ActiveMQ+Zookeeper集群配置文档
Zookeeper + ActiveMQ 集群整合配置文档
一:使用ZooKeeper实现的MasterSlave实现方式
是对ActiveMQ进行高可用的一种有效的解决方案, 高可用的原
理:使用ZooKeeper(集群)注册所有的ActiveMQ
Broker。只有其中的一个Broker可以对外提供服务( 也就是Master节点) ,其
他的Broker处于待机状态,被视为Slave。如果Master因故障而不能提供服务,
则利用ZooKeeper的内部选举机制会从Slave中选举出一个Broker充当Master节
点,继续对外提供服务。
官网文档如下:
http://activemq.apache.org/replicated-leveldb-store.html
二:部署方案, ActiveMQ集群环境准备:
( 1) 首先我们下载apache-activemq-5.11.1-
bin.tar.gz,到我们的一台主节点上去,然后我们在( 192.168.1.111一个节点
上实现集群即可)
( 2) Zookeeper方案
| 主机IP | 消息端口 | 通信端口 | 节点目录/usr/local/下 |
| 192.168.1.111 | 2181 | 2888:3888 | zookeeper |
| 192.168.1.112 | 2181 | 2888:3888 | zookeeper |
| 192.168.1.113 | 2181 | 2888:3888 | zookeeper |
( 3) ActiveMQ方案
| 主机IP | 集群通信端口 | 消息端口 | 控制台端口 | 节点目录/usr/local/下 |
| 192.168.1.111 | 62621 | 51511 | 8161 | activemq-cluster/node1/ |
| 192.168.1.111 | 62622 | 51512 | 8162 | activemq-cluster/node2/ |
| 192.168.1.111 | 62623 | 51513 | 8163 | activemq-cluster/node3/ |
1:首先搭建zookeeper环境
在192.168.1.111节点下software下,解压zookeeper-3.4.5.tar.gz文件,然后改名,操作如下:(在三台机器上都进行这样的配置)
命令: mv zookeeper-3.4.5 zookeeper
配置环境变量:vim /etc/profile
添加:export ZOOKEEPER_HOME=/usr/local/zookeeper,并添加PATH
使环境变量生效:source /etc/profile
然后:cd zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
找到datadir修改为:/usr/local/zookeeper/data
在最下面添加:server.0=192.168.1.111:2888:3888
server.1=192.168.1.112:2888:3888
server.2=192.168.1.113:2888:3888
建立zookeeper/data文件夹,并cd进入
执行vim myid
第一行添加0即可
在112中添加1,113中添加2
搭建完成
三台机器上运行:zkServer.sh start
任意一台运行:zkCli.sh可以连接上客户端
2:继续搭建activemq环境
( 1) 在192.168.1.111节点下,创建/usr/local/activemq-cluster文件夹,解压apache-activemq-5.11.1-
bin.tar.gz文件,然后对解压好的文件改名,操作如下:
1 命令: mkdir /usr/local/activemq-cluster
2 命令: cd software/
3 命令: tar -zxvf apache-activemq-5.11.1-bin.tar.gz -C
/usr/local/activemq-cluster/
4 命令: cd /usr/local/activemq-cluster/
5 命令: mv apache-activemq-5.11.1/ node1
如此操作,再次反复解压apache-activemq-5.11.1-
bin.tar.gz文件到/usr/local/activemqcluster/下,建立node2和node3文件夹,如下:
( 2) 那我们现在已经解压好了三个mq节点也就是node1、 node2、 node3,下面
我们要做的事情就是更改每个节点不同的配置和端口(由于是在一台机器上实
现集群)。
1 修改控制台端口(默认为8161) ,在mq安装路径下的conf/jetty.xml进
行修改即可。(三个节点都要修改,并且端口都不同)
1命令: cd /usr/local/activemq-cluster/node1/conf/
2命令: vim /usr/local/activemq-cluster/node1/conf/jetty.xml

三个节点都需要修改为8161、8162、8163!!!
