Spark内核-部署模式
| Master URL | Meaning |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力。 |
| local[K] | 在本地运行,有K个工作进程,通常设置K为机器的CPU核心数量。 |
| local[*] | 在本地运行,工作进程数量等于机器的CPU核心数量。 |
| spark://HOST:PORT | 以Standalone模式运行,这是Spark自身提供的集群运行模式,默认端口号: 7077。详细文档见:Spark standalone cluster。 |
| mesos://HOST:PORT | 在Mesos集群上运行,Driver进程和Worker进程运行在Mesos集群上,部署模式必须使用固定值:--deploy-mode cluster。详细文档见:MesosClusterDispatcher. |
| yarn-client | 在Yarn集群上运行,Driver进程在本地,Executor进程在Yarn集群上,部署模式必须使用固定值:--deploy-mode client。Yarn集群地址必须在HADOOPCONFDIR or YARNCONFDIR变量里定义。 |
| yarn-cluster | 在Yarn集群上运行,Driver进程在Yarn集群上,Work进程也在Yarn集群上,部署模式必须使用固定值:--deploy-mode cluster。Yarn集群地址必须在HADOOPCONFDIR or YARNCONFDIR变量里定义。 |
用户在提交任务给Spark处理时,以下两个参数共同决定了Spark的运行方式。· –master MASTER_URL :决定了Spark任务提交给哪种集群处理。· –deploy-mode DEPLOY_MODE:决定了Driver的运行方式,可选值为Client或者Cluster。
Standalone 模式运行机制
Standalone集群有四个重要组成部分,分别是:
- Driver:是一个进程,我们编写的Spark应用程序就运行在Driver上,由Driver进程执行;2) Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;3) Worker(NM):是一个进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。4) Executor:是一个进程,一个Worker上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
Standalone Client 模式
