Tensorflow-交叉熵&过拟合
交叉熵
二次代价函数

原理

缺陷
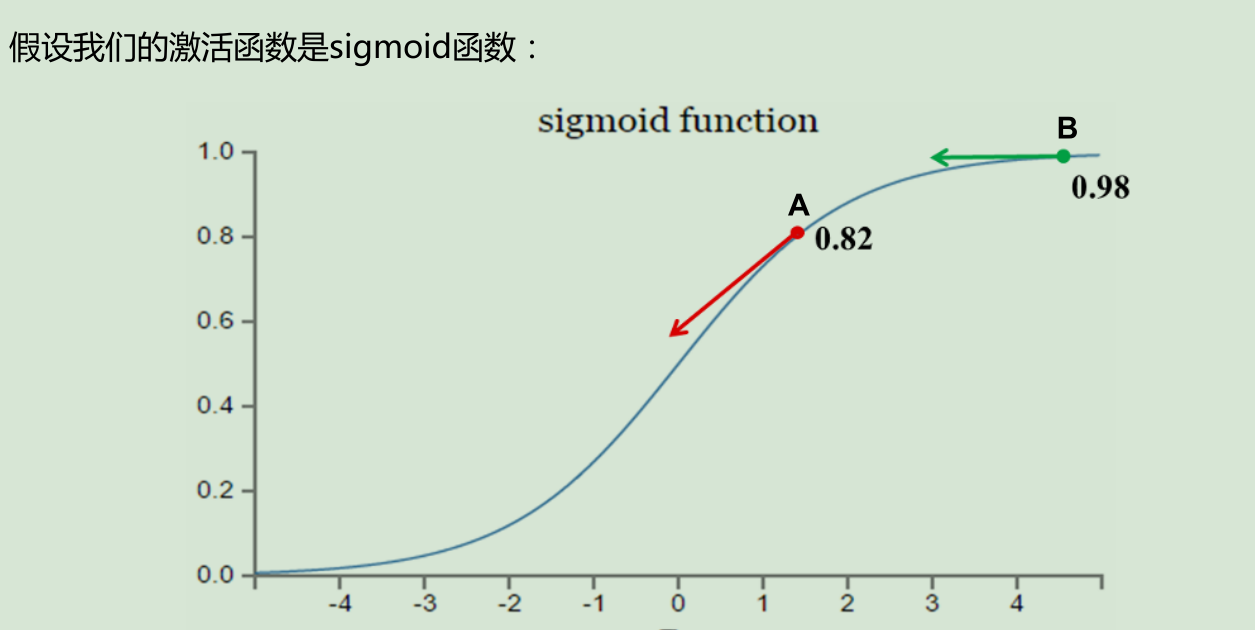
假如我们目标是收敛到0。A点为0.82离目标比较近,梯度比较大,权值调整比较大。B点为0.98离目标比较远,梯度比较小,权值调整比较小。调整方案不合理。
交叉熵代价函数(cross-entropy)
换一个思路,我们不改变激活函数,而是改变代价函数,改用交叉熵代价函数:

原理

用法

实战
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
tf.compat.v1.disable_eager_execution()
import numpy as np #载入数据集
mnist=input_data.read_data_sets("MNIST_data",one_hot=True) #每个批次大小
batch_size=100
#计算一共有多少个批次
n_bath=mnist.train.num_examples // batch_size
print(n_bath)
#定义两个placeholder
x=tf.compat.v1.placeholder(tf.float32,[None,784])
y=tf.compat.v1.placeholder(tf.float32,[None,10]) #创建一个简单的神经网络
W=tf.Variable(tf.zeros([784,10]))
b=tf.Variable(tf.zeros([10]))
prediction=tf.nn.softmax(tf.matmul(x,W)+b) #交叉熵函数
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
#梯度下降
train_step=tf.compat.v1.train.GradientDescentOptimizer(0.2).minimize(loss) #初始化变量
init=tf.compat.v1.global_variables_initializer() #结果存放在一个布尔型列表中
#返回的是一系列的True或False argmax返回一维张量中最大的值所在的位置,对比两个最大位置是否一致
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1)) #求准确率
#cast:将布尔类型转换为float,将True为1.0,False为0,然后求平均值
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.compat.v1.Session() as sess:
sess.run(init)
for epoch in range(21):
for batch in range(n_bath):
#获得一批次的数据,batch_xs为图片,batch_ys为图片标签
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
#进行训练
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
#训练完一遍后,测试下准确率的变化 acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
