Pytorch实战学习(九):进阶RNN
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Advance RNN
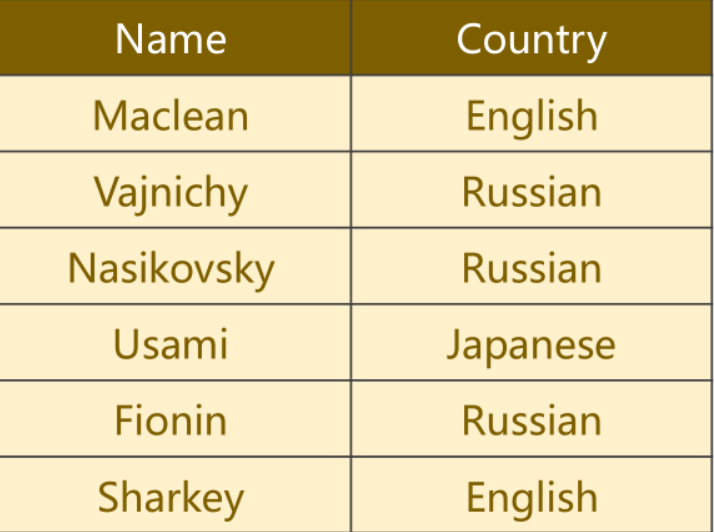
1、RNN分类问题
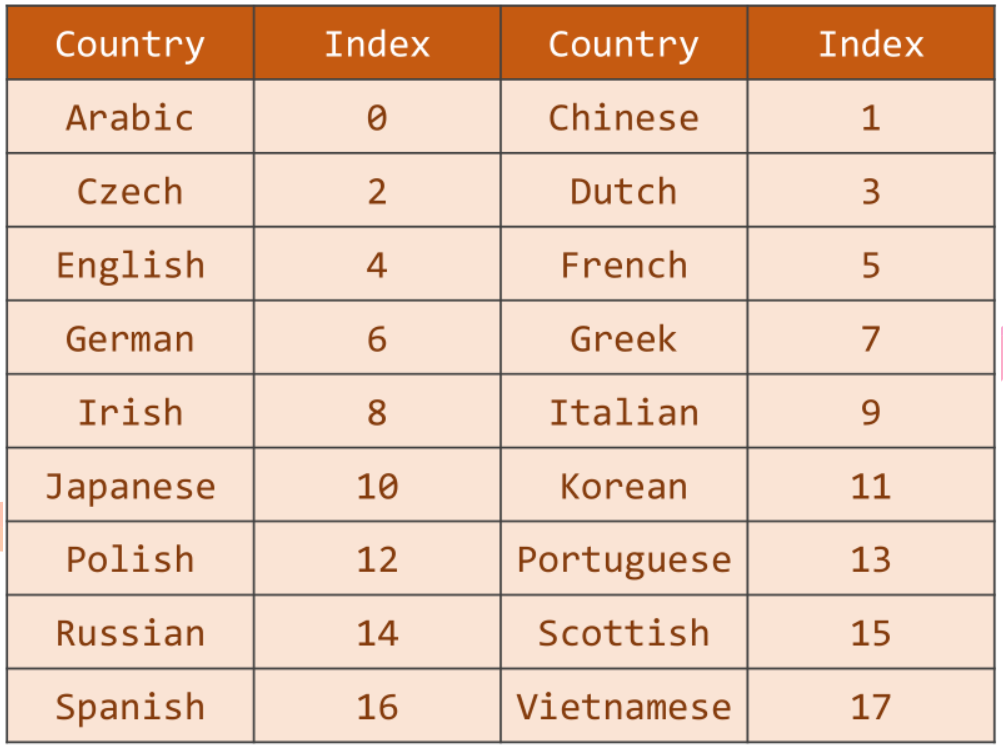
判断数据集中的每个名字所属的国家,共有18个国家类别
2、网络结构
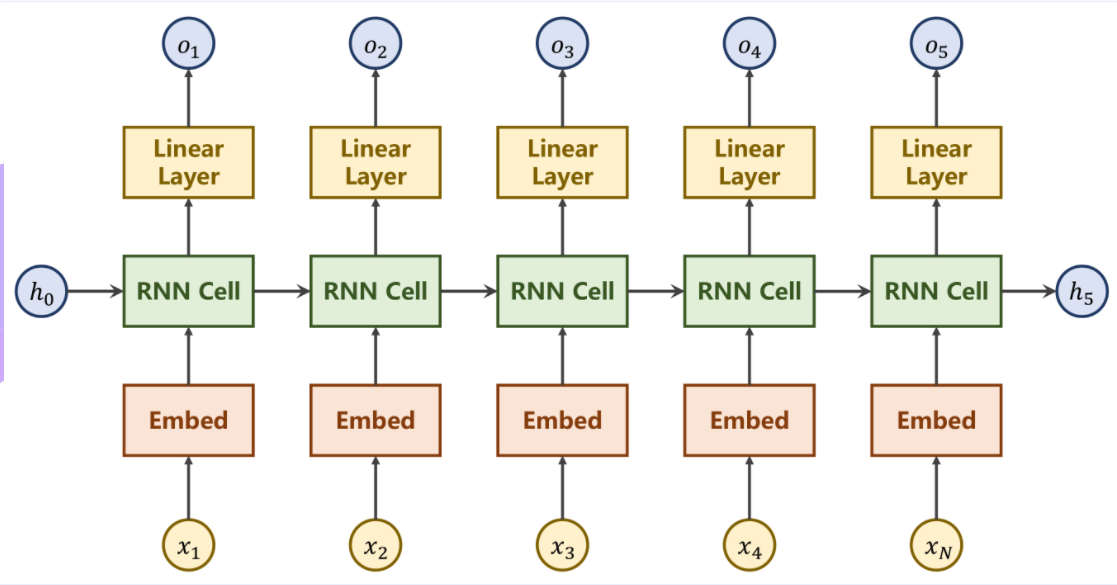
①基础RNN
seq2seq,可以解决自动翻译问题
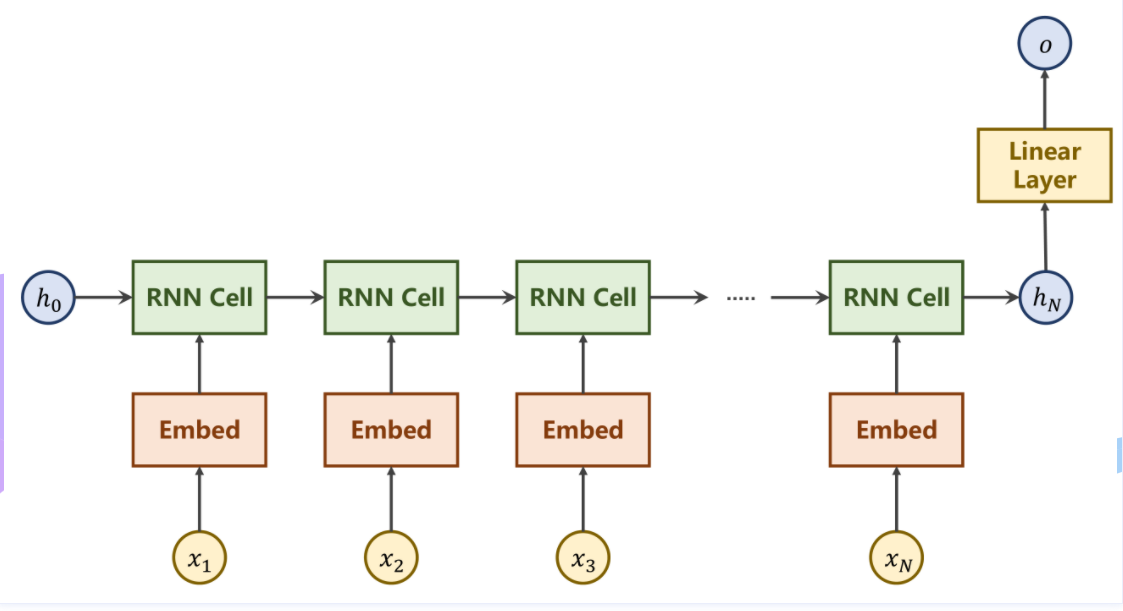
②简化RNN
利用最终的隐藏层状态 h_H 通过一个线性层来
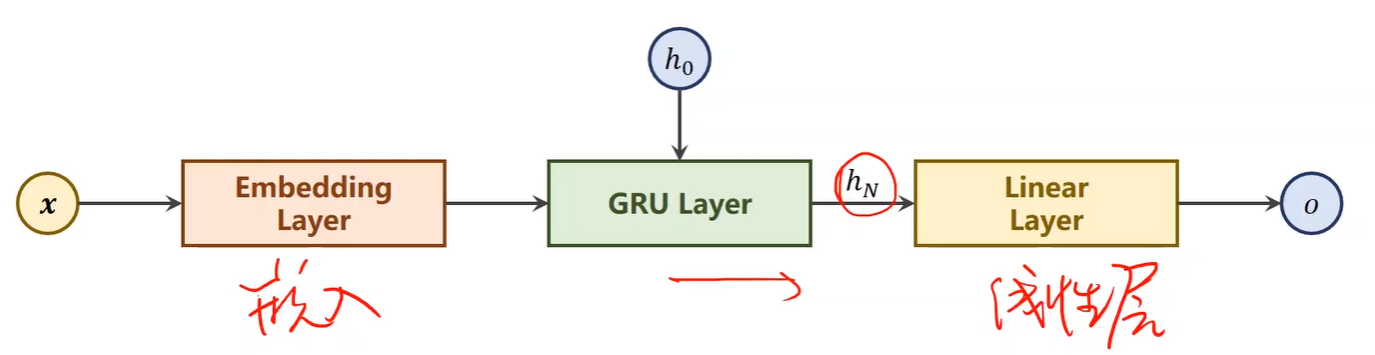
③本例具体结构
3、输入数据
文本数据
数据中的每个名字,实际上是一个序列,每个字母是序列中的一个输入,处理远比想象中费力
每个名字长短不一,即序列之间本身的长度是不固定的。
4、代码部分啦
①Main Cycle
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m*60
return '%dm %ds' % (m, s) if __name__ == '__main__':
'''
N_CHARS:字符数量,英文字母转变为One-Hot向量
HIDDEN_SIZE:GRU输出的隐层的维度
N_COUNTRY:分类的类别总数
N_LAYER:GRU层数
'''
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
#迁移至GPU
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device) criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001) # 记录训练的时长
start = time.time()
print("Training for %d epochs ... " % N_EPOCHS)
#记录训练准确率
acc_list = []
for epoch in range(1, N_EPOCHS+1):
#训练模型
trainModel()
#检测模型
acc = testModel()
acc_list.append(acc) #绘制图像
epoch = np.arange(1, len(acc_list)+1, 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
②Preparing Data
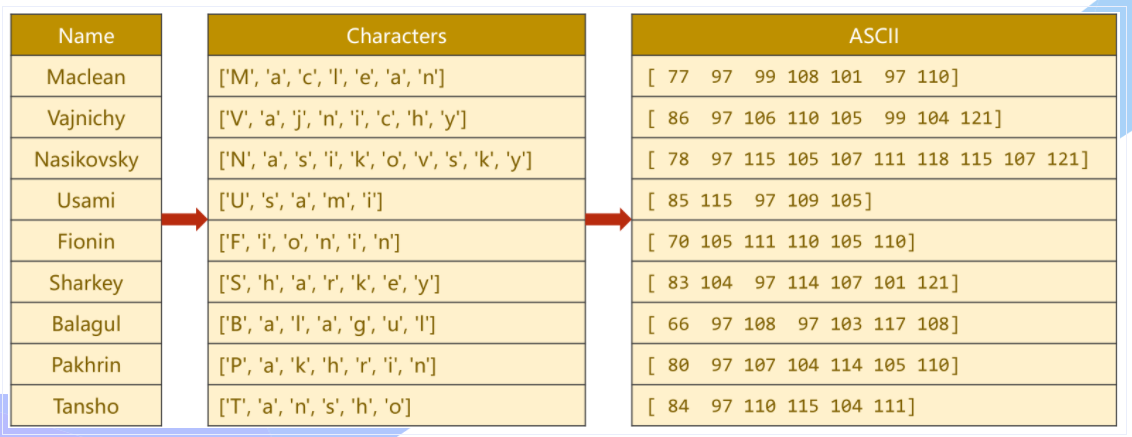
先将【Name】单词拆分成 字符,再用ASCII作为字典
每一个ASCII码值实际上代表着一个长为128的独热向量,以77为例,即在77处为1,其余全部为0
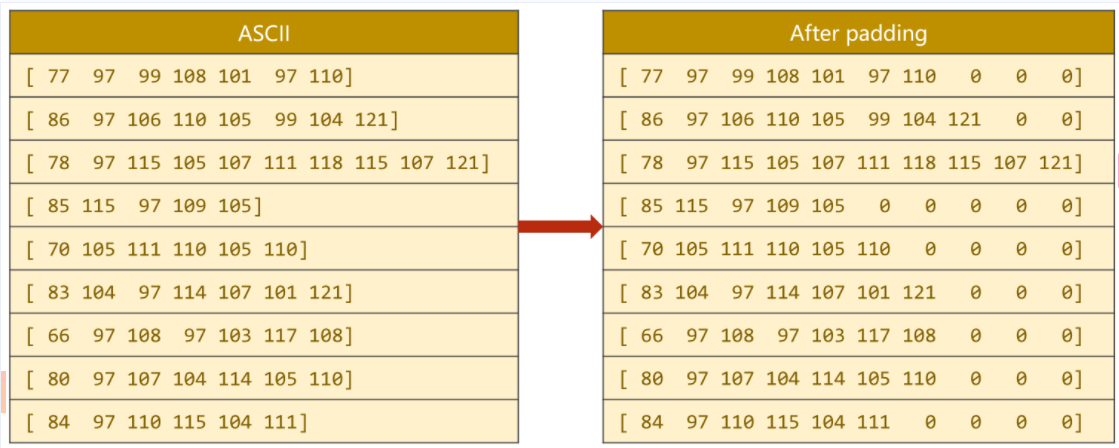
为保证计算,需要将所有输入的名字填充至等长,即进行padding填充,使之能够成为矩阵(张量)
输出的国家类别形成分类索引
##Preparing Data
class NameDataset(Dataset):
def __init__(self, is_train_set=True): #读数据
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader) #数据元组(name,country),将其中的name和country提取出来,并记录数量
self.names = [row[0] for row in rows]
