python爬虫之html解析Beautifulsoup和Xpath
Beautiifulsoup
Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。
Beautiifulsoup:python语言写的
re:C语言写的
lxml:C语言写的
速度最快的是正则,其次是lxml,最后是Beautifulsoup
安装:
pip install Beautiifulsoup4
四大对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
(1)Tag
Tag 通俗点讲就是 HTML 中的一个个标签。
from bs4 import Beautiifulsoup
html = """
print(soup.p)
# <p class="title" name="dromouse"><b>The Dormouse's story</b></p> print(type(soup.p))
# <class 'bs4.element.Tag'>
我们可以利用 soup 加标签名轻松地获取这些标签的内容,这些对象的类型是bs4.element.Tag。对于 Tag,它有两个重要的属性,是 name 和 attrs.
print(soup.name)
# [document] soup 对象本身比较特殊,它的 name 即为 [document]
print(soup.head.name)
# head 对于其他内部标签,输出的值便为标签本身的名称
print(soup.p.attrs)
# {'class': ['title'], 'name': 'dromouse'}
print(soup.p['class']) # 取出标签的属性
print(soup.p.get('class') # 取出标签的属性,找不到返回None
# ['title']
print(soup.a.text) #等于print(soup.a.get_text()) 取出标签下的文本内容
(2) NavigableString
NavigableString简单来讲就是一个可以遍历的字符串。
例如:
print(soup.p.string)
# The Dormouse's story
print(type(soup.p.string))
# <class 'bs4.element.NavigableString'>
(3)BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下
print type(soup.name)
#<type 'unicode'>
print soup.name
# [document]
print soup.attrs
#{} 空字典
(4)Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
我们找一个带注释的标签
print soup.a
print soup.a.string
print type(soup.a.string)
运行结果如下
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
Elsie
<class 'bs4.element.Comment'>
a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。
另外我们打印输出下它的类型,发现它是一个 Comment 类型,所以,我们在使用前最好做一下判断,判断代码如下
if type(soup.a.string)==bs4.element.Comment:
print soup.a.string
搜索文档
Beautiful Soup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似。
使用find_all等类似的方法可以查找想要的文档内容。
在介绍find_all方法之前,先介绍一下过滤器的类型。
字符串
最简单的过滤器是字符串。在搜索方法中传入一个字符串参数,BeautifulSoup会查找与字符串完整匹配的内容。
例如:
from bs4 import BeautifulSoup
soup = Beautiifulsoup(html,'lxml')
soup.find_all('a') #匹配所有的a标签
soup.find_all('a',attrs={'class':'tittle'}) #匹配所有class为tittle的a标签 等于soup.find_all('a',class_='tittle')
正则表达式
find_all方法可以接受正则表示式作为参数,BeautifulSoup会通过match方法来匹配内容。
#匹配以b开头的标签
for tag in soup.find_all(re.compile('^b')):
print(tag.name)
# body b
#匹配包含t的标签
for tag in soup.find_all(re.compile('t')):
print(tag.name)
# html title
列表
find_all方法也能接受列表参数,BeautifulSoup会将与列表中任一元素匹配的内容返回。
#查找a标签和b标签
for tag in soup.find_all(['a','b']):
print(tag.name)
# b a a a
方法
find_all方法也能接受列表参数,BeautifulSoup会将与列表中任一元素匹配的内容返回。
#匹配包含class属性,但是不包括id属性的标签。
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id') print([tag.name for tag in soup.find_all(has_class_but_no_id)])
# ['p','p','p']
css选择器
这就是另一种与 find_all 方法有异曲同工之妙的查找方法.
