Spark3.0.1各种集群模式搭建
对于spark前来围观的小伙伴应该都有所了解,也是现在比较流行的计算框架,基本上是有点规模的公司标配,所以如果有时间也可以补一下短板。
简单来说Spark作为准实时大数据计算引擎,Spark的运行需要依赖资源调度和任务管理,Spark自带了standalone模式资源调度和任务管理工具,运行在其他资源管理和任务调度平台上,如Yarn、Mesos、Kubernates容器等。
spark的搭建和Hadoop差不多,稍微简单点,本文针对下面几种部署方式进行详细描述:
Local:多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone:Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Yarn:Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
了解一个框架最直接的方式首先要拿来玩玩,玩之前要先搭建,废话少说,进入正题,搭建spark集群。
一、环境准备
搭建环境:CentOS7+jdk8+Hadoop2.10.1+Spark3.0.1
- 机器准备,由于已经搭建过Hadoop,spark集群也是使用相同集群(个人电脑资源有限),可以参照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 需要安装jdk1.8、Scala2.12.12、hadoop2.10.1、spark3.0.1,其中jdk1.8和Hadoop2.10也都已经安装完成,这里只介绍Scala和spark环境配置
- 机器免密登录,也在Hadoop部署时做过,可以参照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 下载Scala2.12.12(https://www.scala-lang.org/download/2.12.12.html)、下载spark3.0.1(http://spark.apache.org/downloads.html)
二、配置环境变量
1.配置Scala环境
- tar -zxvf scala-2.12.12.tgz -C /opt/soft/
- cd /opt/soft
- ln -s scala-2.12.12 scala
vim /etc/profile
添加环境变量
#SCALA
export SCALA_HOME=/opt/soft/scala
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
测试是否正常

正常
2.配置spark环境变量
由于各个部署方式都需要该步骤,在此单独配置,各个部署方式不再配置
- tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /opt/soft
- cd /opt/soft
- ln -s spark-3.0.1-bin-hadoop2.7 spark
- vim /etc/profile
添加环境变量
#spark
export SPARK_HOME=/opt/soft/spark
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
三、搭建步骤
1.本地Local模式
上述已经解压配置好spark环境变量,本地模式不需要配置其他配置文件,可以直接使用,很简单吧,先测试一下运行样例:
- cd /opt/soft/spark/bin
run-example SparkPi 10

可以计算出结果
测试spark-shell
- spark-shell

启动成功,说明Local模式部署成功
2.Standalone模式
1>修改Spark的配置文件spark-env.sh
- cd /opt/soft/spark/conf
- cp spark-env.sh.template spark-env.sh
- vim spark-env.sh
添加如下配置:
- # 主节点机器名称
- export SPARK_MASTER_HOST=s141
- # 默认端口号为7077
- export SPARK_MASTER_PORT=7077
2>修改配置文件slaves(从节点配置)
- cd /opt/soft/spark/conf
- cp slaves.template slaves
- vim slaves
删除原有节点,添加从节点主机如下配置:
- s142
- s143
- s144
- s145
3>将spark目录发送到其他机器,可以使用scp一个一个机器复制,这里使用的是自己写的批量复制脚本xrsync.sh(hadoop批量命令脚本xrsync.sh传输脚本)
- xrsync.sh spark-3.0.1-bin-hadoop2.7
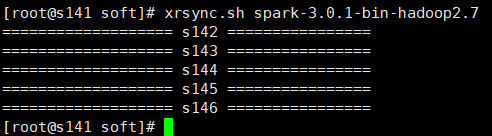
4>在各个机器中建立spark软连接,可以进入各个机器的/opt/soft目录
- ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark
这里使用的是批量执行命令脚本xcall.sh(hadoop批量命令脚本xcall.sh及jps找不到命令解决)
- xcall.sh ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark

5>启动spark集群
- cd /opt/soft/spark/sbin
- 可以单独启动master和slave
- ./start-master.sh
- ./start-slaves.sh spark://s141:7077
- 也可以一键启动master和slave
- ./start-all.sh
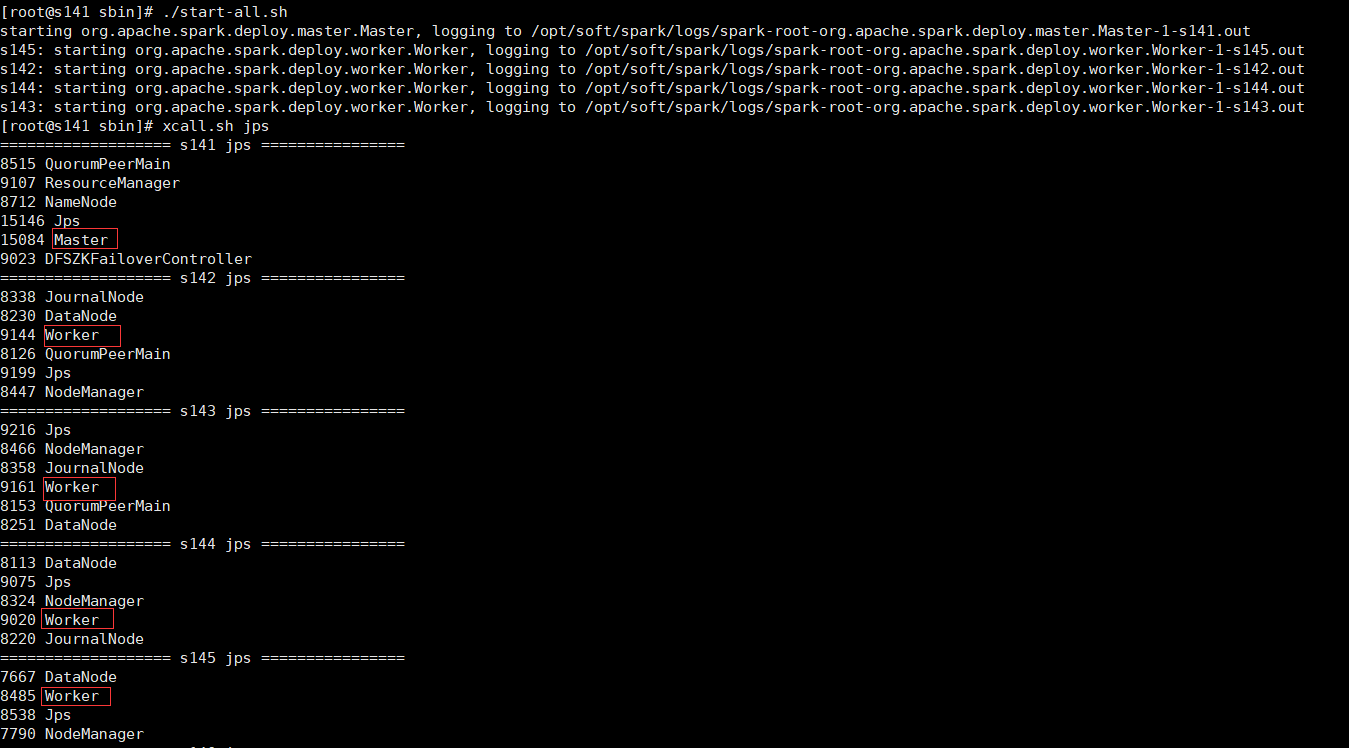
可以看到master和worker进程已经启动成功
6>查看集群资源页面(webUI:http://192.168.30.141:8080/),如果8080端口查不到可以看一下master启动日志,可能是8081端口

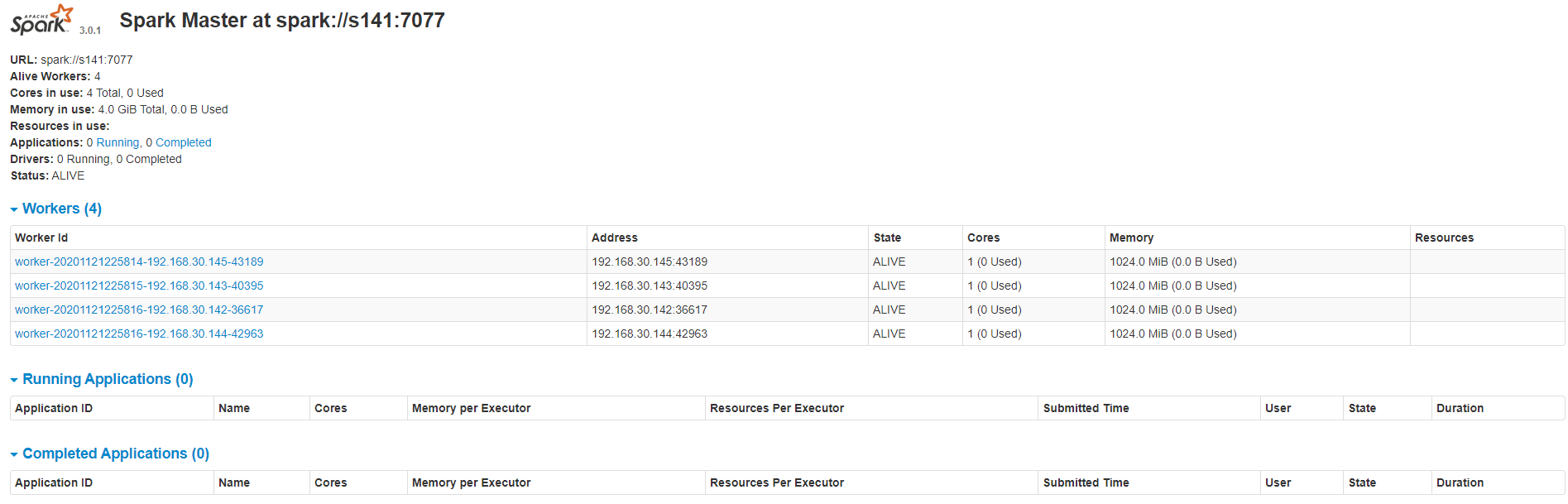
7>进入集群shell验证
- cd /opt/soft/spark/bin
./spark-shell –master spark://s141:7077

