flink学习笔记-数据源(DataSource)
说明:本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1.4 JobGraph -> ExecutionGraph
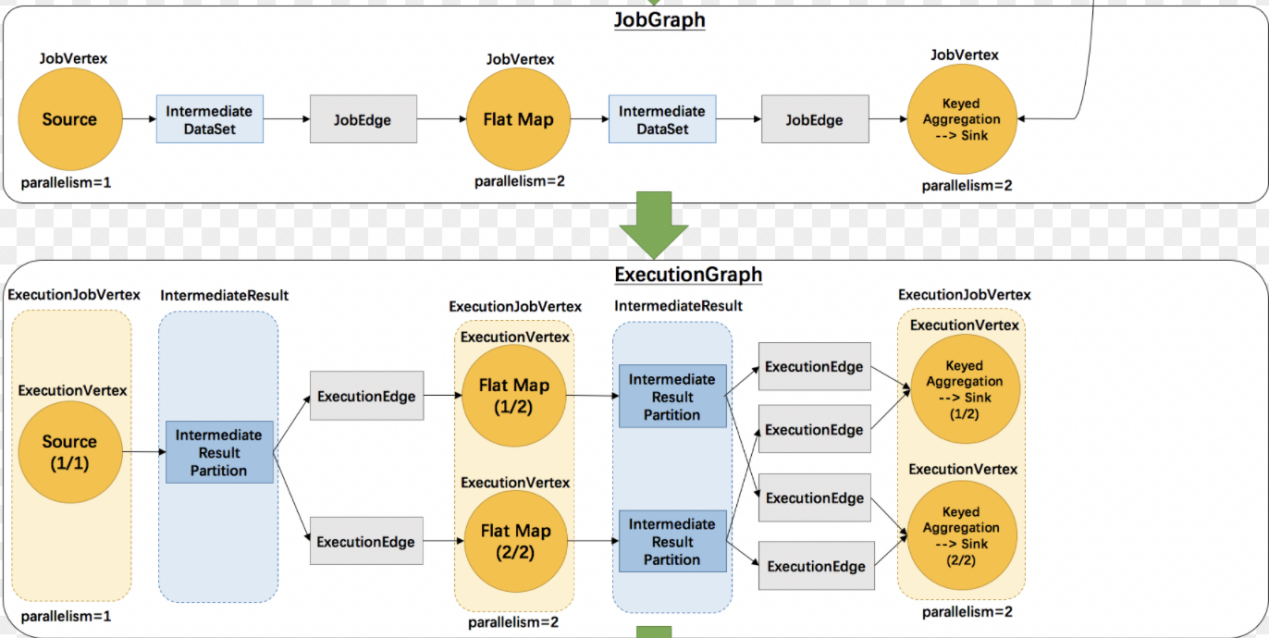
1.5 ExecutionGraph
从JobGraph转换ExecutionGraph的过程中,内部会出现如下的转换。
1.ExecutionJobVertex <- JobVertex:JobVertex转换为ExecutionJobVertex 。
2.ExecutionVertex(比如map)可以并发多个任务。
3.ExecutionEdge <- JobEdge:JobEdge转换为ExecutionEdge。
4.ExecutionGraph 是一个2维结构。
5.根据2维结构分发对应Vertex到指定slot 。
2. DataStreamContext
Flink通过StreamExecutionEnvironment.getExecutionEnvironment()方法获取一个执行环境,Flink引用是在本地执行,还是以集群方式执行,系统会自动识别。如果是本地执行会调用createLocalEnvironment()方法,如果是集群执行会调用createExecutionEnvironment()。
3. 数据源(DataSource)
Flink数据源可以有两种实现方式:
1.内置数据源
a)基于文件
b)基于Socket
c)基于Collection
2.自定义数据源
a)实现SourceFunction(非并行的)
b)实现ParallelSourceFunction
c)继承RichParallelSourceFunction
public class SimpleSourceFunction implements ParallelSourceFunction<Long> {
private long num = 0L;
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<Long> sourceContext) throws Exception {
while (isRunning) {
sourceContext.collect(num); num++;
Thread.sleep(10000);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
4. Transformation
Transformation(Operators/操作符/算子):可以将一个或多个DataStream转换为新的DataStream。
5. DataSink
Flink也包含两类Sink:
1.常用的sink会在后续的connectors中介绍。
2.自定义Sink
自定义Sink可以实现SinkFunction 接口,也可以继承RichSinkFunction。
6. 流式迭代运算(Iterations)
简单理解迭代运算:
当前一次运算的输出作为下一次运算的输入(当前运算叫做迭代运算)。不断反复进行某种运算,直到达到某个条件才跳出迭代(是不是想起了递归)
流式迭代运算:
1.它没有最大迭代次数
2.它需要通过split/filter转换操作指定流的哪些部分数据反馈给迭代算子,哪些部分数据被转发到下游DataStream
3.基本套路
1)基于输入流构建IterativeStream(迭代头)
2)定义迭代逻辑(map fun等)
3)定义反馈流逻辑(从迭代过的流中过滤出符合条件的元素组成的部分流反馈给迭代头进行重复计算的逻辑)
4)调用IterativeStream的closeWith方法可以关闭一个迭代(也可表述为定义了迭代尾)
5)定义“终止迭代”的逻辑(符合条件的元素将被分发给下游而不用于进行下一次迭代)
4.流式迭代运算实例
问题域:输入一组数据,我们对他们分别进行减1运算,直到等于0为止.
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.IterativeStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @Author: lifei
* @Date: 2018/12/16 下午6:43
*/
