深入研究Broker是如何持久化的
前言
上篇文章王子和大家讨论了一下RocketMQ生产者发送消息的底层原理,今天我们接着这个话题,继续深入聊一聊RocketMQ的Broker是如何持久化的。
Broker的持久化对于整个RocketMQ的运行起着至关重要的作用,为什么这么说呢?
其实解释起来很容易,因为消息中间件要实现的功能不仅仅是消息的发送和接收,它本身还要有很强大的存储能力,把来自各个系统的消息持久化到磁盘上。
只有这样,在其他系统消费消息时才能从磁盘中读取想要的消息。
如果不持久化到磁盘上,而是通过内存存储消息,一是内存无法存储大量的消息,二是出现故障消息将会丢失。
所以,Broker的持久化是比较核心的机制,它决定了MQ消息吞吐量,和保证消息的可靠性。
今天我们就来聊一聊,Broker是如何持久化的。
CommitLog
首先我们思考一下,当Broker接收到生产者发来的消息后,内部会做些什么呢?
这时候我们就引入了一个新的概念CommitLog,它就是一个日志文件。Broker接收到消息后的第一步就是把消息写到这个日志文件中,而且是顺序写入的。
那么CommitLog文件是怎么存储的呢?
它可不是直接一个日志文件进行存储的,而是分成很多份存储在磁盘中,每一份限定了最大1GB。
当Broker接收到新的消息时就会顺序的追加到日志文件的末尾,而当文件大小到了1GB,就会新创建一个日志文件,新的消息就会写入新的日志文件,循环往复。
MessageQueue是如何存储的
刚才我们说了,Broker接收到消息要把消息存储到日志文件中,那么上篇文章我们讲的MessageQueue又是如何存储的呢?
这时候我们就又引出了一个新的概念,ConsumeQueue文件,每个MessageQueue会存储到多个ConsumeQueue文件中。
再给大家更详细的说一下,其实Broker的磁盘上是有类似$HOME/store/consumequeue/{topic}/{queueid}/{filename}这样的目录的:
这里面的{topic}代表的就是我们声明的Topic,{queueid}代表的就是我们单个的MessageQueue,而{filename}就是我们的存储文件多个ConsumeQueue文件了。
在ConsumeQueue文件中其实存储的是一条消息对应在CommitLog中的offset(偏移量)。
这么说可能小伙伴们不太理解,别急,王子接下来画个图跟大家仔细的聊一聊。
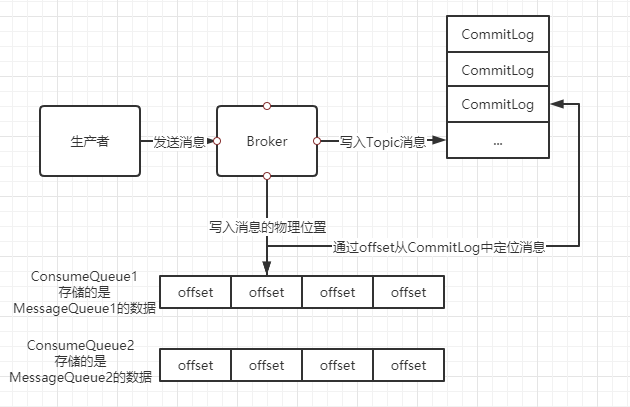
现在我们假设生产者发送了一个消息到一个Topic中,这个Topic的名字叫orderTopic,并指定了它有两个MessageQueue:MessageQueue1、MessageQueue2。
那么Broker接收到消息后,首先把数据存放到了CommitLog中。
然后每个MessageQueue对应了一个ConsumeQueue(实际可以是多个),对应的是ConsumeQueue1、ConsumeQueue2。
那么现在在Broker的磁盘上就有了两个路径文件:
$HOME/store/consumequeue/orderTopic/MessageQueue1/ConsumeQueue1
$HOME/store/consumequeue/orderTopic/MessageQueue2/ConsumeQueue2
然后呢,在写入CommitLog文件后,会同时将消息在CommitLog文件中的位置(偏移量offset)写入到对应的ConsumeQueue中。
所以,ConsumeQueue中存储的其实是消息的引用地址,同时还会存储消息的tag、hashcode以及消息的长度。每条数据20个字节进行存储。
当我们获取消息的时候就可以通过ConsumeQueue中的引用地址去CommitLog中找到我们想要的消息了。
这样解释起来相信小伙伴们应该可以明白了吧。
写入CommitLog的性能探索
接下来我们聊下一个话题,当Broker获取到消息写入CommitLog中时,是如何保证写入性能的呢?
