python基础-RE正则表达式
re 正则表示式
正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
一、正则表达式的作用
1、给字符串进行模糊匹配,
2、对象就是字符串
二、字符匹配(普通字符,元字符)
1.普通字符:数字字符和英文字母和自身匹配
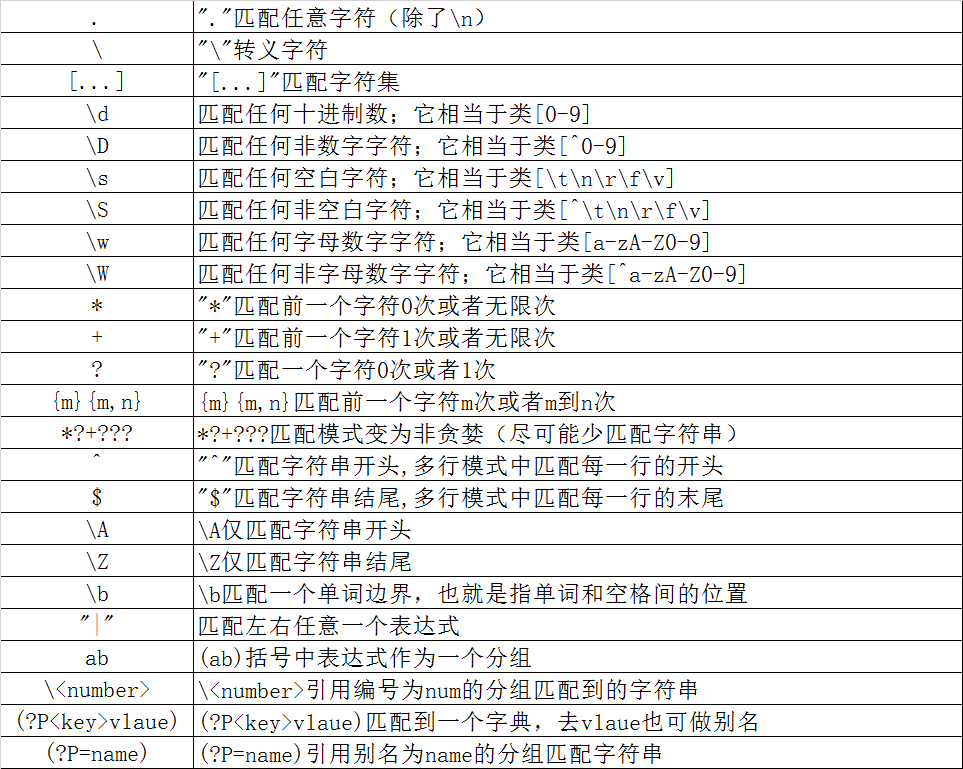
2.元字符:. ^ $ * + ? {} [] () | \
re.方法("规则","匹配的字符串")
. 匹配任意一个字符,除了\n换行符
三、匹配规则
四、使用前需先导入re模块
import re
五、演示示例
findall 用法
ps1:
#找出字符串中的数字
re.findall('\d+',"alex22jack33rain32sdfsd4") #执行这段代码
执行结果:
['', '', '', '']
ps2:
findall 找到匹配,返回所有匹配部分的列表(
re.findall("a..x","adsxaeyxsk19") #找到所有以a开头,以x结尾的字符
执行结果:
['adsx', 'aeyx']
ps3:
re.findall("I","I am LIST") #匹配所有I的字符
执行结果:
['I', 'I']
. 的作用:匹配任意的意思(一个点代表一个字符,有多个字符,就用多个点代替)
re.findall("a..x","adsfaeyxsk19") #匹配以a开头,以x结尾的字符
执行结果:
['aeyx']
^ 只能在字符串的开头去匹配
ps1:
re.findall("^a..x","adsxaeyxsk19") #^ 只能在字符串的开头去匹配
执行结果:
['adsx']
ps2:
re.findall("^I","I am LIST") #匹配开头是I的字符
执行结果:
['I']
以d开头,*匹配所有是d的
re.findall("^d*","dddddddd1ksdfgjdddddd")
执行结果:
['dddddddd']
$ 匹配以什么结尾的字符
re.findall("a..x$","adsxaeyxsk19arrx") #这里表示匹配以x结尾的字符
执行结果:
['arrx']
* + ? {} 匹配重复的符号(贪婪匹配)
ps1:
re.findall("d*","adsxaeddddddddddddyxsk19arrx") #* 紧挨着的字符,可以匹配无穷次
执行结果:
['', 'd', '', '', '', '', 'dddddddddddd', '', '', '', '', '', '', '', '', '', '', '']
ps2:
re.findall("alex*","asdhfalexxx") #*匹配以alex中,x结尾的所有x ,因为*代表可以重复的符号
执行结果:
['alexxx']
ps3:
re.findall("alex+","asdhfalexxx") #+匹配以alex中,x结尾的所有x,因为+代表可以重复的符号
执行结果:
['alexxx']
ps4:
re.findall("alex*","asdhfale") # *可以代表什么都没有
执行结果:
['ale']
ps5:
re.findall("alex?","asdhfalexxx") #?代表0次或1次
执行结果:
['alex']
ps6:
re.findall("alex?","asdhfale") #?代表0次或1次
执行结果:
['ale']
{} 想取多少次,就取多少次
{0,} ==*
re.findall("alex{1,}","asdhfalexx")
执行结果:
['alexx']
{1,}==+
re.findall("alex{0,}","asdhfalexx")
执行结果:
['alexx']
{0,1}==?
re.findall("alex{0,1}","asdhfalexx")
执行结果:
['alex']
{6} 重复6次
