于 Trino SQL 上,做了一个自动自助的 Iceberg 表优化工具,实现了定时对某个 Catalog 下的表进行优化,省去了人工运维优化的成本。
除了快照清理和合并小文件外,Trino 提供了清理无效数据的方法,可以删掉一些已经不被 Iceberg 管理的无用的数据文件。我们是每周对 Iceberg 执行一次无效数据清理。
-- 清理无效文件
ALTER TABLE test_table EXECUTE remove_orphan_files(retention_threshold => '7d')
查询加速
我们都知道对 Iceberg Partition 列进行查询速度都很快,因为其过滤掉很多文件,只读取符合查询分区的数据文件。单读到底层的 ORC 数据文件时,Iceberg 提供了 min/max 等数据元信息,通过元信息可以快速得知所找的数据是否在此文件内。
Bloom Filter
在最新的 Iceberg 1.1.0 版本中,Iceberg 支持在 ORC 数据文件内设置 bloom filters。
而新版 Trino 也跟上 Iceberg 适配 bloom filter,我们需要在 trino-iceberg 的配置文件里配置,来开启 Trino 查询时使用 bloom filter 查询
hive.orc.bloom-filters.enabled = true
除此之外,我们还需要设置 Iceberg 表属性,对列配置上 bloom filter
CREATE TABLE iceberg_table (
token_address varchar,
from_address varchar,
to_address varchar,
block_timestamp timestamp(6) with time zone,
)
WITH (
orc_bloom_filter_columns = ARRAY['token_address','from_address','to_address'],
orc_bloom_filter_fpp = 0.05,
partitioning = ARRAY['day(block_timestamp)']
)
因为 bloom filter 是生效于 ORC 文件中,如果想要应用在旧表上,需要将旧表数据重写到新表上,这样底层的数据文件才带有 bloom filter。
举例:
假如我们有一张 token_transfer 表,表内大概有四个字段
- from_address 买方地址
- to_address 卖家地址
- token_address 交易代币
- block_timestamp 日期
我们对该表 from_address、to_address、token_address 应用 bloom filter,对 timestamp 进行分区。该表每天的数据量假设有 100w 条数据。
此时有俩类查询过来:
- 查询热门 token 今天发生的交易
select * from token_transfer
where token_address = '热门token' and block_timestamp > today
- 查询冷门 token 今天发生的交易
select * from token_transfer
where token_address = '冷门token' and block_timestamp > today
此时俩类查询的 bloom filter 产生的效果是不一样的,因为热门的 token 会存在大部分数据文件里,冷门的 token 大概率只存在于少部分数据文件内。对于热门 token,bloom filter 的加速效果不佳,但对于冷门 token,bloom filter 帮助其快速过滤掉了很多数据文件,快速找到有冷门 token 的数据文件,加速效果极佳。
所以得到的结论是,bloom filter 对一些 不重复,特征值很高的数据有比较好的加速效果。
