Pandas数据分析练手题(十题)
数据集下载地址:https://github.com/Rango-2017/Pandas_exercises
----------------------------------------------------------------------------------------------------------------------
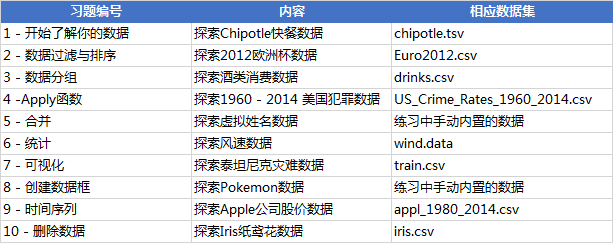
1 - 开始了解你的数据
探索Chipotle快餐数据
-- 将数据集存入一个名为chipo的数据框内
-- 查看前10行内容
-- 数据集中有多少个列(columns)?
-- 打印出全部的列名称
-- 数据集的索引是怎样的?
-- 被下单数最多商品(item)是什么?
-- 在item_name这一列中,一共有多少种商品被下单?
-- 在choice_description中,下单次数最多的商品是什么?
-- 一共有多少商品被下单?
-- 将item_price转换为浮点数
-- 在该数据集对应的时期内,收入(revenue)是多少?
-- 在该数据集对应的时期内,一共有多少订单?
-- 每一单(order)对应的平均总价是多少?
import pandas as pd
#将数据集存入一个名为chipo的数据框内
chipo = pd.read_csv('chipotle.tsv',sep='\t') #查看前10行内容
chipo.head(10) #数据集中有多少个列(columns)?
chipo.shape[1] #打印出全部的列名称
chipo.columns #数据集的索引是怎样的?
chipo.index #被下单数最多商品(item)是什么?
chipo[['item_name','quantity']].groupby(by=['item_name']).sum().sort_values(by=['quantity'],ascending=False) #在item_name这一列中,一共有多少种商品被下单?
chipo.item_name.nunique() #在choice_description中,下单次数最多的商品是什么?
#chipo[['choice_description','quantity']].groupby(by=['choice_description']).sum().sort_values(by=['quantity'],ascending=False)
chipo['choice_description'].value_counts().head() #一共有多少商品被下单?
chipo['quantity'].sum() #将item_price转换为浮点数
#货币符号后取起
chipo['item_price'] = chipo['item_price'].apply(lambda x: float(x[1:])) #在该数据集对应的时期内,收入(revenue)是多少?
(chipo['quantity'] * chipo['item_price']).sum() #在该数据集对应的时期内,一共有多少订单?
chipo['order_id'].nunique() #每一单(order)对应的平均总价是多少?
chipo['item_price_sum'] = chipo['quantity'] * chipo['item_price']
(chipo[['order_id','item_price_sum']].groupby(by=['order_id']).sum()).mean()
2 - 数据过滤与排序
探索2012欧洲杯数据
-- 将数据集命名为euro12
-- 只选取 Goals 这一列
-- 有多少球队参与了2012欧洲杯?
-- 该数据集中一共有多少列(columns)?
-- 将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
-- 对数据框discipline按照先Red Cards再Yellow Cards进行排序
-- 计算每个球队拿到的黄牌数的平均值
-- 找到进球数Goals超过6的球队数据
-- 选取以字母G开头的球队数据
-- 选取前7列
-- 选取除了最后3列之外的全部列
-- 找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
import pandas as pd
#将数据集命名为euro12
euro12 = pd.read_csv('C:\\Users\\Administrator\\Desktop\\Euro2012.csv') #只选取 Goals 这一列
euro12.Goals #有多少球队参与了2012欧洲杯?
euro12.Team.nunique() #该数据集中一共有多少列(columns)?
euro12.shape[1] #将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
discipline = euro12[['Team','Yellow Cards','Red Cards']] #对数据框discipline按照先Red Cards再Yellow Cards进行排序
discipline.sort_values(by=['Red Cards','Yellow Cards'],ascending = False) #计算拿到的黄牌数的平均值
euro12['Yellow Cards'].mean() #找到进球数Goals超过6的球队数据
euro12[euro12.Goals>6] #选取以字母G开头的球队数据
euro12[euro12.Team.str.startswith('G')] #选取前7列
euro12.iloc[:,0:7] #选取除了最后3列之外的全部列
euro12.iloc[:,0:-3] #找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
euro12.loc[euro12['Team'].isin(['England','Italy','Russia']),['Team','Shooting Accuracy']] #loc:通过行标签索引数据
#iloc:通过行号索引行数据
#ix:通过行标签或行号索引数据(基于loc和iloc的混合)
练习3-数据分组
探索酒类消费数据
-- 将数据框命名为drinks
-- 哪个大陆(continent)平均消耗的啤酒(beer)更多?