2 集群配置文件修改:我们在mq安装路径下的conf/activemq.xml进行修
改其中的持久化适配器,修改其中的bind、 zkAddress、 hostname、 zkPath。
然后也需要修改mq的brokerName,并且每个节点名称都必须相同。
命令: vim /usr/local/activemq-cluster/node1/conf/activemq.xml
第一处修改: brokerName=”activemq-cluster”(三个节点都需要修改)

第二处修改:先注释掉适配器中的kahadb
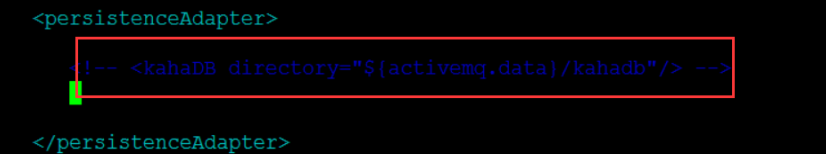
第三处修改:添加新的leveldb配置如下(三个节点都需要修改):
Node1:
<persistenceAdapter>
<!--kahaDB directory="${activemq.data}/kahadb"/ -->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62621"
zkAddress="192.168.1.111:2181,192.168.1.112:2181,192.168.1.113:2181"
hostname="bhz111"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
Node2:
<persistenceAdapter>
<!--kahaDB directory="${activemq.data}/kahadb"/ -->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62622"
zkAddress="192.168.1.111:2181,192.168.1.112:2181,192.168.1.113:2181"
hostname="bhz111"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
Node3:
<persistenceAdapter>
<!--kahaDB directory="${activemq.data}/kahadb"/ -->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62623"
zkAddress="192.168.1.111:2181,192.168.1.112:2181,192.168.1.113:2181"
hostname="bhz111"
zkPath="/activemq/leveldb-stores"
/>
</persistenceAdapter>
第四处修改:(修改通信的端口,避免冲突)
命令: vim /usr/local/activemq-cluster/node1/conf/activemq.xml
修改这个文件的通信端口号, 三个节点都需要修改( 51511,51512,51513)
Ok,到此为止,我们的activemq集群环境已经搭建完毕!
三:测试启动activemq集群:
第一步:启动zookeeper集群,命令: zkServer.sh start
第二步:启动mq集群:顺序启动mq:命令如下:
/usr/local/activemq-cluster/node1/bin/activemq start(关闭stop)
/usr/local/activemq-cluster/node2/bin/activemq start(关闭stop)
/usr/local/activemq-cluster/node3/bin/activemq start(关闭stop)
第三步:查看日志信息:
tail -f /usr/local/activemq-cluster/node1/data/activemq.log
tail -f /usr/local/activemq-cluster/node2/data/activemq.log
tail -f /usr/local/activemq-cluster/node3/data/activemq.log
如果不报错,我们的集群启动成功,可以使用控制台查看!
第四步:集群的brokerUrl配置进行修改即可:
failover:(tcp://192.168.1.111:51511,tcp://192.168.1.111:51512,tcp://1
92.168.1.111:51513)?Randomize=false
/usr/local/activemq-cluster/node1/bin/activemq stop
/usr/local/activemq-cluster/node2/bin/activemq stop
/usr/local/activemq-cluster/node3/bin/activemq stop
zkServer.sh stop
第四:负载均衡配置如下:
集群1链接集群2:
<networkConnectors>
<networkConnector
uri="static:(tcp://192.168.1.112:51514,tcp://192.168.1.112:51515,tcp://192.168.1.112:51516)"
duplex="false"/>
</networkConnectors>
集群2链接集群1:
<networkConnectors>
<networkConnector
uri="static:(tcp://192.168.1.111:51511,tcp://192.168.1.111:51512,tcp://192.168.1.111:51513)"
duplex="false"/>
</networkConnectors>
ActiveMQ+Zookeeper集群配置文档的更多相关文章
- Rhel6-mpich2 hpc集群配置文档
系统环境: rhel6 x86_64 iptables and selinux disabled 主机: 192.168.122.121 server21.example.com 192.168.12 ...
