High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis
论文来源:CVPR 2017
摘要
之前方法的缺点:之前的方法是基于语义和上下文信息的,在填充较大holes的表现得很好,能够捕获更高级的图像特征,但是由于内存限制和难以训练网络的因素,只能处理分辨率较小的图片。
论文提出的方法:提出了一种基于结合图像内容和纹理约束来进行优化的多尺度神经patch结合的方法,该方法不仅保留了上下文结构,而且利用深度分类网络中最相似的中间特征层相关性来调整和匹配Patch来产生高频细节信息。
优势之处: 可以处理大分辨率的图片
网络结构:
数据集: ImagenetImagenet用于预训练VGG-16 ,Paris−Streetview−datasetsParis−Streetview−datasets
Code:Faster-High-Res-Neural-Inpainting
Introduction
现有的修复方法:预测似是而非的图像结构,而且评估速度非常快,因为孔洞区域是在一次正向通过中预测出来的。虽然结果是令人鼓舞的,但这种方法的补绘结果有时缺乏精细的纹理细节,从而在洞的边缘产生可见的伪影。该方法也不能处理高分辨率图像,因为当输入较大时,对抗性损失的训练比较困难。
本论文的灵感来源:
- Phatak提出的encoderdecoder CNN (Context Encoder) 采用 ℓ2 和 adversarial loss相结合来直接预测图像缺失的区域。缺点:纹理细节处理的不好,当输入图片较大(高分辨率图片)时,难以训练adversarial loss。
- Li and Wand实现图像样式转换,通过对中间层的神经响应(neural response)与图像内容相似,低卷积层的局部响应与样式图像的局部响应相似的图像进行优化。这里的局部响应代表小的(典型3*3)的neural patches。这个方法证明了将高频细节从样式图像传输到内容图像。但是现在样式转换多采用引用的gram matrices of neural responses。
本文提出的方法:
- 提出了结合 encoderdecoder CNN (Context Encoder) 的结构预测能力和neural patches的合成高频真实的图像的能力来实现图像修复任务。
- 和样式转换任务一样,我们训练encoderdecoder CNN (Context Encoder)来作为全局内容的约束(global content constraint),并且利用缺失部分和已知区域的局部neural patches相似性。(利用预先训练好的分类网络、中间特征层的patch响应和缺失部分周围的图像内容对纹理约束进行建模。)这两种约束可以通过有限内存BFGS的反向传播算法进行优化。
- 为了进一步提出多尺度neural patch合成的方法,我们假设图片大小为512×512,中间带有256×256的缺失部分,然后我们创造一个三级的金字塔结构,步数为2,每步缩小为原来图片的一半(512 256 128,256 128 64)。然后我们执行一个粗到细化的填充任务。以内容预测网络的最底层输出进行初始化,在每个尺度上(1)执行联合优化以更新缺失部分,(2)上采样以初始化联合优化并为下一个尺度设置内容约束。然后重复此操作,直到以最高分辨率完成联合优化。
本文的贡献:
- 提出了联合优化框架,可以缺失的图像区域建模的全局内容约束和局部纹理约束卷积神经网络。
- 基于联合优化框架的高分辨率图像修复多尺度神经patch合成算法。
- 从神经网络的中间层提取的特征可以用来合成真实的图像内容和纹理
相关工作
使用深度网络进行结构预测:
- 与传统的图像生成(GAN)不同,图像修复的目的是在已知图像区域的条件下,预测缺失部分的内容。最近提出的用于图像修复的encoder-decoder网络结构, 使用 ℓ2 loss 和 adversarial loss (Context Encoder)相结合的损失函数。在论文中,我们采用Context Encoder作为全局内容预测网络,使用它的输出初始化多尺度neural patch合成算法。
