Hadoop 中HDFS、MapReduce体系结构
在网络环境方面,作为分布式系统,Hadoop基于TCP/IP进行节点间的通信和传输。
在数据传输方面,广泛应用HTTP实现。
在监控、通知方面,Hadoop等分布式大数据软件则广泛使用异步消息队列等机制。
1. hadoop的概念及其发展历程
Hadoop是Apache开源组织的一个分布式计算开源框架,用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。
Hadoop框架中最核心设计:HDFS和MapReduce,HDFS实现存储,MapReduce实现原理分析处理。数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Hadoop的集群处理后得到结果,它是一个高性能处理海量数据集的工具。
Hadoop干什么:最初的应用场景是搜索引擎的底层支撑技术,适合大数据的分布式存储与计算平台。
Hadoop核心组件:分布式文件系统HDFS、分布式处理框架MapReduce、分布式资源管理框架Yarn。
Hadoop的架构:从图中可看出,HBase、Spark、MapReduce、Yarn等组件是并行关系。

- HDFS文件系统:存储基础,负责对大数据文件和存储集群进行管理。HDFS不能实现对数据的表格化管理和快速检索(随机读取)。
- HBase:在HDFS基础上,将数据组织为面向列的数据表,并支持按照行键进行快速检索等功能,本身不对数据进行分布式处理。
- Yarn:负责对集群中的内存、CPU等资源进行管理,同时负责对分布式任务进行资源分配和管理。
- MapReduce:通过YARN在分布式集群中申请资源、提交任务,并按照自定义方式对数据进行处理。
- Spark和Tez:MapReduce的升级和替代产品,支持HDFS和HBase作为数据源和输出,并通过Yarn向分布式集群提交分布式处理任务。
- Hive:实现对分布式处理架构的简化应用。Hive映射HDFS形成二维数据表,并且将SQL语句转化为MapReduce过程。
- sqoop和flume:数据交互工具,前者基于MapReduce构建,实现关系型数据库和HDFS、HBase之间的分布式数据互转;后者可以实现将日志数据采集到大数据平台。
- Oozie和hue:实现数据处理过程的工作流构建和可视化操作。
- Zookeeper:实现各个服务集群点的节点监控、高可用性管理和配置同步等功能。
2. HDFS和MapReduce的体系结构
HDFS:hadoop distributed file system,hadooop分布式文件系统,它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集的应用程序。

HDFS体系结构:
主从结构:主节点只有一个:namenode;从节点,有多个,datanodes。
Namenode负责:接收用户操作请求;维护文件系统的目录机构;管理文件与block之间的关系,block与datanode之间关系。
Datanode负责:存储文件;文件被分成block存储在磁盘上;为保证数据安全,文件会有多个副本。
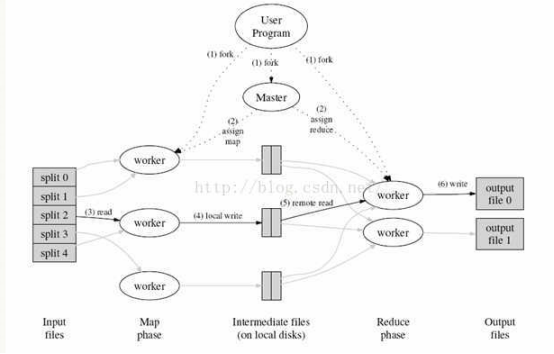
MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce将分为两个部分:Map(映射)和Reduce(归约)。
当你向mapreduce框架提交一个计算作业,它会首先把计算作业分成若干个map任务,然后分配到不同的节点上去执行,每一个map任务处理输入数据中的一部分,当map任务完成后,它会生成一些中间文件,这些中间文件将会作为reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个map的数据汇总到一起并输出。
MapReduce的体系结构:
主从结构:主节点,只有一个:JobTracker;从节点,有很多个:Task Trackers
JobTracker负责:接收客户提交的计算任务;把计算任务分给Task Trackers执行;监控Task Tracker的执行情况;
Task Trackers负责:执行JobTracker分配的计算任务。
3.Hadoop的特点和集群特点
Hadoop集群的物理分布:

单节点物理结构:

Hadoop的特点:
1、扩容能力:能可靠地存储和处理千兆字节数据
2、成本低:可以通过普通机器组成的服务器群来分发以及处理数据。
3、高效率:通过分发数据,hadoop可以在数据所在的节点上并行地处理它们,这使得处理非常的快速。
4、可靠性:hadoop能自动维护数据的多份副本,并且在任务失败后能自动地重新部署计算任务。
Hadoop 中HDFS、MapReduce体系结构的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- hadoop中HDFS的NameNode原理
1. hadoop中HDFS的NameNode原理 1.1. 组成 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 1.2. HDFS架构 ...
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- Hadoop中HDFS工作原理
转自:http://blog.csdn.net/sdlyjzh/article/details/28876385 Hadoop其实并不是一个产品,而是一些独立模块的组合.主要有分布式文件系统HDFS和 ...
- Hadoop中HDFS的管理
本文讲述怎么在Linux Shell中对HDFS进行操作. 三种命令格式: hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统 hadoop dfs只能适用于HDFS文件系 ...
- hadoop中HDFS文件系统 nameNode出现的问题 nameNode无法打开
1,修改core-site.xml文件,先改成localhost,将所有进程关闭stop-all.sh(或者是先关闭所有进程,然后再修改文件),然后重启,在修改core-site.xml文件成ip地址 ...
- Hadoop中Hbase的体系结构
HRegion 当一张表中的数据特别多的时候,HBase把表拆成多个块,每个块就是一个HRegion,每个region中包含这个表里的所有行 HRegionServer 数据库的数据存在HDFS文件系 ...
- Hadoop中HDFS 的相关进程以及工作流程图(详细流程图)
- 每天收获一点点------Hadoop之初始MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
随机推荐
- 针对DEV XtraReport中没有radiobuttonlist的替代方法
private void PrintingSystem_EditingFieldChanged(object sender, DevExpress.XtraPrinting.EditingField ...
- Martini初步
部分内容来自http://jerkwin.github.io/9999/08/01/Martini%E7%B2%97%E7%B2%92%E5%8C%96%E5%8A%9B%E5%9C%BA%E4%BD ...
- 4. 树形DP
337. 打家劫舍 III https://leetcode-cn.com/problems/house-robber-iii/ /** * Definition for a binary tree ...
- C++如何实现多态
1. 什么是多态多态是C++中的一个重要的基础,面向对象编程语言中,接口的多种不同的实现方式即为多态.2. 多态带来的好处多态带来两个明显的好处:一是不用记大量的函数名了,二是它会依据调用时的 ...
- tcpdump详解(转)
tcpdump是Linux下强大的抓包工具,不仅可以分析数据包流向,还可以对数据包内容进行监听.通过分析数据包流向,可以了解一条连接是如何建立双向连接的.tcpdump允许用户(一般是root)拦截和 ...
- 微服务通信之feign的配置隔离
前言 由上文我们知道针对某一个Feign接口,我们可以给他设置特定的配置类.那如果现在有一个服务,我们只想对A服务配置一个拦截器拦截请求而不影响其他服务,那应该怎么做呢? 一.feign接口配置 由前 ...
- 编译一个支持多线程的php安装包
前言 因为项目上的需要,需要用到php,一般来说,用默认的版本和配置就可以满足大多数的场景,因为需要加入多线程,所以需要自己编译一个包 一般来说,发行的包的版本的配置选项和代码都是最稳定的,所以在大多 ...
- rgw配置删除快速回收对象
前言 做rgw测试的时候,经常会有删除文件的操作,而用默认的参数的时候,rgw是通过gc回收机制来处理删除对象的,这个对于生产环境是有好处的,把删除对业务系统的压力分摊到不同的时间点,但是测试的时候, ...
- WPF控件库总结
前言 在使用WPF项目的时候, 一般首要的就是对UI部分的选型, 而WPF相关的UI控件和样式库在Githu也是非常多. 关于UI的部分,可以分为二种: 对控件本身没有很大的需求, 只需要在原有的基础 ...
- Dubbo 服务导出-Version2.7.5
1.源码分析 1.1分析服务导出入口 当容器为spring是dubbo会为容器注册两个监听器:DubboLifecycleComponentApplicationListener和DubboBoots ...