爬取图片过程遇到的ValueError: Missing scheme in request url: h 报错与解决方法
一 、scrapy整体框架
1.1 scrapy框架图
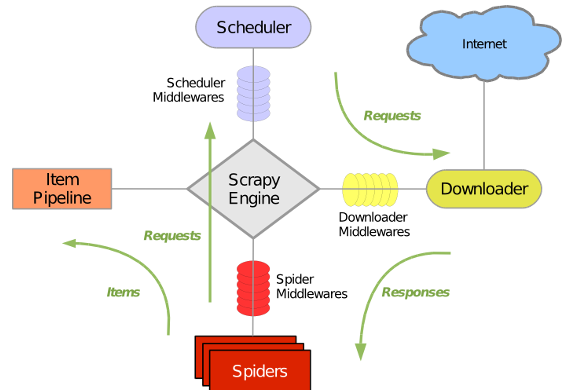
1.2 scrapy框架各结构解析
item:保存抓取的内容
spider:定义抓取内容的规则,也是我们主要编辑的文件
pipelines:管道作用,用来定义如何过滤、存储等功能(比如导出到csv或者mysql等功能)
settings:配置例如ITEM_PIPELINES 、图片存储位置等等功能
middlewares:下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response
1.3 数据流过程
从start_urls 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
二、 爬取图片过程
2.1 整体介绍
2.1.1 环境
Anocondas+python3.6
2.1.2 创建工程
1、创建hupu这个工程
E:\pgtool>scrapy startproject hupu
2、创建相应的spiders
E:\pgtool>cd hupu##必须是进入到创建的项目中去建spiders
E:\pgtool\hupu>scrapy genspider hp hupu.com ##hp=>生成hp.py ,爬虫名称为hp.py,允许访问的域名为hupu.com
通过爬取http://photo.hupu.com/nba/p35923-1.html网页中一个系列的图片
2.2 配置各组件
2.2.1 item.py
import scrapy class HupuItem(scrapy.Item):
# define the fields for your item here like:
hupu_pic = scrapy.Field()
# images = scrapy.Field()
image_paths = scrapy.Field()
2.2.2 settings.py
BOT_NAME = 'hupu' SPIDER_MODULES = ['hupu.spiders']
NEWSPIDER_MODULE = 'hupu.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'hupu.pipelines.HupuImgDownloadPipeline': 300,
}
IMAGES_URLS_FIELD = "hupu_pic" # 对应item里面设定的字段,取到图片的url
#IMAGES_RESULT_FIELD = "image_path"
IMAGES_STORE = 'E:/hupu'
2.2.3 hp.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from urllib.parse import urljoin
from hupu.items import HupuItem
class HpSpider(scrapy.Spider):
name = 'hp'
allowed_domains = ['hupu.com']
start_urls = ['http://photo.hupu.com/nba/p35923-1.html'] def parse(self, response):
item=HupuItem()
url=response.xpath('//div[@id="picccc"]/img[@id="bigpicpic"]/@src').extract() reurl="http:"+url[0]
print ('links is :--','\n',reurl)
list1=[]
list1.append(reurl)
item['hupu_pic']=list1
yield item
ifnext=response.xpath('//span[@class="nomp"]/a[2]/text()').extract()[0]
if "下一张" in ifnext:
next_url=response.xpath('//span[@class="nomp"]/a[2]/@href').extract()[0]
yield Request(('http://photo.hupu.com/nba/'+next_url),callback=self.parse)
2.2.4 pipelines.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class HupuPipeline(object):
def process_item(self, item, spider):
return item
class HupuImgDownloadPipeline(ImagesPipeline): def get_media_requests(self, item, info):
for image_url in item['hupu_pic']:
yield Request(image_url)
三、 爬虫执行与结果
3.1 执行过程
进入到工程路径下 scrapy crawl hp
(base) E:\pgtool\Files\hupu>scrapy crawl hp
3.2 获得结果
四、遇到的问题与分析解决
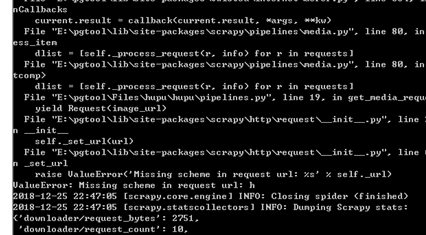
4.1 问题出现
最开始遇到ValueError: Missing scheme in request url: h 这种报错,如下图
4.2 问题解析
如果单纯获取文本,那么只需start_urls是一个list;而如果获取图片,则必须start_urls与item中存储图片路径字段这两者必须都是 list。
4.3 解决方案
未修改前的spiders:
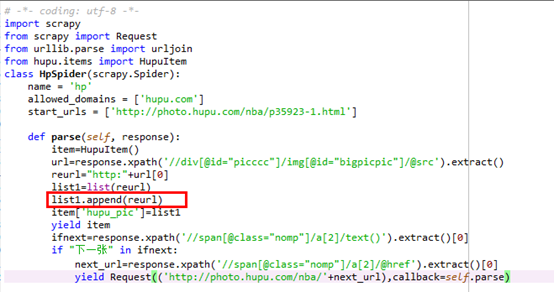
修改后spiders

五、总结
scrapy框架简单容易理解,而且支持异步多线程,是一个比较上手的爬虫框架。本次爬虫犯了一个低级错误,在于直接将图片链接转换为list而不经意间将链接拆分为一个一个的元素,如下示例:
str1='baidu.com'
list1=list(str1)
list1的结果实际为['b','a','i','d','u','.','c','o','m'],这也就是为什么一直报错Missing scheme in request url: h(翻译为:请求URL中的丢失整体链接:在h开始的位置)所以需要我们将整个链接放在只有一个元素的list中,使用修改后list.append()将一个链接完整的放置在list[0]中。
有问题的小伙伴们可以留言讨论交流,转载请注明出处,谢谢。
爬取图片过程遇到的ValueError: Missing scheme in request url: h 报错与解决方法的更多相关文章
- 运行scrapy保存图片,报错ValueError: Missing scheme in request url: h
查阅相关资料,了解到使用ImagesPipeline传入的url地址必须是一个list,而我写的是一个字符串,所以报错,所以需要修改一下传入的url格式就行了 def parse_detail(sel ...
