Kafka入门(3):Sarama生产者是如何工作的
摘要
在这一篇的文章中,我将从Sarama的同步生产者和异步生产者怎么创建开始讲起,然后我将向你介绍生产者中的各个参数是什么,怎么使用。
然后我将从创建生产者的代码开始,按照代码的调用流程慢慢深入,直到发送消息并接收到响应。
这个过程跟上面的文章说到的kafka各个层次其实是有对应关系的。
1.如何使用
1.1 介绍
在学习如何使用Sarama生产消息之前,我先稍微介绍一下。
Sarama有两种类型的生产者,同步生产者和异步生产者。
To produce messages, use either the AsyncProducer or the SyncProducer. The AsyncProducer accepts messages on a channel and produces them asynchronously in the background as efficiently as possible; it is preferred in most cases. The SyncProducer provides a method which will block until Kafka acknowledges the message as produced. This can be useful but comes with two caveats: it will generally be less efficient, and the actual durability guarantees depend on the configured value of
Producer.RequiredAcks. There are configurations where a message acknowledged by the SyncProducer can still sometimes be lost.
官方文档的大致意思是异步生产者使用channel接收(生产成功或失败)的消息,并且也通过channel来发送消息,这样做通常是性能最高的。而同步生产者需要阻塞,直到收到了acks。但是这也带来了两个问题,一是性能变得更差了,而是可靠性是依靠参数acks来保证的。
1.2 异步发送
然后我们直接来看看Sarama是怎么发送异步消息的。
我们先来创建一个最简陋的异步生产者,省略所有的不必要的配置。
注意,为了更容易阅读,我删去了错误处理,并且用省略号替代。
func main() {config := sarama.NewConfig()client, err := sarama.NewClient([]string{"localhost:9092"}, config)...producer, err := sarama.NewAsyncProducerFromClient(client)...defer producer.Close()topic := "topic-test"for i := 0; i <= 100; i++ {text := fmt.Sprintf("message %08d", i)producer.Input() <- &sarama.ProducerMessage{Topic: topic,Key: nil,Value: sarama.StringEncoder(text)}}}
可以看出,Sarama发送消息的套路就是先创建一个config,这里更多的config内容我们会在后文提到。
随后根据这个config,和broker地址,创建出生产者客户端。
再然后根据客户端来创建生产者对象(其实在这里用对象不够严谨,但是我认为这么理解是没有问题的)。
最后就可以使用这个生产者对象来发送信息了。
消息的构造过程中我也省略了其他的参数,只保留了最重要也是最必须的两个参数:主题和消息内容。
到了这里,一个简单的异步生产者发送消息的过程就结束了。
1.3 同步发送
在看完了异步发送之后,你可能会有很多的诸如“为什么要这么做”的疑问。
我们先来看看同步发送,再来对比一下:
func main() {config := sarama.NewConfig()config.Producer.Return.Successes = trueclient, err := sarama.NewClient([]string{"localhost:9092"}, config)...producer, err := sarama.NewSyncProducerFromClient(client)...defer producer.Close()topic := "topic-test"for i := 0; i <= 10; i++ {text := fmt.Sprintf("message %08d", i)partition, offset, err := producer.SendMessage(&sarama.ProducerMessage{Topic: topic,Key: nil,Value: sarama.StringEncoder(text)})...log.Println("send message success, partition = ", partition, " offset = ", offset)}}
可以看出同步发送跟异步发送的过程是很相似的。
不同的地方在于,同步生产者发送消息,使用的不是channel,并且SendMessage方法有三个返回的值,分别为这条消息的被发送到了哪个partition,处于哪个offset,是否有error。
也就是说,只有在消息成功的发送并写入了broker,才会有返回值。
2. 配置
2.1 默认配置
我们顺着源码看一下这一行:
config := sarama.NewConfig()
可以看到Sarama已经返回了一个默认的config了:
// NewConfig returns a new configuration instance with sane defaults.func NewConfig() *Config {c := &Config{}c.Producer.MaxMessageBytes = 1000000c.Producer.RequiredAcks = WaitForLocalc.Producer.Timeout = 10 * time.Second...}
2.2 可选配置
我们来看看Config这个结构体,里面有哪些配置项是允许用户自定义的。
因为实在是太长了,限于篇幅以及作者的学识,在这篇文章中不能一一讲解,所以在这篇文章只会选取部分生产者相关的配置进行讲解。
但是无论是Golang客户端,还是Java客户端,都不重要,你只需要知道哪些参数对于你的生产者的生产速度、消息的可靠性等有关系就可以了。
// Config is used to pass multiple configuration options to Sarama's constructors.type Config struct {Admin struct {...}Net struct {...}Metadata struct {...}Producer struct {...}Consumer struct {...}ClientID string...}
我们可以看出,关于Sarama的配置,分成了很多个部分,我们来具体看一看Producer的这部分。
2.3 重要的生产者参数
在这里我打算介绍一部分我个人认为比较重要的生产者参数。
MaxMessageBytes int
这个参数影响了一条消息的最大字节数,默认是1000000。但是注意,这个参数必须要小于broker中的 message.max.bytes。
RequiredAcks RequiredAcks
这个参数影响了消息需要被多少broker写入之后才返回。取值可以是0、1、-1,分别代表了不需要等待broker确认才返回、需要分区的leader确认后才返回、以及需要分区的所有副本确认后返回。
Partitioner PartitionerConstructor
这个是分区器。Sarama默认提供了几种分区器,如果不指定默认使用Hash分区器。
Retry
这个参数代表了重试的次数,以及重试的时间,主要发生在一些可重试的错误中。
Flush
用于设置将消息打包发送,简单来讲就是每次发送消息到broker的时候,不是生产一条消息就发送一条消息,而是等消息累积到一定的程度了,再打包发送。所以里面含有两个参数。一个是多少条消息触发打包发送,一个是累计的消息大小到了多少,然后发送。
2.4 幂等生产者
在聊幂等生产者之前,我们先来看看生产者中另外一个很重要的参数:
MaxOpenRequests int
这个参数代表了允许没有收到acks而可以同时发送的最大batch数。
Idempotent bool
用于幂等生产者,当这一项设置为true的时候,生产者将保证生产的消息一定是有序且精确一次的。
为什么会需要这个选项呢?
当MaxOpenRequests这个参数配置大于1的时候,代表了允许有多个请求发送了还没有收到回应。假设此时的重试次数也设置为了大于1,当同时发送了2个请求,如果第一个请求发送到broker中,broker写入失败了,但是第二个请求写入成功了,那么客户端将重新发送第一个消息的请求,这个时候会造成乱序。
又比如当第一个请求返回acks的时候,因为网络原因,客户端没有收到,所以客户端进行了重发,这个时候就会造成消息的重复。
所以,幂等生产者就是为了保证消息发送到broker中是有序且不重复的。
消息的有序可以通过MaxOpenRequests设置为1来保证,这个时候每个消息必须收到了acks才能发送下一条,所以一定是有序的,但是不能够保证不重复。
而且当MaxOpenRequests设置为1的时候,吞吐量不高。
注意,当启动幂等生产者的时候,Retry次数必须要大于0,ack必须为all。
在Java客户端中,允许MaxOpenRequests小于等于5。
但是在Sarama中有一个很奇怪的地方我也没有研究明白,我们直接看一看这部分的代码:
if c.Producer.Idempotent {if !c.Version.IsAtLeast(V0_11_0_0) {return ConfigurationError("Idempotent producer requires Version >= V0_11_0_0")}if c.Producer.Retry.Max == 0 {return ConfigurationError("Idempotent producer requires Producer.Retry.Max >= 1")}if c.Producer.RequiredAcks != WaitForAll {return ConfigurationError("Idempotent producer requires Producer.RequiredAcks to be WaitForAll")}if c.Net.MaxOpenRequests > 1 {return ConfigurationError("Idempotent producer requires Net.MaxOpenRequests to be 1")}}
这一部分第一项是版本号,没问题,第二第三项是Retry和Acks,也没有问题。问题在于第四项,这里的MaxOpenRequests参数,我想应该等同于Java客户端中的MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION,按照Java客户端中的配置,应该是这个参数小于等于5,即可保证幂等,但是这里必须得设置为1。
检查了Sarama的Issue,有开发者提出了这个问题,但是目前作者还没有打算解决。
3 broker
在这一节的内容中,我将会从代码的层面介绍 Sarama 生产者发送消息的全过程。但是因为代码很多,我将会省略一些内容,包括一些错误处理、重试等。
这些都很重要,也不应该被省略。但是因为篇幅有限,我只能介绍最核心的发送消息这一部分的内容。
我会在贴代码之前,大概的说一下这段代码的思路。随后,我会在代码中加入一些注释,来更详细的进行解释。
然后我们开始吧!
