ES 实现实时从Mysql数据库中读取热词,停用词
IK分词器虽然自带词库
但是在实际开发应用中对于词库的灵活度的要求是远远不够的,IK分词器虽然配置文件中能添加扩展词库,但是需要重启ES
这章就当写一篇扩展了
其实IK本身是支持热更新词库的,但是需要我感觉不是很好
词库热更新方案:
1:IK 原生的热更新方案,部署一个WEB服务器,提供一个Http接口,通过Modified和tag两个Http响应头,来完成词库的热更新
2:通过修改IK源码支持Mysql定时更新数据
注意:推荐使用第二种方案,也是比较常用的方式,虽然第一种是官方提供的,但是官方也不建议使用
方案一:IK原生方案
1:外挂词库,就是在IK配置文件中添加扩展词库文件多个之间使用分号分割
优点:编辑指定词库文件,部署比较方便
缺点:每次编辑更新后都需要重启ES
2:远程词库,就是在IK配置文件中配置一个Http请求,可以是.dic文件,也可以是接口,同样多个之间使用分号分割
优点:指定静态文件,或者接口设置词库实现热更新词库,不用重启ES,是IK原生自带的
缺点:需要通过Modified和tag两个Http响应头,来提供词库的热更新,有时候会不生效
具体使用就不说了,在这里具体说第二种方案
方案二:通过定时读取Mysql完成词库的热更新
首先要下载IK分词器的源码
网址:https://github.com/medcl/elasticsearch-analysis-ik
下载的时候一定要选对版本,保持和ES的版本一致,否则会启动的时候报错,版本不一致
接着把源码导入IDEA中,并在POM.xml中添加Mysql的依赖,根据自己的Mysql版本需要添加
我的Mysql是5.6.1所以添加5的驱动包
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
然后再config目录下创建一个新的.properties配置文件

在里面配置Mysql的一些配置,以及我们需要的配置
jdbc.url=jdbc:mysql://192.168.43.154:3306/es?characterEncoding=UTF-8&serverTimezone=GMT&nullCatalogMeansCurrent=true
jdbc.user=root
jdbc.password=root
# 更新词库
jdbc.reload.sql=select word from hot_words
# 更新停用词词库
jdbc.reload.stopword.sql=select stopword as word from hot_stopwords
# 重新拉取时间间隔
jdbc.reload.interval=5000
创建一个新的线程,用于调用Dictionary得reLoadMainDict()方法重新加载词库
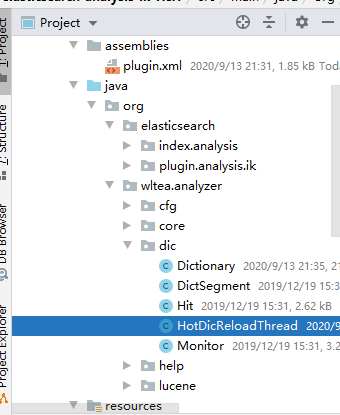
package org.wltea.analyzer.dic;
import org.wltea.analyzer.help.ESPluginLoggerFactory;
public class HotDicReloadThread implements Runnable{
private static final org.apache.logging.log4j.Logger logger = ESPluginLoggerFactory.getLogger(Dictionary.class.getName());
@Override
public void run() {
while (true){
logger.info("-------重新加载mysql词典--------");
Dictionary.getSingleton().reLoadMainDict();
}
}
}
修改org.wltea.analyzer.dic文件夹下的Dictionary
在Dictionary类中加载mysql驱动类
private static Properties prop = new Properties();
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
logger.error("error", e);
}
}
接着,创建重Mysql中加载词典的方法
/**
* 从mysql中加载热更新词典
*/
private void loadMySqlExtDict(){
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null; try {
Path file = PathUtils.get(getDictRoot(),"jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile())); logger.info("-------jdbc-reload.properties-------");
for (Object key : prop.keySet()) {
logger.info("key:{}", prop.getProperty(String.valueOf(key)));
} logger.info("------- 查询词典, sql:{}-------", prop.getProperty("jdbc.reload.sql")); // 建立mysql连接
