MIT 6.S081 Lab5 Copy-On-Write Fork
前言
最近绝大多数的空闲时间都拿来锤15-445了,很久没动6.S081。前几天回头看了一下一个月前锤完的Lazy Allocation,自己写的代码几乎都不认识了.......看来总结之类的东西最好还是趁着热乎的时候写啊。
不过15-445的内容实在太多了,我只是为了锤Lab粗略的看了看课件,课件里很多东西都没研究,相关的总结还是推迟到所有Lab锤完后重新整理一下再写吧。先把几天前刚做完的Copy-On-Write给写出来。最近会把前面草草写下的Lab Lazy Allocation的相关内容整改一下,补上具体的Lab。
Lab5 Copy-On-Write fork的链接:https://pdos.csail.mit.edu/6.828/2019/labs/cow.html
最近xv6-riscv-2019好像被改动过了,我git clone下来的时候发现usertest中多了不少的新测试,trap.c的代码也被改过了。
xv6进程的结构
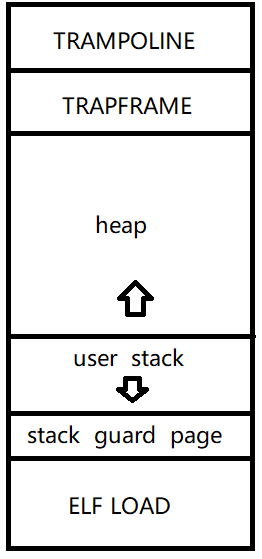
想要处理好这个Lab,需要我们对xv6的进程结构有一个大致的了解。而了解xv6的进程结构,最好的办法是阅读kernel/exec.c的代码。xv6的进程结构大致如上图所示。我们下面对每个进程段进行简要分析:
ELF LOAD 段
ELF LOAD段是我自己给这个段起的名字,你们谷歌查是查不到的....我实在不知道到底该怎么称呼这个段.....
ELF LOAD段是在调用exec时,由ELF文件加载进来的段。我们可以查看一下_sh这个ELF文件的描述:
ms@ubuntu:~/public/MIT 6.S081/Lab5 cow/xv6-riscv-fall19$ readelf -a user/_sh
ELF 头:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
类别: ELF64
数据: 2 补码,小端序 (little endian)
版本: 1 (current)
OS/ABI: UNIX - System V
ABI 版本: 0
类型: EXEC (可执行文件)
系统架构: RISC-V
版本: 0x1
入口点地址: 0xa60
程序头起点: 64 (bytes into file)
Start of section headers: 39464 (bytes into file)
标志: 0x5, RVC, double-float ABI
本头的大小: 64 (字节)
程序头大小: 56 (字节)
Number of program headers: 1
节头大小: 64 (字节)
节头数量: 19
字符串表索引节头: 18 节头:
[号] 名称 类型 地址 偏移量
大小 全体大小 旗标 链接 信息 对齐
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000078
000000000000127e 0000000000000000 WAX 0 0 2
[ 2] .rodata PROGBITS 0000000000001280 000012f8
0000000000000159 0000000000000000 A 0 0 8
[ 3] .sdata PROGBITS 00000000000013e0 00001458
000000000000000e 0000000000000000 WA 0 0 8
[ 4] .sbss NOBITS 00000000000013f0 00001466
0000000000000008 0000000000000000 WA 0 0 8
[ 5] .bss NOBITS 00000000000013f8 00001466
0000000000000078 0000000000000000 WA 0 0 8
[ 6] .comment PROGBITS 0000000000000000 00001466
0000000000000012 0000000000000001 MS 0 0 1
[ 7] .riscv.attributes LOPROC+0x3 0000000000000000 00001478
0000000000000035 0000000000000000 0 0 1
[ 8] .debug_aranges PROGBITS 0000000000000000 000014b0
00000000000000f0 0000000000000000 0 0 16
[ 9] .debug_info PROGBITS 0000000000000000 000015a0
00000000000021c2 0000000000000000 0 0 1
[10] .debug_abbrev PROGBITS 0000000000000000 00003762
00000000000006f1 0000000000000000 0 0 1
[11] .debug_line PROGBITS 0000000000000000 00003e53
0000000000002018 0000000000000000 0 0 1
[12] .debug_frame PROGBITS 0000000000000000 00005e70
0000000000000880 0000000000000000 0 0 8
[13] .debug_str PROGBITS 0000000000000000 000066f0
000000000000039f 0000000000000001 MS 0 0 1
[14] .debug_loc PROGBITS 0000000000000000 00006a8f
0000000000002386 0000000000000000 0 0 1
[15] .debug_ranges PROGBITS 0000000000000000 00008e15
0000000000000080 0000000000000000 0 0 1
[16] .symtab SYMTAB 0000000000000000 00008e98
00000000000008b8 0000000000000018 17 26 8
[17] .strtab STRTAB 0000000000000000 00009750
0000000000000218 0000000000000000 0 0 1
[18] .shstrtab STRTAB 0000000000000000 00009968
00000000000000bc 0000000000000000 0 0 1
........
