RocketMQ - 消费者概述
消费流程
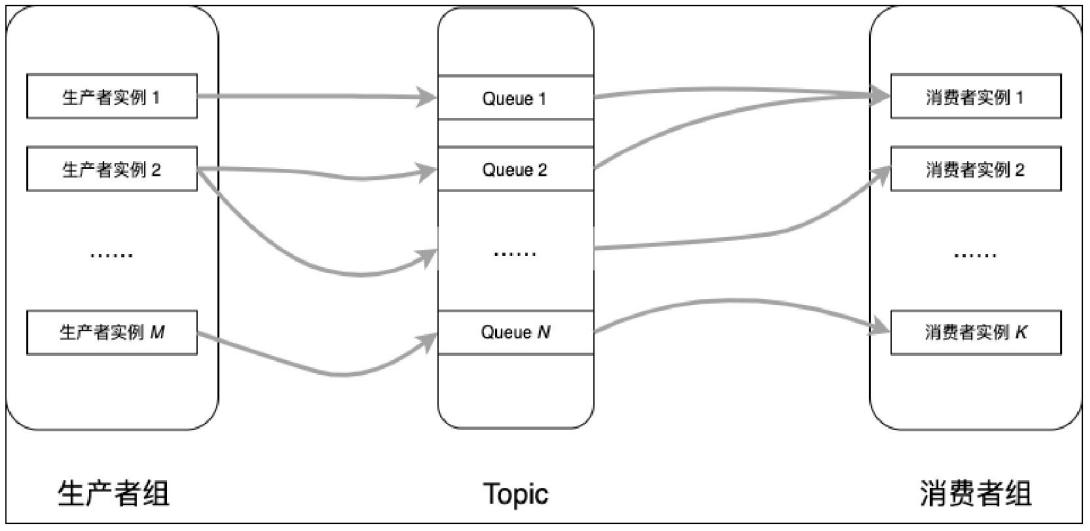
消费者组: 一个逻辑概念,在使用消费者时需要指定一个组名。一个消费者组可以订阅多个Topic。
消费者实例: 一个消费者组程序部署了多个进程,每个进程都可以称为一个消费者实例。
订阅关系: 一个消费者组订阅一个 Topic 的某一个 Tag,这种记录被称为订阅关系。RocketMQ规定消费订阅关系(消费者组名-Topic-Tag)必须一致——在此,笔者想提醒读者,一定要重视这个问题,一个消费者组中的实例订阅的Topic和Tag必须完全一致,否则就是订阅关系不一致。订阅关系不一致会导致消费消息紊乱。
消费模式
RocketMQ目前支持集群消费模式和广播消费模式,其中集群消费模式使用最为广泛
集群消费模式
在同一个消费者组中的消费者实例,是负载均衡(策略可以配置)地消费Topic中的消息,假如有一个生产者(Producer)发送了 120 条消息,其所属的 Topic 有 3 个消费者(Consumer)组,每个消费者组设置为集群消费,分别有2个消费者实例,如图所示。
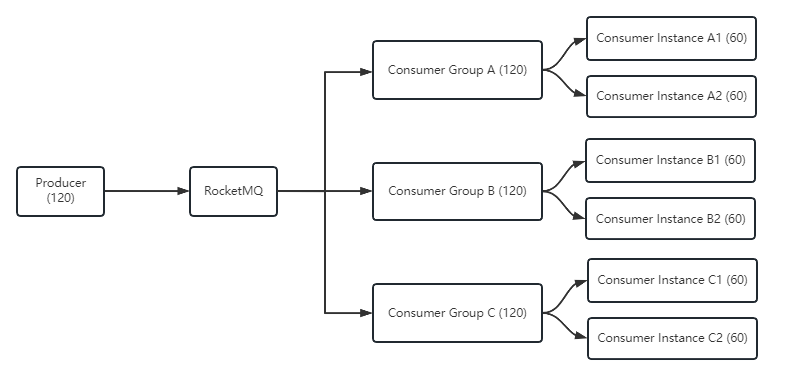
Consumer Group A 的两个实例 Consumer Instance A1 和 Consumer Instance A2 分别负载均衡地消费60条消息。由此我们可以得出使用负载均衡策略时,每个消费者实例消费消息数=生产消息数/消费者实例数,在本例中是60=120/2
适用场景: 目前大部分场景都适合集群消费模式,RocketMQ 的消费模式默认是集群消费。比如异步通信、削峰等对消息没有顺序要求的场景都适合集群消费。因为集群模式的消费进度是保存在Broker端的,所以即使应用崩溃,消费进度也不会出错。
广播消费模式
广播消费,顾名思义全部的消息都是广播分发,即消费者组中的全部消费者实例将消费整个 Topic 的全部消息。比如,有一个生产者生产了 120 条消息,其所属的 Topic 有 3个消费者组,每个消费者组设置为广播消费,分别有两个消费者实例,如图所示。
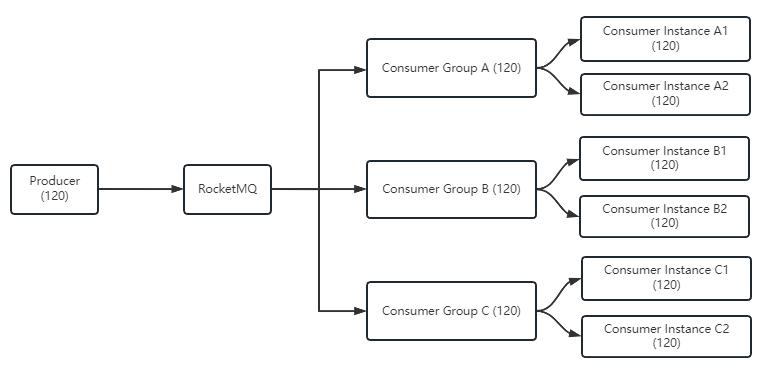
