ELK入门及基本使用
预备知识-Restful
起源
在没有前后端分离概念之前,一个网站的完成总是“all in one”,在这个阶段,页面、数据、渲染全部在服务端完成,这样做的最大的弊端是后期维护,扩展极其痛苦,开发人员必须同时具备前后端知识。于是后来慢慢的兴起了前后端分离的思想:即后端负责数据编造,而前端则负责数据渲染,前端静态页面调用指定 api 获取到有固定格式的数据,再将数据展示出来,这样呈现给用户的就是一个”动态“的过程。
而关于 api 这部分的设计则成了一个问题。如何设计出一个便于理解,容易使用的 api 则成了一个问题,而所谓的 RESTful 就是用来规范我们的 API 的一种约束。
REST
作为 REST,其实是 Representational State Transfer(表象层状态转变)三个单词的缩写,它由 Roy Fielding(Fielding 是 HTTP 协议(1.0 版和 1.1 版)的主要设计者、Apache 服务器软件的作者之一、Apache 基金会的第一任主席)于2000 年论文中提出,他在论文中提到:"我这篇文章的写作目的,就是想在符合架构原理的前提下,理解和评估以网络为基础的应用软件的架构设计,得到一个功能强、性能好、适宜通信的架构。REST 指的是一组架构约束条件和原则。"如果一个架构符合 REST 的约束条件和原则,我们就称它为 RESTful 架构。
要理解 RESTful 架构,最好的方法就是去理解 Representational StateTransfer 这个词组到底是什么意思,它的每一个词代表了什么涵义。如果你把这个名称搞懂了,也就不难体会 REST 是一种什么样的设计。
资源(Resources)
REST 的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"。
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。
要让一个资源可以被识别,需要有个唯一标识,在 Web 中这个唯一标识就是URI(Uniform Resource Identifier)。
URI 既可以看成是资源的地址,也可以看成是资源的名称。如果某些信息没有使用 URI 来表示,那它就不能算是一个资源,只能算是资源的一些信息而已。
你可以用一个 URI(统一资源定位符)指向它,每种资源对应一个特定的 URI。
要获取这个资源,访问它的 URI 就可以,因此 URI 就成了每一个资源的地址或独一无二的识别符。
所谓"上网",就是与互联网上一系列的"资源"互动,调用它的 URI。
URI 设计技巧
1、使用 _ 或 - 来让 URI 可读性更好
曾经 Web 上的 URI 都是冰冷的数字或者无意义的字符串,但现在越来越多的网站使用_或-来分隔一些单词,让 URI 看上去更为人性化。例如国内比较出名的开源中国社区,它上面的新闻地址就采用这种风格,如
http://www.oschina.net/news/38119/oschina-translate-reward-plan。
2、使用 / 来表示资源的层级关系
例如上述/git/git/commit/e3af72cdafab5993d18fae056f87e1d675913d08就表示了一个多级的资源,指的是 git 用户的 git 项目的某次提交记录,又例如/orders/2012/10 可以用来表示 2012 年 10 月的订单记录。
3、使用 ? 用来过滤资源
很多人只是把?简单的当做是参数的传递,很容易造成 URI 过于复杂、难以理解。可以把?用于对资源的过滤,例如/git/git/pulls 用来表示 git 项目的所有推入请求,而/pulls?state=closed 用来表示 git 项目中已经关闭的推入请求,这种 URL 通常对应的是一些特定条件的查询结果或算法运算结果。
, 或; 可以用来表示同级资源的关系
有时候我们需要表示同级资源的关系时,可以使用,或;来进行分割。例如哪天github 可以比较某个文件在随意两次提交记录之间的差异,或许可以使用/git/git
/block-sha1/sha1.h/compare/e3af72cdafab5993d18fae056f87e1d675913d08;bd63e61bdf38e872d5215c07b264dcc16e4febca 作为 URI。不过,现在 github 是使用…来做这个事情的,例如/git/git/compare/master…next。
4、URI 不应该包含动词
因为"资源"表示一种实体,所以应该是名词,URI 不应该有动词,动词应该放在 HTTP 协议中。
举例来说,某个 URI 是/posts/show/1,其中 show 是动词,这个 URI 就设计错了,正确的写法应该是/posts/1,然后用 GET 方法表示 show。
如果某些动作是 HTTP 动词表示不了的,你就应该把动作做成一种资源。比如网上汇款,从账户 1向账户 2汇款 500 元,错误的 URI 是:
POST /accounts/1/transfer/500/to/2