connection = DriverManager.getConnection(
prop.getProperty("jdbc.url"),
prop.getProperty("jdbc.user"),
prop.getProperty("jdbc.password")
); // 执行查询
statement = connection.createStatement();
resultSet = statement.executeQuery(prop.getProperty("jdbc.reload.sql")); // 循环输出查询啊结果,添加到Main.dict中去
while (resultSet.next()) {
String theWord = resultSet.getString("word");
logger.info("------热更新词典:{}------", theWord); // 加到mainDict里面
_MainDict.fillSegment(theWord.trim().toCharArray());
}
} catch (Exception e) {
logger.error("error:{}", e);
} finally {
try {
if (resultSet != null) {
resultSet.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e){
logger.error("error", e);
}
}
}
接着,创建加载停用词词典方法
/**
* 从mysql中加载停用词
*/
private void loadMySqlStopwordDict(){
Connection conn = null;
Statement stmt = null;
ResultSet rs = null; try {
Path file = PathUtils.get(getDictRoot(), "jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile())); logger.info("-------jdbc-reload.properties-------");
for(Object key : prop.keySet()) {
logger.info("-------key:{}", prop.getProperty(String.valueOf(key)));
} logger.info("-------查询停用词, sql:{}",prop.getProperty("jdbc.reload.stopword.sql")); conn = DriverManager.getConnection(
prop.getProperty("jdbc.url"),
prop.getProperty("jdbc.user"),
prop.getProperty("jdbc.password"));
stmt = conn.createStatement();
rs = stmt.executeQuery(prop.getProperty("jdbc.reload.stopword.sql")); while(rs.next()) {
String theWord = rs.getString("word");
logger.info("------- 加载停用词 : {}", theWord);
_StopWords.fillSegment(theWord.trim().toCharArray());
} Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval"))));
} catch (Exception e) {
logger.error("error", e);
} finally {
try {
if(rs != null) {
rs.close();
}
if(stmt != null) {
stmt.close();
}
if(conn != null) {
conn.close();
}
} catch (SQLException e){
logger.error("error:{}", e);
} }
}
接下来,分别在loadMainDict()方法和loadStopWordDict()方法结尾处调用
/**
* 加载主词典及扩展词典
*/
private void loadMainDict() {
// 建立一个主词典实例
_MainDict = new DictSegment((char) 0); // 读取主词典文件
Path file = PathUtils.get(getDictRoot(), Dictionary.PATH_DIC_MAIN);
loadDictFile(_MainDict, file, false, "Main Dict");
// 加载扩展词典
this.loadExtDict();
// 加载远程自定义词库
this.loadRemoteExtDict();
// 加载Mysql外挂词库
this.loadMySqlExtDict();
}
/**
* 加载用户扩展的停止词词典
*/
private void loadStopWordDict() {
// 建立主词典实例
_StopWords = new DictSegment((char) 0); // 读取主词典文件