producer, err := sarama.NewAsyncProducer([]string{"localhost:9092"}, config)
一切都从这么一行开始讲起。
我们进去看看。
在这里其实就只有两个部分,先是通过地址和配置,构建一个 client 。
func NewAsyncProducer(addrs []string, conf *Config) (AsyncProducer, error) {// 构建clientclient, err := NewClient(addrs, conf)if err != nil {return nil, err}// 构建AsyncProducerreturn newAsyncProducer(client)}
3.1 Client的创建
在创建 Client 的过程中,先构建一个 client 结构体。
里面的参数我们先不管,等用到了再进行解释。
然后创建完之后,刷新元数据,并且启动一个协程,在后台进行刷新。
func NewClient(addrs []string, conf *Config) (Client, error) {...// 构建一个clientclient := &client{conf: conf,closer: make(chan none),closed: make(chan none),brokers: make(map[int32]*Broker),metadata: make(map[string]map[int32]*PartitionMetadata),metadataTopics: make(map[string]none),cachedPartitionsResults: make(map[string][maxPartitionIndex][]int32),coordinators: make(map[string]int32),}// 把用户输入的broker地址作为“种子broker”增加到seedBrokers中// 随后客户端会根据已有的broker地址,自动刷新元数据,以获取更多的broker地址// 所以称之为种子random := rand.New(rand.NewSource(time.Now().UnixNano()))for _, index := range random.Perm(len(addrs)) {client.seedBrokers = append(client.seedBrokers, NewBroker(addrs[index]))}...// 启动协程在后台刷新元数据go withRecover(client.backgroundMetadataUpdater)return client, nil}
3.2 元数据的更新
后台更新元数据的设计其实很简单,利用一个 ticker ,按时对元数据进行更新,直到 client 关闭。
这里先提一下我们说的元数据,有哪些内容。
你可以简单的理解为包含了所有 broker 的地址(因为 broker 可能新增,也可能减少),以及包含了哪些 topic ,这些 topic 有哪些 partition 等。
func (client *client) backgroundMetadataUpdater() {// 按照配置的时间更新元数据ticker := time.NewTicker(client.conf.Metadata.RefreshFrequency)defer ticker.Stop()// 循环获取channel,判断是执行更新操作还是终止for {select {case <-ticker.C:if err := client.refreshMetadata(); err != nil {Logger.Println("Client background metadata update:", err)}case <-client.closer:return}}}
然后我们继续来看看 client.refreshMetadata() 这个方法,这个方法是判断了一下需要刷新哪些主题的元数据,还是说全部主题的元数据。
然后我们继续。
在这里也还没有涉及到具体的更新操作。我们看 tryRefreshMetadata 这个方法的参数可以得知,在这里我们设置了需要刷新元数据的主题,重试的次数,超时的时间。
func (client *client) RefreshMetadata(topics ...string) error {deadline := time.Time{}if client.conf.Metadata.Timeout > 0 {deadline = time.Now().Add(client.conf.Metadata.Timeout)}// 设置参数return client.tryRefreshMetadata(topics, client.conf.Metadata.Retry.Max, deadline)}
然后终于来到了tryRefreshMetadata这个方法。
在这个方法中,会选取已经存在的broker,构造获取元数据的请求。
在收到回应后,如果不存在任何的错误,就将这些元数据用于更新客户端。
func (client *client) tryRefreshMetadata(topics []string, attemptsRemaining int, deadline time.Time) error {...broker := client.any()for ; broker != nil && !pastDeadline(0); broker = client.any() {...req := &MetadataRequest{Topics: topics,// 是否允许创建不存在的主题AllowAutoTopicCreation: allowAutoTopicCreation}response, err := broker.GetMetadata(req)switch err.(type) {case nil:allKnownMetaData := len(topics) == 0// 对元数据进行更新shouldRetry, err := client.updateMetadata(response, allKnownMetaData)if shouldRetry {Logger.Println("client/metadata found some partitions to be leaderless")return retry(err)}return errcase ......}}
然后我们继续往下看看当客户端拿到了 response 之后,是如何更新的。
首先,先对本地保存 broker 进行更新。
然后,对 topic 进行更新,以及这个 topic 下面的那些 partition 。