写 CSS 时,标签名不加任何修饰,类名前加.,id名前加#
在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
1.通过标签名查找
print(soup.select('title'))
#[<title>The Dormouse's story</title>]
print(soup.select('a'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print(soup.select('b'))
#[<b>The Dormouse's story</b>]
2.通过类名查找
print(soup.select('.sister'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
3.通过 id 名查找
print(soup.select('#link1'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
4.组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print(soup.select('p #link1'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
直接子标签查找,则使用 > 分隔
print(soup.select("head > title"))
#[<title>The Dormouse's story</title>]
5.属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print(soup.select('a[class="sister"]'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print(soup.select('a[href="http://example.com/elsie"]'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print(soup.select('p a[href="http://example.com/elsie"]'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
6.获取内容
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, 'lxml')
print(type(soup.select('title')))
print(soup.select('title')[0].get_text()) for title in soup.select('title'):
print(title.get_text())
总结:
通过tag标签逐层查找:
soup.select("body a")
找到某个tag标签下的直接子标签
soup.select("head > title")
通过CSS的类名查找:
soup.select(".sister")
通过tag的id查找:
soup.select("#link1")
通过是否存在某个属性来查找:
soup.select('a[href]')
通过属性的值来查找:
soup.select('a[href="http://example.com/elsie"]')
获取内容
soup.select(a #link1)[0].get_text()
XPATH
xpath也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。并且在爬虫框架scrapy中应用广泛。
安装:
pip install lxml
xpath主要语法
选取节点
| / | 从根节点选取,假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置,若以//开头,表示在全局搜索 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 匹配任何元素节点 |
例如:
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 元素。
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
补充:div.xpath('string(.)') 选取div下面的所有文本
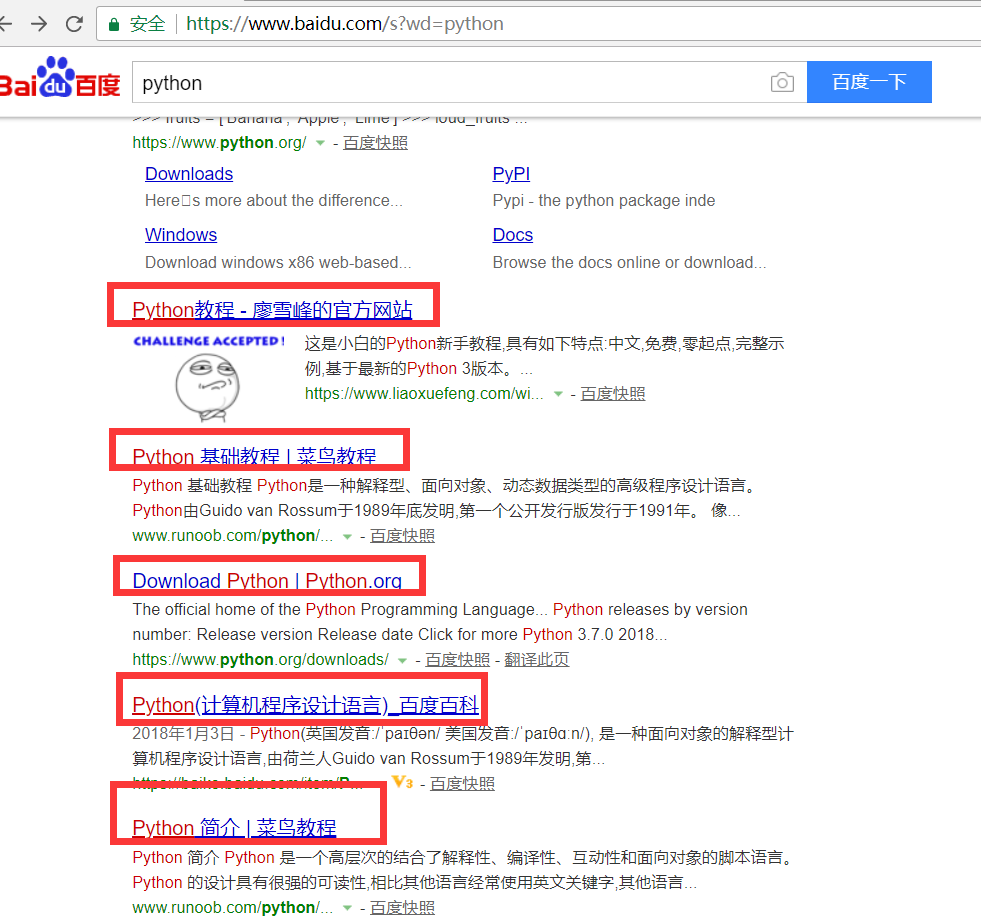
案例:在百度搜索python,提取出搜索结果中的网站的超链接和标题。如图,提取下面红框标记部分的链接和文本。
代码1:Beautifulsoup实现
import requests
from bs4 import BeautifulSoup def get_response():
'''
:return:爬取需要的数据,在本例中就是百度搜索python结果的网页源代码
'''
url = 'http://www.baidu.com/s?wd=python'
html = requests.get(url).text
return html def parse():
info = {}
soup = BeautifulSoup(get_response(),'lxml')
nodelist = soup.find_all('div',class_='result c-container ') # 分析页面源码,所有的信息保存在类名为'result c-container '的div下面
for node in nodelist:
href = node.select('h3 > a')[0].get('href') # 注意select得到的结果是个列表
title = node.select('h3 > a')[0].text # get_text() 和text 都会得到标签下所有的文本
info[title] = href
return info if __name__ == '__main__':
print(parse())
代码2:xpath实现
import requests
from lxml import etree def get_response():
url = 'http://www.baidu.com/s?wd=python'
html = requests.get(url).text
return html def parse():
info = {}
e = etree.HTML(get_response())
nodelist = e.xpath('//div[@class="result c-container "]')
for node in nodelist:
href = node.xpath('./h3/a/@href')[0]
# title = ''.join(node.xpath('./h3/a/text()')) # 用/text()得到该标签下的文本,但是会按照标签隔开以列表形式保存,尝试用join拼接
# title = node.xpath('./h3/a')[0].text # 用text也只能得到该标签的文本,不包含子标签及子标签后面的文本,适用于精确定位
title = node.xpath('./h3/a')[0].xpath('string(.)') # 用xpath('string(.)')得到该标签下的所有文本
info[title] = href
return info if __name__ == '__main__':
print(parse())
python爬虫之html解析Beautifulsoup和Xpath的更多相关文章
- python爬虫(7)——BeautifulSoup
今天介绍一个非常好用的python爬虫库--beautifulsoup4.beautifulsoup4的中文文档参考网址是:http://beautifulsoup.readthedocs.io/zh ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式. 我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参 ...