Consumer Group A 的两个实例 Consumer Instance A1 和 Consumer Instance A2 分别消费120条消息。整个消费者组收到消息120×2=240条。由此我们可以得出广播消费时,每个消费者实例的消费消息数=生产者生产的消息数,整个消费者组中所有实例消费消息数=每个消费者实例消费消息数×消
费者实例数,本例中是240=120×2
适用场景: 广播消费比较适合各个消费者实例都需要通知的场景,比如刷新应用服务器中的缓存,如图所示。
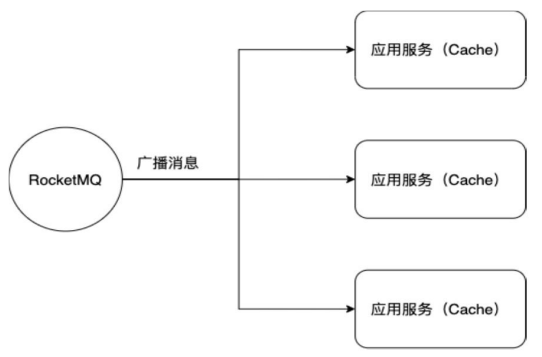
生产者发一个刷新缓存的广播消息,消费者组如果设置为广播消费,那么每个应用服务中的消费者都可以消费这个消息,也都能刷新缓存。
广播消费的消费进度保存在客户端机器的文件中。如果文件弄丢了,那么消费进度就丢失了,可能会导致部分消息没有消费
可靠消费
RocketMQ是一种十分可靠的消息队列中间件,消费侧通过重试-死信机制、Rebalance机制等多种机制保证消费的可靠性。
重试-死信机制
我们假设有一个场景,在消费消息时由于网络不稳定导致一条消息消费失败。此时是让生产者重新手动发消息呢,还是自己做数据补偿?
横向看,RocketMQ的消费过程分为 3个阶段:正常消费、重试消费和死信。在引进了正常Topic、重试队列、死信队列后,消费过程的可靠性提高了。RocketMQ的消费流程如图所示
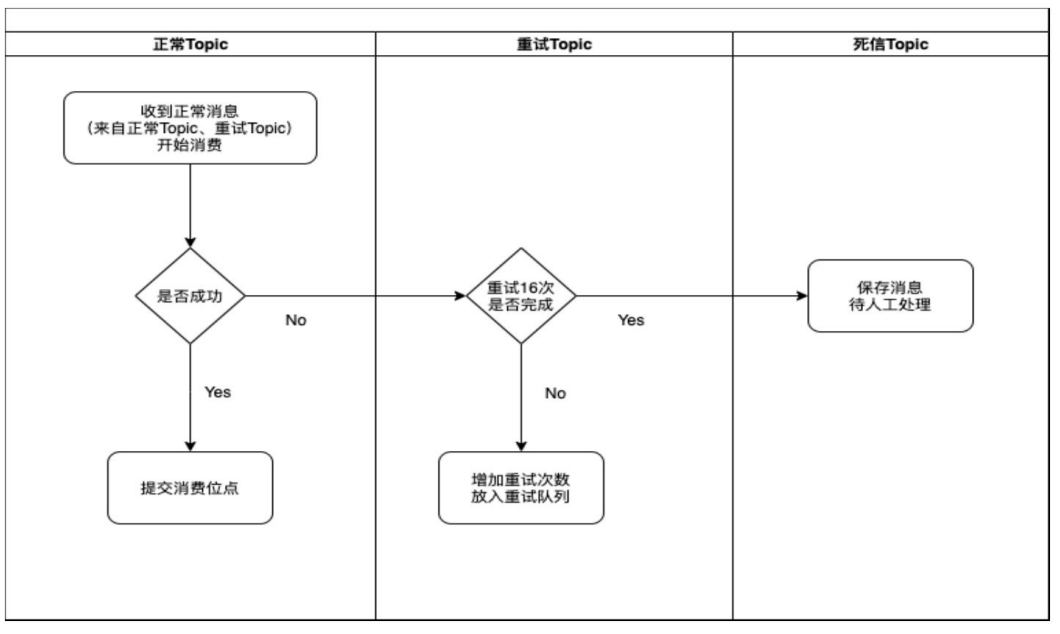
正常Topic: 正常消费者订阅的Topic名字。
重试Topic: 如果由于各种意外导致消息消费失败,那么该消息会自动被保存到重试Topic中,格式为“%RETRY%消费者组”,在订阅的时候会自动订阅这个重试Topic。
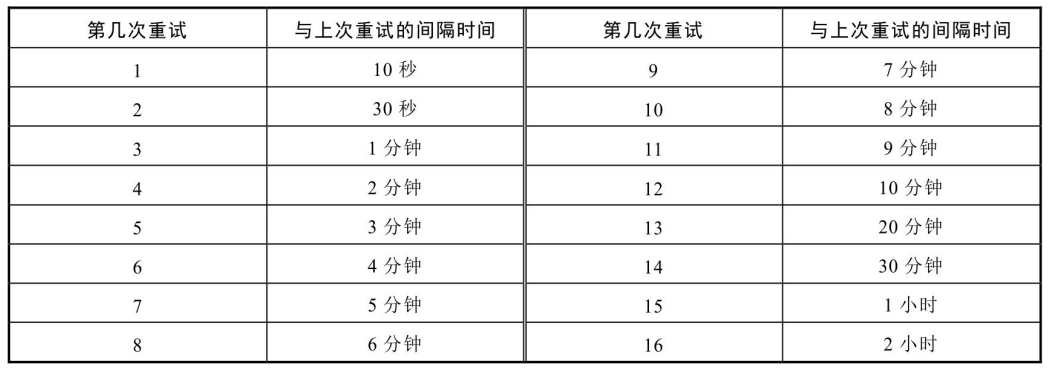
进入重试队列的消息有16次重试机会,每次都会按照一定的时间间隔进行。RocketMQ 认为消费不是一锤子买卖,可能由于各种偶然因素导致正常消费失败,只要正常消费或者重试消费中有一次消费成功,就算消费成功
