HashMap的结构算法及代码分析
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // entry数组为空,new HashMap的时候,并没有初始化数组
n = (tab = resize()).length; //初始化数组,稍后看resize()实现
if ((p = tab[i = (n - 1) & hash]) == null) //分配到的数组位置为null,这里一个很巧妙的操作,没有用取模%运算,而是这个位与,效率更高而且正好这里等于取模
tab[i] = newNode(hash, key, value, null);
else {//分配到的位置不是null的情况,要遍历链表
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // key跟链表第一个元素的key相同,这里比较的是hashcode跟equals,从本方法以及Node的构造方法来看,Node的hash就是其中键的hash值
e = p; // 注意,这里找到后并没有修改节点的值,节点的值是在后边修改的
else if (p instanceof TreeNode) //是treenode,jdk8在链表长度超过8后将node改为红黑树进行优化
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { //遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {// 新元素放于链表尾部
p.next = newNode(hash, key, value, null); // 结合Node的构造方法,node的hash就是此处的hash
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break; //已设置新元素,终止循环
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) //链表有节点的hash跟新元素相同并且equals判断也相等
break; //找到了,终止循环
p = e; // 注意,这句不在if范围内,仅仅在for循环内而已,所以如果已经有对应节点已经有oldValue的情况下,并没有修改原来的值,修改的操作在后边
}
}
if (e != null) { // existing mapping for key //有oldValue的情况,e就是旧节点
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) // 允许重写原来值,或者原来的值为null,注意,onlyIfAbsent,这个属性hashmap实际没用,一直是默认false,也就一直默认覆盖原来的值
e.value = value;
afterNodeAccess(e); // 值更新之后的操作,hashmap中此方法为空,无任何操作,该方法以及后边的afterNodeInsertion()都是给LinkedHashMap用的。
return oldValue;
}
}
++modCount; // 修改计数器,其实只有新增才修改了此值,覆盖原来值的操作,因为提前return 了,此值没有改变
if (++size > threshold) // hashMpa的容量达到了阈值
resize();
afterNodeInsertion(evict);
return null;
}
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
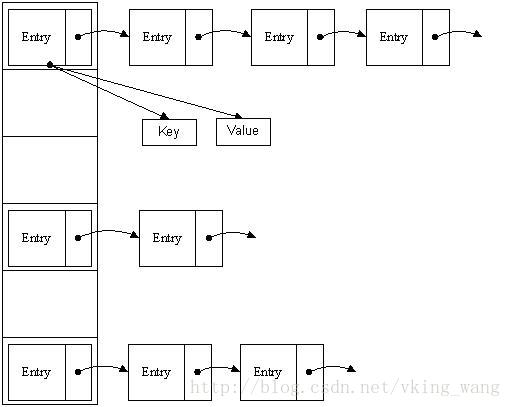
链表的实现类Node:
