一致性HASH算法在分布式应用场景使用
其实不管redis还好,Mysql也好 这种数据存储介质,在分布式场景中都存在共同问题:即集群场景下服务路由。比如redis集群场景下,原本我们分3主3从部署。但万一有一天出现访问量暴增或其中一台机器挂了的场景,那么服务路由(一般采用HASH取模定位的方式)重新计算后 会面临数据在新的节点找不到,于是乎又会走DB查询数据进缓存,如果又是流量很大的场景,会给数据库造成不少压力。如果有一种算法,无论遇到扩容、缩容问题,最终受影响面足够小,即只有部分数据可能需要重新落DB,其他还是能正确找到对应缓存机器节点,那这是最好的。以下文章 是摘自知乎上阿里工程师的一篇原文,还是比较赞许作者以图文思路,比较通俗易懂的文字,讲清楚了一致性HASH算法;推荐你阅读...
以下是原文:
最近有小伙伴跑过来问什么是Hash一致性算法,说面试的时候被问到了,因为不了解,所以就没有回答上,问我有没有相应的学习资料推荐,当时上班,没时间回复,晚上回去了就忘了这件事,今天突然看到这个,加班为大家整理一下什么是Hash一致性算法,希望对大家有帮助!文末送书,长按抽奖助手小程序即可参与,祝君好运!
经常阅读我文章的小伙伴应该都很熟悉我写文章的套路,上来就是先要问一句为什么?也就是为什么要有Hash一致性算法?就像以前介绍为什么要有Spring一样,首先会以历史的角度或者项目发展的角度来分析,今天的分享还是一样的套路,先从历史的角度来一步步分析,探讨一下到底什么是Hash一致性算法!
一、Redis集群的使用
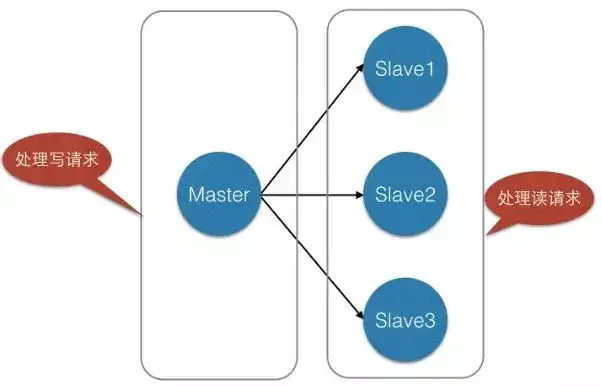
我们在使用Redis的时候,为了保证Redis的高可用,提高Redis的读写性能,最简单的方式我们会做主从复制,组成Master-Master或者Master-Slave的形式,或者搭建Redis集群,进行数据的读写分离,类似于数据库的主从复制和读写分离。如下所示:
同样类似于数据库,当单表数据大于500W的时候需要对其进行分库分表,当数据量很大的时候(标准可能不一样,要看Redis服务器容量)我们同样可以对Redis进行类似的操作,就是分库分表。
假设,我们有一个社交网站,需要使用Redis存储图片资源,存储的格式为键值对,key值为图片名称,value为该图片所在文件服务器的路径,我们需要根据文件名查找该文件所在文件服务器上的路径,数据量大概有2000W左右,按照我们约定的规则进行分库,规则就是随机分配,我们可以部署8台缓存服务器,每台服务器大概含有500W条数据,并且进行主从复制,示意图如下:
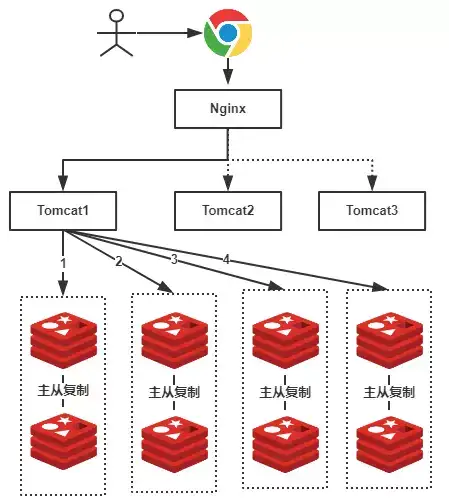
由于规则是随机的,所有我们的一条数据都有可能存储在任何一组Redis中,例如上图我们用户查找一张名称为”a.png”的图片,由于规则是随机的,我们不确定具体是在哪一个Redis服务器上的,因此我们需要进行1、2、3、4,4次查询才能够查询到(也就是遍历了所有的Redis服务器),这显然不是我们想要的结果,有了解过的小伙伴可能会想到,随机的规则不行,可以使用类似于数据库中的分库分表规则:按照Hash值、取模、按照类别、按照某一个字段值等等常见的规则就可以出来了!好,按照我们的主题,我们就使用Hash的方式。
二、为Redis集群使用Hash
可想而知,如果我们使用Hash的方式,每一张图片在进行分库的时候都可以定位到特定的服务器,示意图如下:
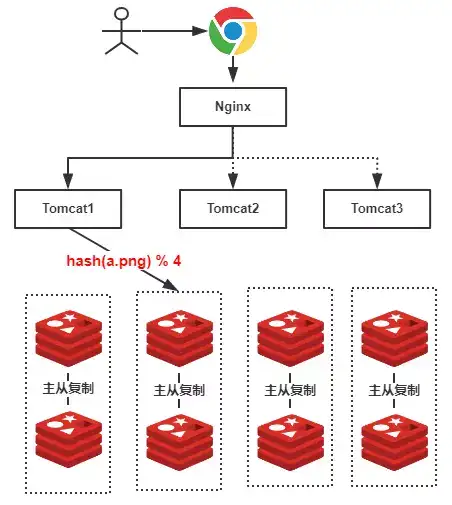
上图中,假设我们查找的是”a.png”,由于有4台服务器(排除从库),因此公式为hash(a.png) % 4 = 2 ,可知定位到了第2号服务器,这样的话就不会遍历所有的服务器,大大提升了性能!
三、使用Hash的问题
上述的方式虽然提升了性能,我们不再需要对整个Redis服务器进行遍历!但是,使用上述Hash算法进行缓存时,会出现一些缺陷,主要体现在服务器数量变动的时候,所有缓存的位置都要发生改变!
试想一下,如果4台缓存服务器已经不能满足我们的缓存需求,那么我们应该怎么做呢?很简单,多增加几台缓存服务器不就行了!假设:我们增加了一台缓存服务器,那么缓存服务器的数量就由4台变成了5台。那么原本hash(a.png) % 4 = 2 的公式就变成了hash(a.png) % 5 = ? , 可想而知这个结果肯定不是2的,这种情况带来的结果就是当服务器数量变动时,所有缓存的位置都要发生改变!换句话说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端数据库请求数据(还记得上一篇的《缓存雪崩》吗?)!
同样的,假设4台缓存中突然有一台缓存服务器出现了故障,无法进行缓存,那么我们则需要将故障机器移除,但是如果移除了一台缓存服务器,那么缓存服务器数量从4台变为3台,也是会出现上述的问题!
所以,我们应该想办法不让这种情况发生,但是由于上述Hash算法本身的缘故,使用取模法进行缓存时,这种情况是无法避免的,为了解决这些问题,Hash一致性算法(一致性Hash算法)诞生了!