public class IterativeStreamJob {
public static void main(String[] args) throws Exception {
//输入一组数据,我们对他们分别进行减1运算,直到等于0为止
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input=env.generateSequence(0,100);//1,2,3,4,5
//基于输入流构建IterativeStream(迭代头)
IterativeStream<Long> itStream=input.iterate();
//定义迭代逻辑(map fun等)
DataStream<Long> minusOne=itStream.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value-1;
}
});
//定义反馈流逻辑(从迭代过的流中过滤出符合条件的元素组成的部分流反馈给迭代头进行重复计算的逻辑)
DataStream<Long> greaterThanZero=minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value>0;
}
});
//调用IterativeStream的closeWith方法可以关闭一个迭代(也可表述为定义了迭代尾)
itStream.closeWith(greaterThanZero);
//定义“终止迭代”的逻辑(符合条件的元素将被分发给下游而不用于进行下一次迭代)
DataStream<Long> lessThanZero=minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value<=0;
}
});
lessThanZero.print();
env.execute("IterativeStreamJob");
}
}
7. Execution参数
Controlling Latency(控制延迟)
1.默认情况下,流中的元素并不会一个一个的在网络中传输(这会导致不必要的网络流量消耗),而是缓存起来,缓存的大小可以在Flink的配置文件、 ExecutionEnvironment、设置某个算子上进行配置(默认100ms)。
1)好处:提高吞吐
2)坏处:增加了延迟
2.如何把握平衡
1)为了最大吞吐量,可以设置setBufferTimeout(-1),这会移除timeout机制,缓存中的数据一满就会被发送
2)为了最小的延迟,可以将超时设置为接近0的数(例如5或者10ms)
3)缓存的超时不要设置为0,因为设置为0会带来一些性能的损耗
3.其他更多的Execution参数后面会有专题讲解
8. 调试
对于具体开发项目,Flink提供了多种调试手段。Streaming程序发布之前最好先进行调试,看看是不是能按预期执行。为了降低分布式流处理程序调试的难度,Flink提供了一些列方法:
1.本地执行环境
2.Collection Data Sources
3.Iterator Data Sink
本地执行环境:
本地执行环境不需要刻意创建,可以断点调试
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
DataStream<String> lines = env.addSource(/* some source */);
env.execute();
Collection Data Sources:
Flink提供了一些Java 集合支持的特殊数据源来使得测试更加容易,程序测试成功后,将source和sink替换成真正source和sink即可。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.fromElements(1, 2, 3, 4, 5);
env.fromCollection(Collection);
env.fromCollection(Iterator, Class);
env.generateSequence(0, 1000)
Iterator Data Sink:
Flink提供一个特殊的sink来收集DataStream的结果
DataStream<Tuple2<String, Integer>> myResult = ...