可以看出,ELF LOAD段包含了程序的代码段、静态数据段、只读数据段、全局变量段、DEBUG信息等。exec函数一次申请一页,然后读取ELF文件的一页,读取完成后,将虚实映射关系添加到该进程的页表中。当ELF文件读取完后,ELF LOAD段也被加载到了进程的最低虚地址上,相应的虚实映射关系也被添加到了页表中。
stack guard page 段
xv6作为一个教学系统,它有很多设计不合理的地方。最明显的一点莫过于栈和堆的设置。很多OS书上告诉我们,进程的stack和heap是共用一块空间的,但它们的增长方向相反。当其中一个逾越到另一个的空间时,即认为空间已满,触发overflow。但xv6的栈却放在了低地址段,栈向下增长,堆放在了高地址段,向上增长......
吐槽完xv6,回过头来讨论这个段。因为stack是向低地址增长的,很可能会踩到ELF LOAD段不应该访问的区域,因此可以考虑在stack的PAGE和ELF LOAD的PAGE间设立GUARD PAGE,当用户访问这一段的时候触发page fault,告知用户栈溢出。
在kernel/exec.c中相关代码如下:
// kernel/exec.c
// Allocate two pages at the next page boundary.
// Use the second as the user stack.
sz = PGROUNDUP(sz);
if((sz = uvmalloc(pagetable, sz, sz + 2*PGSIZE)) == 0)
goto bad;
uvmclear(pagetable, sz-2*PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;
// kernel/vm.c
// mark a PTE invalid for user access.
// used by exec for the user stack guard page.
void
uvmclear(pagetable_t pagetable, uint64 va)
{
pte_t *pte; pte = walk(pagetable, va, 0);
if(pte == 0)
panic("uvmclear");
*pte &= ~PTE_U;
}
uvmclear清理掉stack guard page的PTE_U位,这样当访问到stack guard page时,就会触发page fault。这也是user/usertest.c下的stacktest的原理。
但是.....stack guard page真的能防止栈溢出么?
至少下面这种情况,不能。我们检查一下加载ELF LOAD段的代码,它是通过调用uvmalloc函数,确立ELF LOAD段的相关页面的虚实映射关系的。那么ELF LOAD段的权限是什么?
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
char *mem;
uint64 a; if(newsz < oldsz)
return oldsz; oldsz = PGROUNDUP(oldsz);
a = oldsz;
for(; a < newsz; a += PGSIZE){
mem = kalloc();
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
memset(mem, 0, PGSIZE);
if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0){
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
return newsz;
}
用户可读可写可执行!如果栈溢出没有溢出到stack guard page上,而是溢出到了.text段上,那相当于程序直接修改了程序代码.......(人工智能进化难道就是这么完成的么?)
可能有人会认为,在执行exec时,我们可以知道ELF LOAD段的结束地址,那么把这段地址记录到进程中,作为检测栈溢出的条件不行么?
有时候行,但别忘了,ELF LOAD段还有全局变量段啊!这个段应该是可读可写的!
如果一个用户程序没有全局变量,那么可以以这个条件判断栈溢出。这也是为什么Lab4 Lazy Allocation可以通过的原因,查看user/lazytest.c的代码,它是没有全局变量的,因此代码不会访问到ELF GUARD段的内容。
我们就不要再深究这其中的安全问题了,讨论到这里只是为了能帮大家理清stack guard page到底能做什么,不能做什么。在本实验的测试代码(user/cowtest.c)中和user/usertest.c中都有对全局变量的访问:
// part of user/cowtest.c char junk1[4096];
int fds[2];
char junk2[4096];
char buf[4096];
char junk3[4096]; // test whether copyout() simulates COW faults.
void
filetest()
{
printf("file: "); buf[0] = 99; for(int i = 0; i < 4; i++){
if(pipe(fds) != 0){
printf("pipe() failed\n");
exit(-1);
......