-- 打印出每个大陆(continent)的红酒消耗(wine_servings)的描述性统计值
-- 打印出每个大陆每种酒类别的消耗平均值
-- 打印出每个大陆每种酒类别的消耗中位数
-- 打印出每个大陆对spirit饮品消耗的平均值,最大值和最小值
import pandas as pd
#将数据框命名为drinks
drinks = pd.read_csv('C:\\Users\\Administrator\\Desktop\\drinks.csv') #哪个大陆(continent)平均消耗的啤酒(beer)更多?
(drinks[['continent','beer_servings']].groupby(by=['continent']).mean().sort_values(by=['beer_servings'],ascending =False)).head(1) #打印出每个大陆(continent)的红酒消耗(wine_servings)的描述性统计值
drinks.groupby('continent').wine_servings.describe() #打印出每个大陆每种酒类别的消耗平均值
drinks.groupby('continent').mean() #打印出每个大陆每种酒类别的消耗中位数
drinks.groupby('continent').median() #打印出每个大陆对spirit饮品消耗的平均值,最大值和最小值
drinks.groupby('continent').spirit_servings.describe()
练习4-Apply函数
探索1960 - 2014 美国犯罪数据
-- 将数据框命名为crime
-- 每一列(column)的数据类型是什么样的?
-- 将Year的数据类型转换为 datetime64
-- 将列Year设置为数据框的索引
-- 删除名为Total的列
-- 按照Year(每十年)对数据框进行分组并求和
-- 何时是美国历史上生存最危险的年代?
import pandas as pd
#将数据框命名为drinks
crime = pd.read_csv('C:\\Users\\Administrator\\Desktop\\US_Crime_Rates_1960_2014.csv',index_col=0) #每一列(column)的数据类型是什么样的?
crime.info() #将Year的数据类型转换为 datetime64
crime.Year = pd.to_datetime(crime.Year,format='%Y') #将列Year设置为数据框的索引
crime = crime.set_index('Year',drop=True) #删除名为Total的列
del crime['Total']
crime.head() #按照Year(每十年)对数据框进行分组并求和
crimes = crime.resample('10AS').sum()
population = crime.resample('10AS').max() #人口是累计数,不能直接求和
crimes['Population'] = population #何时是美国历史上生存最危险的年代?
crime.idxmax(0)#最大值的索引值
练习5-合并¶
探索虚拟姓名数据
-- 创建DataFrame
-- 将上述的DataFrame分别命名为data1, data2, data3
-- 将data1和data2两个数据框按照行的维度进行合并,命名为all_data
-- 将data1和data2两个数据框按照列的维度进行合并,命名为all_data_col
-- 打印data3
-- 按照subject_id的值对all_data和data3作合并
-- 对data1和data2按照subject_id作连接
-- 找到 data1 和 data2 合并之后的所有匹配结果
import pandas as pd
import numpy as np
raw_data_1 = {
'subject_id': ['1', '2', '3', '4', '5'],
'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']} raw_data_2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']} raw_data_3 = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
#创建DataFrame
#将上述的DataFrame分别命名为data1, data2, data3
data1 = pd.DataFrame(raw_data_1)
data2 = pd.DataFrame(raw_data_2)
data3 = pd.DataFrame(raw_data_3) #将data1和data2两个数据框按照行的维度进行合并,命名为all_data
all_data = pd.concat([data1,data2],axis=0) #将data1和data2两个数据框按照列的维度进行合并,命名为all_data_col
all_data_col = pd.concat([data1,data2],axis=1) #打印data3
data3 #按照subject_id的值对all_data和data3作合并
pd.merge(all_data,data3,on='subject_id') #对data1和data2按照subject_id作内连接
pd.merge(data1,data2,on='subject_id',how='inner') #找到 data1 和 data2 合并之后的所有匹配结果
pd.merge(data1,data2,on='subject_id',how='outer')
练习6-统计
探索风速数据
-- 将数据作存储并且设置前三列为合适的索引