Order & Z-Order
上文提到,ORC数据文件内有 min/max 值,查询引擎可以根据 min/max 值判断数据是否在此文件内。
可是日常在写入 Iceberg 的数据一般都是无序写入的,无序写入会导致每个数据文件也是无序的,不能发挥 min/max 过滤的效果。
Order
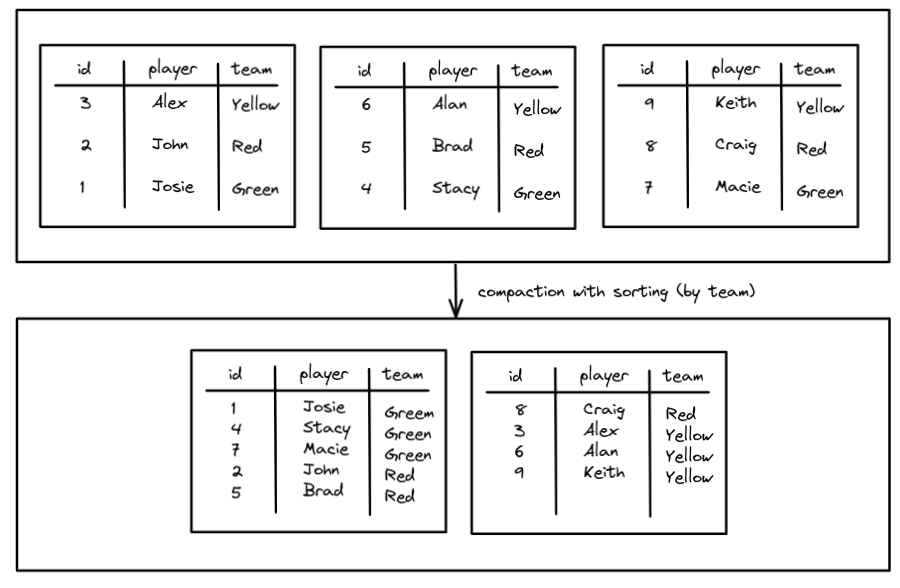
Spark 提供了一个压缩文件并排序的方法,可以将无序的文件按指定列排好序。排序策略不仅可以优化文件大小,还可以对数据进行排序以对数据进行聚类以获得更好的性能。将相似数据聚集在一起的好处是更少的文件可能具有与查询相关的数据,这意味着 min/max 的好处会更大(扫描的文件越少,速度越快)。
CALL catalog.system.rewrite_data_files(
table => 'db.teams',
strategy => 'sort',
sort_order => 'team ASC NULLS LAST, name DESC NULLS FIRST'
)
Z-Order
虽然 Order 排序可以同时对多列进行排序,但其列与列之间的排序是有先后顺序之分的,像是 MySQL 里的联合索引,先对 字段A 排序再对 字段B 排序。如果只是的查询的谓词只包含 字段B,则上述索引失效(先对 字段A 排序再对 字段B 排序)。
而 Z-Order 能解决上面的问题,使用 Z-Order 对多列排序,列与列之间的排序权重相同。所以使用 Z-Order 对多字段进行排序,查询中只要谓词命中了 Z-Order 中其中任何一字段,都能加速查询。
Spark 提供了使用 Z-Order 的方法
CALL catalog.system.rewrite_data_files(
table => 'db.people',
strategy => 'sort',
sort_order => 'zorder(height_in_cm, age)'
)
差异
我们测试过对 100G 的表分别进行 Order 和 Z-Order,命中 Order 最高能带来 10 倍的性能提升,命中 Z-Order 能带来 2 倍的性能提升。粗步得到的结论是,Order 比 Z-Order 大致快 2 倍。
所以在实践应用上不能盲目选择 Z-Order,得根据这张表的热门查询SQL、字段特征、数量来做:
- 查询字段是数据连续且范围小的,选 Order
- 查询字段具有高基数特征,选 Z-Order
- 频繁查询此表多个字段的,选 Z-Order,否则 Order 的性能会更好
小结
Iceberg 做了很多功夫去加速查询,本文中提到的小文件合并、快照清理、Bloom Filter、Order、Z-Order 都是为了在查询时跳过无用的文件,通过减少磁盘 IO 操作来加速查询。Trino 和 Spark 提供许多便利的方法给开发者维护治理 Iceberg;数据治理这块成本比较低,可以写好自动化脚本每天执行数据治理;查询加速这里的维护成本比较高,都是需要重写元数据和数据文件的操作,一般每月做一次重写操作。
参考文章:
- https://zhuanlan.zhihu.com/p/472617094
- https://www.dremio.com/blog/compaction-in-apache-iceberg-fine-tuning-your-iceberg-tables-data-files/
Iceberg 数据治理及查询加速实践的更多相关文章
- Data.gov.uk电子政务云,牛津大学NIE金融大数据实验室王宁:数据治理的现状和实践
牛津大学NIE金融大数据实验室王宁:数据治理的现状和实践 我是牛津互联网研究院的研究员,是英国开放互联网的一个主要的研究机构和相关政策制订的一个机构.今天主要给大家介绍一下英国数据治理的一些现状和实践 ...