}
因此修改代码时要十分小心对越界访问的判断。
TRAMPOLINE段和TRAPFRAME段
这两个段帮助进程实现trap。
先说简单的TRAPFRAME段。这个段用于记录进程发生trap时的现场,因此这个段必须是每个进程独有的。trapframe的物理空间分配并不是在exec或者fork中完成,而是在allocproc中就已经完成了。某个进程执行exec时,TRAPFRAME -> &p->tf 间的映射关系由proc_pagetable添加:
// kernel/exec.c
// Check ELF header
if(readi(ip, 0, (uint64)&elf, 0, sizeof(elf)) != sizeof(elf))
goto bad;
if(elf.magic != ELF_MAGIC)
goto bad; if((pagetable = proc_pagetable(p)) == 0) // 此时TRAPFRAME -> &p->tf间的关系已经写入到pagetable中
goto bad;
TRAMPOLINE段就比较难理解了。首先要明确,TRAMPOLINE是一个虚地址,而单独讨论虚地址是没有意义的,只有这个虚地址存在到实地址的映射时,才有意义。这个映射在xv6的进程中是存在的,也是由proc_pagetable来完成添加,将所有进程的TRAMPOLINE段映射到了同一块代码区域,这块区域的代码逻辑就是/kernel/trampoline.S,即trap处理的入口。
STACK段和HEAP段
首先思考一个问题:xv6进程每个段的起始虚地址在哪里?
ELF LOAD段的虚地址是从0开始的,TRAMPOLINE段永远放在虚地址的最高处(MAXVA),占据一页,因此虚地址就是MAXVA - PGSIZE。TRAPFRAME和TRAMPOLINE是紧挨着的(它们之间有没有guard page我忘了,当没有吧),因此起始虚地址就是MAXVA - 2*PGSIZE。
那么STACK段和HEAP段的起始虚地址呢?
阅读kernel/exec.c源码后我们可以得出结论:STACK段的起始虚地址只有在加载完ELF LOAD段后才能确定。这个地址位于stack guard page的上方一页,而stack guard page也是在ELF LOAD段加载完后才确定的。
当ELF LOAD段、STACK段、stack guard page段、TRAMPOLINE段、TRAMFRAME段都确认后,中间那块剩余的区域,就是HEAP段了,也就是动态内存所处的段。查看一下kernel/proc.h中定义的进程的数据结构:
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Bottom of kernel stack for this process
uint64 ustackbase;
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // Page table
struct trapframe *tf; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
注意到sz这个变量。对于一个进程p来说,虚地址空间[0, p->sz),覆盖了ELF LOAD段、stack guard page段、STACK段的虚地址空间,以及当前已经分配的堆空间。
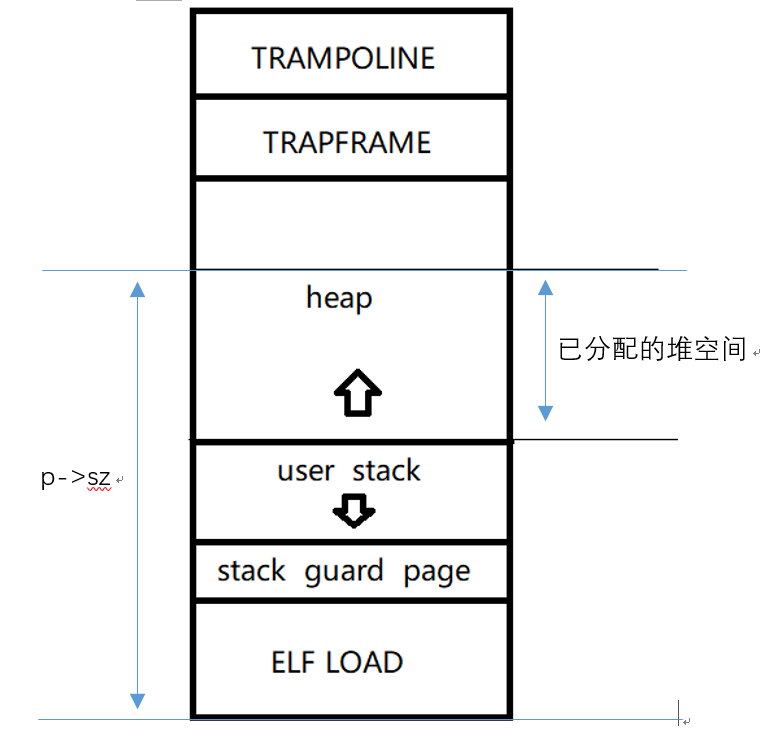
调用exec结束时,p->sz的初始值就被设定为了user stack的结尾处,即当前已分配的堆空间大小为0.