也是正常的,说明Standalone模式部署成功
3.yarn集群模式
1>修改配置文件spark-env.sh
在Standalone模式下搭建yarn集群模式很简单,只需要在spark-env.sh配置文件加入如下内容即可。
- # 添加hadoop的配置目录
- export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop
将spark-env.sh分发到各个机器

4>启动spark集群
先启动Hadoop的yarn集群
- start-yarn.sh
再启动spark集群,和Standalone模式一样有两种方式
- cd /opt/soft/spark/sbin
- 可以单独启动master和slave
- ./start-master.sh
- ./start-slaves.sh spark://s141:7077
- 也可以一键启动master和slave
- ./start-all.sh
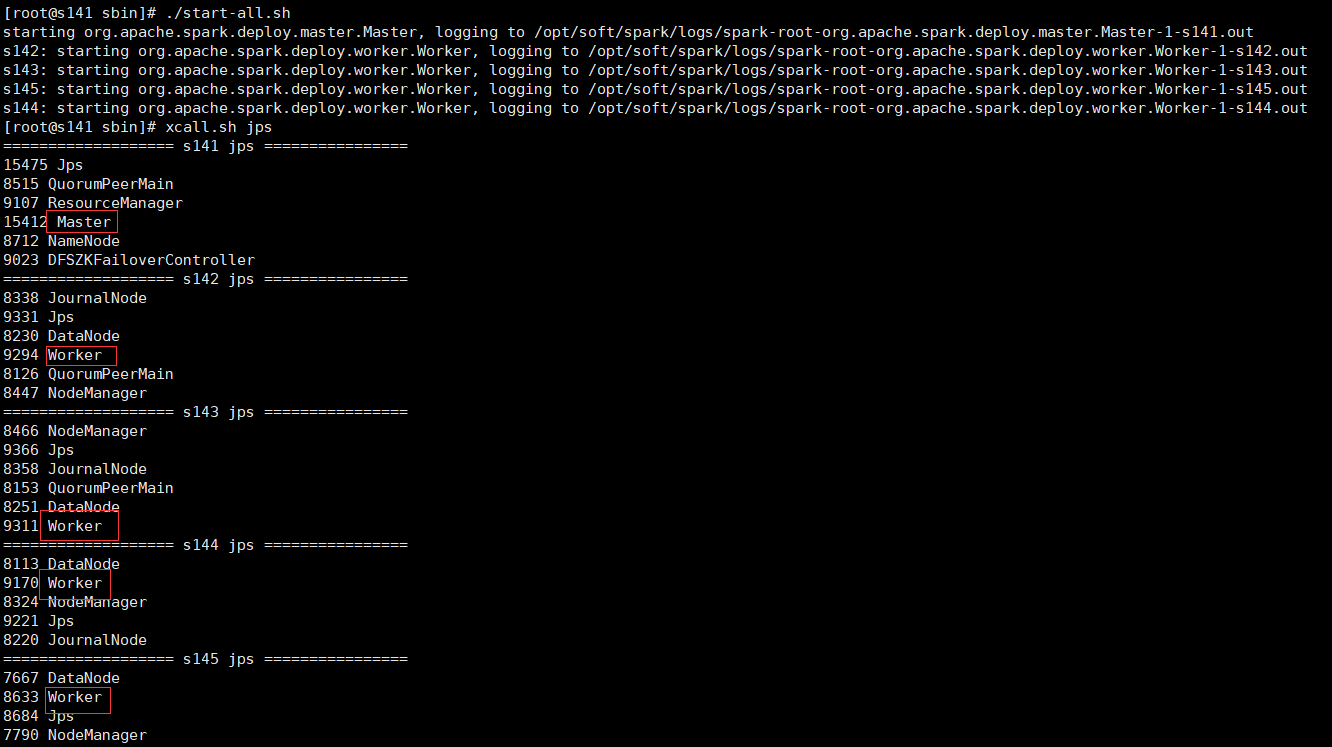
查看master和worker进程正常
5>查看集群资源页面(webUI:http://192.168.30.141:8080/),如果8080端口查不到可以看一下master启动日志,可能是8081端口
6>进入集群shell验证
- cd /opt/soft/spark/bin
./spark-shell –master yarn