func (client *client) updateMetadata(data *MetadataResponse, allKnownMetaData bool) (retry bool, err error) {...// 假设返回了新的broker id,那么保存这些新的broker,这意味着增加了broker、或者下线的broker重新上线了// 如果返回的id我们已经保存了,但是地址变化了,那么更新地址// 如果本地保存的一些id没有返回,说明这些broker下线了,那么删除他们client.updateBroker(data.Brokers)// 然后对topic也进行元数据的更新// 主要是更新topic以及topic对应的partitionfor _, topic := range data.Topics {...// 更新每个topic以及对应的partitionclient.metadata[topic.Name] = make(map[int32]*PartitionMetadata, len(topic.Partitions))for _, partition := range topic.Partitions {client.metadata[topic.Name][partition.ID] = partition...}}
至此,我们元数据的更新就说完了。
下面我们来说一说在更新元数据之前,broker是如何建立连接的,以及请求是如何发送出去,又是如何被broker接收的。
3.3 与Broker建立连接
让我们回到 tryRefreshMetadata 这个方法中。
这个方法里面有这么一行代码:
broker := client.any()
我们进去看看。
在这个方法里, 如果 seedBrokers 存在,那么就打开它,否则的话打开其他的broker。
注意,这里提到的其他的broker,可能是在刷新元数据的时候,获取到的。这就跟上面的内容联系在一起了。
func (client *client) any() *Broker {...if len(client.seedBrokers) > 0 {_ = client.seedBrokers[0].Open(client.conf)return client.seedBrokers[0]}// 不保证一定是按顺序的for _, broker := range client.brokers {_ = broker.Open(client.conf)return broker}return nil}
然后再让我们看看 Open方法做了什么。
Open方法异步的建立了一个tcp连接,然后创建了一个缓冲大小为MaxOpenRequests的channel。
这个名为 responses 的 channel ,用于接收从 broker发送回来的消息。
其实在 broker 中,用于发送消息跟接收消息的 channel 都设置成了这个大小。
MaxOpenRequests 这个参数你可以理解为是Java客户端中的max.in.flight.requests.per.connection。
然后,又启动了一个协程,用于接收消息。
func (b *Broker) Open(conf *Config) error {if conf == nil {conf = NewConfig()}...go withRecover(func() {...dialer := conf.getDialer()b.conn, b.connErr = dialer.Dial("tcp", b.addr)...b.responses = make(chan responsePromise, b.conf.Net.MaxOpenRequests-1)...go withRecover(b.responseReceiver)})
3.4 从Broker接收响应
我们来看看 responseReceiver 是怎么工作的。
其实很容易理解,当 broker 收到一个 response 的时候,先解析消息的头部,然后再解析消息的内容。并把这些内容写进 response 的 packets 中。
func (b *Broker) responseReceiver() {for response := range b.responses {...// 先根据Header的版本读取对应长度的Headervar headerLength = getHeaderLength(response.headerVersion)header := make([]byte, headerLength)bytesReadHeader, err := b.readFull(header)decodedHeader := responseHeader{}err = versionedDecode(header, &decodedHeader, response.headerVersion)...// 解析具体的内容buf := make([]byte, decodedHeader.length-int32(headerLength)+4)bytesReadBody, err := b.readFull(buf)// 省略了一些错误处理,总之,如果发生了错误,就把错误信息写进 response.errors 中response.packets <- buf}}
其实接收响应这部分的代码逻辑很容易理解,就是当 response 这个 channel 有了消息,就读取,然后将读取到的内容写进 response 中。
那么你可能会有一个问题,什么时候才会往response 这个 channel 发送消息呢?
很容易可以猜到,当我们发送了消息给 broker ,就应该要通知 receiver ,准备接受消息了。
既然如此,我们继续刚刚刷新元数据的部分,看看 sarama 是如何把消息发送出去的。
3.5 发送与接受消息
我们回到这一行代码:
response, err := broker.GetMetadata(req)
我们直接进去,发现在这里构造了一个接受返回信息的结构体,然后调用了sendAndReceive方法。
func (b *Broker) GetMetadata(request *MetadataRequest) (*MetadataResponse, error) {response := new(MetadataResponse)err := b.sendAndReceive(request, response)if err != nil {return nil, err}return response, nil}
我们继续往下。
在这里我们可以看到,先是调用了send方法,然后返回了一个promise。并且当有消息写入这个promise的时候,就得到了结果。
而且回想一下我们在receiver中,是不是把获取到的 response 写进了 packets ,把错误结果写进了 errors 呢,跟这里是一致的对吧?