self. len = len(self.names)
self.countries = [row[1] for row in rows] #将country转换成索引
#列表->集合->排序->列表->字典
# set将列表变成集合(去重)--排序--列表
self.country_list = list(sorted(set(self.countries)))
#列表->字典
self.country_dict = self.getCountryDict()
#获取长度
self.country_num = len(self.country_list) #name是字符串
#country是字典,获取键值对,country(key)-index(value)
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]] def __len__(self):
return self.len def getCountryDict(self):
country_dict = dict()
for idx,country_name in enumerate(self.country_list, 0):
country_dict[country_name]=idx
return country_dict #根据索引返回国家名
def idx2country(self, index):
return self.country_list[index] #返回国家数目
def getCountriesNum(self):
return self.country_num # 参数设置
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2 #GRU2层
N_EPOCHS = 100
N_CHARS = 128 #字典长度(ASCII码)
USE_GPU = False # 实例
trainset = NameDataset(is_train_set = True)
# 加载器
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True) testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False) #最终的输出维度(国家类别数量)
N_COUNTRY = trainset.getCountriesNum()
③Model Design
## Model Design
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers =1 , bidirectional = True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1 #Embedding层输入 (SeqLen,BatchSize)
#Embedding层输出 (SeqLen,BatchSize,HiddenSize)
#将原先样本总数为SeqLen,批量数为BatchSize的数据,转换为HiddenSize维的向量
self.embedding = torch.nn.Embedding(input_size, hidden_size)
#bidirection用于表示神经网络是单向还是双向
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional = bidirectional)
#线性层需要*direction