re.findall("alex{6}","asdhfalexxxxxx")
执行结果:
['alexxxxxx']
{0,6} 重复1,2,3,4,5,6
re.findall("alex{0,6}","asdhfalexx")
执行结果:
['alexx']
[ ] 字符集 等于或的作用
ps1:
re.findall("x[yz]","xyuuuu")
执行结果:
['xy']
ps2:
re.findall("x[yz]","xyuuxzuu") #或的作用
执行结果:
['xy', 'xz']
ps3:
re.findall("x[yz]p","xypuuxzpuu") #或的作用
执行结果:
['xyp', 'xzp']
ps4:
re.findall("q[a-z]*","quo") #匹配以a-z结束的字符
执行结果:
['quo']
ps5:
re.findall("q[a-z]*","quogjgkjjhk") #匹配以a-z所有的字符
执行结果:
['quogjgkjjhk']
ps6:
re.findall("q[a-z]*","quogjgkjjhk9") #匹配以a-z所有的字符
执行结果:
['quogjgkjjhk']
ps7:
re.findall("q[0-9]*","quogjgkjjhk9") #匹配以q开头挨着的0-9的字符,所以只有q
执行结果:
['q']
ps8:
re.findall("q[0-9]*","q899uogjgkjjhk9") #匹配以q开头挨着的0-9的字符,所以只有q899
执行结果:
['q899']
[^] 就是不是他的都匹配上
re.findall("q[^a-z]","q213") #只能匹配a-z之外的字符集
执行结果:
['q2']
元字符\ 就是让有意义的变成没有意义,让无意义的变成有意义
ps1:
re.findall("\d","12+(34*6+2-5*(2-1))") #匹配任何十进制的数
执行结果:
['', '', '', '', '', '', '', '', '']
ps2:
re.findall("\d+","12+(34*6+2-5*(2-1))") #匹配任何十进制的数
执行结果:
['', '', '', '', '', '', '']
ps3:
re.findall("[0-9]+","12+(34*6+2-5*(2-1))") #匹配所有0-9的字符
执行结果:
['', '', '', '', '', '', '']
ps4:
re.findall("[\D]+","12+(34*6+2-5*(2-1))") #匹配所有非数字
执行结果:
['+(', '*', '+', '-', '*(', '-', '))']
字符匹配
ps1:
re.findall("\D+","hello world") #\D匹配非数字字符
执行结果:
['hello world']
ps2:
re.findall("\S+","hello world") #\S 匹配非空的字符
执行结果:
['hello', 'world']
ps3:
re.findall("\w","hello world_") #\w 匹配任何字母数字字符
执行结果:
'h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd', '_']
ps4:
re.findall("www.baidu","www/baidu") #匹配任意字符
执行结果:
['www/baidu']
ps5:
re.findall("www.baidu","wwwobaidu") #匹配任意字符
执行结果:
['wwwobaidu']
ps6:
re.findall("www.baidu","www\nbaidu") ##匹配任意字符,但只有\n除外
执行结果:
[]
ps7:
re.findall("www\.baidu","www.baidu") #\去除元字特殊功能
执行结果:
['www.baidu']
ps8:
re.findall("www\*baidu","www*baidu") #\有特殊功能,可以转义