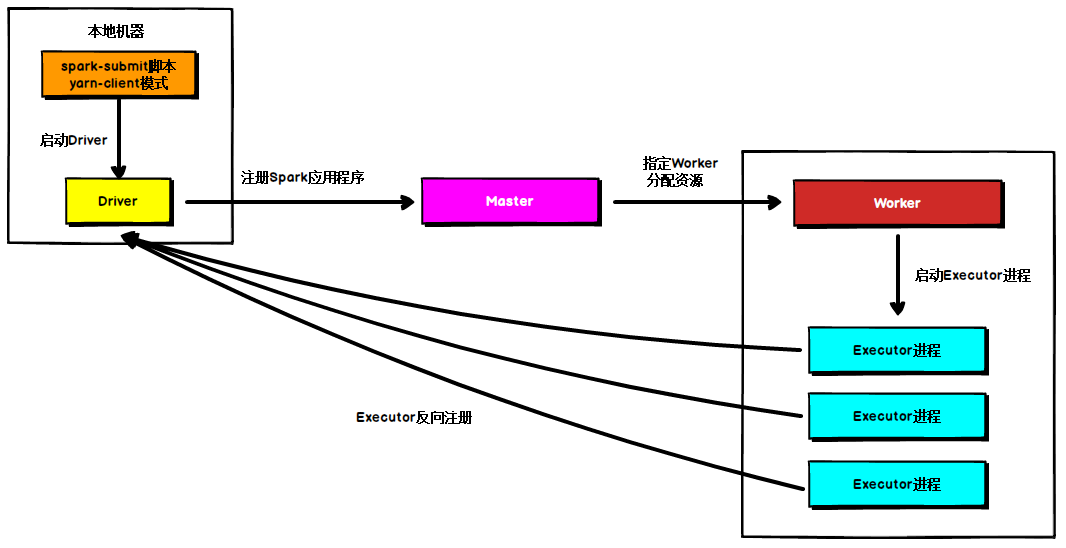
在Standalone Client模式下,Driver在任务提交的本地机器上运行,Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Standalone Cluster模式
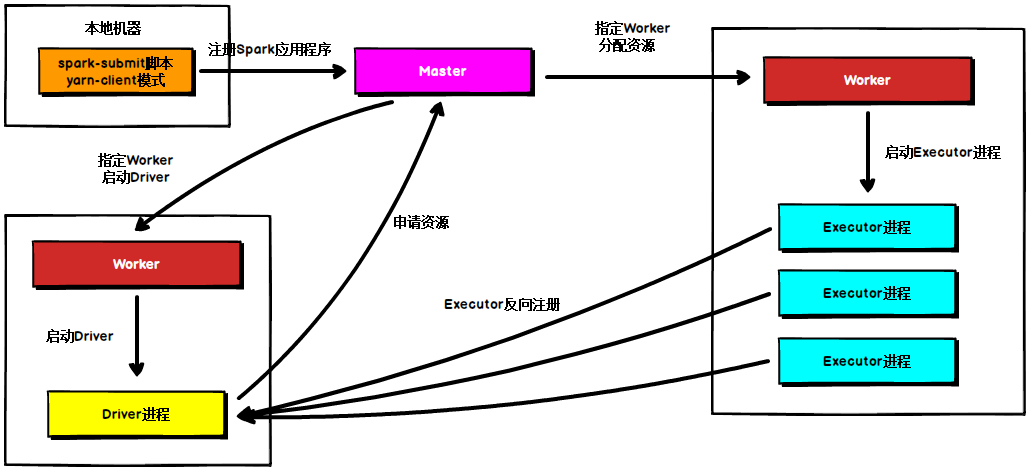
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver进程, Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。注意Standalone的两种模式下(client/Cluster),Master在接到Driver注册Spark应用程序的请求后,会获取其所管理的剩余资源能够启动一个Executor的所有Worker,然后在这些Worker之间分发Executor,此时的分发只考虑Worker上的资源是否足够使用,直到当前应用程序所需的所有Executor都分配完毕,Executor反向注册完毕后,Driver开始执行main程序。
Yarn 模式运行机制
Yarn Client 模式

在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
Yarn Cluster 模式
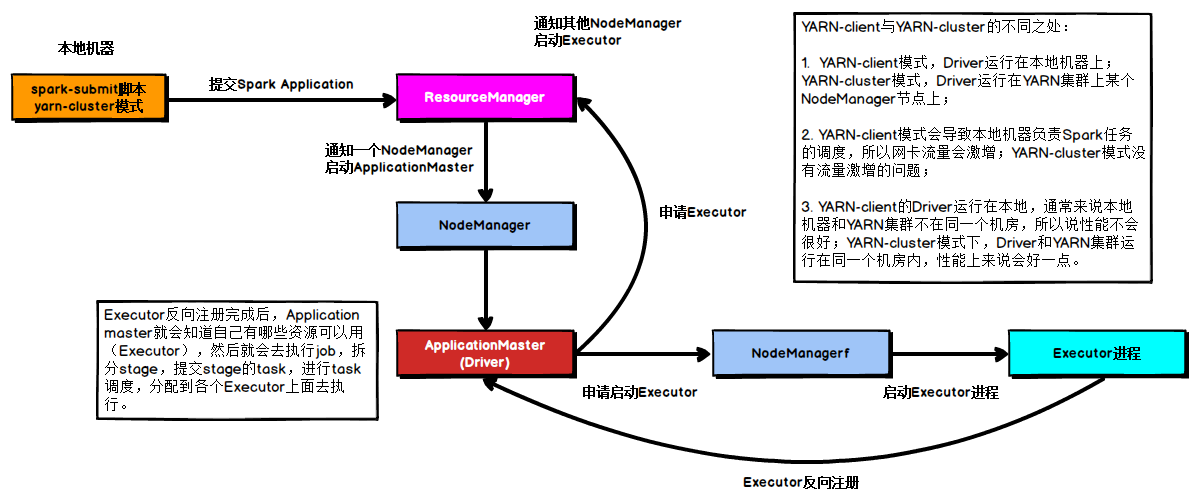
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
作者:十一喵先森
链接:https://juejin.im/post/5e1c414fe51d451cad4111d1
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我的解释:
Standalone Cluster模式
spark集群----一个公司.腾讯
master----老板
worker----部门
driver---项目经理
execotur---执行器---程序员
application---自己编写的程序---客户提要求
流程:
任务提交后,
Master(老板)会找到一个Worker(部门)启动Driver(项目)进程
把application(客户的需求)提交给driver(项目经理),
driver(项目经理)去spark(公司)集群中找到master(老板)要资源,需要多部门配合.
master(老板)会根据调度算法找到可用的多个worker(部门),
Driver(项目经理)在worker(部门)中启动executor(程序员)程序.
