mysql实战优化之二:limit优化(大表翻页查询时) sql优化
mysql的表test中有20105119行数据。
建立索引:data_status,place_cargo_status
场景1:
SELECT
id,
resource_id,
resource_type,
...
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',arrive_work_day,send_work_day,1,cargo_arrive_time),
load_zone_code,
cargo_send_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,send_work_day,2,cargo_arrive_time),
cargo_arrive_next_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,arrive_next_work_day,3,cargo_arrive_time),
next_zone_code,
...
FROM
test
WHERE
data_status=1 and place_cargo_status=1
LIMIT 0,10000
结果:查询时间为:7.360s
场景1:
SELECT
id,
resource_id,
...
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',arrive_work_day,send_work_day,1,cargo_arrive_time),
load_zone_code,
cargo_send_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,send_work_day,2,cargo_arrive_time),
cargo_arrive_next_batch,
F_OMCS_LINK_GET_DAY_BY_WORKDAY('2017-03-13',send_work_day,arrive_next_work_day,3,cargo_arrive_time),
...
FROM
test
WHERE
data_status=1
LIMIT 0,10000
结果:查询时间为:7.111s
场景三:
select * from test
WHERE
data_status=1 and place_cargo_status=1
LIMIT 0,10000
结果:查询时间为0.141s
场景四:
select * from test
WHERE
data_status=1
LIMIT 0,10000
查询时间为0.140s
查看执行计划:
场景四的执行计划:
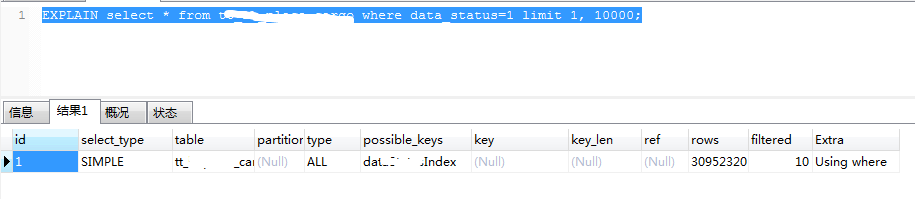
优化一:
如上type=all,是因为data_status是varchar型的,为其加单引号后,如下:

优化二:使用主键翻页,

测试结果如下:
select * from tt_lk_place_cargo where data_status='' and id between 20000000 and 20030000;
结果:使用时间0.381s

mysql实战优化之二:limit优化(大表翻页查询时) sql优化的更多相关文章
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- 如何对MySQL 对于大表(千万级)进行优化
如何对Mysql中的大型表进行优化 @(mysql 笔记) 收集信息 1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数 ...
- 1. 元信息:Meta类 2. 基于对象查询的sql优化 3. 自定义:Group_Concat() 4. ajax前后台交互
一.元信息 ''' 1. 元信息 1. Model类可以通过元信息类设置索引和排序信息 2. 元信息是在Model类中定义一个Meta子类 class Meta: # 自定义表名 db_table = ...
- SQL查询与SQL优化[姊妹篇.第四弹]
在上一篇文章中,我们一起了解了关系模型与关系运算相关的知识,接下来我们一起谈谈,面对复杂的关系数据,我们如何来优化,SQL如何玩转更优呢? 在上一篇中抛出了4个关于优化方面的问题: 1.返回表中0.0 ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
- Oracle 表三种连接方式(sql优化)
在查看sql执行计划时,我们会发现表的连接方式有多种,本文对表的连接方式进行介绍以便更好看懂执行计划和理解sql执行原理. 一.连接方式: 嵌套循环(Nested Loops (NL)) (散列)哈希 ...
- SQL夯实基础(四):子查询及sql优化案例
首先我们先明确一下sql语句的执行顺序,如下有前至后执行: (1)from (2) on (3) join (4) where (5)group by (6) avg,sum... (7 ...
- Delete 语句带有子查询的sql优化
背景: 接到开发通知,应用页面打不开,让我协助... (开发跟我说,表GV_BOOKS一直有锁,锁了有1个多小时了,问我能不能把锁释放掉,我回答他们说,这肯定是sql性能问题,表上有锁是正常现象,不是 ...
随机推荐
- Source Insight 插件
一提到外挂程序,大家肯定都不陌生,QQ就有很多个版本的去广告外挂,很多游戏也有用于扩展功能或者作弊的工具,其中很多也是以外挂的形式提供的.外挂和插件的区别在于插件通常依赖于程序的支持,如果程序不支持插 ...
- Standard 1.1.x VM与Standard VM的区别
在Eclipse或MyEclipse中要设置Installed JREs时,有三个选择: - Execution Environment Description - Standard 1.1.x VM ...
- github上十二款最著名的Android播放器开源项目
1.ijkplayer 项目地址: https://github.com/Bilibili/ijkplayer 介绍:Ijkplayer 是Bilibili发布的基于 FFplay 的轻量级 Andr ...
- python学习笔记(mysqldb下载安装及简单操作)
python支持对mysql的操作 已经安装配置成功python.mysql 之后根据各自电脑配置选择对应系统的MySQL-python 文件是EXE格式.打开下一步即可 下载地址博主分享下: htt ...
- socket编程 TCP 粘包和半包 的问题及解决办法
一般在socket处理大数据量传输的时候会产生粘包和半包问题,有的时候tcp为了提高效率会缓冲N个包后再一起发出去,这个与缓存和网络有关系. 粘包 为x.5个包 半包 为0.5个包 由于网络原因 一次 ...
- java之字符串中查找字串的常见方法
1.int indexOf(String str) :返回第一次出现的指定子字符串在此字符串中的索引. int indexOf(String str, int startIndex):从指定 ...
- idea debug调试快捷键
F9 resume programe 恢复程序 Alt+F10 show execution point 显示执行断点 F8 Step Over ...
- Sunday算法--C#版
public static int Sunday(string text, string pattern) { int i, j, m, k; i = j = 0; int tl, pl; int p ...
- 【Python】序列的方法
任何序列都可以引用其中的元素(item). 下面的内建函数(built-in function)可用于列表(表,定值表,字符串) #s为一个序列 len(s) 返回: 序列中包含元素的个数 min(s ...
- python多线程抓取代理服务器
文章转载自:https://blog.linuxeye.com/410.html 代理服务器:http://www.proxy.com.ru #coding: utf-8 import urllib2 ...