传统数据仓库项目的优化手段 (针对 Oracle+DataStage )
普通手段
Oracle并行场景:
- SQL*Loader 的parallel参数
- 事务失败回滚的并行处理 FAST_START_PARALLEL_ROLLBACK参数
- expdp设置parallelism参数,设置多个datapump文件
- 大批量处理+并行处理(parallel),减少select次数,逻辑清晰,尽可能一次select……jion 之后再进行统一分析函数的处理,select/*+ PARALLEL(Table_Name,并行数) */统计函数 sum avgcase when then else endover(partition by order by )分析函数 lead/lag,rank,ratio_to_report,Period-over-period comparisons 等等...fromTable_Namegroup by
rollup ,cube 等等... - 创建索引、rebuild、设置并行参数(譬如大批量ETL全量时,drop索引,ETL之后再create)
- 收集统计信息的 degree参数
- 还有aleter session enable parallel dml;
insert /*+ append parallel(Table_I,并行数) */
into Table_I nologging
select /*+ PARALLEL(A,并行数) PARALLEL(B,并行数) PARALLEL(C,并行数) */
……
nologging 在DML时往往很有用
Insert、update
1、当然最快的仍然是create table NEW_TAB as select * from OLD_TAB
MERGE:(同样可以使用并行,nologging)
参数:
外部表
- 不能dml,不能建索引,不支持分区