Path file = PathUtils.get(getDictRoot(), Dictionary.PATH_DIC_STOP);
loadDictFile(_StopWords, file, false, "Main Stopwords"); // 加载扩展停止词典
List<String> extStopWordDictFiles = getExtStopWordDictionarys();
if (extStopWordDictFiles != null) {
for (String extStopWordDictName : extStopWordDictFiles) {
logger.info("[Dict Loading] " + extStopWordDictName); // 读取扩展词典文件
file = PathUtils.get(extStopWordDictName);
loadDictFile(_StopWords, file, false, "Extra Stopwords");
}
} // 加载远程停用词典
List<String> remoteExtStopWordDictFiles = getRemoteExtStopWordDictionarys();
for (String location : remoteExtStopWordDictFiles) {
logger.info("[Dict Loading] " + location);
List<String> lists = getRemoteWords(location);
// 如果找不到扩展的字典,则忽略
if (lists == null) {
logger.error("[Dict Loading] " + location + " load failed");
continue;
}
for (String theWord : lists) {
if (theWord != null && !"".equals(theWord.trim())) {
// 加载远程词典数据到主内存中
logger.info(theWord);
_StopWords.fillSegment(theWord.trim().toLowerCase().toCharArray());
}
}
} // 加载Mysql停用词词库
this.loadMySqlStopwordDict(); }
最后在initial()方法中启动更新线程
/**
* 词典初始化 由于IK Analyzer的词典采用Dictionary类的静态方法进行词典初始化
* 只有当Dictionary类被实际调用时,才会开始载入词典, 这将延长首次分词操作的时间 该方法提供了一个在应用加载阶段就初始化字典的手段
*
* @return Dictionary
*/
public static synchronized void initial(Configuration cfg) {
if (singleton == null) {
synchronized (Dictionary.class) {
if (singleton == null) { singleton = new Dictionary(cfg);
singleton.loadMainDict();
singleton.loadSurnameDict();
singleton.loadQuantifierDict();
singleton.loadSuffixDict();
singleton.loadPrepDict();
singleton.loadStopWordDict(); // 执行更新mysql词库的线程
new Thread(new HotDicReloadThread()).start(); if(cfg.isEnableRemoteDict()){
// 建立监控线程
for (String location : singleton.getRemoteExtDictionarys()) {
// 10 秒是初始延迟可以修改的 60是间隔时间 单位秒
pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS);
}
for (String location : singleton.getRemoteExtStopWordDictionarys()) {
pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS);
}
} }
}
}
}
然后,修改src/main/assemblies/plugin.xml文件中,加入Mysql
<dependencySet>
<outputDirectory>/</outputDirectory>
<useProjectArtifact>true</useProjectArtifact>
<useTransitiveFiltering>true</useTransitiveFiltering>
<includes>
<include>mysql:mysql-connector-java</include>
</includes>
</dependencySet>
源码到此修改完成,在自己的数据库中创建两张新的表
建表SQL
CREATE TABLE hot_words (
id bigint(20) NOT NULL AUTO_INCREMENT,