执行结果:
['www*baidu']
匹配中间带有空格的字符
ps1:
re.findall(r"I\b","I am LIST") re的r =\\ ,就相当转义两次
执行结果:
['I']
ps2:
re.findall("I\\b","I am LIST") #\\转义字符
执行结果:
['I']
ps3:
python解释器\\ 两个,re转义\\ 两个,所以是\\\\ 四个
re.findall("c\\\\l","abc\lerwt") #同时匹配c和l
执行结果:
['c\\l']
ps4:
re.findall(r"c\\l","abc\lerwt") #同时匹配c和l
执行结果:
['c\\l']
| 就是或的意思
ps1:
re.findall(r"ka|b","sdjkasf") #匹配ka或b
执行结果:
['ka']
ps2:
re.findall(r"ka|b","sdjkbsf") 匹配ka或b
执行结果:
['b']
ps3:
re.findall(r"ka|b","sdjka|bsf") #匹配ka或b
执行结果:
['ka', 'b']
元字符分组 ()
ps1:
re.findall("(abc)+","abcabc" )
执行结果:
['abc']
ps2:
re.findall("(abc)+","abccccc" )
执行结果:
['abc']
search 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ps1:
re.search("(?P<name>\w+)","abcccc")
执行结果:
<_sre.SRE_Match object; span=(0, 6), match='abcccc'> #匹配成功了,返回的就是对象
ps2:
re.search("\d+","sdfas34sdfg15")
执行结果:
<_sre.SRE_Match object; span=(5, 7), match=''>
ps3:
re.search("\d+","sdfas34sdfg15").group() #\d+ 是匹配数字
执行结果:
''
ps4:
re.search("(?P<name>[a-z]+)","alex36wusir34xialv33") #<>的作用就是把内容进行分组
执行结果:
<_sre.SRE_Match object; span=(0, 4), match='alex'>
ps5:
re.search("(?P<name>[a-z]+)","alex36wusir34xialv33").group() #group()匹配的内容取出来
执行结果:
'alex'
ps6:
re.search("[a-z]*","alex36wusir34xialv33").group() #匹配包含a-z的内容
执行结果:
'alex'
ps7:
re.search("[a-z]+","alex36wusir34xialv33").group() #匹配包含a-z的内容,+号的作用就是重复
执行结果:
'alex'
ps8:
re.search("(?P<name>[a-z]+)\d+","alex36wusir34xialv33").group("name") #通过分组,可以给group传叁数,找出你想要的信息
执行结果:
'alex'
ps9:
re.search("(?P<name>[a-z]+)(?P<age>\d+)","alex36wusir34xialv33").group("age") #通过分组找出你想要的信息
执行结果:
''
ps10:
匹配网站URL的路径
http://www.cnblogs.com/yuanchenqi/articles/5732581.html re.search("(?P<name>[a-z]+)\(?P<age>\d+)","alex36wusir34xialv33").group("age") #()\() 配置URL地址 ,不要运行这条,会报错!