- 适合只使用一次,无需修改,方便load入数据,可以并行查询,可以Nested_Loop JOIN,可以HASH_JOIN
- 外部表结合MERGE的场景

系统级临时表(无DML锁,无REDO)
direct path insert
物化视图:空间换取时间
表空间迁移
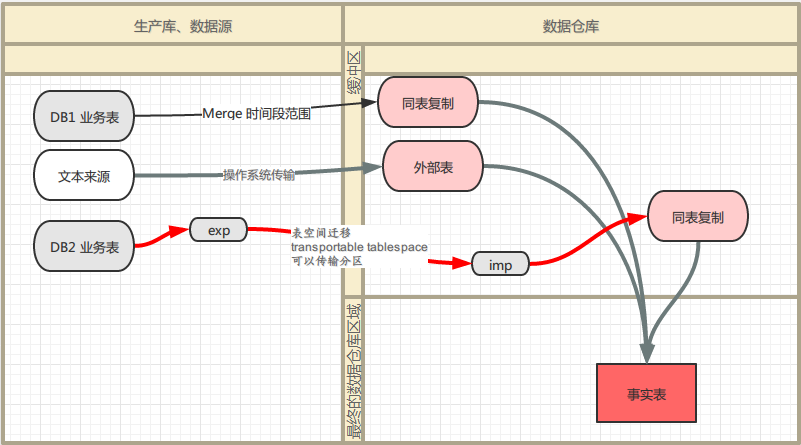
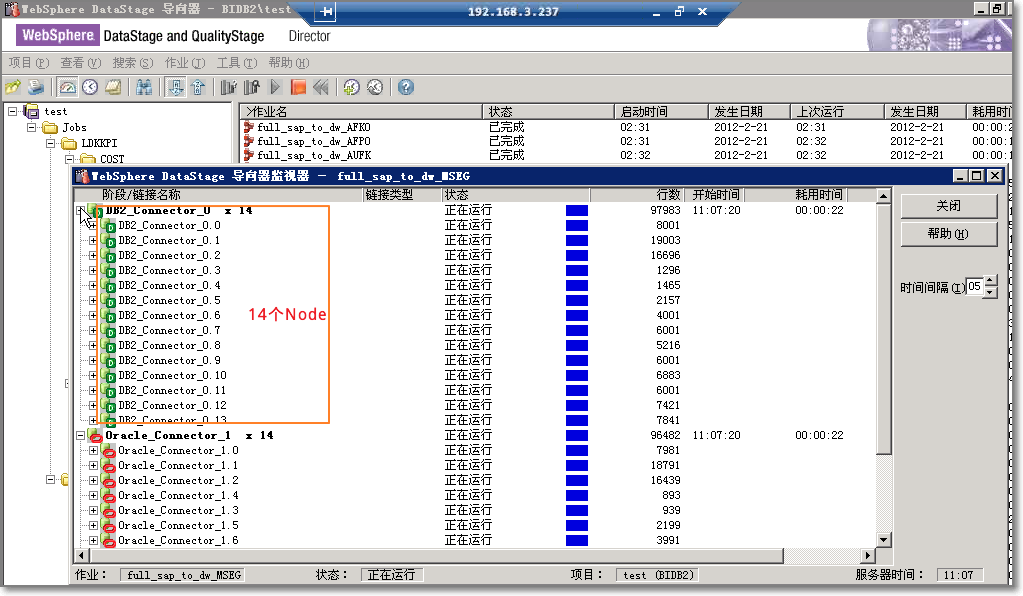
DataStage方面的处理
1、Bulk load方式

读端:设置 enable partitioned reads ,modulus方式分区读取integer(zeile)

写端:oracle connect 选择bulk load方式
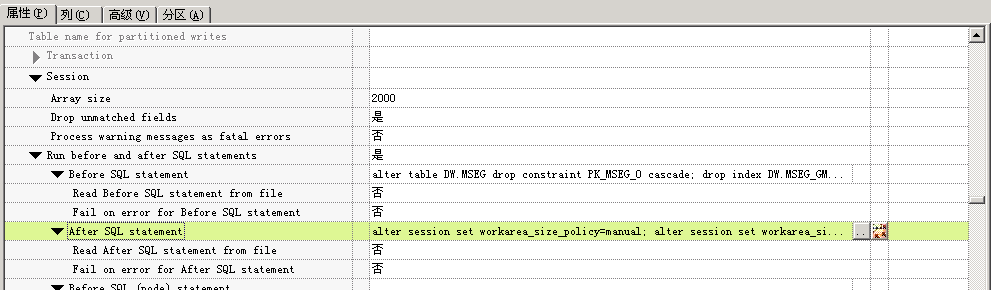
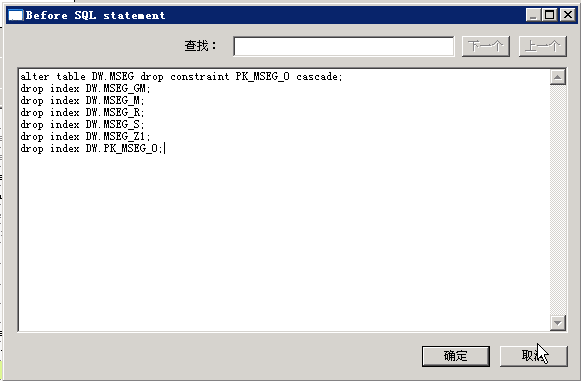
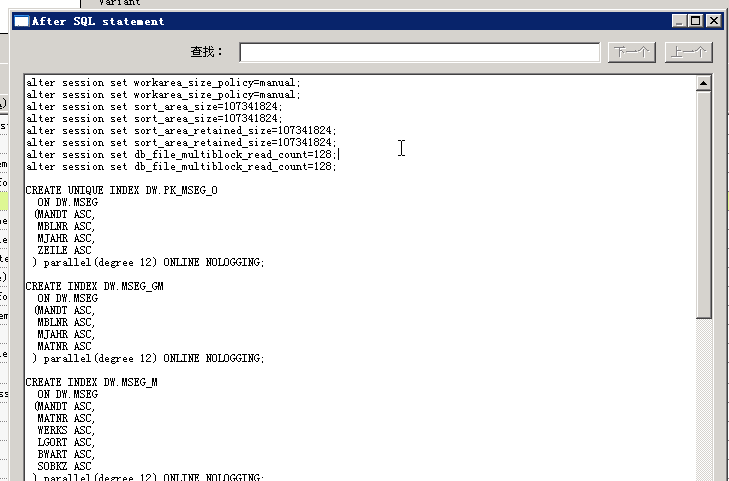

传统数据仓库项目的优化手段 (针对 Oracle+DataStage )的更多相关文章
- 用HAWQ轻松取代传统数据仓库(八) —— 大表分区
一.HAWQ中的分区表 与大多数关系数据库一样,HAWQ也支持分区表.这里所说的分区表是指HAWQ的内部分区表,外部分区表在后面“外部数据”篇讨论.在数据仓库应用中,事 实表通常有非常多 ...
- Nuxt 项目性能优化调研
性能优化,这是面试中经常会聊到的话题.我觉得性能优化应该因具体场景而异,因不同项目而异,不同的手段不同的方案并不一定适合所有项目,当然这其中不乏一些普适的方案,比如耳熟能详的文件压缩,文件缓存,CDN ...
- 基于beego orm 针对oracle定制
目前golang的ORM对oracle支持都没有mysql那样完整,一个orm要同时兼容mysql和oracle由于在sql语法上区别,会使整orm变的非常臃肿. 本项目是在beego orm上修改, ...