Iterator<Tuple2<String, Integer>> myOutput = DataStreamUtils.collect(myResult)
(8)Operators串烧
1. DataStream Transformation
1.1 DataStream转换关系
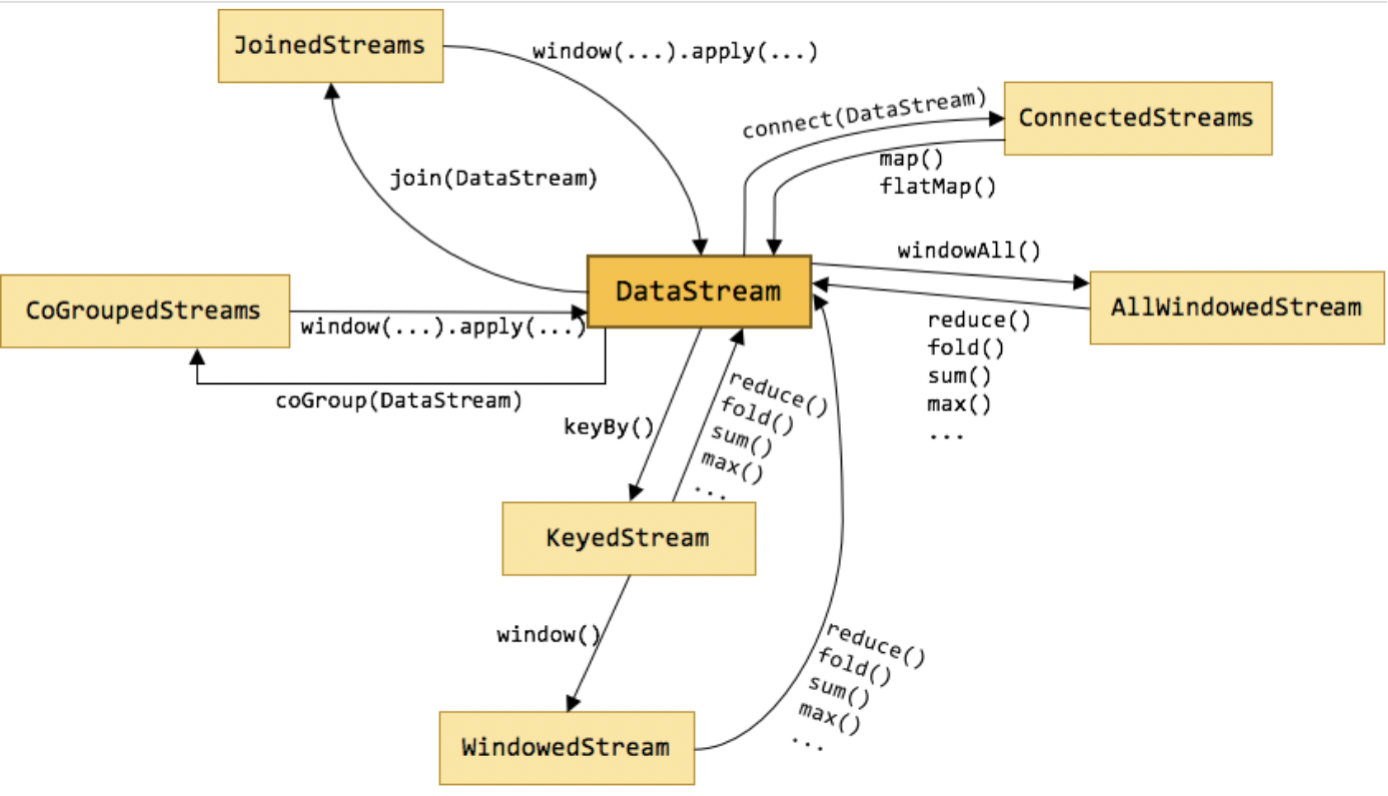
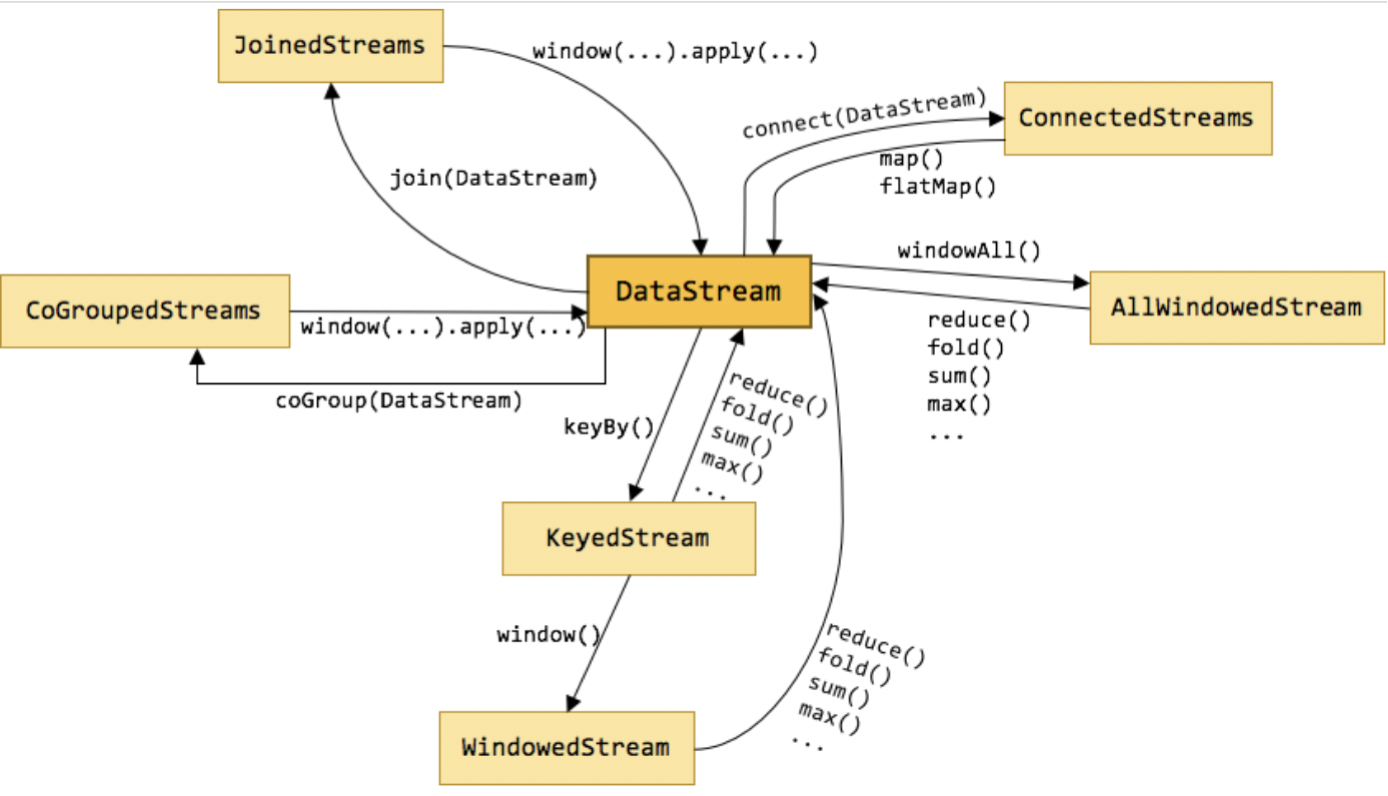
上图标识了DataStream不同形态直接的转换关系,也可以看出DataStream主要包含以下几类:
1.keyby就是按照指定的key分组
2.window是一种特殊的分组(基于时间)
3.coGroup
4.join Join是cogroup 的特例
5.Connect就是松散联盟,类似于英联邦
1.2 DataStream
DataStream 是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。
一个 DataStream 可以从 StreamExecutionEnvironment 通过env.addSource(SourceFunction) 获得。
1.3 map&flatMap
含义:数据映射(1进1出和1进n出)
转换关系:DataStream → DataStream
使用场景:
ETL时删减计算过程中不需要的字段
案例1:
public class TestMap {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input=env.generateSequence(0,10);
DataStream plusOne=input.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("--------------------"+value);
return value+1;
}
});
plusOne.print();
env.execute();
}
}
案例2:
public class TestFlatmap {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> input=env.fromElements(WORDS);
DataStream<String> wordStream=input.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(token);
}
}
}
});
wordStream.print();
env.execute();
}
public static final String[] WORDS = new String[] {
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"And by opposing end them?--To die,--to sleep,--",
"Be all my sins remember'd."