- HP DL160 Gen9服务器集群部署文档
HP DL160 Gen9服务器集群部署文档 硬件配置=======================================================Server Memo ...
- kafka集群搭建文档
kafka集群搭建文档 一. 下载解压 从官网下载Kafka,下载地址http://kafka.apache.org/downloads.html 注意这里最好下载scala2.10版本的kafka, ...
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- redis多机集群部署文档
redis多机集群部署文档(centos6.2) (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下 ...
- zookeeper集群配置与启动——实战
1,准备: A:三台linxu服务器: 10.112.29.177 10.112.29.172 10.112.29.174 命令 hostname 得到每台机器的 hostname vm-10-112 ...
- kafka集群与zookeeper集群 配置过程
Kafka的集群配置一般有三种方法,即 (1)Single node – single broker集群: (2)Single node – multiple broker集群: (3)Mult ...
- Redis集群部署文档(Ubuntu15.10系统)
Redis集群部署文档(Ubuntu15.10系统)(要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如 ...
- java:zookeeper集群配置,dubbo
1.zookeeper集群配置: 2.dubbo:(配置见视频)
随机推荐
- 新知识 HtMl 5
快要毕业了,即将走向实习岗位,但是这日子过的太无聊了,昨天逃课回宿舍打开电脑想看电影但是没什么好看的,于是上床睡觉了,越躺越无聊,然后爬了起来到学习图书馆找了本HTML5的课本,学习了起来(我感觉ht ...
- springmvc重定向请求。
SpringMVC重定向传参数的实现(来自网友) 验证了我说的,从model层中拿来的数据,不管什么类型,都是通过隐含模型,中转,放入request中的.除非你特意把这些数据放到session域中. ...
- python 方法解析顺序 mro
一.概要: mor(Method Resolution Order),即方法解析顺序,是python中用于处理二义性问题的算法 二义性: 1.两个基类,A和B都定义了f()方法,c继承A和B那么C调用 ...
- 虚拟环境管理之virtualenvwrapper
上一篇写了下在linux上使用python的虚拟环境, 干脆把virtualenvwrapper也写一下 1.为什么要用virtualenvwrapper virtualenv 的一个最大的缺点就是: ...
- MIP缓存加速原理 MIP不仅仅只是CDN
什么是MIP?我想我们现在都知道.可是你真的了解MIP吗?MIP加速原理是什么?MIP 是用 CDN 做加速的么?准确答案是:是,但不只是. 很多人并认为MIP百度排名会靠前,甚至权重会提高?作为一个 ...
- ruby 比较符号==, ===, eql?, equal?
“==” 最常见的相等性判断 “==” 使用最频繁,它通常用于对象的值相等性(语义相等)判断,在 Object 的方法定义中,“==” 比较两个对象的 object_id 是否一致,通常子类都会重写覆 ...
- 005---json & pickle
json & pickle 什么是序列化 序列化是指把内存里的数据类型转变成字符串,以便使其能存储在硬盘和网络传输.因为只能接收bytes类型. 为什么要序列化 持久化存储 分类 - json ...
- 前端面试题目汇总摘录(JS 基础篇 —— 2018.11.02更新)
温故而知新,保持空杯心态 JS 基础 JavaScript 的 typeof 返回那些数据类型 object number function boolean undefined string type ...
- linux execl()函数
关于execl()函数族的用法不在赘述,其他博主介绍的很详细.下面说下作者在使用该函数时所犯的错误: 作者想通过使用execl()函数在子进程中调用其他函数,起初楼主是 这样用的: if((a = e ...
- P2212 [USACO14MAR]浇地Watering the Fields
P2212 [USACO14MAR]浇地Watering the Fields 题目描述 Due to a lack of rain, Farmer John wants to build an ir ...