分布式缓存技术redis学习系列(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型
与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String、List、Hash、Set和Sorted Set。
Redis数据类型内存结构分析
Redis内部使用一个redisObject对象来表示所有的key和value。redisObject主要的信息包括数据类型(type)、编码方式(encoding)、数据指针(ptr)、虚拟内存(vm)等。type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部式。

redisObject 对象示意图
下面分别介绍5种数据类型的用法。
String类型
字符串是Redis值的最基础的类型。Redis中使用的字符串是通过包装的,基于c语言字符数组实现的简单动态字符串(simple dynamic string, SDS)一个抽象数据结构。其源码定义如下:
struct sdshdr {
int len; //len表示buf中存储的字符串的长度。
int free; //free表示buf中空闲空间的长度。
char buf[]; //buf用于存储字符串内容。
};

C语言字符串内存结构示意图1
假设上图是”hello”字符串的内存结构,这个时候len=5,free=2那么redis包装后(sds)其长度为:
sizeof(struct sdshdr) + len + free + 1
其中buf的大小为:
len + free + 1
1表示1个字节是用来存储结束符’\0’的。Redis字符串是二进制安全的,因为二进制数据通常会有中间某个字节存储’\0’的这种情况,这意味着一个Redis字符串可以包含任何种类的数据,例如一个JPEG图像或者一个序列化的Ruby对象。二进制是否安全,简单的理解就是能不能在字符串中间有‘\0’,如下图:

C语言字符串内存结构示意图2
对于上图,sds认为这个字符串是“hello world”,而C语言的字符处理函数认为这个字符串是“hello”。
应用场景
String是最常用的一种数据类型,普通的key/value存储都可以归为此类。
常用命令
(1)set——设置key对应的值为String类型的value
(2)get——获取key对应的值
192.168.2.129:6379> setnx name lisi
(integer) 0
192.168.2.129:6379> setnx name1 wangwu
(integer) 1
192.168.2.129:6379> get name
"zhangsan"
192.168.2.129:6379> get name1
"wangwu"
192.168.2.129:6379>
(3)mget——批量获取多个key的值,如果可以不存在则返回nil
192.168.2.129:6379> mget name name1
1) "zhangsan"
2) "wangwu"
192.168.2.129:6379> mget name name1 name2
1) "zhangsan"
2) "wangwu"
3) (nil)
192.168.2.129:6379>
(4)incr &&incrby——incr对key对应的值进行加加操作,并返回新的值;incrby加指定值
192.168.2.129:6379> get age
"20"
192.168.2.129:6379> incr age
(integer) 21
192.168.2.129:6379> set age1 "20"
OK
192.168.2.129:6379> get age1
"20"
192.168.2.129:6379> incr age1
(integer) 21
192.168.2.129:6379> incrby age 3
(integer) 24
从上面的结果可以看出,我们对int型的age和string型的age1都能进行incr操作时,
实际上type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如"20"这样的字符串,当遇到incr、decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。如果你试图对name进行incr操作则报错。
192.168.2.129:6379> incr name
(error) ERR value is not an integer or out of range
(5)decr && decrby——decr对key对应的值进行减减操作,并返回新的值;decrby减指定值
192.168.2.129:6379> decr age
(integer) 23
192.168.2.129:6379> decrby age 3
(integer) 20
192.168.2.129:6379>
(6)其他命令
|
说明 |
|
|
设置key对应的值为String类型的value,如果key已经存在则返回0 |
|
|
setex |
设置key对应的值为String类型的value,并设定有效期 |
|
getrange |
获取key对应value的子字符串 |
|
mset |
批量设置多个key的值,如果成功表示所有值都被设置,否则返回0表示没有任何值被设置 |
|
msetnx |
同mset,不存在就设置,不会覆盖已有的key |
|
getset |
设置key的值,并返回key旧的值 |
|
append |
给指定key的value追加字符串,并返回新字符串的长度 |
|
strlen |
取指定key的value的长度 |
Hash类型
