在Spark shell中基于HDFS文件系统进行wordcount交互式分析
Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以Standalone方式部署在单个机器上面。运行Spark的方式有interactive和submit方式。本文中所有的操作都是以interactive方式操作以Standalone方式部署的Spark。具体的部署方式,请参考Hadoop Ecosystem。
HDFS是一个分布式的文件管理系统,其随着Hadoop的安装而进行默认安装。部署方式有本地模式和集群模式,本文中使用的时本地模式。具体的部署方式,请参考Hadoop Ecosystem。
目标:
能够通过HDFS文件系统在Spark-shell中进行WordCount的操作。
前提:
存在一个文件,可通过下面的命令进行查看。
hadoop fs -ls /

如果不存在,添加一个(LICENSE文件需要在本地目录中存在)。更多hadoop命令,请参考hadoop命令。
hadoop fs -put LICENSE /license.txt
通过Web Browser查看Hadoop是否已经运行。
http://localhost:50070

步骤:
Step 1:进入Spark-shell交互式命令行。
spark-shell
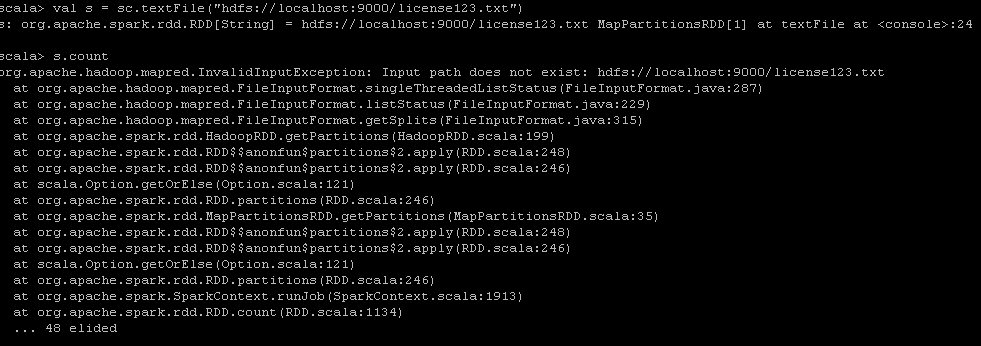
Step 2:读取license.txt文件,并check读取是否成功。如果不存在,则提示如下错误。
val s = sc.textFile("hdfs://localhost:9000/license.txt")
s.count
Step 3:设定输出的文件个数并执行统计逻辑
val numOutputFiles = 128
val counts = s.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _, numOutputFiles)
Step 4:保存计算结果到HDFS中
counts.saveAsTextFile("hdfs://localhost:9000/license_hdfs.txt")
Step 5:在shell中查看结果
hadoop fs -cat /license_hdfs.txt/*
结论:
通过HDFS,我们可以在Spark-shell中轻松地进行交互式的分析(word count统计)。
参考资料:
http://hadoop.apache.org/docs/r1.0.4/cn/commands_manual.html
http://spark.apache.org/docs/latest/programming-guide.html
http://coe4bd.github.io/HadoopHowTo/sparkScala/sparkScala.html
http://coe4bd.github.io/HadoopHowTo/sparkJava/sparkJava.html
在Spark shell中基于HDFS文件系统进行wordcount交互式分析的更多相关文章
- 在Spark shell中基于Alluxio进行wordcount交互式分析
Spark是一个分布式内存计算框架,可部署在YARN或者MESOS管理的分布式系统中(Fully Distributed),也可以以Pseudo Distributed方式部署在单个机器上面,还可以以 ...
- 输入DStream之基础数据源以及基于HDFS的实时wordcount程序
输入DStream之基础数据源以及基于HDFS的实时wordcount程序 一.Java方式 二.Scala方式 基于HDFS文件的实时计算,其实就是,监控一个HDFS目录,只要其中有新文件出现,就实 ...