死信Topic: 死信Topic名字格式为“%DLQ%消费者组名”。如果正常消费1次失败,重试16次失败,那么消息会被保存到死信Topic中,进入死信Topic的消息不能被再次消费。RocketMQ认为,如果17次机会都失败了,说明生产者发送消息的格式发生了变化,或者消费服务出现了问题,需要人工介入处理。
Rebalance机制
Rebalance(重平衡)机制,用于在发生Broker掉线、Topic扩容和缩容、消费者扩容和缩容等变化时,自动感知并调整自身消费,以尽量减少甚至避免消息没有被消费。后面会详细讲述Rebalance的过程。
死信队列
当一条消息初次消费失败,消息队列RocketMQ版会自动进行消息重试,达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息。此时,消息队列RocketMQ版不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
在消息队列RocketMQ版中,这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)
死信消息具有以下特性:
- 不会再被消费者正常消费。
- 有效期与正常消息相同,默认为3天,3天后会被自动删除。因此,请在死信消息产生后的3天内及时处理。
死信队列具有以下特性:
- 一个死信队列对应一个Group ID, 而不是对应单个消费者实例。
- 如果一个Group ID未产生死信消息,消息队列RocketMQ版不会为其创建相应的死信队列。
- 一个死信队列包含了对应Group ID产生的所有死信消息,不论该消息属于哪个Topic。
RocketMQ - 消费者概述的更多相关文章
- RocketMQ消费者示例程序
转载请注明出处:http://www.cnblogs.com/xiaodf/ 本博客实现了一个简单的RocketMQ消费者的示例,MQ里存储的是经过Avro序列化的消息数据,程序读取数据并反序列化后, ...
- 深入研究RocketMQ消费者是如何获取消息的
前言 小伙伴们,国庆都过的开心吗?国庆后的第一个工作日是不是很多小伙伴还沉浸在假期的心情中,没有工作状态呢? 那王子今天和大家聊一聊RocketMQ的消费者是如何获取消息的,通过学习知识来找回状态吧. ...