Hash是一个String类型的field和value之间的映射表,即redis的Hash数据类型的key(hash表名称)对应的value实际的内部存储结构为一个HashMap,因此Hash特别适合存储对象。相对于把一个对象的每个属性存储为String类型,将整个对象存储在Hash类型中会占用更少内存。
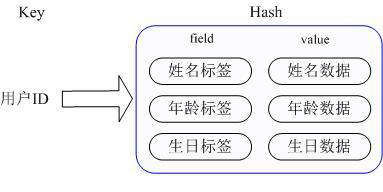
Hash 数据类型内部结构示意图
当前HashMap的实现有两种方式:当HashMap的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
应用场景
用一个对象来存储用户信息,商品信息,订单信息等等。
常用命令
(1)hset——设置key对应的HashMap中的field的value
(2)hget——获取key对应的HashMap中的field的value
192.168.2.129:6379> hset myhash name zhangsan
(integer) 1
192.168.2.129:6379> hset myhash age 20
(integer) 1
192.168.2.129:6379> hget myhash name
"zhangsan"
192.168.2.129:6379> hget myhash age
"20"
192.168.2.129:6379>
(3)hgetall——获取key对应的HashMap中的所有field的value
192.168.2.129:6379> hgetall myhash
1) "name"
2) "zhangsan"
3) "age"
4) "20"
192.168.2.129:6379>
(4)其它命令
|
说明 |
|
|
hsetnx |
设置key对应的HashMap中的field的value,如果不存在则先创建 |
|
hmset |
|
|
hmget |
批量获取key对应的HashMap中的field的value |
|
hincrby |
给key对应的HashMap中的field的value加指定的值 |
|
hexits |
测试key对应的HashMap中的field是否存在 |
|
hlen |
|
|
hdel |
删除key对应的HashMap中的field |
|
hkeys |
|
|
hvals |
返回key对应的HashMap中所有的field的value |
List类型
Redis的List类型其实就是每一个元素都是String类型的双向链表。我们可以从链表的头部和尾部添加或者删除元素。这样的List既可以作为栈,也可以作为队列使用。
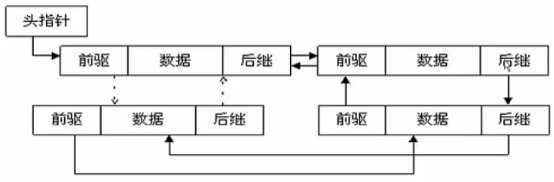
List数据结构内部示意图
应用场景
如好友列表,粉丝列表,消息队列,最新消息排行等。
常用命令
(1)lpush——在key对应的list的头部添加一个元素。
(2)lrange——获取key对应的list的指定下标范围的元素,-1表示获取所有元素。
(3)lpop——从key对应的list的尾部删除一个元素,并返回该元素。
192.168.2.129:6379> lpush newlist news1 news2 news3
(integer) 3
192.168.2.129:6379> lrange newlist 0 -1
1) "news3"
2) "news2"
3) "news1"
192.168.2.129:6379> lpop newlist
"news3"
192.168.2.129:6379> lrange newlist 0 -1
1) "news2"
2) "news1"
192.168.2.129:6379>
从上面的操作可以看出,lpush、lpop从表头操作。

(4)rpush——在key对应的list的尾部添加一个元素。
(5)rpop——从key对应的list的尾部删除一个元素,并返回该元素。
192.168.2.129:6379> rpush newlist2 news1 news2 news3
(integer) 3
192.168.2.129:6379> lrange newlist2 0 -1
1) "news1"
2) "news2"
3) "news3"
192.168.2.129:6379> rpop newlist2
"news3"
192.168.2.129:6379>
从上面的操作可以看出,rpush、rpop从表尾操作。
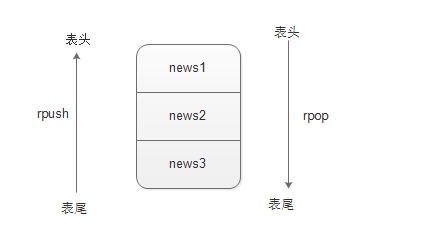
(6)其他命令
|
说明 |
|
|
linsert |
在key对应的list的特定元素的前或后插入元素 |
|
lset |
设置key对应的list中指定下标元素的值 |
|
lrem |
从key对应的list中删除n个和value相同的元素 |
|
ltrim |
保留key对应的list中指定范围的元素 |
|
rpoplpush |
从第一个list的尾部移除一个元素并添加到第二个list的头部 |
|
llen |
|
|
lindex |
返回key对应的list中index的元素 |
Set类型
Redis 集合(Set类型)是一个无序的String类型数据的集合,类似List的一个列表,与List不同的是Set不能有重复的数据。实际上,Set的内部是用HashMap实现的,Set只用了HashMap的key列来存储对象。我们来看看java中HashSet的源码:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
......
/**
* Returns an iterator over the elements in this set. The elements
* are returned in no particular order.