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def _init_hidden(self):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size) return create_tensors(hidden) def forward(self, input, seq_length):
#对input进行转置:Batch x Seq -> Batch x Seq
input = input.t()
batch_size = input.size(1) #(n_Layer * nDirections, BatchSize, HiddenSize)
hidden = self._init_hidden(batch_size)
#(SeqLen, BatchSize, HiddenSize)
embedding = self.embedding(input) #对数据计算过程提速
#需要得到嵌入层的结果(输入数据)及每条输入数据的长度
gru_input = pack_padded_sequence(embedding, seq_length) output, hidden = self.gru(gru_input, hidden) #如果是双向神经网络会有h_N^f以及h_N^b两个hidden
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1] fc_output = self.fc(hidden_cat) return fc_output
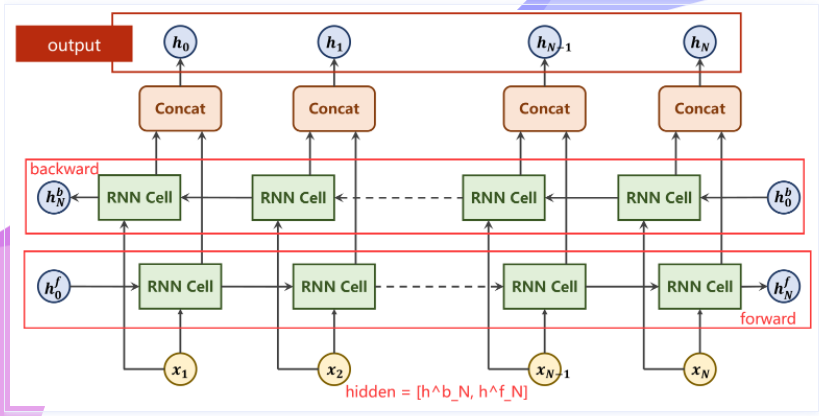
Bi-direction RNN/LSTM/GRU
全面考虑上下文信息
对于RNN系列的网络而言,其输出包括output以及hidden两部分。
output:序列对应输出,也就是 h_1....h_N
hidden:hidden指的是隐含层最终输出结果,在双向网络中即为 h_f_N 和 h_b_N
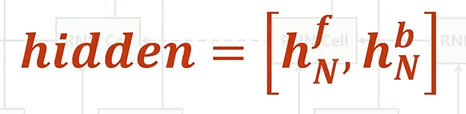

数据转置
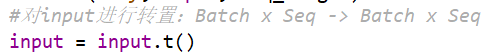

pack_padded_sequence
其原理在于,由于先前对于长短不一的数据需要填充0,而填充的0本质上不必参与运算,因此可以进行优化。
Embedding变换后的结果如图所示,其中深色部分为实际值为0即padding的部分。这部分可以不用参与运算。
***填充0的Embedding大小应该一样,下图有误***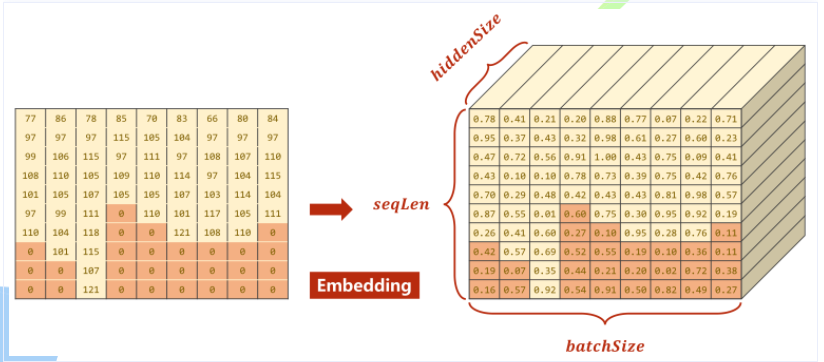
Batch中的序列先按照序列长短进行降序排序
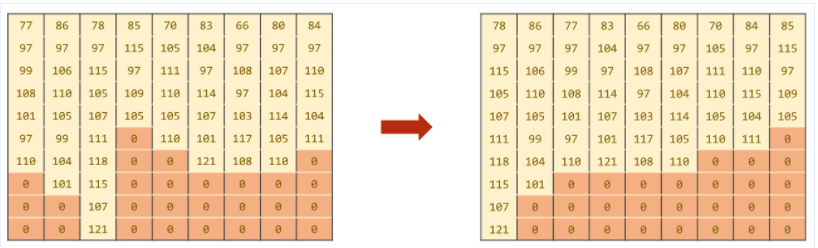
然后记录真正有意义的数字以及该序列的真正长度,最终返回一个PackedSequence对象
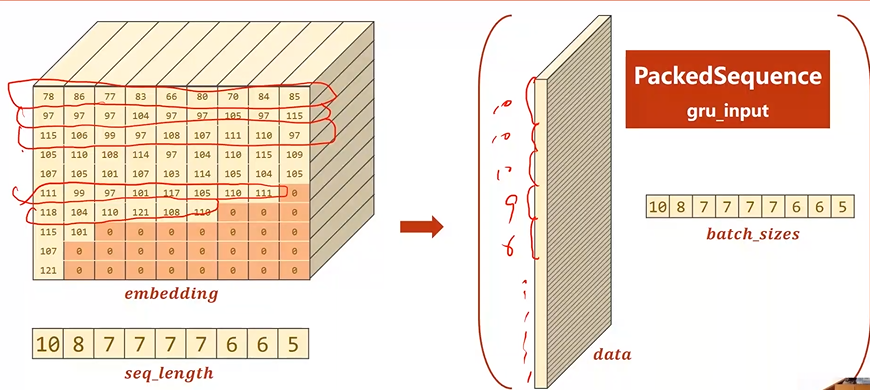
Name 转换成 Tensor
需要 Batch_size、Seq_size 和 每个name长度组成的list
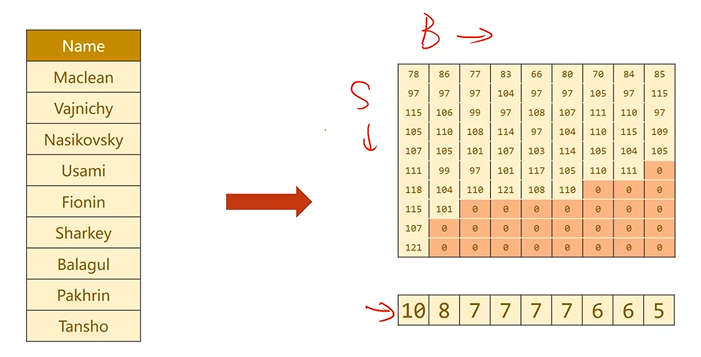
转换过程:
字符串 → 字符 → ASCII码值 → Padding → 转置 → 排序
#ord()取ASCII码值
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr) def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor def make_tensors(names, countries):
sequences_and_length = [name2list(name) for name in names]