风格转换:
- 展示了神经风格转移的成功。这些方法主要是通过结合一个图像的“样式”和另一图像的“内容”来生成的图像。这也表明了神经特征(neural features)在生成图像的精细纹理和高频细节方面也非常强大。
方法
框架概述
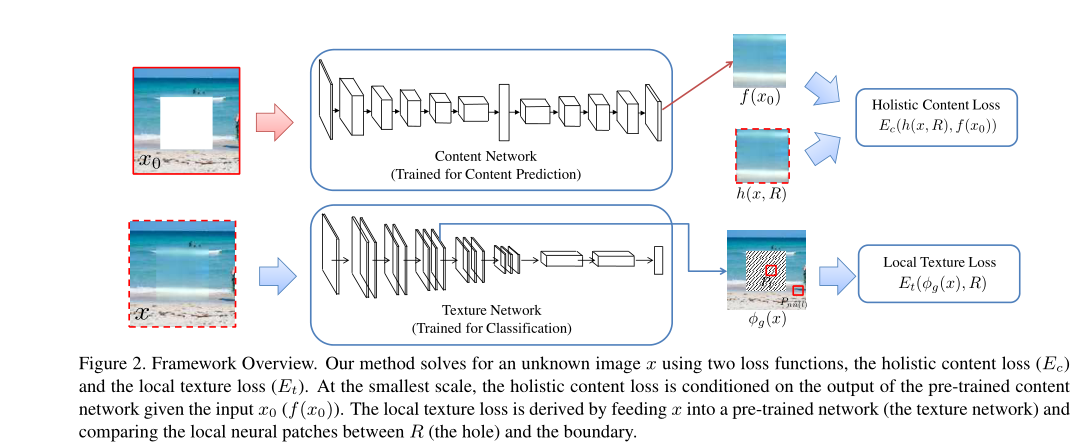
- 在优化损失函数得到最佳的修复图像x〜x〜,该损失函数由三个项构成,包括整体内容项(the holistic content term), 局部纹理项(the local texture term)和TV损失项(the tv-loss term)。
- 整体内容项是一个全局结构约束,它捕获图像的语义和全局结构。首先训练Content network,并用它初始化整体内容项。
- 局部纹理项是对输入图像的局部纹理统计进行建模。使用在ImageNet上预先训练的VGG-19网络计算的。
- 内容约束模型:我们首先训练整体内容网络ff(the holistic content network f),输入网络的是去除中心矩形区域并填充平均颜色的图像,并且ground truth图像xtxt是原始图像的中心矩形的内容。一旦整体内容网络被训练,我们就可以使用网络的输出f(x0)f(x0)作为联合优化的初始内容约束。
- 局部纹理项:目的是为了确保缺失部分的内容和缺失部分周围细节上相似。通过neural patches来定义相似性(neural patches已经成功应用到捕捉图像的样式。)为了优化局部纹理项,将图像xx输入到预先训练的VGG网络(局部纹理网络)中,并在网络的预定特征层上,使缺失区域内的小(通常为3×3)神经块的响应与缺失外的神经块相似。实际上,我们使用relu3_1和relu4_1层的组合来计算神经特征。我们使用有限的内存BFGS通过最小化关节内容和纹理损失来迭代更新xx。
- 多尺度问题:多尺度为了实现高分辨率图像的修复,对于给定的一幅缺失范围较大的高分辨率图像,我们首先对图像进行缩小,然后利用内容网络的预测得到参考内容。然后对于给定参考内容,我们在低分辨率下优化(即内容和纹理约束)。然后对优化结果进行上采样,并将其用作精细尺度下优化的初始化。
联合损失函数
- 输入图像x0x0,输出图像xx。
- R表示输出图像xx的缺失部分,RφRφ表示VGG-19网络的特征映射φ(x)中的对应缺失部分的区域。
- h(·)表示在矩形区域中提取子图像或子特征映射的操作,即h(x,R)表示在x中R区域的颜色内容,h(φ(x),Rφ)h(φ(x),Rφ)表示φ(x)φ(x)中RφRφ区域的内容。
- 内容约束网络(the content network)记为ff,纹理约束网络(the textture network)记为tt。
- 图像缩小比例ii=1,2,.....,N(N是缩小的比例数目),最佳重构(hole filling)结果x〜x〜,可以通过解决以下最小化问题来实现:

- 其中,h(x1,R)=f(x0)h(x1,R)=f(x0),φt(x)φt(x)表示在局部纹理网络tt的中间层的特征映射(feature map)(或特征映射的组合),α是反映这两个项之间重要性的权重。α和β设置为5e-6可以平衡每个损失的大小。
- 损失函数三项的解释:EcEc,EtEt和γγ
EcEc被建模为整体内容约束,用来惩罚优化结果与以前的内容预测(来自内容网络或较粗规模的优化结果)之间的l2l2差异。
EtEt被建模为局部纹理约束,用来惩罚缺失部分内外纹理外观的差异。
- 首先在网络tt中选择某一特征层(或特征层的组合)并提取其特征映射φtφt,对于缺失区域RR中每个s×s×cs×s×c大小的局部查询块P,我们在缺失部分外找到其最相似的块,并通过平均查询块与其最近邻的距离来计算损失。

- |Rφ||Rφ|是区域RφRφ中采样的块的数量,PiPi是以位置ii为中心的局部神经块(local neural patch),nn(i)nn(i)计算公式为:

- N(i)N(i)是ii与RR重叠的相邻位置的集合。
TV loss 目的是为让图像更加平滑。


The Contend Network
- 学习初始内容预测网络(content prediction network )的一种简单方法是训练回归网络ff以使用输入图像xx(具有未知区域)的响应f(x)f(x)来近似于区域RR处的ground truth xgxg。
- 我们实验采用l1l1loss和adversarial loss。
- 对于每个训练的图像,l2l2 loss被定义为:

- adversarial loss被定义为:

- 我们采用和Context Encoder相同的方法,l2l2loss和adversarial loss 组合的方式:

λ取0.999
The Texure Network
- 我们实验ImageNet Classification的VGG-19预训练网络作为纹理网络(the texture network),并且使用relu3−1relu3−1和relu4−1relu4−1层计算局部纹理约束(the local texture term)。用两个层计算比单用一层计算效果会更好。
- 使用VGG-19网络的原因:VGG-19网络经过语义分类训练,因此其中间层的特征具有很强的不变性(纹理变形)。 这有助于推断出缺失部分内容进行更准确重建。
Experiment
可视化和定量的评估。我们首先介绍了这些数据集,然后与其他方法进行了比较,证明了该方法在高分辨率图像修复中的有效性。在这一部分的最后,我们展示了一个真实的应用程序,在这个应用程序中,我们可以从照片中移除干扰因素
DataSets:Paris StreetView and ImageNet.(不使用标签)
- paris streeview: 包含14900张训练图片和100张测试图片。
- ImageNet:包括1260000张训练图片和200张从验证集中随机挑选的图片。
Experimental Settings:在低分辨率(128×128)的情况下,首先将我们的方法与几种基准方法进行了比较。
- 首先,我们将结果与采用l2l2loss的上下文编码器进行了比较。
- 第二,我们将我们的方法与上下文编码器使用对抗性损失所取得的最佳结果进行比较,这是使用深度学习进行图像修复领域的最新技术。
- 最后,我们用AdobePhotoshop中的PatchMatch算法来比较内容感知填充的结果。我们的比较证明了所提出的联合优化框架的有效性。
- 通过与基准方法的比较,说明了整体联合优化算法的有效性和纹理网络在联合优化中的作用,并进一步分析了内容网络和纹理网络在联合优化中的分离作用。
- 最后,我们给出了高分辨率图像修复的结果,并与Content-Aware Fill和Context Encoder(ℓ2 and adversarial loss)进行了比较。注意,对于上下文编码器,高分辨率的结果是通过直接从低分辨率输出上采样获得的。我们的方法在视觉质量方面显示出显著的改进。
Quantitative Comparisons
- 在巴黎街景数据集上的低分辨率(128×128)图像,我们将我们方法和基准方进行对比。表1的结果表明,我们的方法获得了最高的数值性能。我们将此归因于我们方法的本质——它可以推断出Content-Aware Fill失败时的图像的正确结构,并且与Context Encoder的结果相比,还可以合成更好的图像细节(图4)。此外,鉴于修复任务的目标是生成逼真的内容,而不是生成与原始图像中完全相同的内容,定量评估可能不是最有效的修复措施。

- 在巴黎街景数据集上的低分辨率(128×128)图像,我们将我们方法和基准方进行对比。表1的结果表明,我们的方法获得了最高的数值性能。我们将此归因于我们方法的本质——它可以推断出Content-Aware Fill失败时的图像的正确结构,并且与Context Encoder的结果相比,还可以合成更好的图像细节(图4)。此外,鉴于修复任务的目标是生成逼真的内容,而不是生成与原始图像中完全相同的内容,定量评估可能不是最有效的修复措施。
