Gitlab Runner的分布式缓存实战
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
关于本文
本文目标是为K8S环境的Gitlab Runner准备好分布式缓存,并在pipeline脚本中使用该缓存,因此,在阅读本文前建议您对GitLab CI有一定了解,最好是阅读过甚至编写过pipeline脚本;
关于GitLab Runner
如下图所示,开发者将代码提交到GitLab后,可以触发CI脚本在GitLab Runner上执行,通过编写CI脚本我们可以完成很多使用的功能:编译、构建、生成docker镜像、推送到私有仓库等:
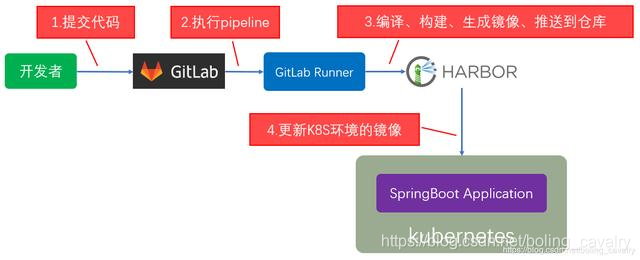
Gitlab Runner的分布式缓存
- 官方文档地址,有关缓存的详情可以参考此文:https://docs.gitlab.com/runner/configuration/autoscale.html#distributed-runners-caching
- 如下是官方的分布式缓存示例(config.toml 文件):
[[runners]]
limit = 10
executor = "docker+machine"
[runners.cache]
Type = "s3"
Path = "path/to/prefix"
Shared = false
[runners.cache.s3]
ServerAddress = "s3.example.com"
AccessKey = "access-key"
SecretKey = "secret-key"
BucketName = "runner"
Insecure = false
- 接下来通过实战完成分布式缓存配置;
环境和版本信息
本次实战涉及到多个服务,下面给出它们的版本信息供您参考:
- GitLab:Community Edition 13.0.6
- GilLab Runner:13.1.0
- kubernetes:1.15.3
- Harbor:1.1.3
- Minio:2020-06-18T02:23:35Z
- Helm:2.16.1
部署分布式缓存
- minio是兼用S3的分布式缓存,也是官方推荐使用的,如下图:
- minio作为一个独立的服务部署,我将用docker部署在服务器:192.168.50.43
- 在服务器上准备两个目录,分别存储minio的配置和文件,执行以下命令:
mkdir -p /var/services/homes/zq2599/minio/gitlab_runner \
&& chmod -R 777 /var/services/homes/zq2599/minio/gitlab_runner \
&& mkdir -p /var/services/homes/zq2599/minio/config \