#取出所有的列表中每个姓名的ASCII码序列
name_sequences = [s1[0] for s1 in sequences_and_length]
#将列表车行度转换为LongTensor
seq_length = torch.LongTensor([s1[1] for s1 in sequences_and_length])
#将整型变为长整型
countries = countries.long() #做padding
#新建一个全0张量大小为最大长度-当前长度
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
#取出每个序列及其长度idx固定0
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_length), 0):
#将序列转化为LongTensor填充至第idx维的0到当前长度的位置
seq_tensor[idx, :seq_len] = torch.LongTensor(seq) #返回排序后的序列及索引
seq_length, perm_idx = seq_length.sort(dim = 0, descending = True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx] return create_tensor(seq_tensor),
create_tensor(seq_length),
create_tensor(countries)
④Training & Test
def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step() total_loss += loss.item() if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch} ', end='')
print(f'[{i * len(inputs)}/{len(train_set)}]', end='')
print(f'loss={total_loss / (i * len(inputs))}') return total_loss def testModel():
correct = 0
total = len(testset)
print("evaluating trained model……")
# 测试不需要求梯度
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item() percent = '%.2f' % (100*correct/total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct/total
⑤完整代码
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import gzip
import csv
import time
from torch.nn.utils.rnn import pack_padded_sequence
import math
#可不加
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" ##Preparing Data
class NameDataset(Dataset):
def __init__(self, is_train_set=True): #读数据
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader) #数据元组(name,country),将其中的name和country提取出来,并记录数量