re模块下的常用方法
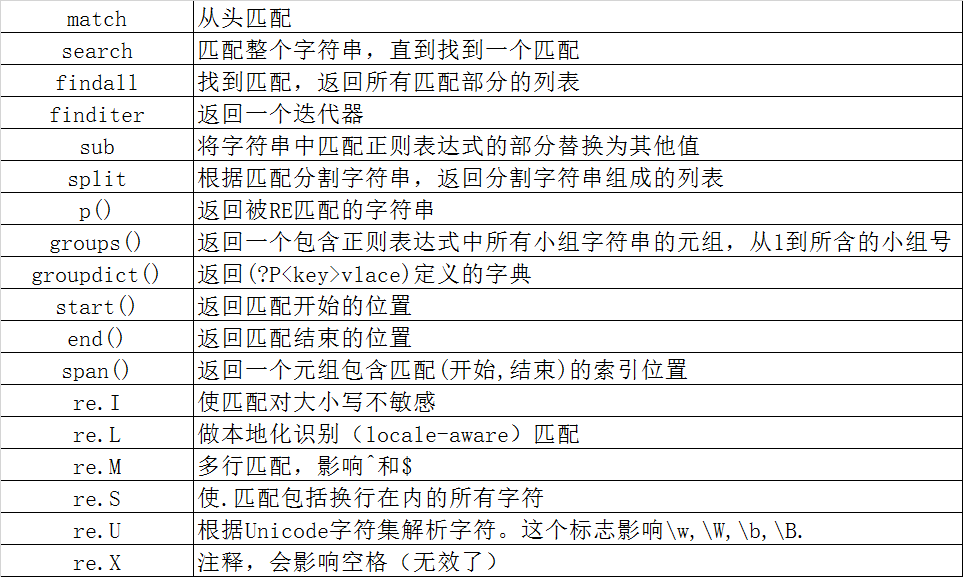
findall
re.findall('a','alvin yuan') #返回所有满足匹配条件的结果,放在列表里
执行结果:
['a', 'a']
search
re.search('a','alvin yuan').group() #函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
#通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
执行结果:
'a'
match
ps1:
re.match('a','abc').group() #同search,不过尽在字符串开始处进行匹配
执行结果:
'a'
ps2:
re.match("\d+","56alex36wusir34xialv33")
执行结果:
<_sre.SRE_Match object; span=(0, 2), match=''>
ps3:
re.match("\d+","56alex36wusir34xialv33").group()
执行结果:
''
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
split 分割
ps1:
ret=re.split('[ab]','abcd') #先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret)
执行结果:
['', '', 'cd']
ps2:
re.split(" ","hello abc def") #匹配中间带有空格的
执行结果:
['hello', 'abc', 'def']
ps3:
re.split("[ l]","hello abcldef")
执行结果:
['he', '', 'o', 'abc', 'def']
ps4:
re.split("[ |]","hello abc|def")
执行结果:
['hello', 'abc', 'def']
ps5:
re.split("[ab]","asdabcd")
执行结果:
['', 'sd', '', 'cd']
ps6:
re.split("[ab]","abc") #以自己为分界点,进行分隔,有的就以‘’ 填充
执行结果:
['', '', 'c']
sub 替换
ps1:
re.sub("\d+","A","jaskd4234ashdjf5423") #把所有数字替换为A(4234替换为A)
执行结果:
'jaskdAashdjfA'
ps2:
re.sub("\d","A","jaskd4234ashdjf5423") #把所有数字替换为A(4234替换为AAAA)
执行结果:
'jaskdAAAAashdjfAAAA'
ps3:
ret=re.sub('\d','abc','alvin5yuan6',1) #把5替换成abc
执行结果:
alvinabcyuan6
ps4:
re.sub("\d","A","jaskd4234ashdjf5423",4) #指定替换次数 4,只替换前面4个数字
执行结果:
'jaskdAAAAashdjf5423'
subn 第一个匹配元组,第二个匹配次数
ps1:
ret=re.subn('\d','abc','alvin5yuan6') #第一个匹配元组,第二个匹配次数
print(ret)
执行结果:
('alvinabcyuanabc', 2)
ps2:
re.subn("\d","A","jaskd4234ashdjf5423") #第一个匹配元组,第二个匹配次数,8次
执行结果:
('jaskdAAAAashdjfAAAA', 8)
compile 编译
ps1:
com=re.compile("\d+") #编译好了一次,下次再用,直接就调用他,不用再编译,提高匹配速度
com.findall("fjlksad234hfjksd3421") #可以匹配多次
执行结果:
['', '']
ps2:
obj=re.compile('\d{3}')
ret=obj.search('abc123eeee')
print(ret.group())
执行结果:
123
finditer(迭代器)当数据非常多的时候,他会把数据存在迭代器中,不会放在内存中,用一条处理一条。