&& chmod -R 777 /var/services/homes/zq2599/minio/config
- 执行docker命令创建minio服务,指定服务端口是9000,并且指定了access key(最短三位)和secret key(最短八位):
sudo docker run -p 9000:9000 --name minio \
-d --restart=always \
-e "MINIO_ACCESS_KEY=access" \
-e "MINIO_SECRET_KEY=secret123456" \
-v /var/services/homes/zq2599/minio/gitlab_runner:/gitlab_runner \
-v /var/services/homes/zq2599/minio/config:/root/.minio \
minio/minio server /gitlab_runner
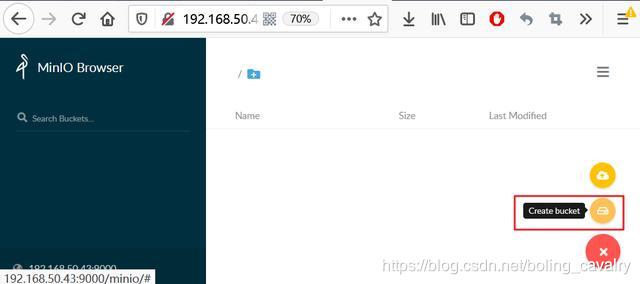
- 浏览器访问,输入access key和secret key后登录成功:

- 如下图,点击红框中的图标,创建一个bucket,名为runner:
- 至此,minio已备好,接下来在GitLab Runner上配置;
GitLab Runner上配置缓存
- 我这里是用helm部署的GitLab Runner,因此修改的是helm的value配置,如果您没有用helm,可以参考接下来的操作直接去配置config.toml文件;
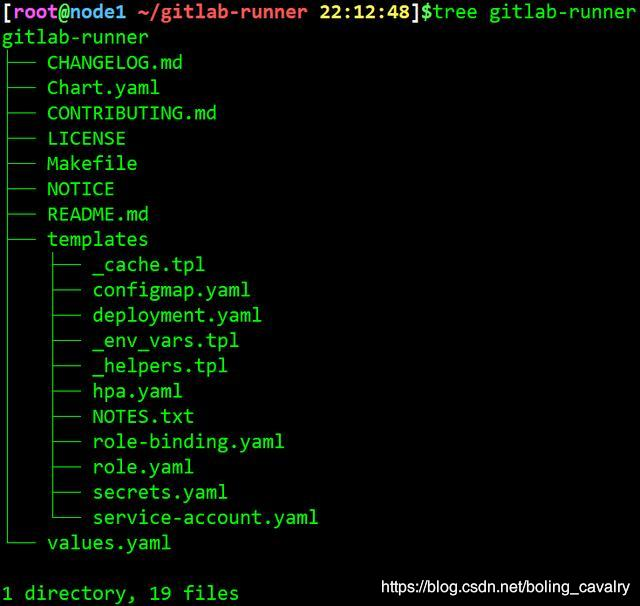
- helm下载了GitLab Runner的包后,解开可见配置信息如下:
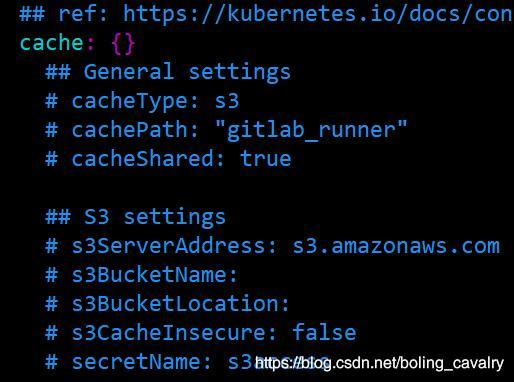
3. 打开values.yaml,找到cache的配置,当前cache的配置如下图,可见值为空内容的大括号,其余信息全部被注释了:
4. 修改后的cache配置如下图,红框1中原先的大括号已去掉,红框2中的是去掉了注释符号,内容不变,红框3中填写的是minio的访问地址,红框4中的是去掉了注释符号,内容不变:
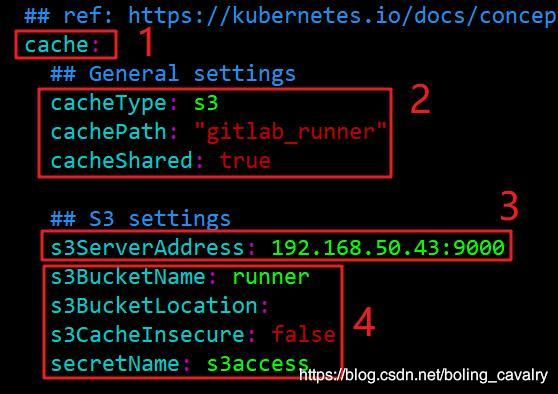
5. 上图红框4中的s3CacheInsecure参数等于false表示对minio的请求为http(如果是true就是https),但实际证明,当前版本的chart中该配置是无效的,等到运行时还是会以https协议访问,解决此问题的方法是修改templates目录下的_cache.tpl文件,打开此文件,找到下图红框中的内容:
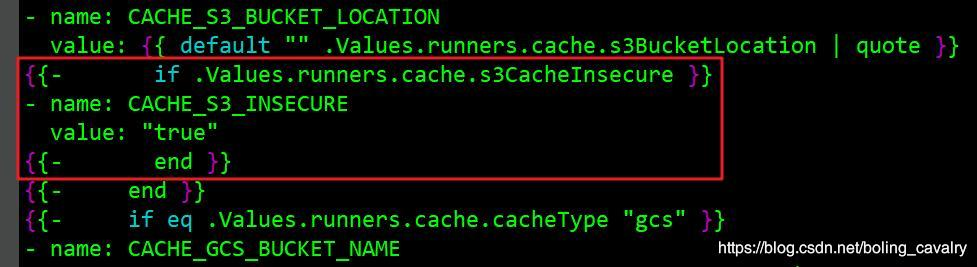
6. 将上图红框中的内容替换成下面红框中的样子,即删除原先的if判断和对应的end这两行,直接给CACHE_S3_INSECURE赋值:
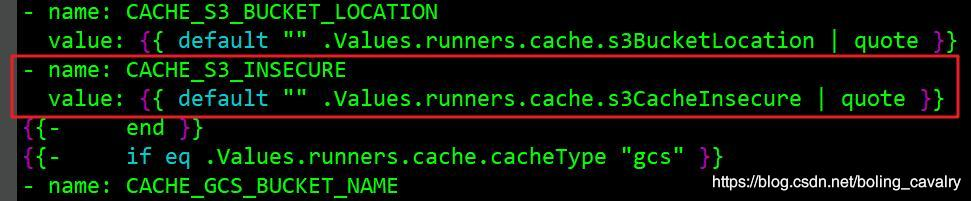
7. 以上只是cache相关的配置,helm部署GitLab Runner的其他设置还请自行处理,所有设置完成后回到values.yam所在目录,执行以下命令即可创建GitLab Runner:
helm install \
--name-template gitlab-runner \
-f values.yaml . \
--namespace gitlab-runner
- 配置完毕,启动Riglab Runner成功后,一起来验证一下;
验证
- 在GitLab仓库中,增加名为.gitlab-ci.yml的文件,内容如下:
# 设置执行镜像
image: busybox:latest
# 整个pipeline有两个stage
stages:
- build
- test
# 定义全局缓存,缓存的key来自分支信息,缓存位置是vendor文件夹
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- vendor/
before_script:
- echo "Before script section"
after_script:
- echo "After script section"
build1:
stage: build
tags:
- k8s
script:
- echo "将内容写入缓存"
- echo "build" > vendor/hello.txt
test1:
stage: test
script:
- echo "从缓存读取内容"
- cat vendor/hello.txt
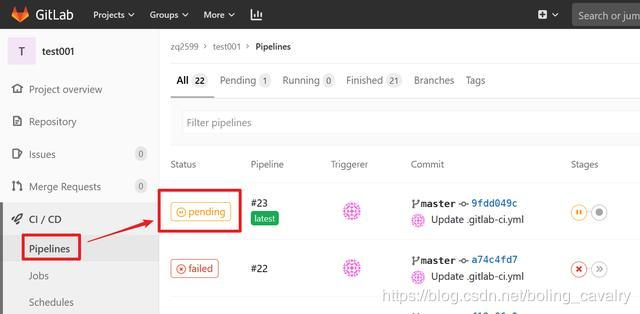
- 提交上述脚本到GitLab,如下图,可见pipeline会被触发,状态为pending是因为正在等待runner创建executor pod:
- 稍后就会执行成功,点开看结果:

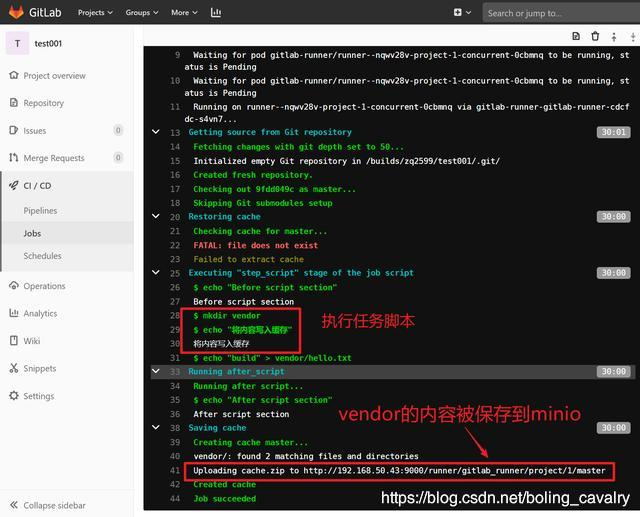
4. 点开build1的图标,可见此job的输出信息:
5. 点开test1的图标,可见对应的控制台输出,上一个job写入的数据被成功读取:
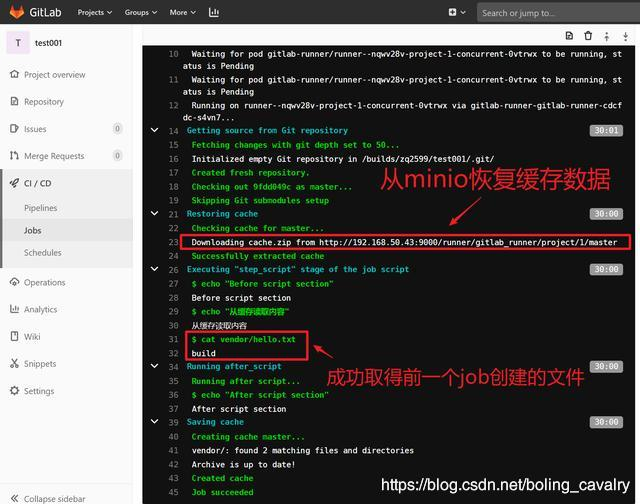
- 至此,可见分布式缓存已经生效,在多台机器的环境中也可以使用pipeline语法的缓存功能了;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Gitlab Runner的分布式缓存实战的更多相关文章
- 从Redis分布式缓存实战入手到底层原理分析、面面俱到覆盖大厂面试考点
概述 官方说明 Redis官网 https://redis.io/ 最新版本6.2.6 Redis中文官网 http://www.redis.cn/ 不过中文官网的同步更新维护相对要滞后不少时间,但对 ...