Copy-On-Write fork的引入
回顾完xv6的进程结构之后,我们可以思考一下,一个fork要完成哪些操作?
首先,必须要调用allocproc,当allocproc成功返回时,TRAMPOLINE和TRAPFRAME这两个段已经完成了初始化,因此无需处理。剩余的四个段(HEAP、STACK、STACK GUARD、ELF LOAD)都需要拷贝一份给新的进程。
这样我们会遇到以下问题:
(1)很多时候,我们调用fork,就是为了调用exec,而exec会释放掉[0, p->sz)之间的所有内容,那么[0, p->sz)这块空间,还没有被访问过一次,就被我们丢掉了。
(2)即使我们调用了fork而不调用exec,对于HEAP段的数据,大多时候的操作很可能是读操作,这个时候HEAP段完全可以和父进程共用。
(3)ELF LOAD段包含了不可写的代码段(.text),至少这个段是可以父子进程共享的。
Copy-On-Write fork的引入可以解决上述问题。当发生fork时,子进程并不会将父进程的[0, p->sz)这块空间拷贝一份留给自己,而是仅仅修改自己的进程页表,将[0, p->sz)映射到相同的实存区域,这块区域我们暂且称之为F区域。当父进程或者子进程对F区域的任意一页进行写操作时,才复制这一页。
分析与设计
Lab的主页已经告诉了我们大致的做法:
Modify uvmcopy() to map the parent's physical pages into the child, instead of allocating new pages, and clear PTE_W in the PTEs of both child and parent.
Modify usertrap() to recognize page faults. When a page-fault occurs on a COW page, allocate a new page with kalloc(), copy the old page to the new page,
and install the new page in the PTE with PTE_W set.
大致的设计如下:
(0)发生pagefault的原因有很多,可能是越界访问,也可能是访问了F区域的页面。为了能区分,我们需要给F区域的页面添加一个标志位PTE_F。若一个页面存在PTE_F位,那么这个页面一定发生了cow fork。
(1)由于存在多个虚地址映射到同一个实地址的情况,因此进程在结束后释放页面时,如果页面还在被其他进程所引用,那么就不能释放掉这个页面。为此我们需要添加数据结构,记录每个页面的引用计数。
(2)修改uvmcopy代码:
如果一个页面即没有PTE_W位也没有PTE_F位,那这个页面必定不可写,我们可以放心的让本进程引用这个页面,给它添不添加PTE_F并不会影响结果
如果一个页面存在PTE_W位,这个页面的引用计数必定为1,我们需要同时修改父子进程的相应的pte,清除掉它们的PTE_W位,替换成PTE_F位。
如果一个页面存在PTE_F位,那么就说明其它进程尚未对这个页面执行过写操作,新进程也可以放心的引用这个页面,并拷贝这个页面的权限就可以了;
(3)在trap中添加cow_handler,通过检查PTE_F位是否存在来判断是否是访问了F区域的页面。如果是,那么拷贝一份这个页面,清除这个页面的PTE_F位,重置为PTE_W位,删除掉旧页面的虚实映射关系,添加新页面到该虚地址的虚实映射关系,让就业面的引用计数减1。
(4)在usertrap中添加了cow_handler后,我们处理来自用户态访问F区域页面引起的page fault。但如果用户程序是调用write来对F区域页面进行写操作时,对F区域页面的写是在内核态完成的(sys_write)。因此需要另行处理。具体方法是修改kernel/vm.c下的copyout函数,查看用户进程的页表并检查flags。
实现
(0)创立新的页表位 PTE_F:
// kernel/riscv.h
#define PTE_V (1L << 0) // valid
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // 1 -> user can access
#define PTE_F (1L << 8) // copy-on-write flag
(1)修改kernel/kalloc.c,为每个页面添加引用计数。
我在做这一部分时脑子真的进水了。刚开始的想法是设计一个链表结构,同时记录下页面的物理地址和引用计数,然后调试起来非常复杂。后来查阅其他博客才明白,页面的物理地址本身就可以作为一个索引。修改过后调试了几次就pass了.....良好的设计可以真的可以节省不少的时间。


extern char end[]; // first address after kernel.
