ELK 分布式日志实战
一. ELK 分布式日志实战介绍
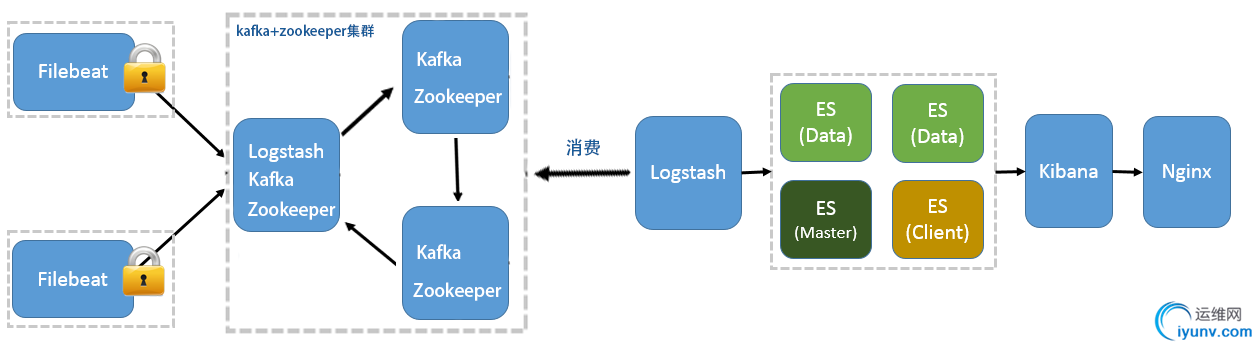
此实战方案以 Elk 5.5.2 版本为准,分布式日志将以下图分布进行安装部署以及配置。
当Elk需监控应用日志时,需在应用部署所在的服务器中,安装Filebeat日志采集工具,日志采集工具通过配置,采集本地日志文件,将日志消息传输到Kafka集群,
我们可部署日志中间服务器,安装Logstash日志采集工具,Logstash直接消费Kafka的日志消息,并将日志数据推送到Elasticsearch中,并且通过Kibana对日志数据进行展示。
二. Elasticsearch配置
1.Elasticsearch、Kibana安装配置,可见本人另一篇博文
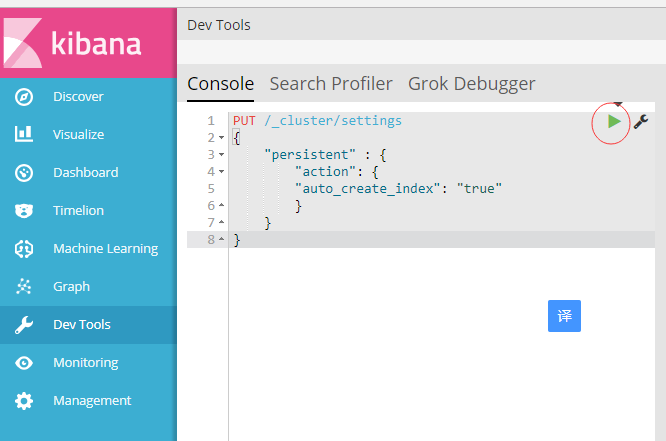
https://www.cnblogs.com/woodylau/p/9474848.html 2.创建logstash日志前,需先设置自动创建索引(根据第一步Elasticsearch、Kibana安装成功后,点击Kibana Devtools菜单项,输入下文代码执行)
PUT /_cluster/settings
{
"persistent" : {
"action": {
"auto_create_index": "true"
}
}
}
三. Filebeat 插件安装以及配置
1.下载Filebeat插件 5.5.2 版本
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.5.2-linux-x86_64.tar.gz
2.解压filebeat-5.5.2-linux-x86_64.tar.gz文件至/tools/elk/目录下
tar -zxvf filebeat-5.5.-linux-x86_64.tar.gz -C /tools/elk/
cd /tools/elk/
mv filebeat-5.5.-linux-x86_64 filebeat-5.5.