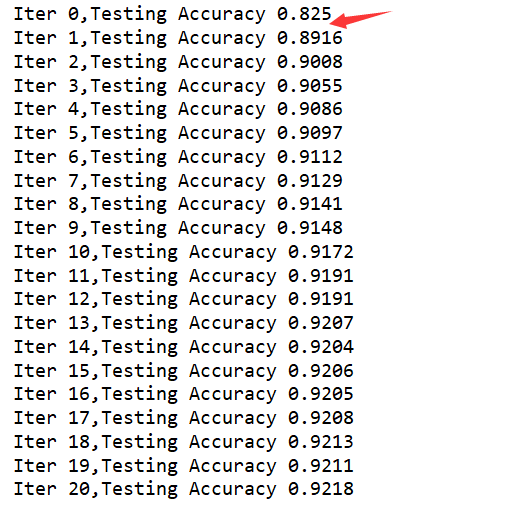
print("Iter "+str(epoch)+",Testing Accuracy "+str(acc))
输出:明显可以看到有了巨大的变化
拟合

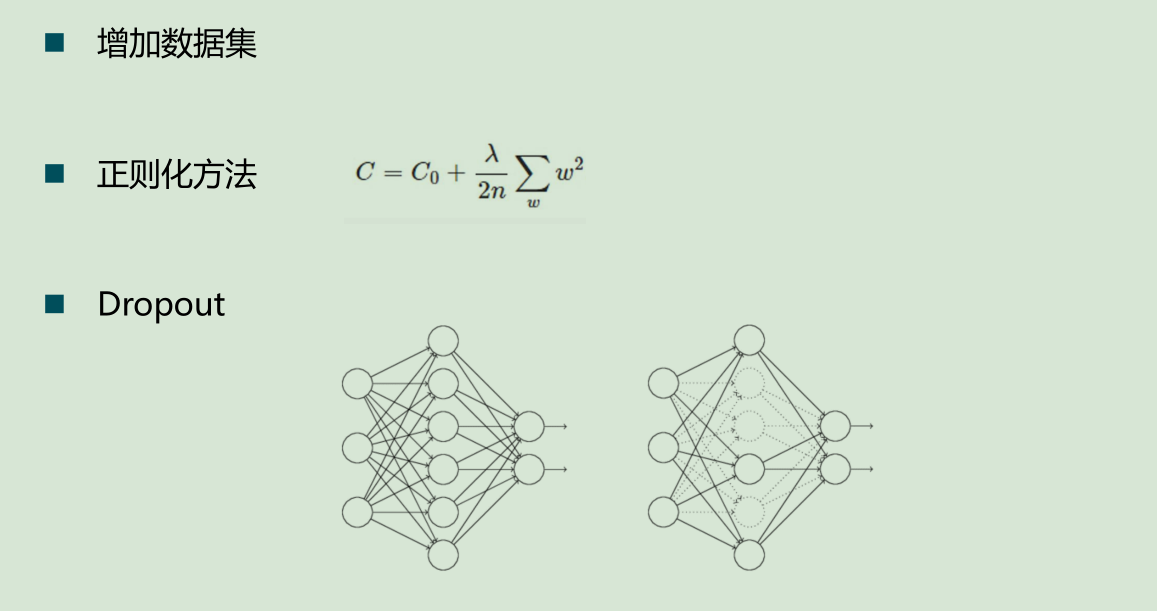
防止过拟合
代码
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
tf.compat.v1.disable_eager_execution()
import numpy as np #载入数据集
mnist=input_data.read_data_sets("MNIST_data",one_hot=True) # 批次的大小
batch_size = 128
n_batch = mnist.train.num_examples // batch_size x = tf.compat.v1.placeholder(tf.float32, [None,784])
y = tf.compat.v1.placeholder(tf.float32, [None, 10])
keep_prob = tf.compat.v1.placeholder(tf.float32) # 创建神经网络
W1 = tf.Variable(tf.compat.v1.truncated_normal([784,2000],stddev=0.1))
b1 = tf.Variable(tf.zeros([1, 2000]))
# 激活层
layer1 = tf.nn.relu(tf.matmul(x,W1) + b1)
# drop层
layer1 = tf.nn.dropout(layer1,keep_prob) # 第二层
W2 = tf.Variable(tf.compat.v1.truncated_normal([2000,500],stddev=0.1))
b2 = tf.Variable(tf.zeros([1, 500]))
layer2 = tf.nn.relu(tf.matmul(layer1,W2) + b2)
layer2 = tf.nn.dropout(layer2,keep_prob) # 第三层
W3 = tf.Variable(tf.compat.v1.truncated_normal([500,10],stddev=0.1))
b3 = tf.Variable(tf.zeros([1,10]))
prediction = tf.nn.sigmoid(tf.matmul(layer2,W3) + b3) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction)) # 梯度下降法
# train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)#得到97的正确率
train_step = tf.compat.v1.train.AdadeltaOptimizer(0.1).minimize(loss) # 初始化变量
init = tf.compat.v1.global_variables_initializer() prediction_2 = tf.nn.softmax(prediction)