四、一致性Hash算法的神秘面纱
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下:
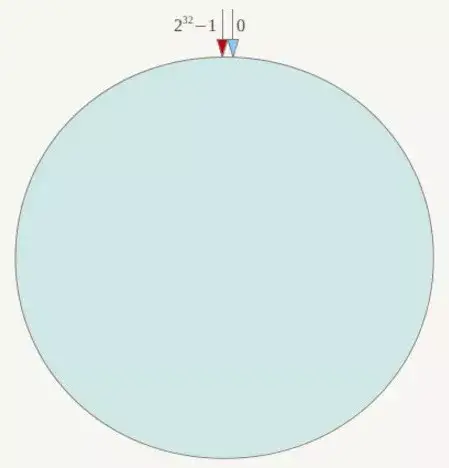
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用IP地址哈希后在环空间的位置如下:
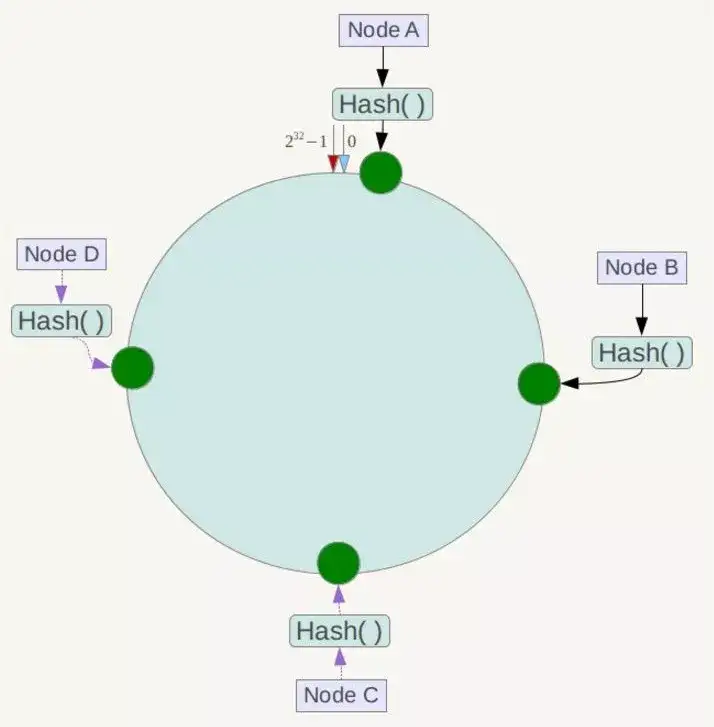
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
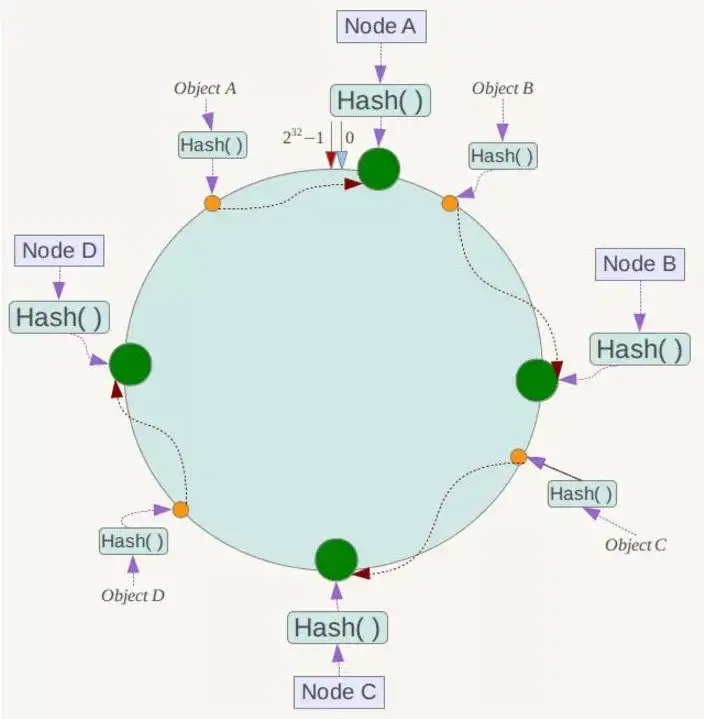
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
五、一致性Hash算法的容错性和可扩展性
现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响,如下所示:
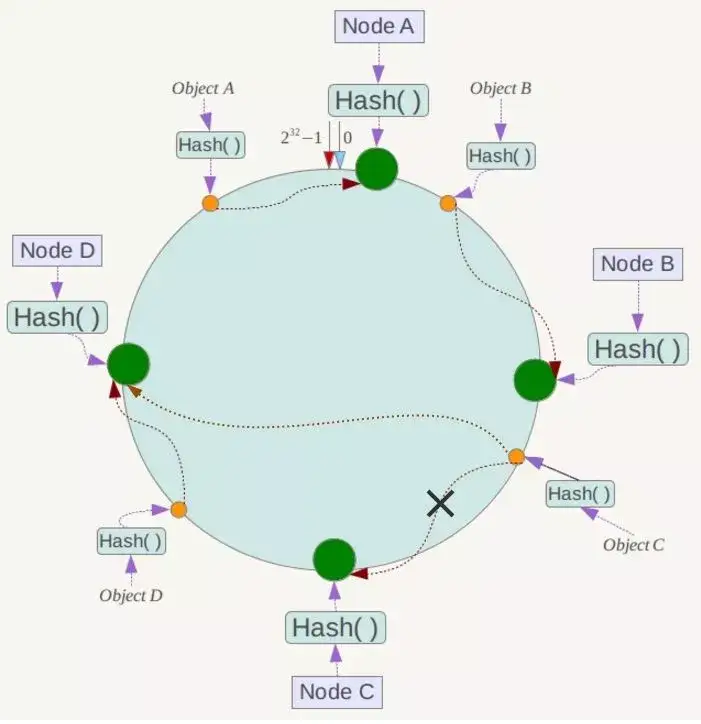
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
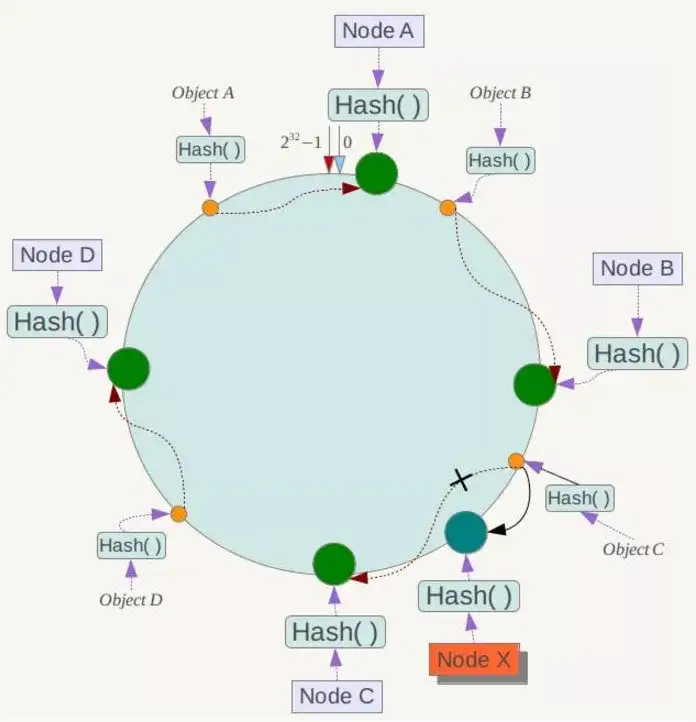
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X !一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
六、Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下: 
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
七、总结
上文中,我们一步步分析了什么是一致性Hash算法,主要是考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来的情况,如何保证当系统的节点数目发生变化的时候,我们的系统仍然能够对外提供良好的服务,这是值得考虑的!