self.names = [row[0] for row in rows]
self. len = len(self.names)
self.countries = [row[1] for row in rows] #将country转换成索引
#列表->集合->排序->列表->字典
# set将列表变成集合(去重)--排序--列表
self.country_list = list(sorted(set(self.countries)))
#列表->字典
self.country_dict = self.getCountryDict()
#获取长度
self.country_num = len(self.country_list) #name是字符串
#country是字典,获取键值对,country(key)-index(value)
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]] def __len__(self):
return self.len def getCountryDict(self):
country_dict = dict()
for idx,country_name in enumerate(self.country_list, 0):
country_dict[country_name]=idx
return country_dict #根据索引返回国家名
def idx2country(self, index):
return self.country_list[index] #返回国家数目
def getCountriesNum(self):
return self.country_num # 参数设置
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2 #GRU2层
N_EPOCHS = 100
N_CHARS = 128 #字典长度(ASCII码)
USE_GPU = False # 实例
trainset = NameDataset(is_train_set = True)
# 加载器
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True) testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False) #最终的输出维度(国家类别数量)
N_COUNTRY = trainset.getCountriesNum() ## Model Design
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers =1 , bidirectional = True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1 #Embedding层输入 (SeqLen,BatchSize)
#Embedding层输出 (SeqLen,BatchSize,HiddenSize)
#将原先样本总数为SeqLen,批量数为BatchSize的数据,转换为HiddenSize维的向量
self.embedding = torch.nn.Embedding(input_size, hidden_size)
#bidirection用于表示神经网络是单向还是双向
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional = bidirectional)
#线性层需要*direction
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size) return hidden def forward(self, input, seq_length):