static class Node<K,V> implements Map.Entry<K,V> { //相当于链表节点
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) { // 节点的hash就是所给元素的hash
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) { //
if (o == this) // 地址相等----------其实这个值不一定是内存地址,不同虚拟机实现不同,sun貌似是地址的一个hash值
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) // 键跟值的equals都相等
return true;
}
return false;
}
}
非常重要的resize() 方法:
/**
* Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
* @return the table
*/
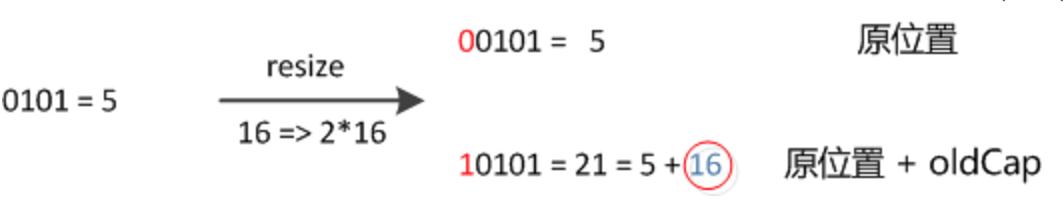
1. final Node<K,V>[] resize() {
2. Node<K,V>[] oldTab = table; //老的数组,也就是所谓的桶
3. int oldCap = (oldTab == null) ? 0 : oldTab.length; // 老的容量
4. int oldThr = threshold; // 阈值
5. int newCap, newThr = 0;
6. if (oldCap > 0) { // 老的容量>0,说明map里已经有元素了
7. if (oldCap >= MAXIMUM_CAPACITY) { // 老的容量已经很大了,直接把阈值扩展到最大,不再容量翻倍了,太费劲了,而且效率提升有限,此时容量2的29次方,大概在3亿
8. threshold = Integer.MAX_VALUE;
9. return oldTab;
10. }
11. else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) //老容量在2<<<28的时候还能翻倍,到了2<<<29就不翻倍了,凑合着用吧
12. newThr = oldThr << 1; // double threshold
13. }
14. else if (oldThr > 0) // initial capacity was placed in threshold // 老容量==0,阈值>0,说明调用了new HashMap(容量=0,加载因子);
15. newCap = oldThr;
16. else { // zero initial threshold signifies using defaults //都是用默认值
17. newCap = DEFAULT_INITIAL_CAPACITY; // 默认1<<<4 = 16
18. newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //默认16*0.75=12
19. }
20. if (newThr == 0) { //上来就new HashMap(容量大于2<<<29);没有指定加载因子的情况,自己计算阈值
21. float ft = (float)newCap * loadFactor;
22. newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
23. (int)ft : Integer.MAX_VALUE);
24. }
25. threshold = newThr;
26. Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
27. table = newTab;
28. if (oldTab != null) {
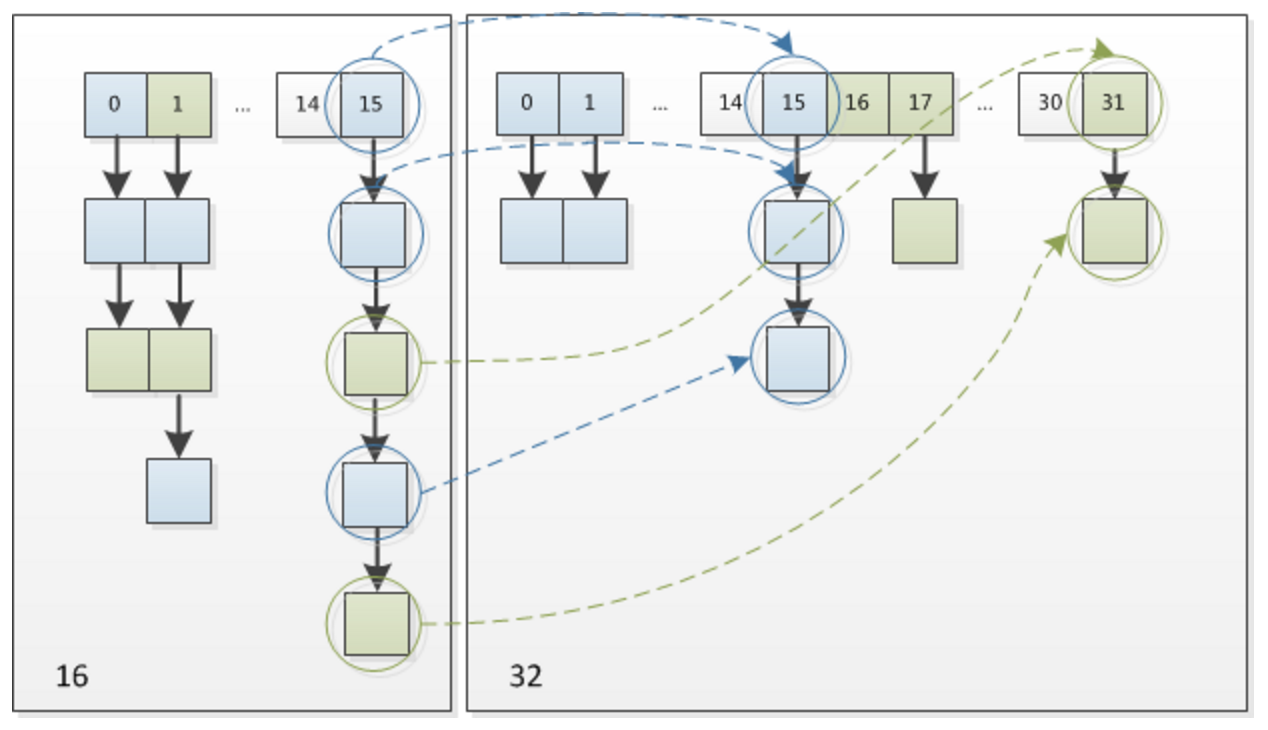
29. for (int j = 0; j < oldCap; ++j) { // 重点来了,迁移老数组进新数组
30. Node<K,V> e;
31. if ((e = oldTab[j]) != null) {
32. oldTab[j] = null;
33. if (e.next == null) //原数组j下标下,就一个元素
34. newTab[e.hash & (newCap - 1)] = e; //直接快速位与取模,找下标
35. else if (e instanceof TreeNode) //是红黑树节点
36. ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
37. else { // preserve order
38. Node<K,V> loHead = null, loTail = null; //这里分别lowHead tail跟highHead tail两个对象,稍后分析为啥这么写
39. Node<K,V> hiHead = null, hiTail = null;
40. Node<K,V> next;
41. do { // j下标下有好多个链表的情况
42. next = e.next;
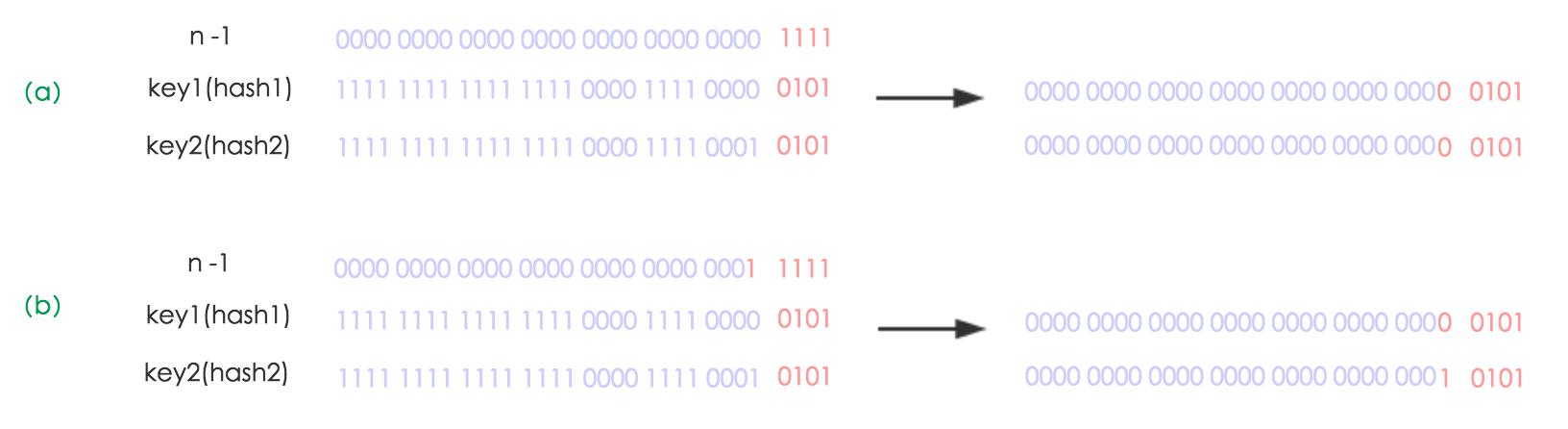
43. if ((e.hash & oldCap) == 0) {//hash中参与计算的新一位为0,下标不变; 计算方式参照上方图解;
44. if (loTail == null)
45. loHead = e;
46. else
47. loTail.next = e;
48. loTail = e;
49. }
50. else { // hash中参与计算的新一位为1,下标变为 原容量+原下标,不用重新计算了,省事儿,就是优化在这里了(实际这一步也是计算了,只是计算比原来简单了)
51. if (hiTail == null)
52. hiHead = e;
53. else
54. hiTail.next = e;
55. hiTail = e;
56. }
57. } while ((e = next) != null);// 遍历下一个元素
58. if (loTail != null) { // 设置下标,放入新数组
59. loTail.next = null;
60. newTab[j] = loHead;
61. }
62. if (hiTail != null) { // 设置下标,放入新数组
63. hiTail.next = null;
64. newTab[j + oldCap] = hiHead;
65. }
66. }
67. }
68. }
69. }
70. return newTab;
71. }
关于HashMap的初始容量:
1. public HashMap(int initialCapacity, float loadFactor) {
2. if (initialCapacity < 0) //给定初始长度<0则抛异常
3. throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
4. if (initialCapacity > MAXIMUM_CAPACITY) //给定初始长度太大,则设为默认最大容量
5. initialCapacity = MAXIMUM_CAPACITY;