- 15套java互联网架构师、高并发、集群、负载均衡、高可用、数据库设计、缓存、性能优化、大型分布式 项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩 展 ...
- .NET分布式缓存Memcached从入门到实战
一.课程介绍 在数据驱动的web开发中,经常要重复从数据库中取出相同的数据,这种重复极大的增加了数据库负载.缓存是解决这个问题的好办法.但是ASP.NET中的虽然已经可以实现对页面局部进行缓存,但还是 ...
- .NET分布式缓存Redis从入门到实战
一.课程介绍 今天阿笨给大家带来一堂NOSQL的课程,本期的主角是Redis.希望大家学完本次分享课程后对redis有一个基本的了解和认识,并且熟悉和掌握 Redis在.NET中的使用. 本次分享课程 ...
- 【ASP.NET Core分布式项目实战】(六)Gitlab安装
Gitlab GitLab是由GitLabInc.开发,使用MIT许可证的基于网络的Git仓库管理工具,且具有wiki和issue跟踪功能.使用Git作为代码管理工具,并在此基础上搭建起来的web服务 ...
- .Net Core 跨平台开发实战-服务器缓存:本地缓存、分布式缓存、自定义缓存
.Net Core 跨平台开发实战-服务器缓存:本地缓存.分布式缓存.自定义缓存 1.概述 系统性能优化的第一步就是使用缓存!什么是缓存?缓存是一种效果,就是把数据结果存在某个介质中,下次直接重用.根 ...
- [.NET领域驱动设计实战系列]专题八:DDD案例:网上书店分布式消息队列和分布式缓存的实现
一.引言 在上一专题中,商家发货和用户确认收货功能引入了消息队列来实现的,引入消息队列的好处可以保证消息的顺序处理,并且具有良好的可扩展性.但是上一专题消息队列是基于内存中队列对象来实现,这样实现有一 ...
- 京东分布式缓存redis应用实战
互联网应用特点三高:高并发.高可用.高性能,要达到这几个目标,好的方法方式是建立相应指标, 来进行准确描述,有了准确指标进行监控,方能易于实现我们设定目标. 先将指标介绍下,方便下面相关术语使用,qp ...
- 小D课堂 - 零基础入门SpringBoot2.X到实战_第9节 SpringBoot2.x整合Redis实战_37、分布式缓存Redis介绍
笔记 1.分布式缓存Redis介绍 简介:讲解为什么要用缓存和介绍什么是Redis,新手练习工具 1.redis官网 https://redis.io/download ...
随机推荐
- LaTeX中的参考文献BibTex
设置: BibTex代码及注释: 显示效果:
- Spring Framework 5.0简述
从Spring框架5.0开始,Spring需要JDK 8+ (Java SE 8+),并且已经为JDK 9提供了现成的支持. Spring框架还支持依赖注入(JSR 330)和通用注释(JSR 250 ...
- CentOS下如何用nmon收集系统实时运行状况
#赋予执行权限 chmod +x nmon 执行./nmon可以查看实时的系统状态有提示的,d看磁盘,n看网络,c看cpu #如果不想看实时的,想收集系统长时间运行情况然后分析,可用这个 nohup ...
- 解决:com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known server
com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known serve ...
- Sql注入--数字型手工测试
Sql注入--数字型手工测试 漏洞原因:是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的"数据"拼接到SQL语句中后,被当作SQL语句的一部分执行. 从而 ...
- 在Python中使用moviepy进行音视频剪辑混音合成时输出文件无声音问题
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在使用moviepy进行音视频剪辑时发现输出成功但 ...
- 第7.12节 可共享的Python类变量
第7.12节 可共享的Python类变量 一. 引言 在上节已经引入介绍了类变量和实例变量,类体中定义的变量为类变量,默认属于类本身,实例变量是实例方法中定义的self对象的变量,对于每个实例都 ...
- 第14.11节 Python中使用BeautifulSoup解析http报文:使用查找方法快速定位内容
一. 引言 在<第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问>介绍了BeautifulSoup对象的主要属性,通过这些属性可以访 ...
- go学习的第7天
不容易啊,坚持7天了呢,今天开始看视频学习 https://www.bilibili.com/video/BV1pt41127FZ?from=search&seid=4441824587572 ...
- JAVA_数据类型介绍与基本数据类型之间的运算规则
基本数据类型 整型: byte.short.int.long java 的整型常量默认为int型,在java程序中变量通常声明为int型,除非不足以表示较大的数才用long,而在声明long型常量必须 ...