#对input进行转置:Batch x Seq -> Batch x Seq
input = input.t()
batch_size = input.size(1) #(n_Layer * nDirections, BatchSize, HiddenSize)
hidden = self._init_hidden(batch_size)
#(SeqLen, BatchSize, HiddenSize)
embedding = self.embedding(input) #对数据计算过程提速
#需要得到嵌入层的结果(输入数据)及每条输入数据的长度
gru_input = pack_padded_sequence(embedding, seq_length) output, hidden = self.gru(gru_input, hidden) #如果是双向神经网络会有h_N^f以及h_N^b两个hidden
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1] fc_output = self.fc(hidden_cat) return fc_output #ord()取ASCII码值
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr) def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor ## Name 转换成 Tensor
def make_tensors(names, countries):
sequences_and_length = [name2list(name) for name in names]
#取出所有的列表中每个姓名的ASCII码序列
name_sequences = [s1[0] for s1 in sequences_and_length]
#将列表车行度转换为LongTensor
seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_length])
#将整型变为长整型
countries = countries.long() #做padding
#新建一个全0张量大小为最大长度-当前长度
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
#取出每个序列及其长度idx固定0
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
#将序列转化为LongTensor填充至第idx维的0到当前长度的位置
seq_tensor[idx, :seq_len] = torch.LongTensor(seq) #返回排序后的序列及索引
seq_lengths, perm_idx = seq_lengths.sort(dim = 0, descending = True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx] return create_tensor(seq_tensor), create_tensor(seq_lengths), create_tensor(countries) def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step() total_loss += loss.item() if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch} ', end='')