6. if (loadFactor <= 0 || Float.isNaN(loadFactor)) //给定负载因子<0或者不是数字,抛异常
7. throw new IllegalArgumentException("Illegal load factor: " +
8. loadFactor);
9. this.loadFactor = loadFactor; //负载因子采用给定值
10. this.threshold = tableSizeFor(initialCapacity); //阈值利用初始容量,通过一个方法进行计算
11. }
计算方法:
1. static final int tableSizeFor(int cap) {
2. int n = cap - 1;
3. n |= n >>> 1; // n = n | n >>> 1
4. n |= n >>> 2;
5. n |= n >>> 4;
6. n |= n >>> 8;
7. n |= n >>> 16;
8. return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
9. }
这个方法的作用就是无论初始容量是多少,最终的容量都将计算为不小于初始容量的2的最小次幂;比如初始容量为4,则经变化后初始容量仍为4,若初始容量为5,则变化后容量应该为8而不是5;之所以这么变化,是因为resize的机制中计算方式,table的长度必须为2的幂,否则计算方式会出错,而且计算起来会比现在复杂。
Iterator<Map.Entry<String, String>> iterator;
iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> next = iterator.next();
String key = next.getKey();
String value = next.getValue();
}
我们通过map得到了一个entrySet对象,然后又获取了一个Iterator对象,最终就是通过这个Iterator来遍历的,那么这个Iterator是怎么个结构,如何实现遍历的呢?
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
//......
}
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
HashIterator的代码:
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() { //构造方法
expectedModCount = modCount;
Node<K,V>[] t = table; //map中哈希表的数组
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);//找到数组中第一个非空元素,赋值给next
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {//本链表找完了,顺着数组找下一个链表,然后遍历
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
}
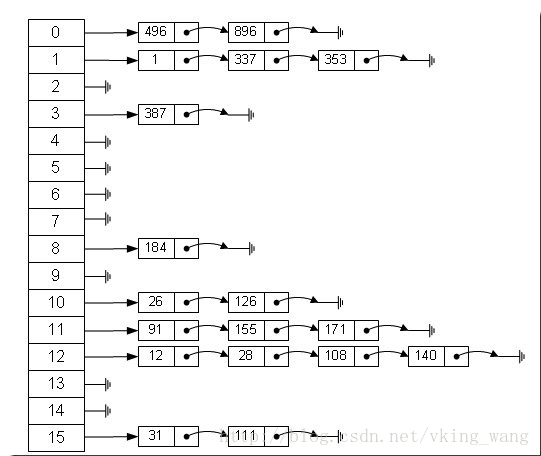
总结,遍历的过程就是找到数组中第一链表开始的位置,顺着遍历完本链表,然后顺着数组找第二个链表的位置,然后遍历第二个链表,这样一条链表一条链表的顺着来的。
HashMap的结构算法及代码分析的更多相关文章
- C++反汇编代码分析--函数调用
推荐阅读: C++反汇编代码分析–函数调用 C++反汇编代码分析–循环结构 C++反汇编代码分析–偷调函数 走进内存,走进汇编指令来看C/C++指针 代码如下: #include "stdl ...