func (b *Broker) sendAndReceive(req protocolBody, res protocolBody) error {responseHeaderVersion := int16(-1)if res != nil {responseHeaderVersion = res.headerVersion()}promise, err := b.send(req, res != nil, responseHeaderVersion)if err != nil {return err}if promise == nil {return nil}// 这里的promise,是上面send方法返回的select {case buf := <-promise.packets:return versionedDecode(buf, res, req.version())case err = <-promise.errors:return err}}
带着这个想法,我们看看 send 方法做了什么事。
这个地方很重要,也是我认为 Sarama 设计的特别巧妙的一个地方。
在send方法中,把需要发送的消息通过与broker的tcp连接,同步发送到broker中。
然后构建了一个responsePromise类型的channel,然后直接将这个结构体丢进这个channel中。然后回想一下,我们在responseReceiver这个方法中,不断消费接收到的response。
此时在responseReceiver中,收到了send方法传递的responsePromise,他就会通过conn来读取数据,然后将数据写入这个responsePromise的packets中,或者将错误信息写入errors中。
而此时,再看看send方法,他返回了这个responsePromise的指针。所以,sendAndReceive方法就在等待这个responsePromise内的packets或者errors的channel被写入数据。当responseReceiver接收到了响应并且写入数据的时候,packets或者errors就会被写入消息。
func (b *Broker) send(rb protocolBody, promiseResponse bool, responseHeaderVersion int16) (*responsePromise, error) {...// 将请求的内容封装进 request ,然后发送到Broker中// 注意一下这里的 b.write(buf)// 里面做了 b.conn.Write(buf) 这件事情req := &request{correlationID: b.correlationID, clientID: b.conf.ClientID, body: rb}buf, err := encode(req, b.conf.MetricRegistry)bytes, err := b.write(buf)...// 如果我们的response为nil,也就是说当不需要response的时候,是不会放进inflight发送队列的if !promiseResponse {// Record request latency without the responseb.updateRequestLatencyAndInFlightMetrics(time.Since(requestTime))return nil, nil}// 构建一个接收响应的 channel ,返回这个channel的指针// 这个 channel 内部包含了两个 channel,一个用来接收响应,一个用来接收错误promise := responsePromise{requestTime, req.correlationID, responseHeaderVersion, make(chan []byte), make(chan error)}b.responses <- promise// 这里返回指针特别的关键,是把消息的发送跟消息的接收联系在一起了return &promise, nil}
让我们来用一张图说明一下上面这个发送跟接收的过程:
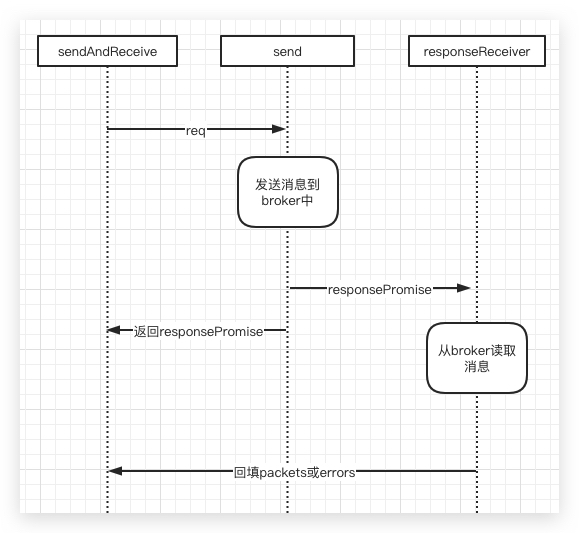
这一段比较绕,但这也是Sarama发送与接受消息的核心内容,希望我的解释能够让你理解:)
4 AsyncProcuder
在上一节中,我们已经分析了client的构造全过程,并且在构造client刷新元数据的时候,也解释了sarama是如何发送消息以及接受消息的。
在这一节中,我打算解释一下AsyncProcuder是如何发送消息的。
因为有了上一节的铺垫,这一节的内容应该会比较容易理解。
我们从newAsyncProducer(client)这一行开始讲起。
我们先说说input:make(chan *ProducerMessage),这个事关我们的消息发送。注意到这个channel是没有缓冲的。
也就是说当我们发送一条消息到input中的时候,此时发送方会阻塞,这说明了之后的操作必须不能够被阻塞,否则会影响消息的发送效率。
然后其他字段我们先不管,后面用到了我们再提。
func newAsyncProducer(client Client) (AsyncProducer, error) {...p := &asyncProducer{client: client,conf: client.Config(),errors: make(chan *ProducerError),input: make(chan *ProducerMessage),successes: make(chan *ProducerMessage),retries: make(chan *ProducerMessage),brokers: make(map[*Broker]*brokerProducer),brokerRefs: make(map[*brokerProducer]int),txnmgr: txnmgr,}go withRecover(p.dispatcher)go withRecover(p.retryHandler)}