ps1:
re.finditer("\d","sdfgs6345dkflfdg534jd")
执行结果:
<callable_iterator object at 0x01093710> #返回的是迭代器对象
ps2:
ret=re.finditer("\d","sdfgs6345dkflfdg534jd")
next(ret).group() #拿到结果
''
next(ret).group()
''
next(ret).group()
''
next(ret).group()
''
next(ret).group()
''
next(ret).group()
''
next(ret).group()
''
补充内容:
ps1:
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret)
执行结果:
['oldboy'] #这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ps2:
re.findall("www\.(baidu|163)\.com","www.baidu.com")
执行结果:
['baidu'] #这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ps3:
re.findall("www\.(baidu|163)\.com","dfdsssfwww.baidu.comdsfsfs")
执行结果:
['baidu'] #这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ps4:
re.findall("www\.(baidu|163)\.com","dfdsssfwww.163.comdsfsfs")
执行结果:
[''] #这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ps5:
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret)
执行结果:
['www.oldboy.com']
ps6:
re.findall("www\.(?:baidu|163)\.com","dfdsssfwww.163.comdsfsfs") #如果要匹配置全部网址,取消他的优化级,在前面加?:
执行结果:
['www.163.com']
生产环境常见正则示例:
1、匹配手机号
phone_num = ''
a = re.compile(r"^1[\d+]{10}")
b = a.match(phone_num)
print(b.group())
2、匹配IPv4
# 匹配IP地址
ip = '192.168.1.1'
a = re.compile(r"(((1?[0-9]?[0-9])|(2[0-4][0-9])|(25[0-5]))\.){3}((1?[0-9]?[0-9])|(2[0-4][0-9])|(25[0-5]))$")
b = a.search(ip)
print(b)
3、匹配E-mail
email = '630571017@qq.com'
a = re.compile(r"(.*){0,26}@(\w+){0,20}.(\w+){0,8}")
b = a.search(email)
print(b.group())
计算机作业
python基础-RE正则表达式的更多相关文章
- 十七. Python基础(17)--正则表达式
十七. Python基础(17)--正则表达式 1 ● 正则表达式 定义: Regular expressions are sets of symbols that you can use to cr ...
- Python基础之 正则表达式指南
本文介绍了Python对于正则表达式的支持,包括正则表达式基础以及Python正则表达式标准库的完整介绍及使用示例.本文的内容不包括如何编写高效的正则表达式.如何优化正则表达式,这些主题请查看其他教程 ...
- Python高手之路【五】python基础之正则表达式
下图列出了Python支持的正则表达式元字符和语法: 字符点:匹配任意一个字符 import re st = 'python' result = re.findall('p.t',st) print( ...