正确的写法是把动词 transfer 改成名词 transaction,资源不能是动词,但是可以是一种服务。
5、URI 中不宜加入版本号
例如:
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个 URI。版本号可以在 HTTP 请求头信息的 Accept 字段中进行区分。
表现层(Representation)
"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
比如,文本可以用 txt 格式表现,也可以用 HTML 格式、XML 格式、JSON 格式表现,甚至可以采用二进制格式;图片可以用 JPG 格式表现,也可以用 PNG格式表现。
URI 只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI 应该只代表"资源"的位置。它的具体表现形式,应该在 HTTP 请求的头信息中用 Accept 和 Content-Type 字段指定,这两个字段才是对"表现层"的描述。
状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议 HTTP 协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
客户端用到的手段,目前来说只能是 HTTP 协议。具体来说,就是 HTTP 协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET 用来获取资源,POST 用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE 用来删除资源。GET、PUT 和 DELETE 请求都是幂等的,无论对资源操作多少次,结果总是一样的, POST 不是幂等的。
什么是 RESTful 架构
综合上面的解释,我们总结一下什么是 RESTful 架构:
1.架构里,每一个 URI 代表一种资源;
2.客户端和服务器之间,传递这种资源的某种表现层;
3.客户端通过四个 HTTP 动词(get、post、put、delete),对服务器端资源进行操作,实现”表现层状态转化”。
注意:REST 架构风格并不是绑定在 HTTP 上,只不过目前 HTTP 是唯一与 REST相关的实例。所以我们这里描述的 REST 也是通过 HTTP 实现的 REST。
辨析 URI、URL、URN
RFC 3986 中是这样说的:
A Uniform Resource Identifier (URI) 是一个紧凑的字符串用来标示抽象或物理资源。一个 URI 可以进一步被分为定位符、名字或两者都是. 术语“Uniform Resource Locator”(URL) 是 URI 的子集, 除了确定一个资源,还提供一种定位该资源的主要访问机制。
所以,URI = Universal Resource Identifier 统一资源标志符,包含 URL和URN,支持的协议有 http、https、ftp、mailto、magnet、telnet、data、file、nfs、gopher、ldap 等,java 还大量使用了一些非标准的定制模式,如 rmi,jar、jndi 和 doc,来实现各种不同用途。
URL = Universal Resource Locator 统一资源定位符,URL 唯一地标识一个资源在 Internet 上的位置。不管用什么方法表示,只要能定位一个资源,就叫URL。
URN = Universal Resource Name 统一资源名称,URN 它命名资源但不指定如何定位资源,比如:只告诉你一个人的姓名,不告诉你这个人在哪。
对于一个资源来说,URN 就好比他的名字,而 URL 就好比是资源的街道住址。
换句话说,URN 标识了一个资源项目,而 URL 则提供了一种找到他的方法。
比如同时指定基本的获取机制和网络位置。举个例子,
http://example.org/wiki/Main_Page,指向了一个被识别为/wike/Main_Page的资源,这个资源的表现形式是 HTML 和相关的代码。而获取这个资源的方法是在网络中从一个名为 example.org 的主机上,通过 HTTP( Hypertext TransferProtocol)获得。
而 URN 则是一种在特定的名称空间中通过通过名字来标识资源的 URI。当讨论一种资源而不需要知道它的位置或者如何去获得它的时候,就可以使用 URN。
例如,在 International Standard Book Number (ISBN)系统中,* ISBN
0-486-27557-4 用来指定莎士比亚的作品《罗密欧与朱丽叶》的一个特定版本。
指示这一版本的 URN 是 urn:isbn:0-486-27557-4*,但是如果想要获得这个版本的书,就需要知道它的位置,这样就必须知道它的 URL。
什么是 ELK
为什么需要 ELK
官网的说法:Elasticsearch 是一个开源的分布式 RESTful 搜索和分析引擎,能够解决越来越多不同的应用场景。
看一个应用场景,常见的 WEB 应用日志分析。一般我们会怎么做?