// defined by kernel.ld. struct run {
struct run *next;
}; struct {
struct spinlock lock;
struct run *freelist;
int refcount[1 << 15];
int used;
} kmem; // Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated. int pa2pageid(void* pa);
void freerange(void *pa_start, void *pa_end);
void* allocpage();
void freepage(void* pa); void
kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
memset(&kmem.refcount, 0, sizeof(kmem.refcount));
kmem.used = 0;
} void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
freepage(p);
} // Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void* pa)
{
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree"); acquire(&kmem.lock);
if(decrease_ref(pa)) {
kmem.used--;
freepage(pa);
// printf("free page %p\n", pa);
}
release(&kmem.lock);
} void *
kalloc(void)
{
acquire(&kmem.lock);
void* page = allocpage(); if(page) {
increase_ref(page, 0);
} release(&kmem.lock);
return page;
} int
pa2pageid(void* pa)
{
return (pa - (void*)end) / PGSIZE;
} void*
allocpage()
{
struct run* r = kmem.freelist ? kmem.freelist : 0;
if(r) {
kmem.used++;
kmem.freelist = r->next;
memset((char*)r, 5, PGSIZE);
}
return r;
} void
freepage(void* pa)
{
memset(pa, 1, PGSIZE);
struct run* r = (struct run*)pa;
r->next = kmem.freelist;
kmem.freelist = r;
} void
increase_ref(void* pa, int exist)
{
int idx = pa2pageid(pa);
if(exist && kmem.refcount[idx] <= 0) {
printf("page %p should exist", pa);
panic("increase ref");
} else if(!exist && kmem.refcount[idx] > 0) {
printf("page %p should not exist", pa);
panic("increase ref");
}
kmem.refcount[idx]++;
} int
decrease_ref(void* pa)
{
int idx = pa2pageid(pa);
if(kmem.refcount[idx] <= 0) {
printf("page %p should exist");
panic("decrease ref");
} return --kmem.refcount[idx] == 0;
}
kernel/kalloc.c
(2)修改uvmcopy。fork时,仅仅修改两个进程的页表,而不申请新的内存空间:
// Given a parent process's page table, copy
// its memory into a child's page table.
// Copies both the page table and the
// physical memory.
// returns 0 on success, -1 on failure.
// frees any allocated pages on failure.
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags; for(i = 0; i < sz; i += PGSIZE) {
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present"); pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte); // if PTE_W or PTE_F is set, then this page doesn't cow-fork and maybe be shared
// so simply increase refcount is ok
// if page could write, set PTE_F flag and clean PTE_W flag for both old and new pagetable
if(*pte & PTE_F || *pte & PTE_W) {
if(0 != mappages(new, i, PGSIZE, pa, (flags & (~PTE_W)) | PTE_F))
goto err;
// we need also adjust page perm for parent process
*pte = PA2PTE(pa) | (flags & (~PTE_W)) | PTE_F;
} else {
if(0 != mappages(new, i, PGSIZE, pa, flags))
goto err;
} increase_ref((void*)pa, 1);
} return 0; err:
uvmunmap(new, 0, i, 1);
// withdraw cow-fork's change on origin thread
for(int j = 0; j <= i; j += PGSIZE) {
pte = walk(old, j, 0);
flags = PTE_FLAGS(*pte);
if(flags & PTE_F) {
flags = (flags & (~PTE_F)) | PTE_W;
pa = PTE2PA(*pte);
*pte = PA2PTE(pa) | flags;
}
}
return -1;
}
(3)在usertrap中添加cow_handler。访问F区域时发生的trap编号仍然是13或15。
我在做这个lab时犯的另一个巨大失误是把panic当做assert一样胡乱使用。panic的原意是“内核不知道自己应该怎么做”,换句话说,只有在出现“内核进入了不应该进入的状态”的情况下,才应该使用panic。大部分情况下,我们认为的“错误”是用户自己作死搞出来的,并不是内核的错,遇到这种情况应当把这个用户进程kill掉,而不是调用panic。
还有一个重大失误,算是写类似代码写多了产生的误区。我写代码的时候总是习惯“return as early as possible”,即尽早返回特殊情况。这样代码逻辑会清晰很多(最主要的是缩进会变少,我只要看到某段代码缩进超过4个心口就会隐隐作痛 →_→)。所以cow_handler刚开始的结构大概是这样的:
int
cowhandler(pagetable_t pagetable, uint64 va)
{
if(situation1)
return -1;
if(situation2)
return -1; ........ finally , this should be a cow-page-fault
if is not a cow-page-fault {
panic("not a cow-pate-fault");
} handle it
}
然后跑usertest的时候,疯狂panic.....