-- 2061年?我们真的有这一年的数据?创建一个函数并用它去修复这个bug
-- 将日期设为索引,注意数据类型,应该是datetime64[ns]
-- 对应每一个location,一共有多少数据值缺失
-- 对应每一个location,一共有多少完整的数据值
-- 对于全体数据,计算风速的平均值
-- 创建一个名为loc_stats的数据框去计算并存储每个location的风速最小值,最大值,平均值和标准差
-- 创建一个名为day_stats的数据框去计算并存储所有location的风速最小值,最大值,平均值和标准差
-- 对于每一个location,计算一月份的平均风速
-- 对于数据记录按照年为频率取样
-- 对于数据记录按照月为频率取样
import pandas as pd
import datetime
#将数据作存储并且设置前三列为合适的索引
df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\wind.data',sep='\s+',parse_dates=[[0,1,2]]) #2061年?我们真的有这一年的数据?创建一个函数并用它去修复这个bug
def fix_century(x):
year = x.year - 100 if x.year>1999 else x.year
return datetime.date(year,x.month,x.day) df['Yr_Mo_Dy'] = df['Yr_Mo_Dy'].apply(fix_century) #将日期设为索引,注意数据类型,应该是datetime64[ns]
df['Yr_Mo_Dy'] = pd.to_datetime(df['Yr_Mo_Dy'])
df = df.set_index('Yr_Mo_Dy') #对应每一个location,一共有多少数据值缺失
df.isnull().sum() #对应每一个location,一共有多少完整的数据值
df.shape[1] - df.isnull().sum() #对于全体数据,计算风速的平均值
df.mean().mean() #创建一个名为loc_stats的数据框去计算并存储每个location的风速最小值,最大值,平均值和标准差
loc_stats = pd.DataFrame()
loc_stats['min'] = df.min()
loc_stats['max'] = df.max()
loc_stats['mean'] = df.mean()
loc_stats['std'] = df.std() #创建一个名为day_stats的数据框去计算并存储所有天的风速最小值,最大值,平均值和标准差
day_stats = pd.DataFrame()
day_stats['min'] = df.min(axis=1)
day_stats['max'] = df.max(axis=1)
day_stats['mean'] = df.mean(axis=1)
day_stats['std'] = df.std(axis=1) #对于每一个location,计算一月份的平均风速
df['date'] = df.index df['year'] = df['date'].apply(lambda df: df.year)
df['month'] = df['date'].apply(lambda df: df.month)
df['day'] = df['date'].apply(lambda df: df.day) january_winds = df.query('month ==1') #query等同于df[df.month==1]
january_winds.loc[:,'RPT':'MAL'].mean() #对于数据记录按照年为频率取样
df.query('month ==1 and day == 1') #对于数据记录按照月为频率取样
df.query('day == 1')
练习7-可视化
探索泰坦尼克灾难数据
-- 将数据框命名为titanic
-- 将PassengerId设置为索引
-- 绘制一个展示男女乘客比例的扇形图
-- 绘制一个展示船票Fare, 与乘客年龄和性别的散点图
-- 有多少人生还?
-- 绘制一个展示船票价格的直方图
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np #将数据框命名为titanic
titanic = pd.read_csv('C:\\Users\\Administrator\\Desktop\\train.csv') #将PassengerId设置为索引
titanic = titanic.set_index('PassengerId') #绘制一个展示男女乘客比例的扇形图
Male = (titanic.Sex == 'male').sum()
Female = (titanic.Sex == 'female').sum() proportions = [Male,Female] plt.pie(proportions, labels=['Male','Female'],shadow=True,
autopct='%1.1f%%',startangle=90,explode=(0.15,0))
plt.axis('equal')
plt.title('Sex Proportion')
plt.tight_layout()
plt.show() #绘制一个展示船票Fare, 与乘客年龄和性别的散点图
lm = sns.lmplot(x='Age',y='Fare', data=titanic,hue='Sex',fit_reg=False)
lm.set(title='Fare x Age') #设置坐标轴取值范围
axes = lm.axes
axes[0,0].set_ylim(-5,)
axes[0,0].set_xlim(-5,85) #有多少人生还?