word varchar(50) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '词语',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci; CREATE TABLE hot_stopwords (
id bigint(20) NOT NULL AUTO_INCREMENT,
stopword varchar(50) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '停用词',
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
接下来对源码进行打包:
打包之前检查自己的POM.xml中的elasticsearch.version的版本,记得和自己的ES的版本对应,否则到时候会报错

检查完毕后,点击IDEA右侧的package进行项目打包,如果版本不对,修改版本并点击IDEA右侧的刷新同步,进行版本的更换,然后打包
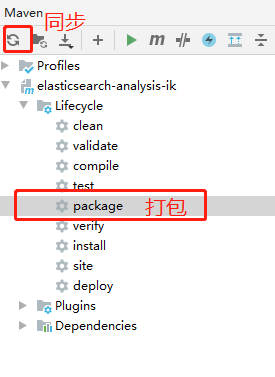
打包完成后在左侧项目中会出现target目录,会看到一个zip,我的是因为解压了,所以有文件夹

点击右键在文件夹中展示,然后使用解压工具解压

解压完成后,双击进入
先把原来ES下的plugins下的IK文件夹中的东西删除,可以先备份,然后把自己打包解压后里面的东西全部拷贝到ES下的plugins下的IK文件夹中
接下来进入bin目录下启动就可以了
当然按照惯例,我的启动时不会那么简单的,很高兴,我的报错了,所有的坑都踩了一遍,之前的版本不对就踩了两次
第一次是源码下载的版本不对
第二次的ES依赖版本不对
好了说报错:报错只贴主要内容
第三次报错:
Caused by: java.security.AccessControlException: access denied ("java.lang.RuntimePermission" "setContextClassLoader")
这个是JRE的类的创建设值权限不对
在jre/lib/security文件夹中有一个java.policy文件,在其grant{}中加入授权即可
permission java.lang.RuntimePermission "createClassLoader";
permission java.lang.RuntimePermission "getClassLoader";
permission java.lang.RuntimePermission "accessDeclaredMembers";
permission java.lang.RuntimePermission "setContextClassLoader";
第四次报错:
Caused by: java.security.AccessControlException: access denied ("java.net.SocketPermission" "192.168.43.154:3306" "connect,resolve")
这个是通信链接等权限不对
也是,在jre/lib/security文件夹中有一个java.policy文件,在其grant{}中加入授权即可
permission java.net.SocketPermission "192.168.43.154:3306","accept";
permission java.net.SocketPermission "192.168.43.154:3306","listen";
permission java.net.SocketPermission "192.168.43.154:3306","resolve";
permission java.net.SocketPermission "192.168.43.154:3306","connect";
到此之后启动无异常
最后就是测试了,启动我的head插件和kibana,这两个没有或者不会的可以看我之前写的,也可以百度
执行分词
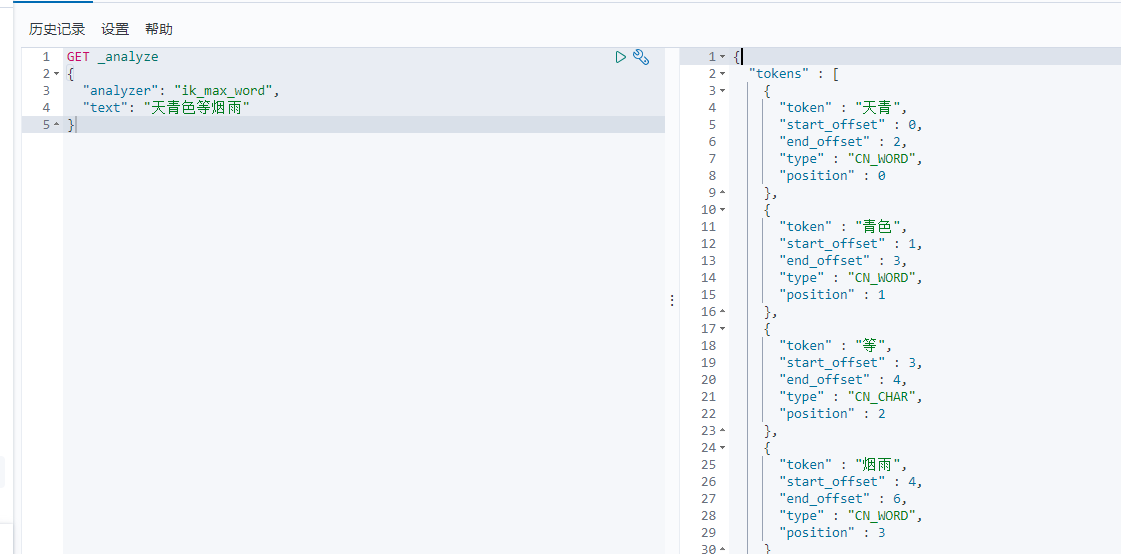
但是我想要 天青色
在Mysql中添加记录
insert into hot_words(word) value("天青色");
重新执行
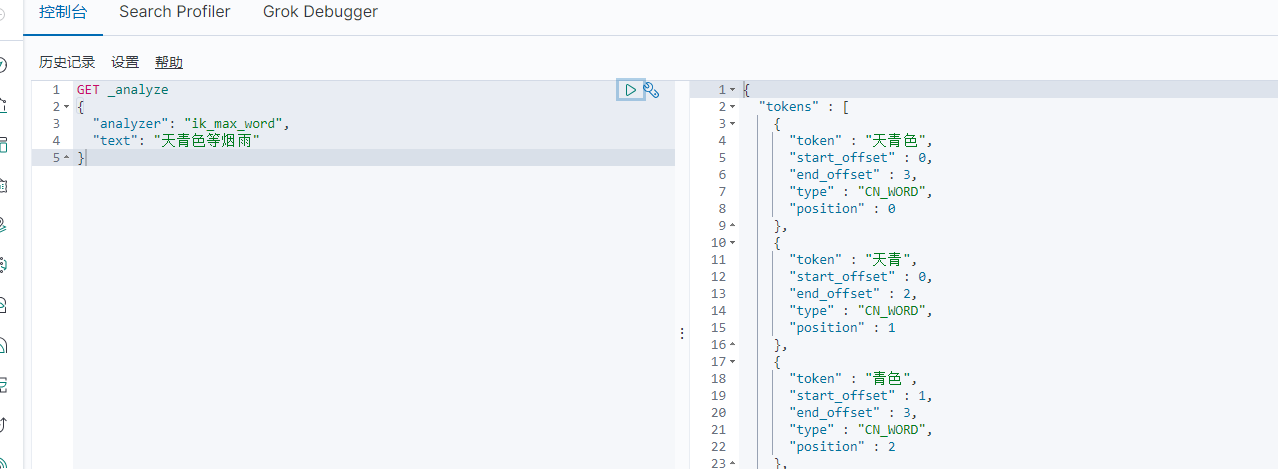
也比如我想要这就是一个词 天青色等烟雨
在Mysql中添加记录
insert into hot_words(word) value("天青色等烟雨");
再次执行

到此实现了ES定时从mysql中读取热词,停用词这个一般用的比较少,有兴趣自己测测,在使用的时候,通过业务系统往数据库热词表和停用词表添加记录就可以了
作者:彼岸舞
时间:2020\09\13
内容关于:ElasticSearch
本文来源于网络,只做技术分享,一概不负任何责任
ES 实现实时从Mysql数据库中读取热词,停用词的更多相关文章
- JDBC Java 程序从 MySQL 数据库中读取数据,并备份到 xml 文档中
MySQL 版本:Server version: 5.7.17-log MySQL Community Server (GPL) 相关内容:JDBC Java 程序从 MySQL 数据库中读取数据,并 ...