思考后发现,这个cowhandler出现的条件是非常严格的,即相应页面必须有PTE_F位,其他情况下都应当把这个进程kill掉,而不是内核去panic。最终修改后的代码如下,如果不符合cow_handler的条件,直接返回-1,把这个进程kill掉。
// kernel/vm.c
// success return 0, failed return -1
int
cow_handler(pagetable_t pagetable, uint64 va)
{
// return 0;
if(0 == pagetable)
panic("no page table\n"); // out of range access
if(myproc()->sz <= va) {
printf("process %d , assess %d\n", myproc()->pid, (uint64)va);
printf("process size %d, stack guard %d\n", myproc()->sz, myproc()->ustackbase);
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), myproc()->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
myproc()->killed = 1;
return -1;
} // find corresponding pte
uint64 vabase = PGROUNDDOWN(va);
pte_t* pte;
if((pte = walk(pagetable, vabase, 0)) == 0)
panic("page should exist"); // cow pagefault situation:
uint flags = PTE_FLAGS(*pte);
if(!(flags & PTE_F && (flags & PTE_W) == 0)) {
return -1;
} // allocate a new page and recalculate it's perm
void* mem = kalloc();
if(0 == mem)
panic("no memory avaliable"); // free origin pte and page
memmove(mem, (void*)PTE2PA(*pte), PGSIZE);
kfree((void*)PTE2PA(*pte));
*pte = 0; // map it
flags = (flags & (~PTE_F)) | PTE_W;
if(mappages(pagetable, vabase, PGSIZE, (uint64)mem, flags))
return -1; return 0;
}
将这个handler添加到usertrap中:
void
usertrap(void)
{
int which_dev = 0; if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode"); // send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec); struct proc *p = myproc(); // save user program counter.
p->tf->epc = r_sepc(); if(r_scause() == 8){
// system call if(p->killed)
exit(-1); // sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->tf->epc += 4; // an interrupt will change sstatus &c registers,
// so don't enable until done with those registers.