启动也正常
Spark3.0.1各种集群模式搭建的更多相关文章
- Redis 5.0.7 讲解,单机、集群模式搭建
Redis 5.0.7 讲解,单机.集群模式搭建 一.Redis 介绍 不管你是从事 Python.Java.Go.PHP.Ruby等等... Redis都应该是一个比较熟悉的中间件.而大部分经常写业 ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- 微服务管理平台nacos虚拟ip负载均衡集群模式搭建
一.Nacos简介 Nacos是用于微服务管理的平台,其核心功能是服务注册与发现.服务配置管理. Nacos作为服务注册发现组件,可以替换Spring Cloud应用中传统的服务注册于发现组件,如:E ...
- Zookeeper简介及单机、集群模式搭建
1.zookeeper简介 一个开源的分布式的,为分布式应用提供协调服务的apache项目. 提供一个简单的原语集合,以便于分布式应用可以在它之上构建更高层次的同步服务. 设计非常易于编程,它使用的是 ...
- ES搜索引擎集群模式搭建【Kibana可视化】
一.简介 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎(与Solr类似),基于RESTful web接口.Elasticsearch是用Ja ...
- Hbase集群模式搭建
1.官网下载hbase安装包 这里不做赘述. 2.解压---直接tar -zxvf xxxx 3.配置hbase集群,要修改3个文件(首先zk集群已经安装好了) 注意:要把hadoop的hdfs-si ...
- 3、zookeeper 集群模式搭建
服务器 1:192.168.1.81 端口:2181.2881.3881 服务器 2:192.168.1.82 端口:2182.2882.3882 服务器 3:192.168.1.83 端口:2 ...
- nacos集群模式搭建踩坑记录
首先数据库使用的本地的mysql 1.看日志提示no set datasource,使用虚拟机ping本地后发现无法ping通,原因是本地没有关闭防火墙. 2.看日志提示不允许建立数据库连接,原因是r ...
- redis安装、测试&集群的搭建&踩过的坑
1 redis的安装 1.1 安装redis 版本说明 本教程使用redis3.0版本.3.0版本主要增加了redis集群功能. 安装的前提条件: 需要安装gcc:yum install gcc- ...
随机推荐
- centos 下安装redis 通过shell脚本
#! /bin/bash echo -e "开始安装redis服务\n" download_url=http://download.redis.io/releases/redi ...
- 关于设置Vscode缩进,保存代码任然缩进无效解决方式
在Vscode按F1,运行命令,输入Formatter config 把内容更改为以下代码 { "onSave": true, "javascript": { ...
- ORA-12609报错分析
问题:监控不断告警ORA-12609 Wed 10/14/2020 10:40 AM 12CRAC1-ALERT中出现ORA错误,请检查 171- nt OS err code: 0 172- Cli ...
- 关于c++ string类的一些使用
主要最近要用的上 才整理一下 用string类别忘了导入头文件 #include <string> 注意这个细节:cout 可直接输出 string 类的对象的内容 但是printf不可以 ...
- VS 2019 远程调试
一.简介 今天遇到一个问题,本地调试无任何问题,但是发布后代码服务器端响应总是不对.所以想调试下.故搞个远程调试.现在先配置下工具.步骤如下. 二.步骤 2.1.远程访问工具下载 地址:https:/ ...
- react-native-image-picker用法
1, 首先,安装下该插件. npm install react-native-image-picker@latest --save 2,自动安装(做了这一步 下面安装的平台设置大部分都自动添加好了) ...
- Mybatis---00Mybatis入门
一.什么是Mybatis Mybatis框架是一个半ORM框架.Mybatis是一个优秀的基于 java 的持久层框架,它内部封装了 jdbc,使开发者只需要关注 sql 语句本身,而不需要花费精力去 ...
- 【转】Optimized Surface Loading and Soft Stretching
FROM:http://lazyfoo.net/tutorials/SDL/05_optimized_surface_loading_and_soft_stretching/index.php Opt ...
- APIO2008免费道路
题目大意 给定一张n个点m条边的图,图上有两种边,求保证有k条第一种边的情况下的最小生成树 传送门 题解 考虑最小生成树kruskal算法 先找到不含限制的最小生成树,然后就可以知道哪些第一种边是必选 ...
- Gym102012A Rikka with Minimum Spanning Trees
题意 \(T\) 组数据,每组数据给定一个 \(n\) 个点,\(m\) 条边,可能含有重边自环的图,求出最小生成树的个数与边权和的乘积,对 \(10^9+7\) 取模. \(\texttt{Data ...