登录到每台服务器上,直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。
这个时候我们希望集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
这样对于大型系统来说,都是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
收集-能够采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
存储-如何存储日志数据分析-可以支持
UI 分析警告-能够提供错误报告,监控机制
ELK就是这样一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,而不仅仅是日志分析。
什么是 ELK
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往 elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和
ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
新增了一个 Beats 系列组件,它是一个轻量级的日志收集处理工具(Agent),Beats 占用资源少,适合于在各个服务器上搜集日志或信息后传输给 Logstash。
加入 Beats 系列组件后,官方名称就变为了 Elastic Stack,产品如下:

安装,启动和 HelloWorld
环境和安装
运行环境为 Linux,演示服务器操作系统版本情况如下:
因为 Elastic Stack中主要组件都是用 Java 写的,所以操作系统上还应该安装好 Java,本次以 Elasticsearch 7 版本为主,所以,需要安装 JDK1.8 以上。

而 Elastic Stack系列产品我们可以到 Elastic的官网上去下载:
https://www.elastic.co/cn/downloads
选择 7.7.0版本为本次版本,从具体的下载页面可以看到 Elastic Stack支持各种形式的安装。
选择以免安装的压缩包的形式。下载后上传到服务器解压缩即可运行。

运行
Elasticsearch 默认不允许用 root用户运行,会报错,而且从服务器安全的角度来说,也不应该以 root用户来做日常工作,因此我们新建一个用户 elk并以elk用户登录。
Elasticsearch
用 tar -xvf命令解压压缩包elasticsearch-7.7.0-linux-x86_64.tar.gzip后进入elasticsearch-7.7.0文件夹中的 bin文件夹,并执行命令./elasticsearch。
待启动完成.....

输入 curl http://localhost:9200
显示:
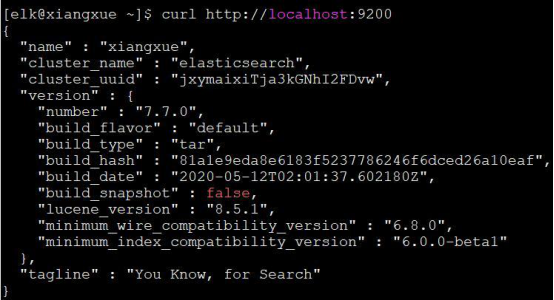
表示Elasticsearch运行成功了,我们试着在本地浏览器进行访问
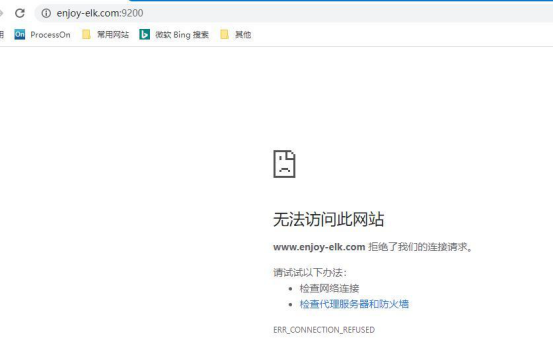
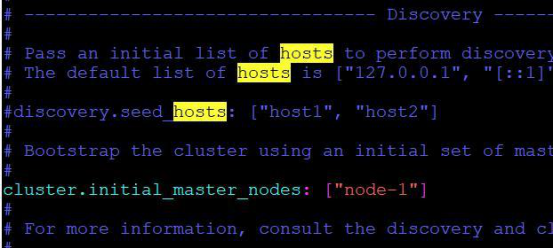
却显示“拒绝了我们的连接请求”,因此我们还需要配置一下 Elasticsearch以允许我们进行外网访问,进入 elasticsearch-7.7.0下的 config目录,编辑elasticsearch.yml文件,删除 network.host前的#字符,并写入服务器的地址并保存。
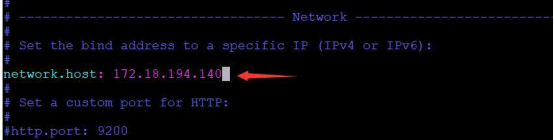
再次运行,但是这次却出了错

从错误提示我们可以知道,还需对 Elasticsearch配置做适当修改,重新编辑elasticsearch.yml文件,并做如下修改:
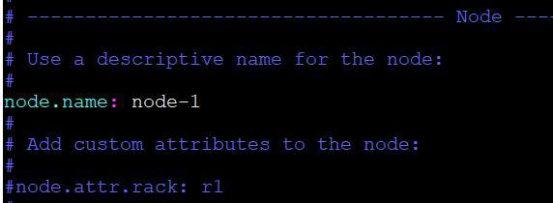
再次启动,并在浏览器中访问
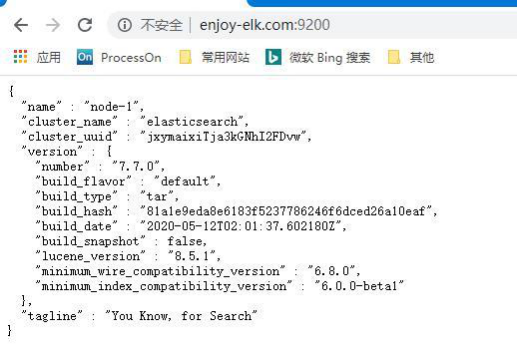
显示 Elasticsearch运行并访问成功!