The effects of content and texture networks
- 我们做了一个研究是去掉内容约束项( the content constraint term ),只在联合优化中使用纹理项。如图8所示,在不使用内容项来指导优化的情况下,修补结果的结构是完全错误的。我们还调整了内容项和纹理项之间的相对权重。我们的发现是,通过使用更多的内容约束权重,结果更符合内容网络的初始预测,但可能缺乏高频细节。类似地,使用更多的纹理项可以得到清晰的结果,但不能保证整个图像结构是正确的(图6)。
The effect of the adversarial loss
- 我们分析了在训练内容网络(the content networks)中使用对抗性损失的效果。人们可能会认为,在不使用对抗性损失的情况下,内容网络仍然能够预测图像的结构,联合优化将在稍后校准纹理。但是我们发现,内容网络给出的初始化质量对最终结果很重要。当初始预测是模糊的(仅使用“l2损失”)时,与同时使用“l2损失”和“对抗损失”训练的内容网络相比,最终结果也变得更加模糊(图7)。
High-Resolution image inpainting
- 我们在图5和图10中展示了高分辨率图像(512×512)修复的结果,并与Content-Aware Fill和Context Encoder(1212 loss+adversarial loss)进行了比较。由于Context Encoder只适用于128x128图像,并且当输入较大时,我们使用双线性插值直接将128×128的输出上采样到512×512。在大多数结果中,我们的多尺度迭代方法结合了其他方法的优点,产生具有相干全局结构和高频细节的结果。如图所示,与Content-Aware Fill相比,我们的方法的一个显著优势是,我们能够生成新的纹理,因为我们不会直接使用现有的patch进行修补。然而,一个缺点是,根据我们当前的实现,我们的算法需要大约1分钟的时间,用Titan X GPU填充512×512图像的256×256个孔,这比内容感知填充要慢得多。
Real-World Distractor Removal Scenario
最后,我们的算法很容易扩展到处理任意形状的缺失部分。我们首先使用一个包围矩形来覆盖任意的缺失部分,这个缺失部分再次填充了平均像素值。经过适当的裁剪和填充,使矩形位于中心位置后,将图像作为内容网络的输入。在联合优化中,内容约束(the content
constraint)是通过内容网络在任意缺失部分内的输出来初始化的。纹理约束基于缺失部分外的区域。图11示出了几个示例及其与内容感知填充算法的比较(注意,上下文编码器(Context Encoder)不能显式地处理任意缺失部分,因此我们不在此与之进行比较)。
Conclusion
我们已经提出了使用神经块合成(neural patch synthesis)在语义修复方面的最新进展。研究发现,纹理网络(the texture network)在产生高频细节方面非常强大,而内容网络(the content network)在语义和全局结构方面具有很强的先验性。这可能对其他应用有潜在的帮助,例如去噪、超分辨率、重定目标和视图/时间插值。当场景复杂时,我们的方法会引入不连续性和伪影(图9)。此外,速度仍然是我们算法的一个瓶颈。我们的目标是在今后的工作中解决这些问题。
High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis的更多相关文章
- Online handwriting recognition using multi convolution neural networks
w可以考虑从计算机的“机械性.重复性”特征去设计“低效的”算法. https://www.codeproject.com/articles/523074/webcontrols/ Online han ...