intr_on(); syscall();
} else if((which_dev = devintr()) != 0){
// ok
} else if(r_scause() == 13 || r_scause() == 15) {
// printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
// printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
if(cow_handler(myproc()->pagetable, r_stval()) != 0) {
p->killed = 1;
}
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
vmprint(p->pagetable);
p->killed = 1;
} if(p->killed)
exit(-1); // give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield(); usertrapret();
}
(4)处理内核态下对F区域页面的写操作:
其实就是修改copyout的代码,添加上对flags的检查,然后使用(3)中的cow_handler函数就可以了:
// kernel/vm.c
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
pte_t* pte;
if(dstva > MAXVA)
return -1; while(len > 0){
va0 = PGROUNDDOWN(dstva);
pte = walk(pagetable, va0, 0); if(0 == pte) {
panic("copyout : pte should exist");
}
if(*pte & PTE_F) {
if(cow_handler(pagetable, va0) != 0) {
panic("copyout : handle cow failed");
}
pa0 = walkaddr(pagetable, va0);
} else {
pa0 = walkaddr(pagetable, va0);
} if(pa0 == 0)
return -1; n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n); len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
还有不少琐碎的地方.....就不贴上来了。这个Lab应该是近几个Lab中最简单的了。
测试全部通过:
xv6 kernel is booting virtio disk init 0
hart 2 starting
hart 1 starting
init: starting sh
$ cowtest
simple: ok
simple: ok
three: ok
three: ok
three: ok
file: ok
ALL COW TESTS PASSED
$ usertests
usertests starting
test reparent2: OK
test pgbug: OK
test sbrkbugs: usertrap(): unexpected scause 0x000000000000000c pid=3220
sepc=0x0000000000004430 stval=0x0000000000004430
page table 0x00000000861f5000
..0: pte 0x0000000021882801 pa 0x000000008620a000 perm : PTE_V|
.. ..0: pte 0x0000000021882c01 pa 0x000000008620b000 perm : PTE_V|
..255: pte 0x0000000021fd1001 pa 0x0000000087f44000 perm : PTE_V|
.. ..511: pte 0x0000000021882401 pa 0x0000000086209000 perm : PTE_V|
.. .. ..510: pte 0x00000000218830c7 pa 0x000000008620c000 perm : PTE_V|PTE_R|PTE_W|
.. .. ..511: pte 0x000000002000204b pa 0x0000000080008000 perm : PTE_V|PTE_R|PTE_X|
usertrap(): unexpected scause 0x000000000000000c pid=3221
sepc=0x0000000000004430 stval=0x0000000000004430
page table 0x00000000861e2000
..0: pte 0x0000000021877c01 pa 0x00000000861df000 perm : PTE_V|
.. ..0: pte 0x0000000021878001 pa 0x00000000861e0000 perm : PTE_V|
.. .. ..0: pte 0x00000000216d2d1b pa 0x0000000085b4b000 perm : PTE_V|PTE_R|PTE_X|PTE_U|PTE_F|
..255: pte 0x0000000021878c01 pa 0x00000000861e3000 perm : PTE_V|
.. ..511: pte 0x0000000021876c01 pa 0x00000000861db000 perm : PTE_V|
.. .. ..510: pte 0x00000000218830c7 pa 0x000000008620c000 perm : PTE_V|PTE_R|PTE_W|
.. .. ..511: pte 0x000000002000204b pa 0x0000000080008000 perm : PTE_V|PTE_R|PTE_X|
OK
test badarg: OK
test reparent: OK
test twochildren: OK ........ test sbrkarg: OK
test validatetest: OK
test stacktest: OK
test opentest: OK
test writetest: OK
test writebig: OK
test createtest: OK
test openiput: OK
test exitiput: OK
test iput: OK
test mem: OK
test pipe1: OK
test preempt: kill... wait... OK
test exitwait: OK
test rmdot: OK
test fourteen: OK
test bigfile: OK
test dirfile: OK
test iref: OK
test forktest: OK
test bigdir: OK
ALL TESTS PASSED
MIT 6.S081 Lab5 Copy-On-Write Fork的更多相关文章
- MIT 6.S081 xv6调试不完全指北
前言 今晚在实验室摸鱼做6.S081的Lab3 Allocator,并立下flag,改掉一个bug就拍死一只在身边飞的蚊子.在击杀8只蚊子拿到Legendary后仍然没能通过usertest,人已原地 ...
- MIT 6.S081 Lab File System
前言 打开自己的blog一看,居然三个月没更新了...回想一下前几个月,开题 + 实验室杂活貌似也没占非常多的时间,还是自己太懈怠了吧,掉线城和文明6真的是时间刹手( 不过好消息是把15445的所有l ...
- MIT 6.S081 聊聊xv6中的文件系统(上)
前言 Lab一做一晚上,blog一写能写两天,比做Lab的时间还长( 这篇博文是半夜才写完的,本来打算写完后立刻发出来,但由于今天发现白天发博点击量会高点,就睡了一觉后才发(几十的点击量也是点击量啊T ...
- MIT 6.S081 聊聊xv6的文件系统(中)日志层与事务
前言 我本想把上篇中没讲完的剩余层全部在本篇中讲完,但没想到越写越多.日志层的代码不多,其思想和解决问题的手段也不算难以理解,但其背后涉及的原理和思想还是非常值得回味的,因此我打算用一整篇完整的blo ...