3.配置filebeat.yml文件cd /tools/elk/filebeat-5.5.
vi filebeat.yml
4.filebeat.yml 用以下文本内容覆盖之前文本filebeat.prospectors:
- input_type: log
paths:
# 应用 info日志
- /data/applog/app.info.log
encoding: utf-8
document_type: app-info
#定义额外字段,方便logstash创建不同索引时所设
fields:
type: app-info
#logstash读取额外字段,必须设为true
fields_under_root: true
scan_frequency: 10s
harvester_buffer_size: 16384
max_bytes: 10485760
tail_files: true - input_type: log
paths:
#应用错误日志
- /data/applog/app.error.log
encoding: utf-8
document_type: app-error
fields:
type: app-error
fields_under_root: true
scan_frequency: 10s
harvester_buffer_size: 16384
max_bytes: 10485760
tail_files: true # filebeat读取日志数据录入kafka集群
output.kafka:
enabled: true
hosts: ["192.168.20.21:9092","192.168.20.22:9092","192.168.20.23:9092"]
topic: elk-%{[type]}
worker: 2
max_retries: 3
bulk_max_size: 2048
timeout: 30s
broker_timeout: 10s
channel_buffer_size: 256
keep_alive: 60
compression: gzip
max_message_bytes: 1000000
required_acks: 1
client_id: beats
partition.hash:
reachable_only: true
logging.to_files: true
5.启动 filebeat 日志采集工具
cd /tools/elk/filebeat-5.5.
#后台启动 filebeat
nohup ./filebeat -c ./filebeat-kafka.yml &
四. Logstash 安装配置
1. 下载Logstash 5.5.2 版本wget https://artifacts.elastic.co/downloads/logstash/logstash-5.5.2.tar.gz
2.解压logstash-5.5.2.tar.gz文件至/tools/elk/目录下tar -zxvf logstash-5.5..tar.gz -C /tools/elk/
cd /tools/elk/
mv filebeat-5.5.-linux-x86_64 filebeat-5.5.
3.安装x-pack监控插件(可选插件,如若elasticsearch安装此插件,则logstash也必须安装)
./logstash-plugin install x-pack
4.编辑logstash_kafka.conf 文件