titanic.Survived.sum() #绘制一个展示船票价格的直方图
df = titanic.Fare.sort_values(ascending = False) plt.hist(df,bins = (np.arange(0,600,10)))
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.title('Fare Payed Histrogram')
plt.show()
练习8-创建数据框
探索Pokemon数据
-- 创建一个数据字典
-- 将数据字典存为一个名叫pokemon的数据框中
-- 数据框的列排序是字母顺序,请重新修改为name, type, hp, evolution, pokedex这个顺序
-- 添加一个列place['park','street','lake','forest']
-- 查看每个列的数据类型
import pandas as pd
#创建一个数据字典
raw_data = {"name": ['Bulbasaur', 'Charmander','Squirtle','Caterpie'],
"evolution": ['Ivysaur','Charmeleon','Wartortle','Metapod'],
"type": ['grass', 'fire', 'water', 'bug'],
"hp": [45, 39, 44, 45],
"pokedex": ['yes', 'no','yes','no']
}
#将数据字典存为一个名叫pokemon的数据框中
pokemon = pd.DataFrame(raw_data) #数据框的列排序是字母顺序,请重新修改为name, type, hp, evolution, pokedex这个顺序
pokemon = pokemon[['name', 'type', 'hp', 'evolution', 'pokedex']] #添加一个列place['park','street','lake','forest']
pokemon['place'] = ['park','street','lake','forest'] #看每个列的数据类型
pokemon.dtypes
练习9-时间序列
探索Apple公司股价数据
-- 读取数据并存为一个名叫apple的数据框
-- 查看每一列的数据类型
-- 将Date这个列转换为datetime类型
-- 将Date设置为索引
-- 有重复的日期吗?
-- 将index设置为升序
-- 找到每个月的最后一个交易日(business day)
-- 数据集中最早的日期和最晚的日期相差多少天?
-- 在数据中一共有多少个月?
-- 按照时间顺序可视化Adj Close值
import pandas as pd
#读取数据并存为一个名叫apple的数据框
apple = pd.read_csv('C:\\Users\\Administrator\\Desktop\\appl_1980_2014.csv') #查看每一列的数据类型
apple.dtypes #将Date这个列转换为datetime类型
apple.Date = pd.to_datetime(apple.Date) #将Date设置为索引
apple = apple.set_index('Date') #有重复的日期吗?
apple.index.is_unique #将index设置为升序
apple = apple.sort_index(ascending = True) #找到每个月的最后一个交易日(business day)
apple_month = apple.resample('BM').mean()
apple_month.head() #数据集中最早的日期和最晚的日期相差多少天?
(apple.index.max() - apple.index.min()).days #在数据中一共有多少个月?
len(apple_month) #按照时间顺序可视化Adj Close值
apple['Adj Close'].plot(title = 'Apple Stock').get_figure().set_size_inches(9,5)
练习10-删除数据
探索Iris纸鸢花数据
-- 将数据集存成变量iris
-- 创建数据框的列名称['sepal_length','sepal_width', 'petal_length', 'petal_width', 'class']
-- 数据框中有缺失值吗?
-- 将列petal_length的第10到19行设置为缺失值
-- 将petal_lengt缺失值全部替换为1.0
-- 删除列class
-- 将数据框前三行设置为缺失值
-- 删除有缺失值的行
-- 重新设置索引
import pandas as pd
import numpy as np
#读取数据并存为一个名叫apple的数据框
iris = pd.read_csv('C:\\Users\\Administrator\\Desktop\\iris.data') #创建数据框的列名称['sepal_length','sepal_width', 'petal_length', 'petal_width', 'class']
iris.columns = ['sepal_length','sepal_width', 'petal_length', 'petal_width', 'class'] #数据框中有缺失值吗?
iris.isnull().sum() #将列petal_length的第10到19行设置为缺失值
iris['petal_length'].loc[10:19]=np.nan #将petal_lengt缺失值全部替换为1.0
iris.petal_length.fillna(1 , inplace=True) #删除列class
del iris['class'] #将数据框前三行设置为缺失值
iris.loc[0:2,:]=np.nan #删除有缺失值的行
iris = iris.dropna(how='any') #重新设置索引
iris = iris.reset_index(drop = True)#加上drop参数,原有索引就不会成为新的列
参考至科赛网
https://www.kesci.com/home/project/59e77a636d213335f38daec2
Pandas数据分析练手题(十题)的更多相关文章
- Python数据分析练手:分析知乎大V
原文链接:https://zhuanlan.zhihu.com/p/92768131?utm_source=tuicool&utm_medium=referral 知乎,可以说是国内目前最大的 ...
- 一步一步 Pwn RouterOS之ctf题练手
前言 本文由 本人 首发于 先知安全技术社区: https://xianzhi.aliyun.com/forum/user/5274 本文目的是以一道比较简单的 ctf 的练手,为后面的分析 Rout ...