- HashMap的结构以及核心源码分析
摘要 对于Java开发人员来说,能够熟练地掌握java的集合类是必须的,本节想要跟大家共同学习一下JDK1.8中HashMap的底层实现与源码分析.HashMap是开发中使用频率最高的用于映射(键值对 ...
- ADB结构及代码分析【转】
本文转载自:http://blog.csdn.net/happylifer/article/details/7682563 最近因为需要,看了下adb的源代码,感觉这个作者很牛,设计的很好,于是稍微做 ...
- KMP算法以及优化(代码分析以及求解next数组和nextval数组)
KMP算法以及优化(代码分析以及求解next数组和nextval数组) 来了,数据结构及算法的内容来了,这才是我们的专攻,前面写的都是开胃小菜,本篇文章,侧重考研408方向,所以保证了你只要看懂了,题 ...
- HashMap底层结构、原理、扩容机制
https://www.jianshu.com/p/c1b616ff1130 http://youzhixueyuan.com/the-underlying-structure-and-princip ...
- Java7/8 中 HashMap 和 ConcurrentHashMap的对比和分析
大家可能平时用HashMap比较多,相对于ConcurrentHashMap 来说并不是很熟悉.ConcurrentHashMap 是 JDK 1.5 添加的新集合,用来保证线程安全性,提升 Map ...
- HashMap的小总结 + 源码分析
一.HashMap的原理 所谓Map,就是关联数组,存的是键值对——key&value. 实现一个简单的Map,你也许会直接用两个LIst,一个存key,一个存value.然后做查询或者get ...
- 1.Java集合-HashMap实现原理及源码分析
哈希表(Hash Table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
随机推荐
- 小程序上传多图片多附件多视频 c#后端
前言: 最近在研究微信小程序,本人自己是C#写后端的;感觉小程序挺好玩的,就自己研究了一下:刚好今天又给我需求,通过小程序上传多图 然后C#后端保存到服务器: 用NET明白 前端上传需要用到流,然后就 ...
- .net core 结合nlog使用Elasticsearch , Logstash, Kibana
什么是ELK ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件.新增了一个FileBeat,它是一个轻量级的日志收集处理工具 ...
- MultiDataTrigger
MultiDataTrigger是多条件数据触发器 和MltiTrigger是同样的,只不过前者是数据,后者是属性. 这个是基本的使用语法 <MultiDataTrigger> <M ...
- Tensorflow报错:InvalidArgumentError: You must feed a value for placeholder tensor 'input_y' with dtype
此错误神奇之处是每次第一次运行不会报错,第二次.第三次第四次....就都报错了.关掉重启,又不报错了,运行完再运行一次立马报错!搞笑! 折磨了我半天,终于被我给解决了! 问题解决来源于这边博客:htt ...
- golang并发练习代码笔记
golang语言的精髓就是它的并发机制,十分简单,并且极少数在语言层面实现并发机制的语言,golang被成为网络时代的c语言,golang的缔造者也有c语言的缔造者,Go语言是google 推出的一门 ...
- [agc014d] Black and White Tree
Description 有一颗n个点的树,刚开始每个点都没有颜色. Alice和Bob会轮流对这棵树的一个点涂色,Alice涂白,Bob涂黑,Alice先手. 若最后存在一个白点,使得这个 ...
- 洛谷P4011 孤岛营救问题(状压+BFS)
传送门 和网络流有半毛钱关系么…… 可以发现$n,m,p$都特别小,那么考虑状压,每一个状态表示位置以及钥匙的拥有情况,然后每次因为只能走一步,所以可以用bfs求出最优解 然后是某大佬说的注意点:每个 ...
- Java面向对象之构造代码块 入门实例
一.基础概念 1.构造代码块,给所有对象进行初始化. 2.构造函数,只给对应的对象初始化. 3.局部代码块,控制局部变量的生命周期. 二.实例代码 class Person { private int ...
- python中文件路径的问题
慎用中文路径!慎重中文路径!!慎用中文路径!!! good = np.loadtxt(u'D:/feiq/feiq/Recv Files/Recv Files/LOS 数据集/good_user2', ...
- 【离散数学】SDUT OJ 指定长度路径数
指定长度路径数 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Problem Description 题目给出一个有n个节点 ...