Hadoop ->> MapReduce编程模型
对于MapReduce模型的实现,有Java等一些语言实现了接口,或者用像Hive/Pig这样的平台来操作。MapReduce由Map函数、Reduce函数和Main函数实现。第一步,源数据文件按默认文件系统块大小分割成M个数据块后传给M个Map函数,M个Map函数分布在N台机器上。Map函数接受两个参数传入,第一个参数是键值(key),第二个参数是数据值(value),其实这就是一个tuple。文件中一行就是一个tuple的元素,key就是行在文件内的偏移量(offset)。给Map的数据看上去像这样:
(0, 0067011990999991950051507004…9999999N9+00001+99999999999…)
(106, 0043011990999991950051512004…9999999N9+00221+99999999999…)
(212, 0043011990999991950051518004…9999999N9-00111+99999999999…)
(318, 0043012650999991949032412004…0500001N9+01111+99999999999…)
(424, 0043012650999991949032418004…0500001N9+00781+99999999999…)
但是这个偏移量其实对于后面对MapReduce的实现没有用。我们需要做的是Map函数按照我们希望得到的数据结构进行分组生成一个新的tuple。Map函数会生成一个新的tuple,key变成我们希望的字段的值。tuple的值就是后面需要用到的值了。Map函数做的事情就是这么简单。Map输出的数据流不会马上进入到Reduce函数,而是有一个中间处理的过程(shuffle)来对数据进行排序和整合到一块。这一步我们不需要去实现,像Java这样的MapReduce接口已经自动实现这一步。这一步的目的是为了减小结果集,降低网络IO。合并数据结果集完成后再对数据进行分割(Partition),这个过程通过Hash函数对Key生成哈希值后和N进行模(Mod)运算,N=Reduce函数的数量,目的是为了让每个Reduce函数都处理一段范围的数据。结果存储以本地文件的形式存储。然后通知JobTracker自己的任务完成了并把中间结果集文件的地址告诉它。JobTacker再告诉TaskTracker接下来去哪拿到文件然后调用Reduce函数处理。这里问题就来了,不同的文件块在不同的节点上处理,那这里是不是需要不同的节点在彼此间进行数据交换,把应该别的节点处理的数据丢给他,自己也接受别的节点给过来的需要自己处理的数据,然后再生成文件存储在本地,等待TaskTracker下一步调用Reduce函数去处理它?可以这么看,其实整个过程就是数据流,利用元组或者数组(tuple)的形式存储一对值,按照值进行数据集整理,这样看有点类似于数据库里压缩技术,就是关键字压缩。最后丢给Reduce函数的元组看上去是这样(1, [a,b,c])。Reduce函数接收到元组再把元组中List的数据值拿出来进行计算。整个过程Map函数通过一个迭代器把键值对传给Reduce函数,这样不会出现内存溢出的情况。Map和Reduce在Data node由不同的Task tracker来执行。
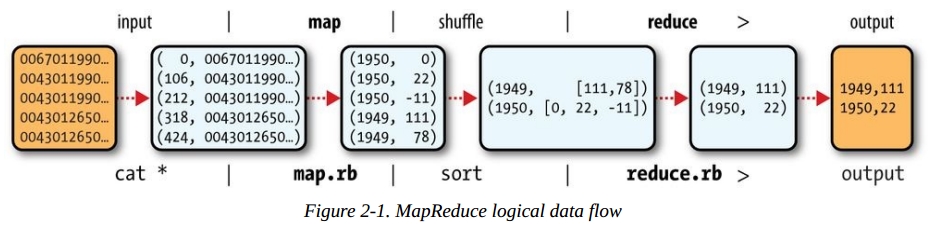
这里留下一些问题,在《Hadoop实战》一书中作者讲到Map函数输出的结果集在合并之后(也就是sort and merge这一步)可以进行数据分割(Partition),再给到Reduce函数去处理。这点倒是上面这张图没有体现出来的。
可以预先定义R个Reduce函数来接受分割后的input数据集,前一步分割的数据集的个数等于这个R。这时我想起了之前《Hadoop in action》一书讲到的可以通过多少JVM来启动多个任务来并行执行多个map函数和reduce函数。R个Reduce函数最终输出结果再合并成一个文件或者作为下一个任务管道的输入。
Hadoop ->> MapReduce编程模型的更多相关文章
- [转]Hadoop集群_WordCount运行详解--MapReduce编程模型
Hadoop集群_WordCount运行详解--MapReduce编程模型 下面这篇文章写得非常好,有利于初学mapreduce的入门 http://www.nosqldb.cn/1369099810 ...
