Hadoop(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程

1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等
2.NameNode返回是否可以上传,如果是的话,建立连接通道
3.客户端通过FSDataOutputStream模块请求上传block,NameNode根据网络拓扑距离计算返回的节点,dn1,dn2,dn3
4.客户端与dn1建立连接通道,dn1收到请求后会向dn2发起连接请求,dn2收到请求后会向dn3发起请求.请求通道全部打通后,会从后逐次向前应答,最后应答到客户端,通道建立成功
5.客户端开始上传block,block以packet为单位进行传输,大小为64k,dn1接收到packet后,将packet放入buffer缓冲中,一边往本地磁盘写,一边发送给dn2,dn2接收到后,以同样的方式进行处理和传输给dn3,dn3也进行同样的处理
6.等到block发送完毕后,本次传输结束
2.HDFS的读数据流程
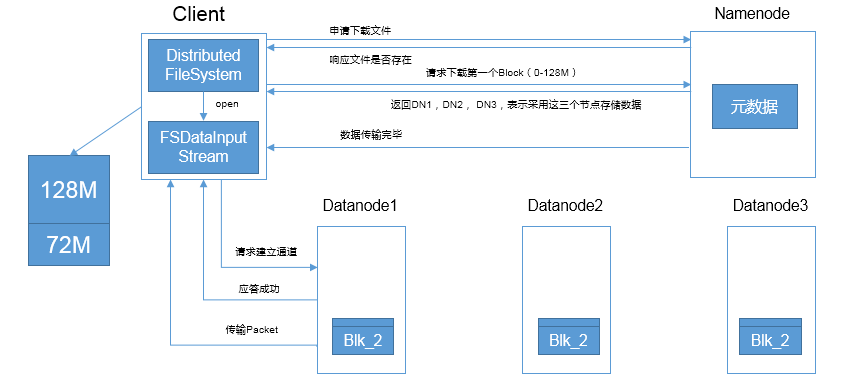
1. 客户端向NameNode申请文件下载,NameNode检查请求的合法性.如果请求合法,返回可以下载的相应,建立连接通道
2. 客户端请求下载文件,NameNode查询元数据,返回DataNode节点,DataNode节点以拓扑距离排序
3. 客户端请求连接第一个DataNode,应答成功后,DataNode开始以Packet传输数据.
4. 客户端接收Packet,边接收边写入磁盘.
5. 文件传输完成,关闭连接.
3.机架感知

通常情况下,如果有三份备份(replication)的话,HDFS的策略是第一个replication在客户端所处的节点上,如果客户端在集群外,从拓扑网络的距离近的节点上随机选一个,第二个replication和第一个replication是同一机架上随机的节点.第三个replication是不同机架上随机的节点
Hadoop(8)-HDFS的读写数据流程以及机架感知的更多相关文章
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- HDFS 读写数据流程
一.上传数据 二.下载数据 三.读写时的节点位置选择 1.网络节点距离(机架感知) 下图中: client 到 DN1 的距离为 4 client 到 NN 的距离为 3 DN1 到 DN2 的距离为 ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- HDFS 读/写数据流程
1. HDFS 写数据流程 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件, NameNode 检查目标文件是否已存在,父目录是否存在: NameNo ...
- HDFS数据流——写数据流程
剖析HDFS文件写入 假设文件ss.avi共200m,其写入HDFS指定路径/user/atguigu/ss.avi流程如下: 1)客户端向namenode请求上传文件到指定路径,namenode通过 ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- Hadoop_08_客户端向HDFS读写(上传)数据流程
1.HDFS的工作机制: HDFS集群分为两大角色:NameNode.DataNode (Secondary Namenode) NameNode负责管理整个文件系统的元数据 DataNode 负责管 ...
随机推荐
- SELECT s.* FROM person p INNER JOIN shirt s ON s.owner = p.id WHERE p.name LIKE 'Lilliana%' AND s.color <> 'white';
SELECT s.* FROM person p INNER JOIN shirt sON s.owner = p.idWHERE p.name LIKE 'Lilliana%'AND s.color ...
- 深入浅出 关于SQL Server中的死锁问题
深入浅出 关于SQL Server中的死锁问题 博客2013-02-12 13:44 分享到:我要吐槽 死锁的本质是一种僵持状态,是多个主体对于资源的争用而导致的.理解死锁首先需要对死锁所涉及的相 ...
- numpy cheat sheet
numpy cheat sheet https://files.cnblogs.com/files/lion-zheng/Numpy_Python_Cheat_Sheet.pdf
- 数据结构学习-数组A[m+n]中依次存放两个线性表(a1,a2···am),(b1,b2···bn),将两个顺序表位置互换
将数组中的两个顺序表位置互换,即将(b1,b2···bn)放到(a1,a2···am)前边. 解法一: 将数组中的全部元素(a1,a2,···am,b1,b2,···bn)原地逆置为(bn,bn-1, ...
- HTTP 状态码 301 302
301 Moved Permanently被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一.如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为 ...
- 2014-2015 ACM-ICPC East Central North America Regional Contest (ECNA 2014) A、Continued Fractions 【模拟连分数】
任意门:http://codeforces.com/gym/100641/attachments Con + tin/(ued + Frac/tions) Time Limit: 3000/1000 ...
- 【转】iOS的APP资源,开源的哦
完整项目 文章转自 “标哥的技术博客” IOS-Swift2.0 高仿半糖App 这个开源项目为半糖,官网➡,类似于美丽说,一款电商App,使用语言:Swift2.0,开发工具: Xcode 7.1 ...
- Android学习笔记_54_自定义 Widget (Toast)
1.Toast控件: 通过查看源代码,发现Toast里面实现的原理是通过服务Context.LAYOUT_INFLATER_SERVICE获取一个LayoutInflater布局管理器,从而获取一个V ...
- HDU 1426 Sudoku Killer(dfs 解数独)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1426 Sudoku Killer Time Limit: 2000/1000 MS (Java/Oth ...
- jquery 跨域获取网页数据
<script language="javascript" src="http://cbsahhs.blog.163.com/jquery.min.js" ...