- 传统数据仓库架构与Hadoop的区别
一, 下面一张图为传统架构和Hadoop的区别 主要讲以下横向扩展和扩展横向扩展:(Mpp 是hash分布,具有20节点)添加新的设备和现有的设备一起提供负载能力.Hadoop中系统扩容时,系统平台增 ...
- 【Vuejs】335-(超全) Vue 项目性能优化实践指南
点击上方"前端自习课"关注,学习起来~ 前言 Vue 框架通过数据双向绑定和虚拟 DOM 技术,帮我们处理了前端开发中最脏最累的 DOM 操作部分, 我们不再需要去考虑如何操作 D ...
- Mysql之Explain关键字及常见的优化手段
Explain关键字字段描述: Explain关键字字段详情描述 id 我们写的查询语句一般都以SELECT关键字开头,比较简单的查询语句里只有一个SELECT关键字,但是下边两种情况下在一条查询语句 ...
- Ejabberd作为推送服务的优化手段
AVOS Cloud目前还在用Ejabberd做Android的消息推送服务.当时选择Ejabberd,是因为Ejabberd是一个发展很长时间的XMPP实现,并且基于Erlang,设想能在我们自主研 ...
- [转]优化数据库大幅度提高Oracle的性能
几个简单的步骤大幅提高Oracle性能--我优化数据库的三板斧. 数据库优化的讨论可以说是一个永恒的主题.资深的Oracle优化人员通常会要求提出性能问题的人对数据库做一个statspack,贴出数据 ...
- javaweb项目的优化 - 几番思念
简单地来看一个浏览器用户访问的流程: 浏览器->服务器->返回结果显示 这么简单地看,可能想得到的优化手段很少,常见的可能就是优化sql,加快数据库处理:加个缓存,加快返回:使用静态文件 ...
随机推荐
- PIE SDK栅格生成等值线、面
1.算法功能简介 等值线图能直观地展示数据的变化趋势,是众多领域展示成果的重要图建之一,被广泛应用于石油勘探.矿物开采.气象预报等众多领域.等值线的绘制是指从大量采样数据中提取出具有相同值的点的信 ...
- idea中使用restclient测试接口发送http请求
转载:https://jingyan.baidu.com/article/ca41422f0bfd8e1eae99ed31.html
- Springboot与MyBatis简单整合
之前搭传统的ssm框架,配置文件很多,看了几天文档才把那些xml的逻辑关系搞得七七八八,搭起来也是很麻烦,那时我完全按网上那个demo的版本要求(jdk和tomcat),所以最后是各种问题没成功跑起来 ...
- java 读写操作大文件 BufferedReader和RandomAccessFile
一 老问这问题,两个都答出来算加分项? 二 具体代码如下,没什么好说的直接说对比. BufferedReader和RandomAccessFile的区别RandomAccessFile 在数据越大,性 ...
- 使用Git(msysgit)和TortoiseGit上传代码到GitHub
1.准备 下载Git for Windows (msysgit) 下载TortoiseGit 安装过程很简单,一直点击下一步到完成即可. 2.配置TortoiseGit 1.双击TortoiseGit ...
- 关于EF执行返回表的存储过程
1.关于EF执行返回表的存储过程 不知道为什么EF生成的存储过程方法会报错,以下方法可以使用,call是MySQL执行存储过程的命令 [HttpGet] public HttpResponseMess ...
- ubuntu下安装MySQL8.0
为了一劳永逸不每次都到处找资料,花了一下午时间做了这些.其中大部分是根据官方手册来的,后面部分谢谢大佬的帮助,超开心. 一.首先,将MySQL APT存储库添加到系统的软件存储库列表中 1.转到htt ...
- python的返回值
1.返回值的作用 函数并非总是直接显示输出,相反,它可以处理一些数据,并返回一个或一组值.函数返回的值被称为返回值.在函数中,可使用return语句将值返回到调用函数的代码行.返回值让你能够将程序的大 ...
- Java Socket, DatagramSocket, ServerSocketChannel io代码跟踪
Java Socket, DatagramSocket, ServerSocketChannel这三个分别对应了,TCP, udp, NIO通信API封装.JDK封装了,想跟下代码,看下具体最后是怎么 ...
- 重构指南 - 移除重复内容(Remove Duplication)
在项目中或多或少的都存在着重复的或者功能相似的代码,如果要对代码做改动,就要修改多个地方,所以我们需要将多处重复的代码提取到一个公共的地方供统一调用,以减少代码量,提高代码可维护性. 重构前代码 pu ...