- C语言考试解答十题
学院比较奇葩,大一下期让学的VB,这学期就要学C++了,然后在开学的前三个周没有课,就由老师讲三个周的C语言,每天9:30~11:30听课,除去放假和双休日,实际听课时间一共是12天*2小时,下午是1 ...
- Python之路【第二十四篇】:Python学习路径及练手项目合集
Python学习路径及练手项目合集 Wayne Shi· 2 个月前 参照:https://zhuanlan.zhihu.com/p/23561159 更多文章欢迎关注专栏:学习编程. 本系列Py ...
- 2019前端面试系列——JS高频手写代码题
实现 new 方法 /* * 1.创建一个空对象 * 2.链接到原型 * 3.绑定this值 * 4.返回新对象 */ // 第一种实现 function createNew() { let obj ...
- Java实习生常规技术面试题每日十题Java基础(八)
目录 1.解释内存中的栈(stack).堆(heap)和静态区(static area)的用法. 2.怎样将GB2312编码的字符串转换为ISO-8859-1编码的字符串? 3.运行时异常与受检异常有 ...
- Java实习生常规技术面试题每日十题Java基础(七)
目录 1. Java设计模式有哪些? 2.GC是什么?为什么要有GC? 3. Java中是如何支持正则表达式. 4.比较一下Java和JavaSciprt. 5.Math.round(11.5) 等于 ...
- Java实习生常规技术面试题每日十题Java基础(六)
目录 1.在Java语言,怎么理解goto. 2.请描述一下Java 5有哪些新特性? 3.Java 6新特性有哪些. 4.Java 7 新特性有哪些. 5.Java 8 新特性有哪些. 6.描述Ja ...
- Java实习生常规技术面试题每日十题Java基础(五)
目录 1.启动一个线程是用run()还是start()? . 2.线程的基本状态以及状态之间的关系. 3.Set和List的区别,List和Map的区别? 4.同步方法.同步代码块区别? 5.描述Ja ...
随机推荐
- JAVA字符配置替换方案
在JAVA中,很多时候,我们后台要对数据进行变量配置,希望可以在运行时再进行变量替换.我们今天给大空提供的是org.apache.commons.text方案. 1.首先,引用org.apache.c ...
- python爬虫--用xpath爬豆瓣电影
步骤 将目标网站下的页面抓取下来 将抓取下来的数据根据一定规则进行提取 具体流程 将目标网站下的页面抓取下来 1. 倒库 import requests 2.头信息(有时候可不写) headers ...
- Python最会变魔术的魔术方法,我觉得是它!
在上篇文章中,我有一个核心的发现:Python 内置类型的特殊方法(含魔术方法与其它方法)由 C 语言独立实现,在 Python 层面不存在调用关系. 但是,文中也提到了一个例外:一个非常神秘的魔术方 ...
- 查询是否sci或者ei收录
1,如果查文章是不是被SCI检索:进入ISI Web of Knowledge,选择Web of Science 数据库,进行查询:2,如果查文章是不是被EI检索:进入EI Village, 选择Co ...
- Swing01-概述
1.Swing概述 Swing百分之百由Java本身实现,是一套轻量级组件(完全由Java实现的组件叫做轻量级套件,依赖于本地平台的套件称之为重量级套件).Swing不再依赖于平台的GUI,因此真正做 ...
- JavaSE22-Lambda表达式&方法引用
1.Lambda表达式 1.1 Lambda表达式的标准格式 1 (形式参数) -> {代码块} 形式参数:如果有多个参数,参数之间用逗号隔开:如果没有参数,留空即可 ->:由英文中画线和 ...
- 很多人不知道的Python 炫技操作:条件语句的写法
有的人说 Python 是一门 入门容易,但是精通难的语言,这一点我非常赞同. Python 语言里有许多(而且是越来越多)的高级特性,是 Python 发烧友们非常喜欢的.在这些人的眼里,能够写出那 ...
- 【译】理解Rust中的Futures(二)
原文标题:Understanding Futures in Rust -- Part 2 原文链接:https://www.viget.com/articles/understanding-futur ...
- Python代码打包成exe可执行程序
首先,打包成exe可执行程序是针对windows平台来说的. 目前比较主流的打包工具就是pyinstaller. 参考:Using PyInstaller 首先安装pyinstaller: pip i ...
- 游标数据练习java
//===============================================================生成游标的方法 List menu=new ArrayList(); ...