- COW奶牛!Copy On Write机制了解一下
前言 只有光头才能变强 在读<Redis设计与实现>关于哈希表扩容的时候,发现这么一段话: 执行BGSAVE命令或者BGREWRITEAOF命令的过程中,Redis需要创建当前服务器进程的 ...
- clone的fork与pthread_create创建线程有何不同&pthread多线程编程的学习小结(转)
进程是一个指令执行流及其执行环境,其执行环境是一个系统资源的集合,这些资源在Linux中被抽 象成各种数据对象:进程控制块.虚存空间.文件系统,文件I/O.信号处理函数.所以创建一个进程的 过程就是这 ...
- 【MIT6.S081/6.828】手把手教你搭建开发环境
目录 1. 简介 2. 安装ubuntu20.04 3. 更换源 3.1 更换/etc/apt/sources.list文件里的源 3.2 备份源列表 3.3 打开sources.list文件修改 3 ...
- Bootstrap看厌了?试试Metro UI CSS吧
(此文章同时发表在本人微信公众号"dotNET每日精华文章",欢迎右边二维码来关注.) 题记:Bootstrap作为一款超级流行的前端框架,已经成为很多人的首选,不过有时未免有点审 ...
- Linux线程学习(二)
线程基础 进程 系统中程序执行和资源分配的基本单位 每个进程有自己的数据段.代码段和堆栈段 在进行切换时需要有比较复杂的上下文切换 线程 减少处理机的空转时间,支持多处理器以及减少上下文切换开销, ...
随机推荐
- SQL实战——02. 查找入职员工时间排名倒数第三的员工所有信息
查找入职员工时间排名倒数第三的员工所有信息CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_date` date NOT NULL, ...
- OneWire总线的Arduino库函数
OneWire总线基本点 One-wire总线是DALLAS公司研制开发的一种协议,采用单根信号线,既传输时钟,又传输数据而且数据传输是双向的.它具有节省I/O 口线资源.结构简单.成本低廉.便于总线 ...
- HashMap 、ConcurrentHashMap知识点全解析
散列表 在了解hashmap之前,要先知道什么是散列表,因为hashmap就是在散列表结构基础上改造而成的.散列表,也叫哈希表,是根据关键码值(key value)而直接进行访问的数据结构.也就是说, ...
- 洛谷P1450 [HAOI2008]硬币购物 背包+容斥
无限背包+容斥? 观察数据范围,可重背包无法通过,假设没有数量限制,利用用无限背包 进行预处理,因为实际硬币数有限,考虑减掉多加的部分 如何减?利用容斥原理,减掉不符合第一枚硬币数的,第二枚,依次类推 ...
- 如果你想or即将成为一名程序员,那你需要知道这些东西!上岗须知~
前两天公司学院的同学给我看了一下即将入职的应届生的数量,真是不少.感慨一下,一批新人即将到来,而自己又老去了一岁.码农是一个必将终身学习的职业.而相关的知识越来越多了.接下来该学什么?接下来该干什么? ...
- lumen-ioc容器测试 (4)
lumen-ioc容器测试 (1) lumen-ioc容器测试 (2) lumen-ioc容器测试 (3) lumen-ioc容器测试 (4) lumen-ioc容器测试 (5) lumen-ioc容 ...
- ansible使用script模块在受控机上执行脚本(ansible2.9.5)
一,ansible的script模块的用途 script 模块用来在远程主机上执行 ansible 管理主机上的脚本, 即:脚本一直存在于 ansible 管理主机本地, 不需要手动拷贝到远程主机后再 ...
- centos8平台使用ip命令代替ifconfig管理网络
一,为什么建议使用ip命令代替ifconfig? 1,ifconfig所属的net-tools包已经不再被维护了 虽然可以用,但会发生看不到部分ip等情况, [root@centos8 liuhong ...
- phpstorm 使用xdebug
一.在phpstudy配置 开启xdebug的zend扩展,在php.ini 中添加下面的代码: [xdebug] zend_extension = "D:\phpstudy_pro\Ext ...
- 因果推理综述——《A Survey on Causal Inference》一文的总结和梳理
因果推理 本文档是对<A Survey on Causal Inference>一文的总结和梳理. 论文地址 简介 关联与因果 先有的鸡,还是先有的蛋?这里研究的是因果关系,因果关系与普通 ...