摘自-https://zhuanlan.zhihu.com/p/34985026
一致性HASH算法在分布式应用场景使用的更多相关文章
- 一致性Hash算法及使用场景
一.问题产生背景 在使用分布式对数据进行存储时,经常会碰到需要新增节点来满足业务快速增长的需求.然而在新增节点时,如果处理不善会导致所有的数据重新分片,这对于某些系统来说可能是灾难性的. 那 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性 hash 算法( consistent hashing )a
一致性 hash 算法( consistent hashing ) 张亮 consistent hashing 算法早在 1997 年就在论文 Consistent hashing and rando ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 分布式算法(一致性Hash算法)
一.分布式算法 在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法( ...
- Java实现一致性Hash算法深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中”一致性Hash算法”部分,对于为什么要使用一致性Hash算法和一致性Hash算法的算法原 ...
- [速成]了解一致性hash算法
定义 一致性hash算法,在维基百科的定义是: Consistent hashing is a special kind of hashing such that when a hash table ...
- 一致性Hash算法与代码实现
一致性Hash算法: 先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值 ...
- 一致性hash算法及java实现
一致性hash算法是分布式中一个常用且好用的分片算法.或者数据库分库分表算法.现在的互联网服务架构中,为避免单点故障.提升处理效率.横向扩展等原因,分布式系统已经成为了居家旅行必备的部署模式,所以也产 ...
随机推荐
- ERP费用报销操作与设计--开源软件诞生31
赤龙ERP费用报销讲解--第31篇 用日志记录"开源软件"的诞生 [进入地址 点亮星星]----祈盼着一个鼓励 博主开源地址: 码云:https://gitee.com/redra ...
- 转:使用DOS命令chcp查看windows操作系统的默认编码以及编码和语言的对应关系
代码页是字符集编码的别名,也有人称"内码表".早期,代码页是IBM称呼电脑BIOS本身支持的字符集编码的名称.当时通用的操作系统都是命令行界面系统,这些操作系统直接使用BIOS供应 ...
- PyQt(Python+Qt)学习随笔:QCommandLinkButton的特征及用途
CommandLinkButton是Windows Vista引入的新控件,,它的预期用途与单选按钮类似,用于在一组互斥选项之间进行选择.命令链接按钮不应单独使用,而应作为向导和对话框中单选按钮的替代 ...
- LoadRunner 多用户并发 登录,上传数据,登出的脚本教程
这里记录 Web/Http 模式,模拟多用户并发进行 : 登录,上传数据,退出登录一整套流程.并发的用户量多少,可自定义.这里不介绍录屏的方式,是自己写脚本去执行的. 1.安装loadRunner ...
- 米酷CMS 7.0.4代码审计
工具:seay源代码审计系统 源代码:网上很好找,这里就懒得贴上了,找不到的话可以给我留言 后面一段时间会深入学习安全开发,代码审计,内网渗透和免杀,快快成长. 审这个系统是因为在先知上看到一篇审它老 ...
- AcWing 404. 婚礼
大型补档计划 题目链接 根据题意,显然只有新郎这边可能存在矛盾,考虑这边怎么放即可,新娘那边的放法与这边正好相反且一一对应. 显然对于两个约束条件是一对矛盾,开始我以为可以用并查集,后来发现输出方案的 ...
- git学习——git命令之创建版本库和版本退回
原文来至 一.创建版本库 版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改.删除,Git都能跟踪,以便任何时刻都可以追 ...
- (干货)构建镜像之Dockerfile
Dockerfile是一个文本文件,记录了镜像构建的所有步骤. 饭提示:学习Dockerfile构建镜像,就是在学习Dockerfile文件构建的命令+shell脚本语句 Dockerfile简单介绍 ...
- Typora快捷使用方式
快捷使用: 1.一级标题 # + 空格 + 内容 2.六级标题 # + 空格 + 内容 3.有序序号 1. + 空格 + 内容 4.无序序号 -+ 空格.*+空格.++空格 5.代码块 ```pyth ...
- centos 7系统安装mysql 8.0
一.关闭防火墙 [root@node01 ~]# systemctl disable firewalld [root@node01 ~]# systemctl stop firewalld [root ...