- RocketMQ消费者实践
最近工作中用到了RocketMQ,现记录下,如何正确实现消费~ 消费者需要注意的问题 防止重复消费 如何快速消费 消费失败如何处理 Consumer具体实现 防止重复消费 重复消费会造成数据不一致等问 ...
- RocketMQ 消费者
本文分析 DefaultMQPushConsumer,异步发送消息,多线程消费的情形. DefaultMQPushConsumerImpl MQClientInstance 一个客户端进程只有一个 M ...
- rocketmq消息存储概述
了解消息存储部分首先需要关注的几个方法,load()--Load previously stored messages.start()--Launch this message store.putMe ...
- RocketMQ学习分享
消息队列的流派 什么是 MQ Message Queue(MQ),消息队列中间件.很多人都说:MQ 通过将消息的发送和接收分离来实现应用程序的异步和解偶,这个给人的直觉是——MQ 是异步的,用来解耦的 ...
- RocketMQ入门案例
学习RocketMQ,先写一个Demo演示一下看看效果. 一.服务端部署 因为只是简单的为了演示效果,服务端仅部署单Master模式 —— 一个Name Server节点,一个Broker节点.主要有 ...
- rocketmq 控制台 trackType NOT_CONSUME_YET
1. 问题描述 rocketmq消费者偶有没有收到消息,查看后台, 显示NOT_CONSUME_YET 2. 分析 mq控制台 显示有该条消息数据 只是状态为未消费 那么问题应该出在 消费者一方 诶? ...
- SpringBoot2.0 整合 RocketMQ ,实现请求异步处理
一.RocketMQ 1.架构图片 2.角色分类 (1).Broker RocketMQ 的核心,接收 Producer 发过来的消息.处理 Consumer 的消费消息请求.消息的持 久化存储.服务 ...
- RocketMQ之一:RocketMQ整体介绍
常用MQ介绍及对比--<MQ详解及四大MQ比较> RocketMQ环境搭建--<RocketMQ之三:RocketMQ集群环境搭建> RocketMQ物理部署结构 Rocket ...
随机推荐
- .NET MAUI 安卓应用开发初体验
一..NET MAUI开发环境搭建&安卓SDK和安卓模拟器安装提示网络连接失败问题解决 引言 本节目标是帮助第一次搭建.NET MAUI开发环境,在下载安卓SDK和安卓模拟器过程中一直提示网络 ...
- SpringCloud Alibaba(六) - Seata 分布式事务锁
1.Seata 简介 1.1 Seata是什么 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务.Seata 将为用户提供了 AT.TCC.SAGA 和 XA 事 ...
- 大数据-业务数据采集-FlinkCDC
CDC CDC 是 Change Data Capture(变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入.更新以及删除等),将这些变更按发生的顺序完整记录下来,写入 ...
- JavaScript入门⑧-事件总结大全
JavaScript入门系列目录 JavaScript入门①-基础知识筑基 JavaScript入门②-函数(1)基础{浅出} JavaScript入门③-函数(2)原理{深入}执行上下文 JavaS ...
- 如何用 30s 给面试官讲清楚跳表
查找 假设有如下这样一个有序链表: 想要查找 24.43.59,按照顺序遍历,分别需要比较的次数为 2.4.6 目前查找的时间复杂度是 O(N),如何提高查找效率? 很容易想到二分查找,将查找的时间复 ...
- 高可用系列文章之三 - NGINX 高可用实施方案
前文链接 高可用系列文章之一 - 概述 - 东风微鸣技术博客 (ewhisper.cn) 高可用系列文章之二 - 传统分层架构技术方案 - 东风微鸣技术博客 (ewhisper.cn) 四 NGINX ...
- python循环结构之for循环
在python中,for循环是应用非常广的循环语句,遍历字典.遍历列表等等... # for语句结构 for 遍历 in 序列: 执行语句 遍历字典 lipsticks = {"Chanel ...
- php的可变变量覆盖漏洞
题目如下: <?php highlight_file('source.txt'); echo "<br><br>"; $flag = 'xxxxxxx ...
- MYSQL进阶学习笔记
MySQL在Linux中的使用: 1.查看mysql在linux的安装版本 mysqladmin –version 2.mysql服务的启动与停止 (1).启动: service mysql star ...
- 1+X Web初级笔记查漏补缺+练习题
学习笔记: position:relative是相对定位,是相对于自身位置移动,但是占据原有空间 absolute是绝对定位,原有空间不保留会被其他元素挤占 绝对定位 absolute不占位置完全浮动 ...