# 得到一个布尔型列表,存放结果是否正确
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(prediction_2,1)) #argmax 返回一维张量中最大值索引 # 求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) # 把布尔值转换为浮点型求平均数 with tf.compat.v1.Session() as sess:
sess.run(init)
for epoch in range(100):
for batch in range(n_batch):
# 获得批次数据
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x:batch_xs, y:batch_ys, keep_prob:0.8})
test_acc = sess.run(accuracy, feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0} )
train_acc = sess.run(accuracy, feed_dict={x: mnist.train.images, y: mnist.train.labels, keep_prob: 1.0})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) + ",Train Accuracy " + str(train_acc))
Tensorflow-交叉熵&过拟合的更多相关文章
- 深度学习原理与框架-Tensorflow卷积神经网络-卷积神经网络mnist分类 1.tf.nn.conv2d(卷积操作) 2.tf.nn.max_pool(最大池化操作) 3.tf.nn.dropout(执行dropout操作) 4.tf.nn.softmax_cross_entropy_with_logits(交叉熵损失) 5.tf.truncated_normal(两个标准差内的正态分布)
1. tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') # 对数据进行卷积操作 参数说明:x表示输入数据,w表示卷积核, stride ...
- TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵
TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵 神经元模型:用数学公式比表示为:f(Σi xi*wi + b), f为激活函数 神经网络 是以神经元为基本单位构成的 激 ...
- 『TensorFlow』分类问题与两种交叉熵
关于categorical cross entropy 和 binary cross entropy的比较,差异一般体现在不同的分类(二分类.多分类等)任务目标,可以参考文章keras中两种交叉熵损失 ...
- 机器学习之路:tensorflow 深度学习中 分类问题的损失函数 交叉熵
经典的损失函数----交叉熵 1 交叉熵: 分类问题中使用比较广泛的一种损失函数, 它刻画两个概率分布之间的距离 给定两个概率分布p和q, 交叉熵为: H(p, q) = -∑ p(x) log q( ...