我们知道,Elasticsearch提供的是 restful风格接口,我们用浏览器访问不是很方便,除非我们自行编程访问 restful接口。这个时候,就可以用上 Kibana 了,它已经为我们提供了友好的 Web 界面,方便我们后面对 Elasticsearch的学习。
接下来我们安装运行 Kibana。
Kibana
同样用 tar -xvf命令解压压缩包,进入解压后的目录。为了方便我们的访问和连接 Elasticsearch,也需要进入 Kibana的 config 目录对 Kibana 进行配置。
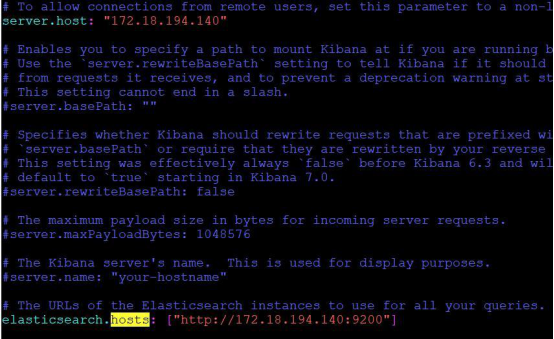
然后进入 Kibana的 bin 目录运行./kibana,kibana因为是用 node.js 编写的,所以启动和运行较慢,需要等待一段时间:

从提示我们可以看出,kibana的访问端口是 5601,我们依然在本地浏览器中访问:
等候几分钟以后,就会进入 kibana的主界面
TIPS:如何检测系统中是否启动了 kibana?
我们一般会用ps -ef来查询某个应用是否在 Linux系统中启动,比如Elasticsearch,
我们用 ps -ef|grep java 或者 ps -ef|grep elasticsearch均可
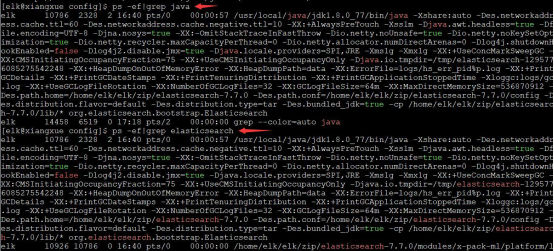
但是当我们尝试 ps -ef|grep kibana,却是不行的

因为 kibana 是 node 写的,所以 kibana 运行的时候是运行在 node 里面,我们要查询的话,只能 ps -ef|grep node
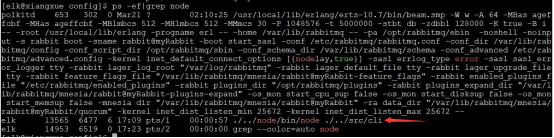
或者使用 netstat -tunlp|grep 5601

因为我们的kibana开放的端口是5601,所以看到5601端口被 Listen (监听),说明 kibana启动成功。
附:netstat参数说明:
-t (tcp)仅显示 tcp相关选项
-u (udp)仅显示 udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服務状态
-p 显示建立相关链接的程序名
更多 netstat的相关说明,自行查阅 Linux手册
HelloWorld
点击面板中的“Dev Tools”按钮,进入 Dev 工具,开始我们的 Elasticsearch初次访问之旅。
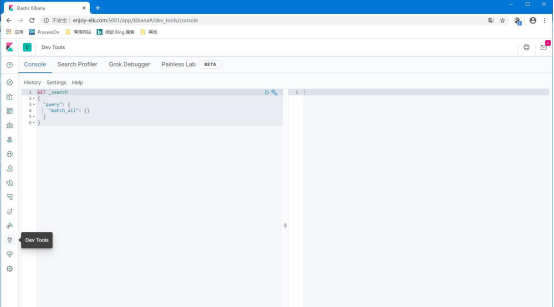
创建索引
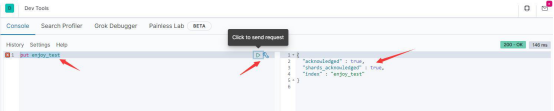
在左边命令窗口中输入 put enjoy_test,并点击相关按钮 ,于是看到右
边的结果窗口中 es给我们返回了处理结果,表示我们在 es中创建索引成功。
查看索引
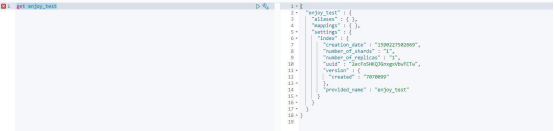
要查看我们刚刚创建的索引,执行“get enjoy_test”
添加文档
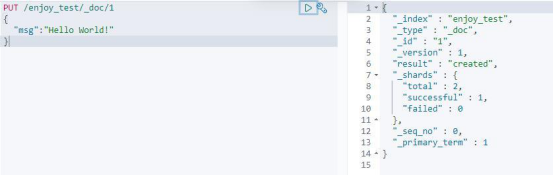
往这个索引中添加文档,执行:
PUT /enjoy_test/_doc/1
{
"msg":"Hello World!"