print(f'[{i * len(inputs)}/{len(trainset)}]', end='')
print(f'loss={total_loss / (i * len(inputs))}') return total_loss def testModel():
correct = 0
total = len(testset)
print("evaluating trained model……")
# 测试不需要求梯度
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries)
output = classifier(inputs, seq_lengths)
pred = output.max(dim=1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item() percent = '%.2f' % (100*correct/total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct/total def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m*60
return '%dm %ds' % (m, s) if __name__ == '__main__':
'''
N_CHARS:字符数量,英文字母转变为One-Hot向量
HIDDEN_SIZE:GRU输出的隐层的维度
N_COUNTRY:分类的类别总数
N_LAYER:GRU层数
'''
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
#迁移至GPU
if USE_GPU:
device = torch.device("cuda:0")
classifier.to(device) criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001) # 记录训练的时长
start = time.time()
print("Training for %d epochs ... " % N_EPOCHS)
#记录训练准确率
acc_list = []
for epoch in range(1, N_EPOCHS+1):
#训练模型
trainModel()
#检测模型
acc = testModel()
acc_list.append(acc) #绘制图像
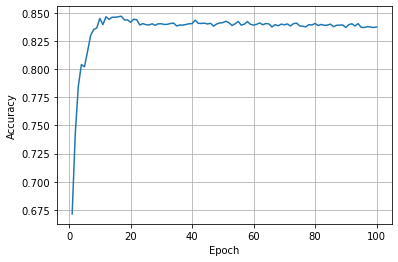
epoch = np.arange(1, len(acc_list)+1, 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
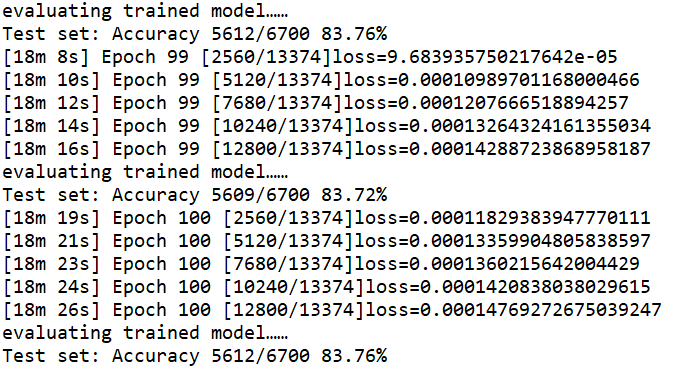
运行结果:准确率最高 83.79%,训练100次,花费18分半钟
Pytorch实战学习(九):进阶RNN的更多相关文章
- 深度学习之PyTorch实战(1)——基础学习及搭建环境
最近在学习PyTorch框架,买了一本<深度学习之PyTorch实战计算机视觉>,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架. PyTorch ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- 参考《深度学习之PyTorch实战计算机视觉》PDF
计算机视觉.自然语言处理和语音识别是目前深度学习领域很热门的三大应用方向. 计算机视觉学习,推荐阅读<深度学习之PyTorch实战计算机视觉>.学到人工智能的基础概念及Python 编程技 ...