cd /tools/elk/logstash-5.5./config
vi logstash_kafka.conf
5.配置 logstash_kafka.conf
input {
kafka {
codec => "json"
topics_pattern => "elk-.*"
bootstrap_servers => "192.168.20.21:9092,192.168.20.22:9092,192.168.20.23:9092"
auto_offset_reset => "latest"
group_id => "logstash-g1"
}
}
filter {
#当非业务字段时,无traceId则移除
if ([message] =~ "traceId=null") {
drop {}
}
}
output {
elasticsearch {
#Logstash输出到elasticsearch
hosts => ["192.168.20.21:9200","192.168.20.22:9200","192.168.20.23:9200"]
# type为filebeat额外字段值
index => "logstash-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
flush_size => 20000
idle_flush_time => 10
sniffing => true
template_overwrite => false
# 当elasticsearch安装了x-pack插件,则需配置用户名密码
user => "elastic"
password => "elastic"
}
}
6.启动 logstash 日志采集工具
1 cd /tools/elk/logstash-5.5.2
#后台启动 logstash
2 nohup /tools/elk/logstash-5.5.2/bin/logstash -f /tools/elk/logstash-5.5.2/config/logstash_kafka.conf &
五. 最终查看ELK安装配置结果
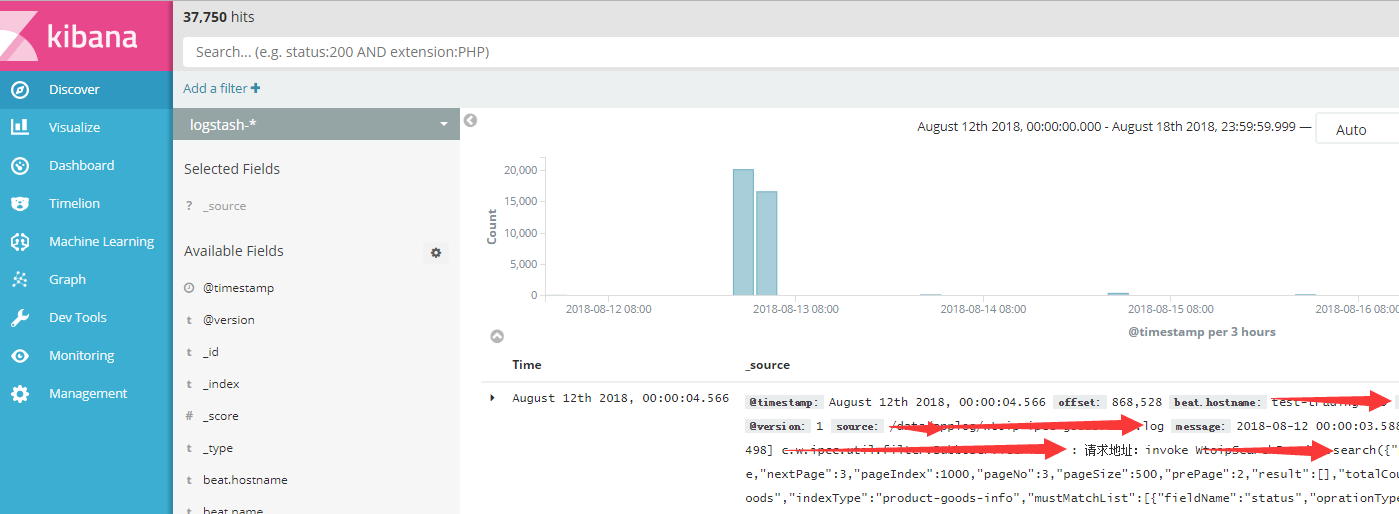
1.访问 Kibana, http://localhost:5601,点击 Discover菜单,配置索引表达式,输入 logstash-*,点击下图蓝色按钮,则创建查看Logstash采集的应用日志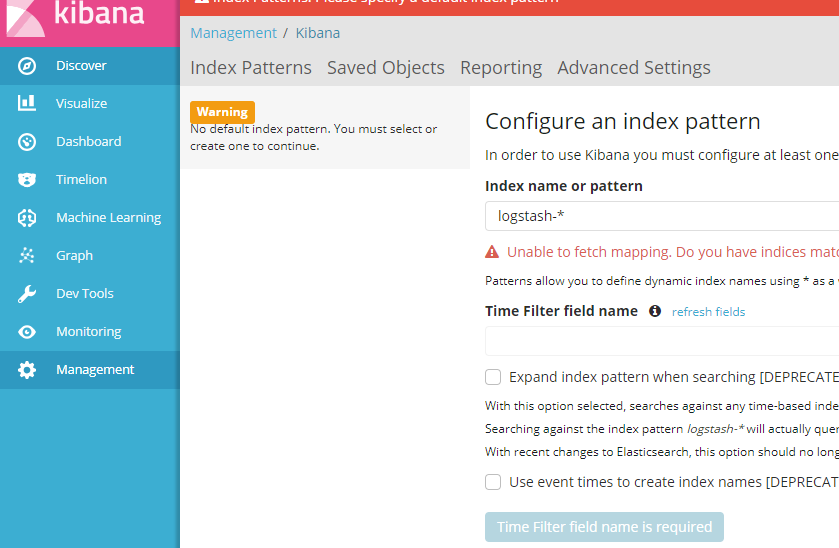
ELK 分布式日志实战的更多相关文章
- ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK全框架 SpringBootSecurity1.传统系统日志收集的问题2.Logstash操作工作原理3.分布式日志收集ELK原理4.Elasticsearch+Log ...
- .NetCore快速搭建ELK分布式日志中心
懒人必备:.NetCore快速搭建ELK分布式日志中心 该篇内容由个人博客点击跳转同步更新!转载请注明出处! 前言 ELK是什么 它是一个分布式日志解决方案,是Logstash.Elastaics ...
- 懒人必备:.NetCore快速搭建ELK分布式日志中心
该篇内容由个人博客点击跳转同步更新!转载请注明出处! 前言 ELK是什么 它是一个分布式日志解决方案,是Logstash.Elastaicsearch.Kibana的缩写,可用于从不同的服务中收集日志 ...