4.1 dispatcher
我们往下看看下面协程启动的go withRecover(p.dispatcher)。
在这个方法中,首先创建了一个以Topic为key的map,这个map的value是无缓冲的channel。
到这里我们很容易可以推测得出,当通过input发送一条消息的时候,消息会到dispatcher这里,被分配到各个Topic中。
注意,在这个时候,channel还是无缓冲的,所以我们可以推测下一步的操作,依旧是无阻塞的。
func (p *asyncProducer) dispatcher() {handlers := make(map[string]chan<- *ProducerMessage)...for msg := range p.input {...// 拦截器for _, interceptor := range p.conf.Producer.Interceptors {msg.safelyApplyInterceptor(interceptor)}...// 找到这个Topic对应的Handlerhandler := handlers[msg.Topic]if handler == nil {// 如果此时还不存在这个Topic对应的Handler,那么创建一个// 虽然说他叫Handler,但他其实是一个无缓冲的handler = p.newTopicProducer(msg.Topic)handlers[msg.Topic] = handler}// 然后把这条消息写进这个Handler中handler <- msg}}
然后让我们来handler = p.newTopicProducer(msg.Topic)这一行的代码。
在这里创建了一个缓冲大小为ChannelBufferSize的channel,用于存放发送到这个主题的消息。
然后创建了一个topicProducer,在这个时候你可以认为消息已经交付给各个topic的topicProducer了。
func (p *asyncProducer) newTopicProducer(topic string) chan<- *ProducerMessage {input := make(chan *ProducerMessage, p.conf.ChannelBufferSize)tp := &topicProducer{parent: p,topic: topic,input: input,breaker: breaker.New(3, 1, 10*time.Second),handlers: make(map[int32]chan<- *ProducerMessage),partitioner: p.conf.Producer.Partitioner(topic),}go withRecover(tp.dispatch)return input}
4.2 topicDispatch
然后我们来看看go withRecover(tp.dispatch)这一行代码。
同样是启动了一个协程,来处理消息。
也就是说,到了这一步,对于每一个Topic,都有一个协程来处理消息。
在这个dispatch()方法中,也同样的接收到一条消息,就会去找这条消息所在的分区的channel,然后把消息写进去。
func (tp *topicProducer) dispatch() {for msg := range tp.input {...// 同样是找到这条消息所在的分区对应的channel,然后把消息丢进去handler := tp.handlers[msg.Partition]if handler == nil {handler = tp.parent.newPartitionProducer(msg.Topic, msg.Partition)tp.handlers[msg.Partition] = handler}handler <- msg}}
4.3 PartitionDispatch
我们进tp.parent.newPartitionProducer(msg.Topic, msg.Partition)这里看看。
你可以发现partitionProducer跟topicProducer是很像的。
其实他们就是代表了一条消息的分发,从producer到topic到partition。
注意,这里面的channel缓冲大小,也是ChannelBufferSize。
func (p *asyncProducer) newPartitionProducer(topic string, partition int32) chan<- *ProducerMessage {input := make(chan *ProducerMessage, p.conf.ChannelBufferSize)pp := &partitionProducer{parent: p,topic: topic,partition: partition,input: input,breaker: breaker.New(3, 1, 10*time.Second),retryState: make([]partitionRetryState, p.conf.Producer.Retry.Max+1),}go withRecover(pp.dispatch)return input}
4.4 partitionProducer
到了这一步,我们再来看看消息到了每个partition所在的channel,是如何处理的。
其实在这一步中,主要是做一些错误处理之类的,然后把消息丢进brokerProducer。
可以理解为这一步是业务逻辑层到网络IO层的转变,在这之前我们只关心消息去到了哪个分区,而在这之后,我们需要找到这个分区所在的broker的地址,并使用之前已经建立好的TCP连接,发送这条消息。