- 『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)
深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新 ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- [原创].NET 业务框架开发实战之九 Mapping属性原理和验证规则的实现策略
原文:[原创].NET 业务框架开发实战之九 Mapping属性原理和验证规则的实现策略 .NET 业务框架开发实战之九 Mapping属性原理和验证规则的实现策略 前言:之前的讨论一直关注在怎么从D ...
- PyTorch 实战:计算 Wasserstein 距离
PyTorch 实战:计算 Wasserstein 距离 2019-09-23 18:42:56 This blog is copied from: https://mp.weixin.qq.com/ ...
- Python接口测试框架实战与自动化进阶✍✍✍
Python接口测试框架实战与自动化进阶 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看 ...
- Android学习笔记进阶之在图片上涂鸦(能清屏)
Android学习笔记进阶之在图片上涂鸦(能清屏) 2013-11-19 10:52 117人阅读 评论(0) 收藏 举报 HandWritingActivity.java package xiaos ...
随机推荐
- 【Oculus Interaction SDK】(六)实体按钮 && 按压交互
前言 这篇文章是[Oculus Interaction SDK]系列的一部分,如果发现有对不上的对方,可以回去翻看我之前发布的文章,或在评论区留言.如果文章的内容已经不适用于新版本了,也可以直接联系我 ...
- ES的数据结构
1 ES的数据结构 es使用怎样的数据结构来存储数据呢 通过以下四种的逻辑组合来存储数据:索引.类型.文档和字段. 1.1 index索引 数据属于哪个索引?不同的数据用不同的索引来区分. 比如 当前 ...
- 爬虫Charles安装破解使用教程
转:https://blog.csdn.net/qq_27109535/article/details/125787745 1 下载安装程序及破解包 链接:https://pan.baidu.com/ ...
- 阅读openfoam框图
看完of的帮助文档,会非常怀念fluent的帮助文档或是matlab的帮助文档 比如我要解决一个matlab问题,基本上看帮助文档一分钟就知道我要如何取用我想要的东西,of帮助文档不光做不到,还给你炫 ...
- day15-SpringMVC执行流程
SpringMVC执行流程 1.SpringMVC执行流程分析图 例子 (1)创建 HaloHandler package com.li.web.debug; import org.springfra ...
- 来了!来了!国内使用chatGPT的方式总结
大家好,最近ChatGPT大火呀. 最近几天OpenAI发布的ChatGPT聊天机器人火出天际了,连着上了各个平台的热搜榜. 这个聊天机器人最大的特点是不仅可以模仿人类说话风格同时回答大量问题,能和你 ...
- LG P2633 Count on a tree
\(\text{Solution}\) 树上主席树板子 \(\text{Code}\) #include <cstdio> #include <algorithm> #defi ...
- string str = string.Empty也会出错?
如题 为什么会出现这种情况?大佬解释一下.
- 剖析flutter_download_manager学习如何做下载管理,暂停和取消
前言 内容类应用中图片或文件下载,一般应用中应用更新和升级,这些都是经典的下载场景.下载是项目中基础且重要的模块. 从代码逻辑复用性和人力成本考虑,一直想实现一个纯Dart实现的下载库,作为技术储备. ...
- Spark Streaming实时计算
spark批处理模式: receiver模式:接收数据流,负责数据的存储维护,缺点:数据维护复杂(可靠性,数据积压等),占用计算资源(core,memory被挤占) direct模式:数据源由三方组件 ...