- 李呈祥:bilibili在湖仓一体查询加速上的实践与探索
导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践.主要内容包括: 什么是湖仓一体架构 哔哩哔哩目前的湖仓一体架构 湖仓一体架构下,数据的排序组织优化 湖仓一 ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- 好未来数据中台 Node.js BFF实践(一):基础篇
好未来数据中台 Node.js BFF实践系列文章列表: 基础篇 实战篇(TODO) 进阶篇(TODO) 好未来数据中台的Node.js中间层从7月份开始讨论可行性,截止到9月已经支持了4个平台,其中 ...
- 数据治理之元数据管理的利器——Atlas入门宝典
随着数字化转型的工作推进,数据治理的工作已经被越来越多的公司提上了日程.作为Hadoop生态最紧密的元数据管理与发现工具,Atlas在其中扮演着重要的位置.但是其官方文档不是很丰富,也不够详细.所以整 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 一文读懂 Spring Boot、微服务架构和大数据治理三者之间的故事
微服务架构 微服务的诞生并非偶然,它是在互联网高速发展,技术日新月异的变化以及传统架构无法适应快速变化等多重因素的推动下诞生的产物.互联网时代的产品通常有两类特点:需求变化快和用户群体庞大,在这种情况 ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
随机推荐
- Visual Studio高版本 ArcObject for .Net 低版本
在基于ArcGIS的开发中,经常会存在Visual Studio版本高,ArcObject for .Net 版本低的问题.例如Visual Studio 2015的环境下,安装ArcObject f ...
- JavaEE Day03 MySQL约束
MySQL约束--今日内容 1. SQL-(DDL,DML,DQL),讲完DQL查询语句的使用 排序查询 聚合函数 分组查询 分页查询 2. 约束 3. 多表之间的关系 4. 范式(用于更好地设计表, ...
- 【每日一题】【暴力&双指针&动态规划】42. 接雨水-211130/220214
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水. 方法1:暴力求解(超时) import java.util.*; public class Solu ...
- java并发数据结构之CopyOnWriteArrayList
CopyOnWriteArrayList是一个线程安全的List实现,其在对对象进行读操作时,由于对象没有发生改变,因此不需要加锁,反之在对象进行增删等修改操作时,它会先复制一个对象副本,然后对副本进 ...
- Day37:正则表达式详解
正则表达式 1.1 概述 正则表达式可以用一些规定的字符来制定规则,并用来校验数据格式的合法性. 比如我们在网站上输入用户账号,要求我们输入的账号信息要符合账号的格式,而校验我们输入的账号格式是否正确 ...
- 常用模块二——hashlib加密模块,subprocess模块,logging日志模块
一.hashlib加密模块 1.何为加密 将明文数据处理成密文数据 让人无法看懂 2.为什么加密 保证数据的安全 3.如何判断数据是否是加密的 一串没有规律的字符串(数字.字母.符号) 4.密文的长短 ...
- C语言读写txt文件
写入和读取txt文件 #include<stdio.h> #include<string.h> int main( int argc, char *argv[] ) { int ...
- [0x12] 132.小组队列
题意 link(more:UVA540) 简化题意:对 \(n\) 个小组排队,每个小组有至多 \(m\) 个成员(每个成员有唯一编号 \(x\)),当一个人来到队伍时,如果队中有同组成员,直接插入其 ...
- wsl2 kali修改语言
直接执行sudo dpkg-reconfigure locales 会提示 dpkg-query: package 'locales' is not installed and no informat ...
- .Net 7 团队把国内的龙芯确实当做一等公民和弃用的项目
楔子: 国内龙芯据说是用的自己的指令集,在研究ILC的时候,发现了龙芯在微软那边确实是一等公民的存在. 龙芯官网 龙芯平台.NET,是龙芯公司基于开源社区.NET独立研发适配的龙芯版本,我们会长期进行 ...