- MapReduce编程模型及其在Hadoop上的实现
转自:https://www.zybuluo.com/frank-shaw/note/206604 MapReduce基本过程 关于MapReduce中数据流的传输过程,下图是一个经典演示: 关于上 ...
- mapreduce编程模型你知道多少?
上次新霸哥给大家介绍了一些hadoop的相关知识,发现大家对hadoop有了一定的了解,但是还有很多的朋友对mapreduce很模糊,下面新霸哥将带你共同学习mapreduce编程模型. mapred ...
- MapReduce 编程模型
一.简单介绍 1.MapReduce 应用广泛的原因之中的一个在于它的易用性.它提供了一个因高度抽象化而变得异常简单的编程模型. 2.从MapReduce 自身的命名特点能够看出,MapReduce ...
- MapReduce编程模型详解(基于Windows平台Eclipse)
本文基于Windows平台Eclipse,以使用MapReduce编程模型统计文本文件中相同单词的个数来详述了整个编程流程及需要注意的地方.不当之处还请留言指出. 前期准备 hadoop集群的搭建 编 ...
- MapReduce编程模型简介和总结
MapReduce应用广泛的原因之一就是其易用性,提供了一个高度抽象化而变得非常简单的编程模型,它是在总结大量应用的共同特点的基础上抽象出来的分布式计算框架,在其编程模型中,任务可以被分解成相互独立的 ...
- MapReduce 编程模型概述
MapReduce 编程模型给出了其分布式编程方法,共分 5 个步骤:1) 迭代(iteration).遍历输入数据, 并将之解析成 key/value 对.2) 将输入 key/value 对映射( ...
- 批处理引擎MapReduce编程模型
批处理引擎MapReduce编程模型 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MapReduce是一个经典的分布式批处理计算引擎,被广泛应用于搜索引擎索引构建,大规模数据处理 ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
随机推荐
- UVA - 11795 状压DP
#include<iostream> #include<algorithm> #include<cstdio> #include<cstring> #i ...
- 执行AJAX返回HTML片段中的JavaScript脚本
如果AJAX加载的数据是一个HTML片段,而且这个HTML片段还包含脚本<script>块,那么在你把这数据xmlHttp.responseText用innerHTML方法插入到当前文档一 ...
- 深入剖析PHP输入流 php://input
另附一个一个连接: http://www.nowamagic.net/academy/detail/12220520 ///////////////////////////////////////// ...
- mac 系统配置(一)
1.终端颜色配置 文件 .bash_profile下添加环境变量如下: export CLICOLOR=1 export LSCOLORS=gxfxaxdxcxegedabagacad 环境变量生效: ...
- jQuery随笔-自定义属性获取+tooltip
1.Jquery自定义属性获取 1) 通过自定义属性值获取document console.log($('[data-id='+item_id+']',listWrap)); $('[data-id= ...
- [V1-Team] WEDO创意论坛技术规格说明书
WEDO 创意论坛技术规格说明书 0x0 文档版本 版本号 说明 v1.0 初步确定技术路线 附Github仓库:WEDO 0x1 技术说明 1. 前端框架 在主流的前端框架中,我们调研了Vue. ...
- 常用维护SQL-数据清理
truncate某个库的表数据 show full processlist; select concat('truncate table ',table_schema,'.',table_name,' ...
- 一个新时代的UI设计师需要具备这些技能
如今互联网行业发展如日中天,设计师本就是稀缺人才.再加上未来也将迎接人工智能时代,未来的设计师不只像现在只是做一些网页.APP界面,还会出现更多的UI设计衍生职业.如下列举的几大类: 一.初级阶段 1 ...
- ZABBIX 监控基本报警故障
CPU触发器: 1)Processor load is too high on {HOST.NAME} {HOST.NAME}上处理器负载太高 触发器表达式:{Zabbix server:system ...
- white-space中 pre pre-line pre-wrap的区别
css3为white-space新增了2个非常高冷的值:pre-line与pre-wrap. 现在我们来看一下它们与pre之间的区别呢? pre:会保留空格,但我想它与pre-line/pre-wra ...