};
}

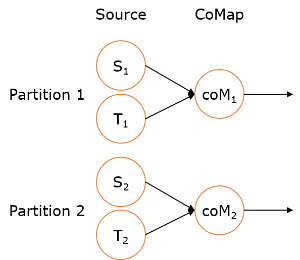
如右上图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例(S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。这与 Apache Kafka 是很类似的,把流想象成 Kafka Topic,而一个流分区就表示一个 Topic Partition,流的目标并行算子实例就是 Kafka Consumers。
1.4 filter
含义:数据筛选(满足条件event的被筛选出来进行后续处理),根据FliterFunction返回的布尔值来判断是否保留元素,true为保留,false则丢弃
转换关系: DataStream → DataStream
使用场景:
过滤脏数据、数据清洗等

案例:
public class TestFilter {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input=env.generateSequence(-5,5);
input.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value>0;
}
}).print();
env.execute();
}
}
1.5 keyBy
含义:
根据指定的key进行分组(逻辑上把DataStream分成若干不相交的分区,key一样的event会被划分到相同的partition,内部采用hash分区来实现)
转换关系: DataStream → KeyedStream
限制:
1.可能会出现数据倾斜,可根据实际情况结合物理分区来解决(后面马上会讲到)
2.Key的类型限制:
1)不能是没有覆盖hashCode方法的POJO
2)不能是数组
使用场景:
1.分组(类比SQL中的分组)
案例:
public class TestKeyBy {
public static void main(String[] args) throws Exception {
//统计各班语文成绩最高分是谁
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple4<String,String,String,Integer>> input=env.fromElements(TRANSCRIPT);
KeyedStream<Tuple4<String,String,String,Integer>,Tuple> keyedStream = input.keyBy("f0");
keyedStream.maxBy("f3").print();
env.execute();
public static final Tuple4[] TRANSCRIPT = new Tuple4[] {
Tuple4.of("class1","张三","语文",100),
Tuple4.of("class1","李四","语文",78),
Tuple4.of("class1","王五","语文",99),
Tuple4.of("class2","赵六","语文",81),
Tuple4.of("class2","钱七","语文",59),
Tuple4.of("class2","马二","语文",97)
};
}
1.6 KeyedStream
KeyedStream用来表示根据指定的key进行分组的数据流。
一个KeyedStream可以通过调用DataStream.keyBy()来获得。
在KeyedStream上进行任何transformation都将转变回DataStream。
在实现中,KeyedStream是把key的信息写入到了transformation中。
每个event只能访问所属key的状态,其上的聚合函数可以方便地操作和保存对应key的状态。
1.7 reduce&fold& Aggregations
分组之后当然要对分组之后的数据也就是KeyedStream进行各种聚合操作啦(想想SQL)。
KeyedStream → DataStream
对于KeyedStream的聚合操作都是滚动的(rolling,在前面的状态基础上继续聚合),千万不要理解为批处理时的聚合操作(DataSet,其实也是滚动聚合,只不过他只把最后的结果给了我们)。

案例1:
public class TestReduce {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple4<String,String,String,Integer>> input=env.fromElements(TRANSCRIPT);
KeyedStream<Tuple4<String,String,String,Integer>,Tuple> keyedStream = input.keyBy(0);
keyedStream.reduce(new ReduceFunction<Tuple4<String, String, String, Integer>>() {
@Override
public Tuple4<String, String, String, Integer> reduce(Tuple4<String, String, String,
Integer> value1, Tuple4<String, String, String, Integer> value2) throws Exception {
value1.f3+=value2.f3;
return value1;
}
}).print();
env.execute();
}
public static final Tuple4[] TRANSCRIPT = new Tuple4[] {
Tuple4.of("class1","张三","语文",100),
Tuple4.of("class1","李四","语文",78),
Tuple4.of("class1","王五","语文",99),
Tuple4.of("class2","赵六","语文",81),
Tuple4.of("class2","钱七","语文",59),
Tuple4.of("class2","马二","语文",97)
};
}
案例2:
public class TestFold {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple4<String,String,String,Integer>> input=env.fromElements(TRANSCRIPT);
DataStream<String> result =input.keyBy(0).fold("Start", new FoldFunction<Tuple4<String,String,String,Integer>,String>() {
@Override