}
查看文档
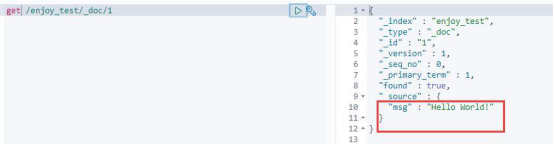
查询我们刚刚加入的文档,执行“get /enjoy_test/_doc/1”
Elasticsearch 基本原理和概念
从上面的例子中,我们看到了很多熟悉又陌生的概念,比如索引、文档等等。这些概念和我们平时看到的数据库里的比如索引有什么区别呢?
举个例子,现在我们要保存唐宋诗词,数据库中我们们会怎么设计?诗词表我们可能的设计如下:
|
朝代 |
作者 |
诗词年代 |
标题 |
诗词全文 |
|
唐 |
李白 |
静夜思 |
床前明月光,疑是地上霜。举头望明月,低头思故乡。 |
|
|
宋 |
李清照 |
如梦令 |
常记溪亭日暮,沉醉不知归路,兴尽晚回舟,误入藕花深处。争渡,争渡,惊起一滩鸥鹭。 |
|
|
…. |
…. |
… |
…. |
……. |
要根据朝代或者作者寻找诗,都很简单,比如“select 诗词全文 from 诗词表where作者=‘李白’”,如果数据很多,查询速度很慢,怎么办?我们可以在对应的查询字段上建立索引加速查询。
但是如果我们现在有个需求:要求找到包含“望”字的诗词怎么办?用
“select 诗词全文 from 诗词表 where 诗词全文 like‘%望%’”,这个意味着
要扫描库中的诗词全文字段,逐条比对,找出所有包含关键词“望”字的记录,。
基本上,数据库中一般的 SQL 优化手段都是用不上的。数量少,大概性能还能接受,如果数据量稍微大点,就完全无法接受了,更何况在互联网这种海量数据的情况下呢?
怎么解决这个问题呢,用倒排索引。
倒排索引 Inverted index
比如现在有:
蜀道难(唐)李白 蜀道之难难于上青天,侧身西望长咨嗟。
静夜思(唐)李白 举头望明月,低头思故乡。
春台望(唐)李隆基 暇景属三春,高台聊四望。
鹤冲天(宋)柳永 黄金榜上,偶失龙头望。明代暂遗贤,如何向?未遂风云便,争不恣狂荡。何须论得丧?才子词人,自是白衣卿相。烟花巷陌,依约丹青屏障。
幸有意中人,堪寻访。且恁偎红翠,风流事,平生畅。青春都一饷。忍把浮名,换了浅斟低唱!