- CVPR 2017 Paper list
CVPR2017 paper list Machine Learning 1 Spotlight 1-1A Exclusivity-Consistency Regularized Multi-View ...
- OpenCV中的图像插值示例
本文地址:http://www.cnblogs.com/QingHuan/p/7384433.html,转载请注明出处 ======================================== ...
- GUI的最终选择 Tkinter(四):Entry、Listbox、Scrollbar和Scale组件
Entry组件 Entry组件就是平时所说的输入框.输入框是程序员用到的最多的一个程序,例如在输入账号和密码的时候需要提供两个输入框,用于接收密码的输入框还会有星号将实际输入的内容隐藏起来. Tkin ...
- Audio Bit Depth Super-Resolution with Neural Networks
Audio Bit Depth Super-Resolution with Neural Networks 作者:Thomas Liu.Taylor Lundy.William Qi 摘要 Audio ...
- Tkinter 之Scale滑块标签
一.参数说明 语法 作用 Scale(window, label="滑块") 滑块标题 Scale(window, label="滑块", from_=0) 滑 ...
- ECCV 2014 Results (16 Jun, 2014) 结果已出
Accepted Papers Title Primary Subject Area ID 3D computer vision 93 UPnP: An optimal O(n) soluti ...
- [C2P2] Andrew Ng - Machine Learning
##Linear Regression with One Variable Linear regression predicts a real-valued output based on an in ...
- Review of Semantic Segmentation with Deep Learning
In this post, I review the literature on semantic segmentation. Most research on semantic segmentati ...
随机推荐
- Luogu P2447 [SDOI2010]外星千足虫
题意 给定 \(n\) 个变量和 \(m\) 个异或方程,求最少需要多少个才能确定每个变量的解. \(\texttt{Data Range:}1\leq n\leq 10^3,1\leq m\leq ...
- Nginx 配置请求响应时间
1.常见默认nginx.conf配置日志格式 log_format main '$remote_addr - $remote_user [$time_local] "$request&quo ...
- Learn day5 迭代器\生成器\高阶函数\推导式\内置函数\模块(math.time)
1.迭代器 # ### 迭代器 """能被next调用,并不断返回下一个值的对象""" """ 特征:迭代器会 ...
- Ubuntu18.04上安装NS-3
目录 第一步:处理gcc/g++版本 第二步:安装相关依赖 第三步:正式安装 第四步:测试 我自己前后安装过好几次NS3了,网上其他相关的博客质量都不是很好,因此自己总结了一个ns3的安装过程. 首先 ...
- Dapr Java Http 调用
版本介绍 Java 版本:8 Dapr Java SKD 版本:0.9.2 Dapr Java-SDK HTTP 调用文档 有个先决条件,内容如下: Dapr and Dapr CLI. Java J ...
- 直播APP源码是如何实现音视频同步的
1. 音视频同步原理 1)时间戳 直播APP源码音视频同步主要用于在音视频流的播放过程中,让同一时刻录制的声音和图像在播放的时候尽可能的在同一个时间输出. 解决直播APP源码音视频同步问题的最佳方案 ...
- leetcode147median-of-two-sorted-arrays
题目描述 有两个大小分别为m和n的有序数组A和B.请找出这两个数组的中位数.你需要给出时间复杂度在O(log (m+n))以内的算法. There are two sorted arrays A an ...
- 12 RESTful架构(SOAP,RPC)
12 RESTful架构(SOAP,RPC) 推荐: http://www.ruanyifeng.com/blog/2011/09/restful.html
- vite 搭建Vue3.0项目
1.全局安装vite:npm install create-vite-app -g 2.创建项目:npx create-vite-app project-name 3.cd project-name ...
- 企业网络拓扑RSTP功能实例
组网图形 RSTP简介 以太网交换网络中为了进行链路备份,提高网络可靠性,通常会使用冗余链路.但是使用冗余链路会在交换网络上产生环路,引发广播风暴以及MAC地址表不稳定等故障现象,从而导致用户通信质 ...