public String fold(String accumulator, Tuple4<String, String, String, Integer> value) throws Exception {
return accumulator + "=" + value.f1;
}
});
result.print();
env.execute();
}
public static final Tuple4[] TRANSCRIPT = new Tuple4[] {
Tuple4.of("class1","张三","语文",100),
Tuple4.of("class1","李四","语文",78),
Tuple4.of("class1","王五","语文",99),
Tuple4.of("class2","赵六","语文",81),
Tuple4.of("class2","钱七","语文",59),
Tuple4.of("class2","马二","语文",97)
};
}
1.8 Interval join
KeyedStream,KeyedStream → DataStream
在给定的周期内,按照指定的key对两个KeyedStream进行join操作,把符合join条件的两个event拉到一起,然后怎么处理由用户你来定义。
key1 == key2 && e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
场景:把一定时间范围内相关的分组数据拉成一个宽表
案例:
public class TestIntervalJoin {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<Transcript> input1=env.fromElements(TRANSCRIPTS).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Transcript>() {
@Override
public long extractAscendingTimestamp(Transcript element) {
return element.time;
}
});
DataStream<Student> input2=env.fromElements(STUDENTS).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Student>() {
@Override
public long extractAscendingTimestamp(Student element) {
return element.time;
}
});
KeyedStream<Transcript,String> keyedStream=input1.keyBy(new KeySelector<Transcript, String>() {
@Override
public String getKey(Transcript value) throws Exception {
return value.id;
}
});
KeyedStream<Student,String> otherKeyedStream=input2.keyBy(new KeySelector<Student, String>() {
@Override
public String getKey(Student value) throws Exception {
return value.id;
}
});
//e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
// key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2))
.upperBoundExclusive()
.lowerBoundExclusive()
.process(new ProcessJoinFunction<Transcript, Student, Tuple5<String,String,String,String,Integer>>() {
@Override
public void processElement(Transcript transcript, Student student, Context ctx, Collector<Tuple5<String, String, String, String, Integer>> out) throws Exception {
out.collect(Tuple5.of(transcript.id,transcript.name,student.class_,transcript.subject,transcript.score));
}
}).print();
env.execute();
}
public static final Transcript[] TRANSCRIPTS = new Transcript[] {
new Transcript("1","张三","语文",100,System.currentTimeMillis()),
new Transcript("2","李四","语文",78,System.currentTimeMillis()),
new Transcript("3","王五","语文",99,System.currentTimeMillis()),
new Transcript("4","赵六","语文",81,System.currentTimeMillis()),
new Transcript("5","钱七","语文",59,System.currentTimeMillis()),
new Transcript("6","马二","语文",97,System.currentTimeMillis())
};
public static final Student[] STUDENTS = new Student[] {
new Student("1","张三","class1",System.currentTimeMillis()),
new Student("2","李四","class1",System.currentTimeMillis()),
new Student("3","王五","class1",System.currentTimeMillis()),
new Student("4","赵六","class2",System.currentTimeMillis()),
new Student("5","钱七","class2",System.currentTimeMillis()),
new Student("6","马二","class2",System.currentTimeMillis())
};
private static class Transcript{