- 持续更新scrapy的错误,ValueError: Missing scheme in request url:
只需要将 for href in response.xpath('XX').extract(): yield Request(hrefs) 修改为下面,就可以显示出来 for href in resp ...
- scrapy 错误:Missing scheme in request url: %s' % self._url
先说报错原因:使用了和start_urls同名的参数 我通过scral crawl projename -a start_urls=http:example.com来传start_urls,然后想在项 ...
- kubernetes安装过程报错及解决方法
1.your configuration file uses an old API spec: "kubeadm.k8s.io/v1alpha2". 执行kubeadm init ...
- adb+tcpdump手机抓包过程出现的报错及解决方法
tcpdump下载:https://www.androidtcpdump.com/android-tcpdump/downloads 1.夜神模拟器连接不上adb D:1手机木马取证\android- ...
- The address where a.out.debug has been loaded is missing以及No symbol "*" in current context原因与解决方法
最近,在debug core的时候,发现p 变量的时候提示“No symbol "*" in current context”,我们的代码使用-g编译的,经查有可能是下列几个原因或 ...
- PHPmailer关于Extension missing: openssl报错的解决
最近在写一个网页的时候,需要用到PHPmailer来发送邮件,按照官网上给出的demo写出一个例子,却报错Extension missing: openssl 最后发现需要修改php.ini中的配置: ...
- missing 1 required positional argument: 'on_delete'报错解决方案
最近在使用Python的Django框架开发web站点,通过models.py文件建表后,执行数据库迁移(命令行:mange.py makemigrations)时报错,下面是查看官方文档后找到的解决 ...
- jupyter notebook中出现ValueError: signal only works in main thread 报错 即 长时间in[*] 解决办法
我在jupyter notebook中新建了一个基于py3.6的kernel用来进行tensorflow学习 但是在jupyter notebook中建立该kernel时,右上角总是显示 服务正在启动 ...
随机推荐
- android:TableLayout表格布局详解
http://blog.csdn.net/justoneroad/article/details/6835915 这篇博文包括的内容:1.TableLayout简介2.TableLayout行列数的确 ...
- Tomcat 启动速度优化
创建一个web项目 选择发布到 汤姆猫 的下面 deploy path: 表示发布到的文件名称 把项目添加到 tomcat 里,运行,我们可以在 tomcat里找到我们发布的项目: 现在启动时间: 现 ...
- Linux 下的多线程编程(1)
#include<stdio.h> #include<pthread.h> #include<string.h> #include<sys/time.h> ...
- 配置两台Azure服务器,一台加入另一台的ad域加入不进去的问题
AD服务器 10.0.0.4 数据库服务器 10.0.0.5 将数据库服务器加入到AD域中,需要将Azure的DNS改成10.0.0.4 Copy一下
- Oracle 反向索引(反转建索引) 理解
一 反向索引 1.1 反向索引的定义 反向索引作为B-tree索引的一个分支,主要是在创建索引时,针对索引列的索引键值进行字节反转,进而实现分散存放到不同叶子节点块的目的. 1.2 反向索引针对的问题 ...
- 嵌入式:UCOSIII的使用(17.01.24补充)
0.一些移植.系统相关 OS_CFG_APP.H /* --------------------- MISCELLANEOUS ------------------ */ #define OS_CFG ...
- iOS Xcode 小技巧,提升理解查询能力,Command + 点击鼠标右键 Jump to Definition等
前言: 介绍下Xcode 小技巧,以及一下快捷键,让你调试程序更加出类拔萃,安排! Command + 点击鼠标右键 Jump to Definition,可能你平时也在用,但是你明白全部的用法吗,试 ...
- 技巧:Vimdiff 使用
技巧:Vimdiff 使用 各种 IDE 大行其道的同时,传统的命令行工具以其短小精悍,随手可得的特点仍有很大的生存空间,这篇短文介绍了一个文本比较和合并的小工具:vimdiff.希望能对在 Unix ...
- [NOI2002]荒岛野人(exgcd,枚举)
题目描述 克里特岛以野人群居而著称.岛上有排列成环行的M个山洞.这些山洞顺时针编号为1,2,…,M.岛上住着N个野人,一开始依次住在山洞C1,C2,…,CN中,以后每年,第i个野人会沿顺时针向前走Pi ...
- poj_1306_Combinations
Computing the exact number of ways that N things can be taken M at a time can be a great challenge w ...