都有望字,于是我们可以这么保存
|
序号 |
关键字 |
蜀道难 |
静夜思 |
春台望 |
鹤冲天 |
|
1 |
望 |
有 |
有 |
有 |
有 |
如果查哪个诗词中包含上,怎么办,上述的表格可以继续填入新的记录
|
序号 |
关键字 |
蜀道难 |
静夜思 |
春台望 |
鹤冲天 |
|
1 |
望 |
有 |
有 |
有 |
有 |
|
2 |
上 |
有 |
有 |
其实,上述诗词的中每个字都可以作为关键字,然后建立关键字和文档之间的对应关系,也就是标识关键字被哪些文档包含。
所以,倒排索引就是,将文档中包含的关键字全部提取处理,然后再将关键字和文档之间的对应关系保存起来,最后再对关键字本身做索引排序。用户在检索某一个关键字是,先对关键字的索引进行查找,再通过关键字与文档的对应关系找到所在文档。
在存储在关系型数据库中的数据,需要我们事先分析将数据拆分为不同的字段,而在 es 这类的存储中,需要应用程序根据规则自动提取关键字,并形成对应关系。
这些预先提取的关键字,在全文检索领域一般被称为 term(词项),文档的词项提取在 es 中被称为文档分析,这是全文检索很核心的过程,必须要区分哪些是词项,哪些不是,比如很多场景下,apple和 apples 是同一个东西,望和看其实是同一个动作。
Elasticsearch 基本概念
Elasticsearch 中比较关键的基本概念有索引、文档、映射、映射类型、文档字段概念,为了方便理解,可以和关系数据库中的相关概念进行个比对:
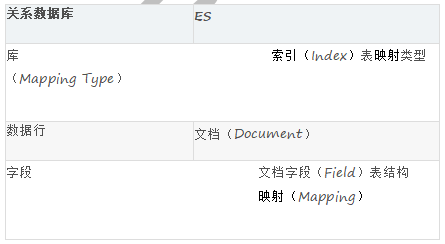
Elasticsearch 索引
Elasticsearch 索引是映射类型的容器。一个 Elasticsearch 索引非常像关系型世界的数据库,是独立的大量文档集合。
当然在底层,肯定用到了倒排索引,最基本的结构就是“keyword”和“PostingList”,Posting list就是一个 int的数组,存储了所有符合某个 term的文档 id。
另外,这个倒排索引相比特定词项出现过的文档列表,会包含更多其它信息。
它会保存每一个词项出现过的文档总数,在对应的文档中一个具体词项出现的总次数,词项在文档中的顺序,每个文档的长度,所有文档的平均长度等等相关信息。
文档 (Document)
文档是 es 中所有可搜索数据的最小单位,比如日志文件中的日志项、一部电影的具体信息等等。
文档会被序列化 JSON格式保存到 ElasticSearch 中,JSON 对象由字段组成,每个字段都有对象的字段类型(字符串,数值,布尔,日期,二进制,范围类型)。
同时每个文档都有一个 Unique ID,可以自己指定 ID,或者通过 ElasticSearch 自动生成。
所以严格来说,es 中存储的文档是一种半结构化的数据。
映射
映射(mapping)定义了每个字段的类型、字段所使用的分词器等。
get /enjoy_test/_mapping
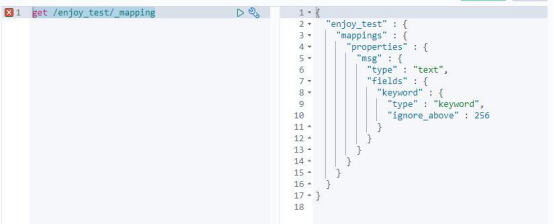
可以显式映射,由我们在索引映射中进行预先定义;也可以动态映射,在添加文档的时候,由 es 自动添加到索引,这个过程不需要事先在索引进行字段数据类型匹配等等,es 会自己推断数据类型。
既然说到了字段类型,当然就离不开字段的数据类型了。
文档字段
文档中的一个字段 field就相当于关系型数据库中的一列 column,那么它肯定有数据类型,es 提供的数据类型包括至少有:
数据类型
核心数据类型
# 字符串类型:string,字符串类还可被分为 text和 keyword 类型,如果我们让 es自动映射数据,那么 es 会把字符串定义为 text,并且还加了一个 keyword类型字段。
text文本数据类型,用于索引全文值的字段。使用文本数据类型的字段,它们会被分词,在索引之前将字符串转换为单个术语的列表(倒排索引),分词过程允许 ES 搜索每个全文字段中的单个单词。什么情况适合使用 text,只要不具备唯一性的字符串一般都可以使用 text。
keyword,关键字数据类型,用于索引结构化内容的字段。使用 keyword 类型的字段,其不会被分析,给什么值就原封不动地按照这个值索引,所以关键字字段只能按其确切值进行搜索。什么情况下使用 keyword,具有唯一性的字符串,例如:电子邮件地址、MAC 地址、身份证号、状态代码...等等。
# 数字型数据类型:long、integer、short、byte、double、float
# 日期类型:date
# 布尔类型:boolean
复杂数据类型
# 数组:无需专门的数据类型
# 对象数据类型:单独的 JSON对象
# 嵌套数据类型:nested,关于 JSON对象的数组
地理数据类型:
# 地理点数据类型
# 地理形状数据类型
专门数据类型:
# IPv4 数据类型
# 单词计数数据类型 token_count
我们结合前面的映射来看看:
创建一个新的索引:put /open-soft
显式映射:
put /open-soft/_mapping
{
"properties" : {
"corp" : {
"type" : "text"
},
"lang" : {
"type" : "text"
},
"name" : {
"type" : "text"
}
索引或者说入库一个文档,注意这个文档的字段,比我们显示映射的字段要多个 star字段:
put /open-soft/_doc/1
{
"name": "Apache Hadoop",
"lang": "Java",
"corp": "Apache",
"stars":200
}
通过 get /open-soft/_mapping,我们可以看到 es 自动帮我们新增了 stars这个字段。
修改映射,增加一个新的字段:
put /open-soft/_mapping
{
"properties" : {
"year" : {
"type" : "integer"
}
}
}
数组
不需要特殊配置,一个字段如果被配置为基本数据类型,就是天生支持数组类型的。任何字段都可以有 0个或多个值,但是在一个数组中数据类型必须一样。
比如:
put /open-soft/_doc/2
{
"name": ["Apache Activemq","Activemq Artemis"],
"lang": "Java",
"corp": "Apache",
"stars":[500,200]
}
是没问题的,但是如果:
put /open-soft/_doc/3
{
"name": ["Apache Kafka"],
"lang": "Java",
"corp": "Apache",
"stars":[500,"kafka"]
}
则会出错。
对象
JSON文档是有层次结构的,一个文档可能包含其他文档,如果一个文档包含其他文档,那么该文档值是对象类型,其数据类型是对象。当然 ElasticSearch中是没有所谓对象类型的,比如:
put /open-soft/_doc/object
{
"name": ["Apache ShardingSphere"],
"lang": "Java",
"corp": "JingDong",
"stars":400,
"address":{
"city":"BeiJing",
"country":"亦庄"
}
}
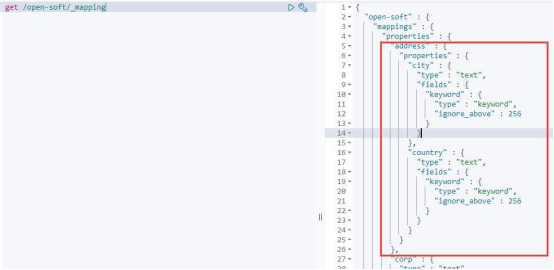
对象类型可以在定义索引的映射关系时进行指定。
多数据类型
如果说数组允许你使用同一个设置索引多项数据,那么多数据类型允许使用不同的设置,对同一项数据索引多次。带来的好处就是可以同一文本有多种不同的索引方式,比如一个字符串类型的字段,可以使用 text类型做全文检索,使用keyword 类型做聚合和排序。我们可以看到 es 的动态映射生成的字段类型里,往往字符串类型都使用了多数据类型。当然,我们一样也可以自己定义:
put /open-soft/_mapping
{
"properties" : {
"name" : {
"type" : "text",
"fields":{
"raw":{
"type" : "keyword"
},
"length":{
"type" : "token_count",
"analyzer":"standard"
}
}
}
}
}
在上面的代码里,我们使用"fields"就把 name字段扩充为多字段类型,为name新增了两个子字段 raw和 length,raw设置类型为 keyword,length 设置类型为 token_count,告诉 es 这个字段在保存还需要做词频统计。
通过 fields字段设置的子字段 raw 和 length,在我们添加文档时,并不需要单独设置值,他们 name共享相同的值,只是 es 会以不同的方式处理字段值。
同样在检索文档的时候,它们也不会显示在结果中,所以它们一般都是在检索中以查询条件的形式出现,以减少检索时的性能开销。
字段参数
在上面的代码里出现了analyzer这个词,这是什么?这个叫字段参数,和 type一样,可以用来对字段进行配置。常用的字段参数和作用如下:
analyzer
指定分词器。elasticsearch是一款支持全文检索的分布式存储系统,对于 text类型的字段,首先会使用分词器进行分词,然后将分词后的词根一个一个存储在倒排索引中,后续查询主要是针对词根的搜索。
analyzer该参数可以在每个查询、每个字段、每个索引中使用,其优先级如下(越靠前越优先):
1、字段上定义的分词器
2、索引配置中定义的分词器
3、默认分词器(standard)
normalizer