- python基础之正则表达式
正则表达式语法 正则表达式 (或 RE) 指定一组字符串匹配它;在此模块中的功能让您检查一下,如果一个特定的字符串匹配给定的正则表达式 (或给定的正则表达式匹配特定的字符串,可归结为同一件事). 正则 ...
- python基础之正则表达式和re模块
正则表达式 就其本质而言,正则表达式(或 re)是一种小型的.高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现.正则表达式模式被编译成一系列的字节码,然后由用 ...
- python基础之正则表达式。
简介 就其本质而言,正则表达式是内嵌在python内,由re模块实现,小型的专业化语言,最后由c写的匹配引擎执行.正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来 ...
- Python开发【第一篇】Python基础之正则表达式补充
正则表达式 一简介:就其本质而言,正则表达式(或RE)是一种小型的.高度专业化的标称语言,(在Python中)它内嵌在Python中,并通过re模块实现.正则表达式模式被编译成一系列的字节码,然后由用 ...
- python基础之 正则表达式,re模块
1.正则表达式 正则表达式:是字符串的规则,只是检测字符串是否符合条件的规则而已 1.检测某一段字符串是否符合规则 2.将符合规则的匹配出来re模块:是用来操作正则表达式的 2.正则表达式组成 字符组 ...
- python基础之正则表达式 re模块
内容梗概: 1. 正则表达式 2. re模块的使⽤ 3. 一堆练习正则表达式是对字符串串操作的一种逻辑公式. 我们一般使用正则表达式对字符串进行匹配和过滤.使用正则的优缺点: 优点: 灵活,功能性强, ...
随机推荐
- Sharepoint学习笔记—ECM系列--文档集(Document Set)的实现
文档集是 SharePoint Server 2010 中的一项新功能,它使组织能够管理单个可交付文档或工作产品(可包含多个文档或文件).文档集是特殊类型的文件夹,它合并了唯一的文档集属性以及文件夹和 ...
- Android 6.0 权限管理最佳实践
博客: Android 6.0 运行时权限管理最佳实践 github: https://github.com/yanzhenjie/AndPermission
- 【Swift】iOS开发历险记(一)
前言 边开发边学习,边攒经验,汇总一下记录到这里 声明 欢迎转载,但请保留文章原始出处:) 博客园:http://www.cnblogs.com 农民伯伯: http://over140.cnblog ...
- 【Swift 2.0】实现简单弹幕功能
前言 简单实现弹幕功能,表跟我谈效率,但也有用队列控制同时弹的数量. 声明 欢迎转载,但请保留文章原始出处:) 博客园:http://www.cnblogs.com 农民伯伯: http://over ...
- linux 学习随笔-系统日常管理常用命令
1:W 查看系统整体负载,无法查看具体负载,比如内存,磁盘 23:25:20 up 13 min, 2 users, load average: 0.00, 0.01, 0.01 USER ...
- SQLSERVER2008 R2安装说明
SQLSERVER2008 R2安装说明一. 安装环境:SQLSERVER2008 R2有32位版本和64位版本,32位版本可以安装在WINDOWS XP及以上操32位和64位的操作系统上,如果服务器 ...
- js字符串转为日期格式
1. <script type="text/javascript"> //字符串转日期格式,strDate要转为日期格式的字符串 function getDate(st ...
- javascrip中parentNode和offsetParent之间的区别
首先是 parentNode 属性,这个属性好理解,就是在 DOM 层次结构定义的上下级关系,如果元素A包含元素B,那么元素B就可以通过 parentElement 属性来获取元素A. 要明白 off ...
- git 中关于LF 和 CRLF 的问题
git 中关于LF 和 CRLF 的转换问题注意: Windows下编辑器设置中,建议调整设置为Unix风格.(具体设置位置各种编辑器上不同,需要找找) 使用Git Bash进行命令行操作时,运行一下 ...
- php基础教程
PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言. PHP Hypertext Preprocessor 什么是 PHP 文件? PHP 文件能够包含文本.HTML.CSS 以及 PHP 代 ...