- 52、Spark Streaming之输入DStream之基础数据源以及基于HDFS的实时wordcount程序
一.概述 1.Socket:之前的wordcount例子,已经演示过了,StreamingContext.socketTextStream() 2.HDFS文件 基于HDFS文件的实时计算,其实就是, ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- 在spark udf中读取hdfs上的文件
某些场景下,我们在写UDF实现业务逻辑时候,可能需要去读取某个文件. 我们可以将此文件上传个hdfs某个路径下,然后通过hdfs api读取该文件,但是需要注意: UDF中读取文件部分最好放在静态代码 ...
- cloudera manager安装spark后使用spark shell编写基于scala的world count
val file = sc.textFile("hdfs://zhcloudil-lcnode04:8020/user/cloudil/wc_spark.txt") val cou ...
- Spark Shell简单使用
基础 Spark的shell作为一个强大的交互式数据分析工具,提供了一个简单的方式学习API.它可以使用Scala(在Java虚拟机上运行现有的Java库的一个很好方式)或Python.在Spark目 ...
- Hadoop Shell命令(基于linux操作系统上传下载文件到hdfs文件系统基本命令学习)
Apache-->hadoop的官网文档命令学习:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html FS Shell 调用文件系统( ...
- Tachyon:Spark生态系统中的分布式内存文件系统
转自: http://www.csdn.net/article/2015-06-25/2825056 摘要:Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, ...
随机推荐
- ExposedObject的使用
ExposedObject可以将一个对象快速封装未一个dynamic using System; namespace ConsoleApp2 { class Program { static void ...
- 【题解】 UVa11300 Spreading the Wealth
题目大意 圆桌旁边坐着\(n\)个人,每个人有一定数量的金币,金币的总数能被\(n\)整除.每个人可以给他左右相邻的人一些金币,最终使得每个人的金币数量相等.您的任务是求出被转手的金币的数量的最小值. ...
- ubuntu14.04,安装Chrome(谷歌浏览器)
Linux:ubuntu14.04 一直都很喜欢谷歌浏览器,进入linux怎么能没有? 安装方法:谷歌浏览器官方下载的ubuntu版本,下载后点击即可安装. 下载地址:http://download. ...
- 如何修改git显示的用户名
我是这样试了一下,可以改: 输入修改用户名和邮箱: $git config --global user.email "tanteng@gmail.com" $git config ...
- 洛谷P1963 [NOI2009]变换序列(二分图)
传送门 我可能真的只会网络流……二分图的题一点都做不来…… 首先每个位置有两种取值,所以建一个二分图,只要有完美匹配就说明有解 考虑一下每一个位置,分别让它选择两种取值,如果都不能形成完美匹配,说明无 ...
- birth
第一次开通博客, 今天开始了计算机方面的学习,我将通过博客来总结自己的学习内容以及分享学习经验,同时我将分享在技术方面的所见所闻以及所思所想,希望能和大家一起探讨,共同进步~
- 基于Spring MVC的文件上传和下载功能的实现
配置文件中配置扫描包,以便创建各个类的bean对象 <context:component-scan base-package="com.neuedu.spring_mvc"& ...
- shell-002:统计IP访问量
统计IP访问量 #!/bin/bash # 统计IP的访问量 # 第一步首先得获取到日志的IP # 第二步给IP排序,这样相同的的IP就会在一起 sort # 第三步则给重复的IP统计数量,去重 un ...
- GDI绘图写的简单扫雷
由于没话多少时间,这个扫雷我只实现了主要功能(扫雷功能,递归实现) 废话不多说,直接上代码 using System; using System.Collections.Generic; using ...
- [软件工程]团队介绍&学长采访
项目 内容 这个作业属于哪个课程 2019春季计算机学院软件工程(罗杰) 这个作业的要求在哪里 第一次团队作业 - 采访! 我们在这个课程的目标是 团队开发,合作学习 1.团队介绍 岗位 人员& ...