- TF Boys (TensorFlow Boys ) 养成记(五): CIFAR10 Model 和 TensorFlow 的四种交叉熵介绍
有了数据,有了网络结构,下面我们就来写 cifar10 的代码. 首先处理输入,在 /home/your_name/TensorFlow/cifar10/ 下建立 cifar10_input.py,输 ...
- Tensorflow手写数字识别(交叉熵)练习
# coding: utf-8import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data #pr ...
- 5 TensorFlow实战Google深度学习框架一书中的错误两处(交叉熵定义有误)
第一处: 书中62页定义的交叉熵函数定义有误,虽然这个所谓交叉熵的数值能够减少,但是是不能提升预测性能的,因为定义就错了. 我已经将预测过程可视化,直接将交叉熵改为我的,或者用原书的,就可以看到预测结 ...
- TensorFlow 实战(一)—— 交叉熵(cross entropy)的定义
对多分类问题(multi-class),通常使用 cross-entropy 作为 loss function.cross entropy 最早是信息论(information theory)中的概念 ...
- 经典损失函数:交叉熵(附tensorflow)
每次都是看了就忘,看了就忘,从今天开始,细节开始,推一遍交叉熵. 我的第一篇CSDN,献给你们(有错欢迎指出啊). 一.什么是交叉熵 交叉熵是一个信息论中的概念,它原来是用来估算平均编码长度的.给定两 ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数
import tensorflow as tf # 1. sparse_softmax_cross_entropy_with_logits样例. # 假设词汇表的大小为3, 语料包含两个单词" ...
随机推荐
- 走进 Python 类的内部
这篇文章和大家一起聊一聊 Python 3.8 中类和对象背后的一些概念和实现原理,主要尝试解释 Python 类和对象属性的存储,函数和方法,描述器,对象内存占用的优化支持,以及继承与属性查找等相关 ...
- C# NPOI Excel多级表头导出多个表
下载地址:https://files.cnblogs.com/files/netlock/NPOIDemo.rar
- HttpApplication执行顺序
类的实例(Global继承自该类)是在 ASP.NET 基础结构中创建的,而不是由用户直接创建的.HttpApplication 类的一个实例在其生存期内被用于处理多个请求,但它一次只能处理一个请求. ...
- python序列(五)切片操作
功能:截取列表中的任何部分. 切片适用于列表.元组.字符串.range对象等类型.. 格式:[::]切片使用两个冒号分隔的3个数字来完成. 第一个数字表示切片开始位置(默认为0). 第二个数字表示切片 ...
- reactor模式:主从式reactor
前面两篇文章提到 reactor模式:单线程的reactor模式 reactor模式:多线程的reactor模式 NIO的server模式只有5个阶段,但是,NIO的selectionkey里确实有个 ...
- swing桌面四子棋程序开发过程中遇到的一些问题记录(二)
第二个遇到的问题是将JButton按钮设置成透明的按钮.首先UI给我一张透明的图片,如果我直接给Button按钮设置背景图片的话,是没有透明的效果的,只会留下白色的底,设置前后的效果如下图 制作透明的 ...
- Xamarin.Forms 5.0 来了
Xamarin.Forms 5.0 已经正式发布,并带来其新功能,具体看官方博客https://devblogs.microsoft.com/xamarin/xamarin-forms-5-0-is- ...
- 2021超详细的HashMap原理分析,面试官就喜欢问这个!
一.散列表结构 散列表结构就是数组+链表的结构 二.什么是哈希? Hash也称散列.哈希,对应的英文单词Hash,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出 这个映射的规则就是对 ...
- LeetCode841 钥匙和房间
有 N 个房间,开始时你位于 0 号房间.每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙能使你进入下一个房间. 在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i ...
- kubernetes环境部署单节点redis
kubernetes部署redis数据库(单节点) redis简介 Redis 是我们常用的非关系型数据库,在项目开发.测试.部署到生成环境时,经常需要部署一套 Redis 来对数据进行缓存.这里介绍 ...