- JDBC Java 程序从 MySQL 数据库中读取数据,并封装到 Javabean 对象中
MySQL 版本:Server version: 5.7.17-log MySQL Community Server (GPL) 相关内容:JDBC Java 连接 MySQL 数据库 用于测试的 M ...
- C#实现MySQL数据库中的blob数据存储
在MySQL数据库中,有一种blob数据类型,用来存储文件.C#编程语言操作MySQL数据库需要使用MySQL官方组件MySQL.Data.dll. Mysql.Data.dll(6.9.6)组件下载 ...
- MySQL数据库中tinyint字段值为1,读取出来为true的问题
原文:https://blog.csdn.net/shuyou612/article/details/46788475 MySQL数据库中tinyint字段值为1,读取出来为true的问题 今天在 ...
- 从SQLSERVER/MYSQL数据库中随机取一条或者N条记录
从SQLSERVER/MYSQL数据库中随机取一条或者N条记录 很多人都知道使用rand()函数但是怎麽使用可能不是每个人都知道 建立测试表 USE [sss] GO ,NAME ) DEFAULT ...
- 用JDBC把Excel中的数据导入到Mysql数据库中
步骤:0.在Mysql数据库中先建好table 1.从Excel表格读数据 2.用JDBC连接Mysql数据库 3.把读出的数据导入到Mysql数据库的相应表中 其中,步骤0的table我是先在Mys ...
- Mysql数据库中CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP区别
如图所示,mysql数据库中,当字段类型为timestamp时,如果默认值取CURRENT_TIMESTAMP,则在insert一条记录时,end_time的值自动设置为系统当前时间,如果勾选了 ON ...
- MySQL数据库中的索引(一)——索引实现原理
今天我们来探讨一下数据库中一个很重要的概念:索引. MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构,即索引是一种数据结构. 我们知道,数据库查询是数据库的最主要 ...
- Jmeter从数据库中读取数据
Jmeter从数据库中读取数据 1.测试计划中添加Mysql Jar包 2.添加线程组 3.添加 jdbc connection configuration 4.添加JDBC Request,从数据库 ...
随机推荐
- C#LeetCode刷题之#933-最近的请求次数(Number of Recent Calls)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4134 访问. 写一个 RecentCounter 类来计算最近的 ...
- vue scss 样式穿透
使用2个style的方式不够优雅,可以使用下面方式做样式穿透 .normal-field /deep/ .el-form-item { margin-bottom: 0px; } .normal-fi ...
- 剑指Offer——II平衡二叉树
class TreeNode: def __init__(self, x): self.val = x self.left = None self.right = None # 这道题使用中序遍历加上 ...
- 在.NET Core中使用MongoDB明细教程(2):使用Filter语句检索文档
在上篇文章我们介绍了一些驱动程序相关的基础知识,以及如何将文档插入到集合中.在这篇文章中,我们将学习如何从数据库中检索文档. 作者:依乐祝 译文地址:https://www.cnblogs.com/y ...
- 剑指offer数组中重复的数字
package 数组; /*在一个长度为n的数组里的所有数字都在0到n-1的范围内. 数组中某些数字是重复的,但不知道有几个数字是重复的. 也不知道每个数字重复几次.请找出数组中任意一个重复的数字. ...
- C# 监听值的变化
1.写一个监听值变化的类 public class MonitorValueChange { private Visibility myValue; public Visibility MyValue ...
- 在string.replace中使用具名组匹配
let reg = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/; let re = '2015-01-02'. r ...
- Golang bytes.buffer详解
原文:https://www.jianshu.com/p/e53083132a25 Buffer 介绍 Buffer 是 bytes 包中的一个 type Buffer struct{…} A buf ...
- Linux环境下安装JDK8
Linux环境下搭建Java项目运行环境,首先要安装JDK,安装JDK8的步骤如下: 1 下载JDK安装包 下载地址:http://www.oracle.com/technetwork/java/ja ...
- A review of learning in biologically plausible spiking neural networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Contents: ABSTRACT 1. Introduction 2. Biological background 2.1. Spik ...