func (pp *partitionProducer) dispatch() {// 找到这个主题和分区的leader所在的brokerpp.leader, _ = pp.parent.client.Leader(pp.topic, pp.partition)// 如果此时找到了这个leaderif pp.leader != nil {pp.brokerProducer = pp.parent.getBrokerProducer(pp.leader)pp.parent.inFlight.Add(1)// 发送一条消息来表示同步pp.brokerProducer.input <- &ProducerMessage{Topic: pp.topic, Partition: pp.partition, flags: syn}}...// 各种异常情况// 然后把消息丢进brokerProducer中pp.brokerProducer.input <- msg}
4.5 brokerProducer
到了这里,大概算是整个发送流程最后的一个步骤了。
我们来看看pp.parent.getBrokerProducer(pp.leader)这行代码里面的内容。
其实就是找到asyncProducer中的brokerProducer,如果不存在,则创建一个。
func (p *asyncProducer) getBrokerProducer(broker *Broker) *brokerProducer {p.brokerLock.Lock()defer p.brokerLock.Unlock()bp := p.brokers[broker]if bp == nil {bp = p.newBrokerProducer(broker)p.brokers[broker] = bpp.brokerRefs[bp] = 0}p.brokerRefs[bp]++return bp}
那我们就来看看brokerProducer是怎么创建出来的。
看这个方法中启动的第二个协程,我们可以推测bridge这个channel收到消息后,会把收到的消息打包成一个request,然后调用Produce方法。
并且,将返回的结果的指针地址,写进response中。
然后构造好brokerProducerResponse,并且写入responses中。
func (p *asyncProducer) newBrokerProducer(broker *Broker) *brokerProducer {var (input = make(chan *ProducerMessage)bridge = make(chan *produceSet)responses = make(chan *brokerProducerResponse))bp := &brokerProducer{parent: p,broker: broker,input: input,output: bridge,responses: responses,stopchan: make(chan struct{}),buffer: newProduceSet(p),currentRetries: make(map[string]map[int32]error),}go withRecover(bp.run)// minimal bridge to make the network response `select`ablego withRecover(func() {for set := range bridge {request := set.buildRequest()response, err := broker.Produce(request)responses <- &brokerProducerResponse{set: set,err: err,res: response,}}close(responses)})if p.conf.Producer.Retry.Max <= 0 {bp.abandoned = make(chan struct{})}return bp}
让我们再来看看broker.Produce(request)这一行代码。
是不是很熟悉呢,我们在client部分讲到的sendAndReceive方法。
而且我们可以发现,如果我们设置了需要Acks,就会返回一个response;如果没设置,那么消息发出去之后,就不管了。
此时在获取了response,并且填入了response的内容后,返回这个response的内容。
func (b *Broker) Produce(request *ProduceRequest) (*ProduceResponse, error) {var (response *ProduceResponseerr error)if request.RequiredAcks == NoResponse {err = b.sendAndReceive(request, nil)} else {response = new(ProduceResponse)err = b.sendAndReceive(request, response)}if err != nil {return nil, err}return response, nil}
至此,Sarama生产者相关的内容就介绍完毕了。
写在最后
这一篇写的实在是有些久了。
主要是作者这段时间实在是太忙了,还没有完全平衡好目前的学习工作和生活,导致每天花在学习上的时间不多,效率也不高。
另外就是网上我也没有查到有Sarama相关的解析,都是一些API的调用。因为作者恰好开始学习Kafka,为了更好地了解生产者的每一个参数,我选择去研究生产者客户端。
但是,因为作者源码阅读能力实在是有限,在这个过程中很有可能会有一些错误的理解。所以当你发现了一些违和的地方,也请不吝指教,谢谢你!
再次感谢你能看到这里!
PS:如果有其他的问题,也可以在公众号找到我,欢迎来找我玩~

Kafka入门(3):Sarama生产者是如何工作的的更多相关文章
- 《OD大数据实战》Kafka入门实例
官网: 参考文档: Kafka入门经典教程 Kafka工作原理详解 一.安装zookeeper 1. 下载zookeeper-3.4.5-cdh5.3.6.tar.gz 下载地址为: http://a ...