为什么要优化写入的性能呢?因为这一步骤的写入性能直接影响着Broker的吞吐量。
如果每次写入消息速度很慢,那么每秒能处理的消息数量自然就会跟着大大减少了,这个相信小伙伴们都可以理解。
那么RocketMQ针对这一步骤是怎么做的呢?
实际上,它采用了OS操作系统的PageCache和顺序写两个机制,来提升了写入CommitLog的性能。
首先我们之前就聊过了,Broker在写入CommitLog时,采用的是顺序写入的方式,每次只要在文件的末尾追加写入数据就可以了,这样的方式要比随机写入的方式性能提升不少。
另外,其实写入CommitLog日志时,并不是直接将数据写入到磁盘文件中的,而是先写入OS操作系统的PageCache中,然后由OS操作系统的后台线程选择时间,异步化的把PageCache中的数据同步到物理磁盘中的。
所以通过顺序写+写入PageCache+异步刷盘这么一套优化过后,其实写入CommitLog的性能甚至可以和直接写入内存相媲美。
也正是因为这,才保证了Broker的高吞吐量。
同步刷盘和异步刷盘
刚才我们聊到的就是异步刷盘的策略,Broker在写入OS的PageCache之后,就直接返回给生产者ACK了。
这样,生产者就会认为我的消息已经成功发送给了Broker。那么这样的策略是否会存在问题呢?
其实简单想一想就会明白,问题肯定是存在的。
因为OS操作系统的PageCache也是一种缓存,如果写入了缓存就认为发送成功没有问题了,那如果缓存还没来得及刷新到物理磁盘,这个时候Broker挂掉了,会发生什么呢?
当然,这个时候缓存中的消息数据就会丢失,无法恢复!
所以说技术的选择上是有舍有得的,如果选择了异步刷盘的策略,就会大大提高Broker的吞吐量,但同时也会有丢失消息的隐患。
那么什么是同步刷盘策略呢?
其实同步刷盘就是跳过了PageCache这一步骤,当生产者发送消息给Broker后,Broker必须把数据存到真实的物理磁盘中之后才会返回ACK给生产者,这个时候生产者才会断定消息发送成功了。
消息一旦写入物理磁盘,除非是磁盘硬件损坏,导致数据丢失。否则我们就可以认为消息是不会丢失的了。
在同步刷盘策略下,假如没有刷到物理磁盘上时Broker挂掉了,这时是不会返回ACK给生产者的,那么生产者会认为发送失败,进行消息重发机制就可以了。
当主从切换完成后,消息就会正常的写入Broker了。所以这种策略是可以保证消息不会丢失的。
还是那句话,技术的选择是有舍有得的,使用同步刷盘策略保证了消息的可靠性,但同时会降低Broker的吞吐量。
所以具体选择哪种策略,还要根据实际的业务需求来定夺了。
总结
好了,今天王子和大家深入的聊了聊Broker是如何持久化的,介绍了什么是CommitLog,什么是ConsumeQueue。
又和大家聊了聊写入CommitLog的实现细节,如何通过PageCache保证性能。
最后和大家介绍了同步刷盘、异步刷盘的不同之处。
那今天的分享就到这里了,我们下期再见。
往期文章推荐:

深入研究Broker是如何持久化的的更多相关文章
- 深入研究RocketMQ消费者是如何获取消息的
前言 小伙伴们,国庆都过的开心吗?国庆后的第一个工作日是不是很多小伙伴还沉浸在假期的心情中,没有工作状态呢? 那王子今天和大家聊一聊RocketMQ的消费者是如何获取消息的,通过学习知识来找回状态吧. ...
- Dledger的是如何实现主从自动切换的
前言 hello小伙伴们,今天王子又来继续和大家聊RocketMQ了,之前的文章我们一直说Broker的主从切换是可以基于Dledger实现自动切换的,那么小伙伴们是不是很好奇它究竟是如何实现的呢?今 ...
- RocketMQ的消息是怎么丢失的
前言 通过之前文章的阅读,有关RocketMQ的底层原理相信小伙伴们已经有了一个比较清晰的认识. 那么接下来王子想跟大家讨论一个话题,如果我们的项目中引入了MQ,势必要面对的一个问题,就是消息丢失问题 ...