- python爬虫07 | 有了 BeautifulSoup ,妈妈再也不用担心我的正则表达式了
我们上次做了 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍 有些朋友觉得 利用正则表达式去提取信息 太特么麻烦了 有没有什么别的方式 更方便过滤我们想要的内容啊 emmmm 你还别说 还 ...
- Python爬虫十六式 - 第四式: 使用Xpath提取网页内容
Xpath:简单易用的网页内容提取工具 学习一时爽,一直学习一直爽 ! Hello,大家好,我是Connor,一个从无到有的技术小白.上一次我们说到了 requests 的使用方法.到上节课为止, ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- Python爬虫:数据解析 之 xpath
资料: W3C标准:https://www.w3.org/TR/xpath/all/ W3School:https://www.w3school.com.cn/xpath/index.asp 菜鸟教程 ...
- Python爬虫(十三)_案例:使用XPath的爬虫
本篇是使用XPath的案例,更多内容请参考:Python学习指南 案例:使用XPath的爬虫 现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子且将该帖子里每个楼层发布的图片下载 ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
随机推荐
- java中InputStream转化为byte[]数组
//org.apache.commons.io.IOUtils.toByteArray已经有实现 String filePath = "D:\\aaa.txt"; in = new ...
- webservice 使用axis2实现
Axis2 是Apache的:使用下载 :org.apache.axis2.eclipse.service.plugin_1.6.2.jar org.apache.axis2.eclipse.code ...
- Spring MVC的路径匹配
Spring MVC中的路径匹配比起标准web.xml的servlet映射要灵活得多.路径匹配的默认策略是由org.springframework.util.AntPathMatcher实现的.顾名思 ...
- PHPFastCGI进程管理器PHP
PHP-FPM是一个PHPFastCGI进程管理器,是只用于PHP的. PHP-FPM其实是PHP源代码的一个补丁,旨在将FastCGI进程管理整合进PHP包中.必须将它patch到你的PH ...
- 【BZOJ3277/3473】串/字符串 后缀数组+二分+RMQ+双指针
[BZOJ3277]串 Description 字符串是oi界常考的问题.现在给定你n个字符串,询问每个字符串有多少子串(不包括空串)是所有n个字符串中至少k个字符串的子串(注意包括本身). Inpu ...
- python中静态方法、类方法、属性方法区别
在python中,静态方法.类方法.属性方法,刚接触对于它们之间的区别确实让人疑惑. 类方法(@classmethod) 是一个函数修饰符,表是该函数是一个类方法 类方法第一个参数是cls,而实例方法 ...
- ehcarts之toolbox,工具栏
toolbox 工具栏.内置有导出图片,数据视图,动态类型切换,数据区域缩放,重置五个工具. feature各工具配置项.具体显示功能 1.saveAsImage 保存为图片. 2.restore 还 ...
- 为什么要提倡"Design Pattern"呢? 开闭原则 系统设计时,注意对扩展开放,对修改闭合。
[亲身经历] 无规矩不成方圆 设计模式 - 搜狗百科 https://baike.sogou.com/v123729.htm?fromTitle=设计模式 为什么要提倡"Design Pat ...
- <2013 07 22> 游历西欧
从本月11号开始到昨天,10天时间,和其他六位同学畅游了西欧,路经慕尼黑-巴塞罗马-尼斯-马赛-巴黎-阿姆斯特丹,最后回到慕尼黑,每个地方都待了两天,参观了主要的景点和建筑,见识了本地文化与饮食. 令 ...
- mysql 5.7.18版本 sql_mode 问题
only_full_group_by 模式的,但开启这个模式后,原先的 group by 语句就报错,然后又把它移除了. only_full_group_by ,感觉,group by 将变成和 di ...