private String id;
private String name;
private String subject;
private int score;
private long time;
public Transcript(String id, String name, String subject, int score, long time) {
this.id = id;
this.name = name;
this.subject = subject;
this.score = score;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
}
private static class Student{
private String id;
private String name;
private String class_;
private long time;
public Student(String id, String name, String class_, long time) {
this.id = id;
this.name = name;
this.class_ = class_;
this.time = time;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getClass_() {
return class_;
}
public void setClass_(String class_) {
this.class_ = class_;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
}
}
1.9 connect & union(合并流)
connect之后生成ConnectedStreams,会对两个流的数据应用不同的处理方法,并且双流 之间可以共享状态(比如计数)。这在第一个流的输入会影响第二个流 时, 会非常有用; union 合并多个流,新的流包含所有流的数据。
union是DataStream* → DataStream。
connect只能连接两个流,而union可以连接多于两个流 。
connect连接的两个流类型可以不一致,而union连接的流的类型必须一致。
案例:
public class TestConnect {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> someStream = env.generateSequence(0,10);
DataStream<String> otherStream = env.fromElements(WORDS);
ConnectedStreams<Long, String> connectedStreams = someStream.connect(otherStream);
DataStream<String> result=connectedStreams.flatMap(new CoFlatMapFunction<Long, String, String>() {
@Override
public void flatMap1(Long value, Collector<String> out) throws Exception {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split("\\W+")) {
out.collect(word);
}
}
});
result.print();
env.execute();
}
public static final String[] WORDS = new String[] {
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."
};
}

flink学习笔记-数据源(DataSource)的更多相关文章
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-快速生成Flink项目
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- HIVE UDF
基本函数 SHOW FUNCTIONS; DESCRIBE FUNCTION <function_name>; 日期函数 返回值类型 名称 描述 string from_unixtime( ...
- SDL_AudioSpec(转)
转贴地址:http://www.cnblogs.com/nanguabing/archive/2012/04/12/2444084.html ============================= ...
- spring注解注入属性
- JS事件冒泡和事件捕获的详解
在学校,听老师讲解事件冒泡和事件捕获机制的时候跟听天书一样,只依稀记得IE使用的是事件冒泡,其他浏览器则是事件捕获.当时的我,把它当成IE浏览器兼容问题,所以没有深究(IE8以下版本的浏览器已基本退出 ...
- 747. Largest Number At Least Twice of Others比所有数字都大两倍的最大数
[抄题]: In a given integer array nums, there is always exactly one largest element. Find whether the l ...
- 268. Missing Number序列中遗失的数字
[抄题]: Given an array containing n distinct numbers taken from 0, 1, 2, ..., n, find the one that is ...
- 关于sleep的理解
unix是按时间片轮转调度, windows是抢占式调度 以吃蛋糕为例子,10个人吃蛋糕,如果是unix下, 假设开始时,每个人都处于就绪状态,那么操作系统调度大家排好队,按顺序吃,每个人吃1分钟, ...
- Solidity notes
1. 查询transaction历史记录 https://forum.ethereum.org/discussion/2116/in-what-ways-can-storage-history-be- ...
- nodelet的理解
1.介绍 nodelet包可以为在相同进程中的多个算法之间实现零拷贝的传输方式. 这个包也提供了实现一个nodelet所需的nodelet基类以及用于实例化nodelet的NodeletLoader类 ...
- numpy.loadtxt() 出现codecError_____ Excel 做矩阵乘法
1) 用 numpy读入csv文件是报错 UnicodeDecodeError: 'gbk' codec can't decode byte 0xbf in position 2: illegal m ...