- RocketMQ消息丢失解决方案:事务消息
前言 上篇文章,王子通过一个小案例和小伙伴们一起分析了一下消息是如何丢失的,但没有提出具体的解决方案. 我们已经知道发生消息丢失的原因大体上分为三个部分: 1.生产者发送消息到MQ这一过程导致消息丢失 ...
- RocketMQ消息丢失解决方案:同步刷盘+手动提交
前言 之前我们一起了解了使用RocketMQ事务消息解决生产者发送消息时消息丢失的问题,但使用了事务消息后消息就一定不会丢失了吗,肯定是不能保证的. 因为虽然我们解决了生产者发送消息时候的消息丢失问题 ...
- 探索RocketMQ的重复消费和乱序问题
前言 在之前的MQ专题中,我们已经解决了消息中间件的一大难题,消息丢失问题. 但MQ在实际应用中不是说保证消息不丢失就万无一失了,它还有两个令人头疼的问题:重复消费和乱序. 今天我们就来聊一聊这两个常 ...
- Lind.DDD.LindMQ~关于持久化到Redis的消息格式
回到目录 关于持久化到Redis的消息格式,主要是说在Broker上把消息持久化的过程中,需要存储哪些类型的消息,因为我们的消息是分topic的,而每个topic又有若干个queue组成,而我们的to ...
- Broker模块划分
本篇在上一篇<消息中间件架构讨论>的基础上分析Broker的模块划分. 上图是之前讨论确定的系统架构(后续内容会按照这个架构来叙述),几点基础: Broker采用主从结构 Broker负责 ...
- ActiveMQ(3)---ActiveMQ原理分析之消息持久化
持久化消息和非持久化消息的存储原理 正常情况下,非持久化消息是存储在内存中的,持久化消息是存储在文件中的.能够存储的最大消息数据在${ActiveMQ_HOME}/conf/activemq.xml文 ...
随机推荐
- MPI实现Jacobi
一.Jacobi迭代 #include<stdio.h> #include<mpi.h> #include<stdlib.h> #define totalsize ...
- 蒲公英 · JELLY技术周刊 Vol.19 从零开始的 Cloud IDE 开发
蒲公英 · JELLY技术周刊 Vol.19 你是否也会有想法去开发一个自己的 IDE 却苦于时间和精力不足,完成 Desktop IDE 却又被 Cloud IDE 的概念追在身后难以入睡,这样的两 ...
- java面试题0001-区分类中重载方法的依据是什么?
到底是根据什么来区分类中重载的方法? A:不同的返回值类型. B:不同的参数类型. C:不同的访问权限. D:不同的参数名称. 解析: Step1.我们先在DifferentiateReload类中创 ...
- 3个必备cookie实用方法
今天跟大家介绍一下三种cookie的使用方法,selenium提供了我们add_cookie()方法来跳过验证码直接登录的方法.我们现在以博客园登录为例,都知道现在博客园登录要拼图验证. 先在网页打开 ...
- PyTorch入门-CIFAR10图像分类
CIFAR10数据集下载 CIFAR10数据集包含10个类别,图像尺寸为 3×32×32 官方下载地址很慢,这里给一个百度云: https://pan.baidu.com/s/1oTvW8wNa-VO ...
- pyqt 设置QTabWidget标签页不可选
pyqt 设置QTabWidget标签页不可选 for i in range(1,7): self.tabWidget.setTabEnabled(i,False)i-对应标签页的位数
- C#知识点:I/O
一.什么是I/0流? 英文翻译:Input/Output,在程序里简单的理解为读写数据操作数据的意思.流操作是为了解决体积大数据占用太多的内存,就是分段进行操作.就跟我们吃饭一样,一口一口的吃,还没见 ...
- 执行Python程序出现“SyntaxError: Non-UTF-8 code starting with '\xb6'...”错误怎么办?
如果文件中有中文,直接执行python xx.py会出现以下错误: SyntaxError: Non-UTF- code starting with '\xb6' in file XX.py on l ...
- Nginx之https配置
14.1. 对称加密 安全隐患:钥匙除我之外,还有多个人拥有.泄露风险较大,钥匙传递的过程风险较大 14.2. 非对称加密 优缺点:私钥很安全.但是非对称算法开销很大,大批量应用于业务,会导致性能成本 ...
- 提升开发幸福度-IDE配置
插件 vscode插件 Settings Sync Atom One Dark Theme Bracket Pair Colorizer Code Runner Dracular Official E ...