- Kafka 入门三问
目录 1 Kafka 是什么? 1.1 背景 1.2 定位 1.3 产生的原因 1.4 Kafka 有哪些特征 消息和批次 模式 主题和分区 生产者和消费者 broker 和 集群 1.5 Kafka ...
- 【转帖】Kafka入门介绍
Kafka入门介绍 https://www.cnblogs.com/swordfall/p/8251700.html 最近在看hdoop的hdfs 以及看了下kafka的底层存储,发现分布式的技术基本 ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- kafka 入门
李克华 云计算高级群: 292870151 195907286 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch kafka入门:简介.使用场景.设计原理.主要配置及集群搭 ...
- Kafka入门介绍
1. Kafka入门介绍 1.1 Apache Kafka是一个分布式的流平台.这到底意味着什么? 我们认为,一个流平台具有三个关键能力: ① 发布和订阅消息.在这方面,它类似一个消息队列或企业消息系 ...
- Kafka入门 --安装和简单实用
一.安装Zookeeper 参考: Zookeeper的下载.安装和启动 Zookeeper 集群搭建--单机伪分布式集群 二.下载Kafka 进入http://kafka.apache.org/do ...
- Kafka技术内幕 读书笔记之(一) Kafka入门
在0.10版本之前, Kafka仅仅作为一个消息系统,主要用来解决应用解耦. 异步消息 . 流量削峰等问题. 在0.10版本之后, Kafka提供了连接器与流处理的能力,它也从分布式的消息系统逐渐成为 ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
随机推荐
- PHP date_create_from_format() 函数
------------恢复内容开始------------ 实例 返回一个根据指定格式进行格式化的新的 DateTime 对象: <?php$date=date_create_from_for ...
- 牛客练习赛63 牛牛的斐波那契字符串 矩阵乘法 KMP
LINK:牛牛的斐波那契字符串 虽然sb的事实没有改变 但是 也不会改变. 赛时 看了E和F题 都不咋会写 所以弃疗了. 中午又看了一遍F 发现很水 差分了一下就过了. 这是下午和古队长讨论+看题解的 ...
- CF掉分日记 6.6 6.8
---恢复内容开始--- 写的效果依旧不好 还没写完前四题比赛就结束了 而且这些普及组的题目 我大多还是缺少简单算法的灵性 总是把问题搞复杂化. 6.5 A 第一道题非常水 简单分析发现是一个快速幂的 ...
- Maven 配置编译版本
pom.xml <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</gro ...
- SpringMvc响应数据和结果视图
响应数据和结果视图 返回值分类 字符串 controller 方法返回字符串可以指定逻辑视图名,通过视图解析器解析为物理视图地址. //指定逻辑视图名,经过视图解析器解析为 jsp 物理路径:/WEB ...
- SAFe必备——提高团队敏捷性
规模化敏捷之于项目群,就像Scrum之于敏捷团队.为了创建高质量业务解决方案,企业需要提高自身能力,提升团队和技术敏捷性,实现真正的规模化敏捷. 敏捷发布火车 实现团队和技术敏捷性,首先需要敏捷团队围 ...
- SpringCloud系列之服务容错保护Netflix Hystrix
1. 什么是雪崩效应? 微服务环境,各服务之间是经常相互依赖的,如果某个不可用,很容易引起连锁效应,造成整个系统的不可用,这种现象称为服务雪崩效应. 如图,引用国外网站的图例:https://www. ...
- 1、迭代器 Iterator模式 一个一个遍历 行为型设计模式
1.Iterator模式 迭代器(iterator)有时又称游标(cursor)是程序设计的软件设计模式,可在容器(container,例如链表或者阵列)上遍访的接口,设计人员无需关心容器的内容. I ...
- Vue老项目支持Webpack打包
1.老的vue项目支持webpack打包 最近在学习Vue.js.版本是2.6,webpack的版本也相对较老,是2.1.0版本.项目脚手架只配置了npm run dev和npm run build. ...
- 使用 .NET Core 3.x 构建 RESTFUL Api
准备工作:在此之前你需要了解关于.NET .Core的基础,前面几篇文章已经介绍:https://www.cnblogs.com/hcyesdo/p/12834345.html 首先需要明确一点的就是 ...