- ELK分布式日志+NLog在.NetCore中的应用
一.ELK简介 ELK是Elasticsearch.Logstash和Kibana首字母的缩写.这三者均是开源软件,这三套开源工具组合起来形成了一套强大的集中式日志管理平台 Elasticsearch ...
- 传统ELK分布式日志收集的缺点?
传统ELK图示: 单纯使用ElK实现分布式日志收集缺点? 1.logstash太多了,扩展不好. 如上图这种形式就是一个 tomcat 对应一个 logstash,新增一个节点就得同样的拥有 logs ...
- 微服务—ELK分布式日志框架
在微服务架构下,微服务被拆分成多个微小的服务,每个微小的服务都部署在不同的服务器实例上,当我们定位问题,检索日志的时候需要依次登录每台服务器进行检索. 这样是不是感觉很繁琐和效率低下.所以我们还需要一 ...
- SpringBoot+kafka+ELK分布式日志收集
一.背景 随着业务复杂度的提升以及微服务的兴起,传统单一项目会被按照业务规则进行垂直拆分,另外为了防止单点故障我们也会将重要的服务模块进行集群部署,通过负载均衡进行服务的调用.那么随着节点的增多,各个 ...
- 微服务系列之分布式日志 ELK
1.ELK简介 ELK是ElasticSearch+LogStash+Kibana的缩写,是现代微服务架构流行的分布式日志解决方案,旨在大规模服务的日志集中管理查看,极大的为微服务开发人员提供了排查生 ...
- ELK +Nlog 分布式日志系统的搭建 For Windows
前言 我们为啥需要全文搜索 首先,我们来列举一下关系型数据库中的几种模糊查询 MySql : 一般情况下LIKE 模糊查询 SELECT * FROM `LhzxUsers` WHERE UserN ...
随机推荐
- 简单的PHP算法题
简单的PHP算法题 目录 1.只根据n值打印n个0 2.根据n值打印一行 0101010101010101010101…… 3.根据n值实现1 00 111 0000 11111…… 4.根据n值实现 ...
- SAP+DB2 糟糕的报表查询『ZCOR0015』 优化全程记录
ZCOR0015的优化全过程记录文档 2015年3月,今天无意翻到这篇写于2010年7月的文档,回想那时的工作,毕业3年初出茅庐的我面对接触不多的SAP+DB2竟敢操刀动斧,自信满满. 虽然这过程一路 ...
- RPMForge介绍及安装
网站RPMForge介绍,安装 http://wiki.centos.org/AdditionalResources/Repositories/RPMForge#head-f0c3ecee3dbb40 ...
- n对mod求模整除时转化成mod的数学式
n对mod求模,它的值在0到mod-1之间,如果要求模整除的时候转化成mod可以用下面的式子: n = (n - 1 % mod + mod) % mod +1 这里先减一,模上mod再加一,这样如果 ...
- Android数字签名解析(一)
一.数字签名概述 所谓"数字签名"就是通过某种password运算生成一系列符号及代码组成电子password进行签名,来取代书写签名或印章. 数字签名有两种功效:一是能确定消息 ...
- centos安装nodejs二进制包
1.下载nodejs的二进制包 wget https://nodejs.org/dist/v6.3.1/node-v6.3.1-linux-x64.tar.xz 2.解压下载的安装包 tar xf n ...
- 1..net转java背景介绍
注册博客2年了.从注册就开始接触.net.以前也有想过转java.只是没想过会这么快. .net语法这么优美好用.可惜了生态环境. .net还没有学成大神.就要离开了. 公司有个项目要用java.在加 ...
- 第13章 GPIO输入—按键检测
本章参考资料:<STM32F76xxx参考手册>.库帮助文档<STM32F779xx_User_Manual.chm>. 按键检测使用到GPIO外设的基本输入功能,本章中不再赘 ...
- ffmpeg视频和声音
推送视频和声音 ffmpeg -f dshow -i video="screen-capture-recorder" -f dshow -i audio="内装麦克风 ( ...
- mysql数据去重复distinct、group by
使用distinct 和group by都可以实现数据去重. select distinct 字段 group by 一般放在where条件后