*
* @return an Iterator over the elements in this set
* @see ConcurrentModificationException
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}
可见创建一个HashSet的时候实际上创建了一个HashMap;Set中的元素,只是存放在了底层HashMap的key上,底层HashMap的value列为空,遍历HashSet的时候从HashMap中取出keySet来遍历。
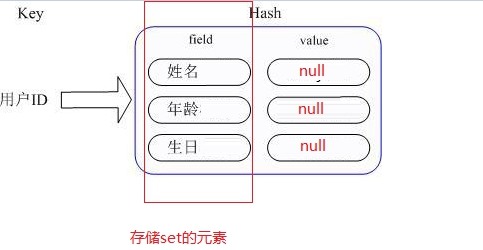
Set底层结构示意图
应用场景
集合有取交集、并集、差集等操作,因此可以求共同好友、共同兴趣、分类标签等。
常用命令
(1)sadd——在key对应的set中添加一个元素。
(2)smembers——获取key对应的set的所有元素。
(3)spop——随机返回并删除key对应的set中的一个元素。
192.168.2.129:6379> sadd myset news1 news2 news3
(integer) 3
192.168.2.129:6379> smembers myset
1) "news3"
2) "news2"
3) "news1"
192.168.2.129:6379> spop myset
"news3"
192.168.2.129:6379>
(4)sdiff——求给定key对应的set与第一个key对应的set的差集
192.168.2.129:6379> smembers myset
1) "news3"
2) "news2"
3) "news1"
192.168.2.129:6379> sadd myset2 news3 news4 news5
(integer) 3
192.168.2.129:6379> smembers myset2
1) "news4"
2) "news3"
3) "news5"
192.168.2.129:6379> sdiff myset myset2
1) "news1"
2) "news2"
192.168.2.129:6379>
(5)suion——求给定key对应的set并集
192.168.2.129:6379> sunion myset myset2
1) "news3"
2) "news1"
3) "news2"
4) "news4"
5) "news5"
192.168.2.129:6379>
192.168.2.129:6379> sinter myset myset2
1) "news3"
192.168.2.129:6379>
(7)其他命令
|
说明 |
|
|
srem |
删除key对应的set中的一个元素 |
|
sdiffstore |
求给定key对应的set与第一个key对应的set的差集,并存储到另一个key对应的set中 |
|
sinterstore |
求给定key对应的set交集,并存储到另一个key对应的set中 |
|
suionstore |
求给定key对应的set并集,并存储到另一个key对应的set中 |
|
somve |
从第一个key对应的set中删除指定元素并添加到第二个key对应的set中 |
|
scard |
|
|
sismember |
测试某个元素是否为key对应的set中的元素个数 |
|
srandmember |
随机返回key对应的set中的一个元素,但不删除元素 |
SortSet
SortSet顾名思义,是一个排好序的Set,它在Set的基础上增加了一个顺序属性score,这个属性在添加修改元素时可以指定,每次指定后,SortSet会自动重新按新的值排序。
sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score。
应用场景
如按时间排序的时间轴。
常用命令
(1)zadd ——在key对应的zset中添加一个元素
(2)zrange——获取key对应的zset中指定范围的元素,-1表示获取所有元素
192.168.2.129:6379> zadd myzset 1 "one" 2 "two" 3 "three"
(integer) 3
192.168.2.129:6379> zrange myzset 0 -1
1) "one"
2) "two"
3) "three"
192.168.2.129:6379> zrange myzset 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
192.168.2.129:6379>
(3)zrem——删除key对应的zset中的一个元素
192.168.2.129:6379> zrem myzset one
(integer) 1
192.168.2.129:6379> zrange myzset 0 -1 withscores
1) "two"
2) "2"
3) "three"
4) "3"
192.168.2.129:6379>
(4)其它命令
|
命令 |
说明 |
|
zincrby |
如果key对应的zset中已经存在元素member,则对member的score属性加指定的值 |
|
zrank |
返回key对应的zset中指定member的排名。其中member按score值递增(从小到大);排名以0为底,也就是说,score值最小的成员排名为0 |
|
获得成员按score值递减(从大到小)排列的排名 |
|
|
返回有序集key中,指定区间内的成员。其中成员的位置按score值递减(从大到小)来排列 |
|
|
返回有序集key中,指定分数范围的元素列表 |
|
|
zcount |
返回有序集key中,score值在min和max之间(默认包括score值等于min或max)的成员 |
|
zcard |
返回key的有序集元素个数 |
Redis常用命令
键值常用命令
keys/exits/del/expire/ttl/move/persist/randomkey/rename/type
服务器常用命令
ping/echo/select/quit/dbsize/info/config get/flushdb/flushall
这些命令都很容易使用,就不举例说明了。到此,redis的数据类型以及常用命令已经介绍完毕,下一篇我们将学习redis的一些高级特性。
参考文档
http://www.redis.cn/documentation.html
http://blog.csdn.net/tonysz126/article/details/8280696/
分布式缓存技术redis学习系列(二)——详细讲解redis数据结构(内存模型)以及常用命令的更多相关文章
- 分布式缓存技术memcached学习系列(二)——memcached基础命令
上文<linux环境下编译memcahed>介绍了memcahed在linux环境下的安装以及登录,下面介绍memcahed的基本命令的使用. Add 功能:往内存增加一条新的缓存记录 语 ...