Driver(项目经理)开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor(程序员)上执行
Yarn Cluster 模式
Application---需求
ApplicationMaster(Driver)---项目经理
Executor---程序员
yarn---公司
ResourceManager---老板
NodeManager---部门
流程:
本地机器提交application(需求)到resourcemanager(老板),
resourcemanager(老板)在NodeManager(部门)上启动ApplicationManster(项目),就是driver.
ApplicationMaster(项目经理)向ResourceManager(老板)申请Executor(程序员)内存,
在合适的多个NodeManager(部门)上启动Executor(程序员)进程,
Driver(项目经理)开始执行main函数,
并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor(程序)上执行。
Spark内核-部署模式的更多相关文章
- 【待补充】Spark 集群模式 && Spark Job 部署模式
0. 说明 Spark 集群模式 && Spark Job 部署模式 1. Spark 集群模式 [ Local ] 使用一个 JVM 模拟 Spark 集群 [ Standalone ...
- Spark job 部署模式
Spark job 的部署有两种模式,Client && Cluster spark-submit .. --deploy-mode client | cluster [上传 Jar ...
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
- Apache Spark技术实战之8:Standalone部署模式下的临时文件清理
未经本人同意严禁转载,徽沪一郎. 概要 在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件,这些临时目录和文件又是在什么时候被清理,本文将就这些问题做深入细致的解答. 从 ...
- Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
问题导读 1.在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件? 2.在Standalone部署模式下分为几种模式? 3.在client模式和cluster模式下有什么 ...
- Spark安装部署(local和standalone模式)
Spark运行的4中模式: Local Standalone Yarn Mesos 一.安装spark前期准备 1.安装java $ sudo tar -zxvf jdk-7u67-linux-x64 ...
- 【Spark】Spark的Standalone模式安装部署
Spark执行模式 Spark 有非常多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则执行在集群中,眼下能非常好的执行在 Yarn和 Mesos 中.当然 Spark 还有自带的 St ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
随机推荐
- 03生成微博授权URL接口
1.创建apps/oauth模块进行oauth认证 '''2.1 在apps文件夹下新建应用: oauth''' cd syl/apps python ../manage.py startapp oa ...
- maven打包时报No compiler is provided in this environment处理
系统:macOS 开发工具:Idea 问题描述:在idea中执行mvn clean install时报No compiler is provided in this environment. Perh ...
- 【Updating】汇编语言学习记录02
换码指令.字符的输出 前置知识: XLAT 指令:将BX指定的缓冲区中.AL指定的位移处的一个字节数据取出赋给AL,实际相当于(AL) = (DS:(BX+AL)).注意,不是单纯地赋予AL+BX,而 ...
- IO模式 select、poll、epoll
阻塞(blocking).非阻塞(non-blocking):最常听到阻塞与非阻塞这两个词就是在函数调用中,比如waitid这个函数,通过NOHANG参数可以把waitid设置为非阻塞的,也就是问询一 ...
- rsync单项同步
配置rsync+inotify实时单向同步 定期同步的缺点: 执行备份的时间固定,延期明显,实时性差 当同步源长期不变化时,密集的定期任务是不必要的(浪费资源) 实时同步的优点: 一旦同步源出现变化, ...
- CentOS下配置VNC
配置桌面 # 安装gnome桌面环境 yum groupinstall Desktop -y # 安装中文语言支持包(可选) yum groupinstall 'Chinese Support' -y ...
- 避开一部分安装问题的Burpsuite的安装教程
Burpsuite的安装教程 前言: 既然网上有很多的Burpsuite的安装教程为什么笔者还要在写这篇文章呢? 笔者发现网上的许多安装教程都存在着许许多多的问题,有时候对于一些安装细节描述不是很深, ...
- Java数据结构(十三)—— 二叉排序树(BST)
二叉排序树(BST) 需求 给定数列{7,3,10,12,5,1,9},要求能够高效的完成对数据的查询和添加 思路三则 使用数组,缺点:插入和排序速度较慢 链式存储,添加较快,但查找速度慢 使用二叉排 ...
- 老猿学5G:3GPP和中国移动5G计费架构概览
☞ ░ 前往老猿Python博文目录 ░ 一.引言 老猿学5G这个专栏主要记录笔者因工作原因学习了解5G计费相关知识,文章按时间顺序循序渐进的介绍5G基础概念以及5G计费相关知识,该专栏前期已经完结, ...
- PyQt(Python+Qt)学习随笔:QHeaderView.ResizeMode取值及含义
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 关于ResizeMode的使用请参考<PyQt(Python+Qt)学习随笔:QTableWi ...