- 分布式缓存技术memcached学习(二)——memcached基础命令
上文<linux环境下编译memcahed>介绍了memcahed在linux环境下的安装以及登录,下面介绍memcahed的基本命令的使用. Add 功能:往内存增加一条新的缓存记录 语 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 分布式缓存技术memcached学习系列(五)—— memcached java客户端的使用
Memcached的客户端简介 我们已经知道,memcached是一套分布式的缓存系统,memcached的服务端只是缓存数据的地方,并不能实现分布式,而memcached的客户端才是实现分布式的地方 ...
- 分布式缓存技术memcached学习系列(三)——memcached内存管理机制
几个重要概念 Slab memcached通过slab机制进行内存的分配和回收,slab是一个内存块,它是memcached一次申请内存的最小单位,.在启动memcached的时候一般会使用参数-m指 ...
- 分布式缓存技术memcached学习系列(一)——linux环境下编译memcahed
安装依赖工具 [root@localhost upload]# yum install gcc make cmake autoconf libtool 下载并上传文件 memcached 依 ...
- 分布式缓存技术redis学习系列(五)——redis实战(redis与spring整合,分布式锁实现)
本文是redis学习系列的第五篇,点击下面链接可回看系列文章 <redis简介以及linux上的安装> <详细讲解redis数据结构(内存模型)以及常用命令> <redi ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- 分布式缓存技术redis学习系列(三)——redis高级应用(主从、事务与锁、持久化)
上文<详细讲解redis数据结构(内存模型)以及常用命令>介绍了redis的数据类型以及常用命令,本文我们来学习下redis的一些高级特性. 安全性设置 设置客户端操作秘密 redis安装 ...
- 分布式缓存技术redis学习系列(一)——redis简介以及linux上的安装
redis简介 redis是NoSQL(No Only SQL,非关系型数据库)的一种,NoSQL是以Key-Value的形式存储数据.当前主流的分布式缓存技术有redis,memcached,ssd ...
随机推荐
- centos 7 安装 python-dev包提示No package python-dev available
centos安装 python-dev包提示No package python-dev available: 出现此问题的原因是python-dev的包在centos的yum中不叫python-dev ...
- PS快捷键
- MySQL插入数据返回id
按照应用需要,常常要取得刚刚插入数据库表里的记录的ID值,在MYSQL中可以使用LAST_INSERT_ID()函数,在MSSQL中使用 @@IDENTITY.挺方便的一个函数.但是,这里需要注意的是 ...
- easyUi load方法重新加载表单的数据
1.表单回显数据的方法 <script> //方法一 function loadLocal(){ $('#ff').form('load',{ name:'myname', email:' ...
- python学习笔记-(十四)进程&协程
一. 进程 1. 多进程multiprocessing multiprocessing包是Python中的多进程管理包,是一个跨平台版本的多进程模块.与threading.Thread类似,它可以利用 ...
- Java的生日
你知道巴西的税务系统,亚马逊的Kindle阅读器以及韩国的第一大镁板制造厂有什么共同点吗?乍一看上去,这简直就是风马牛不相及,但是这些系统同世界上其它100亿个设备共享一个元素,那就是Java. 19 ...
- 面试题目——《CC150》高等难题
面试题18.1:编写一个函数,将两个数字相加.不得使用+或其他算数运算符. package cc150.high; public class Add { public static void main ...
- 学习笔记——k近邻法
对新的输入实例,在训练数据集中找到与该实例最邻近的\(k\)个实例,这\(k\)个实例的多数属于某个类,就把该输入实例分给这个类. \(k\) 近邻法(\(k\)-nearest neighbor, ...
- 条件编译#if #ifdef
近期由于一些莫名其妙的原因开始学c++,我觉得我哪天要是挂了也是被自己给折腾死的,算了,反正不是折腾死就是被淘汰,当是没事打发时间了,废话不多说,开始今天的主题. 之前接触的注释就是注释,条件语句就是 ...
- 【译文】Java Logging
本文讲Java内置的java.util.logging软件包中的 api.主要解释怎样使用该api添加logging到你的application中,怎样加配置它等.但是本文不谈你应该把什么东西写到日志 ...