规范化,主要针对 keyword 类型,在索引该字段或查询字段之前,可以先对原始数据进行一些简单的处理,然后再将处理后的结果当成一个词根存入倒排索引中,默认为 null,比如:
PUT index
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": { // 1
"type": "custom",
"char_filter": [],
"filter": ["lowercase", "asciifolding"] // 2
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"foo": {
"type": "keyword",
"normalizer": "my_normalizer" // 3
}
}
}
}
}
代码 1:首先在 settings中的 analysis 属性中定义 normalizer。
代码 2:设置标准化过滤器,示例中的处理器为小写、asciifolding。
代码 3:在定义映射时,如果字段类型为 keyword,可以使用 normalizer
引用定义好的 normalizer
boost
权重值,可以提升在查询时的权重,对查询相关性有直接的影响,其默认值为1.0。其影响范围为词根查询(team query),对前缀、范围查询。5.0 版本后已废止。
coerce
数据不总是我们想要的,由于在转换 JSON body 为真正 JSON 的时候,整型数字5有可能会被写成字符串"5"或者浮点数 5.0,这个参数可以将数值不合法的部分去除。默认为 true。
例如:将字符串会被强制转换为整数、浮点数被强制转换为整数。
例如存在如下字段类型:
"number_one": {
"type": "integer"
}
声明 number_one字段的类型为数字类型,那是否允许接收“6”字符串形式的数据呢?因为在 JSON中,“6”用来赋给 int类型的字段,也是能接受的,默认 coerce 为 true,表示允许这种赋值,但如果 coerce 设置为 false,此时 es只能接受不带双引号的数字,如果在 coerce=false 时,将“6”赋值给 number_one时会抛出类型不匹配异常。
copy_to
copy_to参数允许您创建自定义的_all字段。换句话说,多个字段的值可以复制到一个字段中。
例如,first_name和 last_name 字段可以复制到 full_name 字段如下:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": "full_name"
表示字段 full_name的值来自 first_name + last_name。
关于 copy_to重点说明:
1、字段的复制是原始值。
2、同一个字段可以复制到多个字段,写法如下:“copy_to”: [ “field_1”,
“field_2”]
doc_values
Doc values 的存在是因为倒排索引只对某些操作是高效的。倒排索引的优势在于查找包含某个项的文档,而对于从另外一个方向的相反操作并不高效,即:确定哪些项是否存在单个文档里,聚合需要这种次级的访问模式。
对于以下倒排索引:
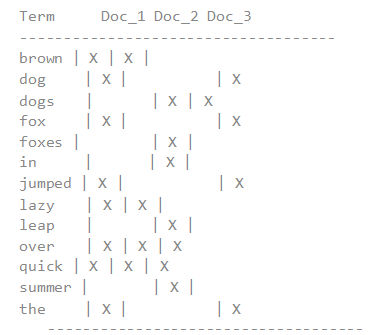
如果我们想要获得所有包含 档的词的完整列表,倒排索引是根据项来排序的,所以我们首先在词 ,然后扫描所有列,找到包含 brown 的文档。我们可以快速 和 包含 brown 这个 token。
然后,对于聚合部分,我们需要找到 Doc_1 和 Doc_2 里所有唯一的词项。用倒排索引做这件事情代价很高:我们会迭代索引里的每个词项并收集 Doc_1 和 Doc_2 列里面 token。这很慢而且难以扩展:随着词项和文档的数量增加,执行时间也会增加。
Doc values 通过转置两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,doc values 将文档映射到它们包含的词项:

当数据被转置之后,想要收集到 Doc_1 和 Doc_2 的唯一 token 会非常容易。获得每个文档行,获取所有的词项,然后求两个集合的并集。
doc_values缺省是 true,即是开启的,并且只适用于非 text类型的字段。
dynamic
是否允许动态的隐式增加字段。在执行 index api 或更新文档 API 时,对于_source字段中包含一些原先未定义的字段采取的措施,根据 dynamic 的取值,会进行不同的操作:
true,默认值,表示新的字段会加入到类型映射中。
false,新的字段会被忽略,即不会存入_souce字段中,即不会存储新字段,也无法通过新字段进行查询。
strict,会显示抛出异常,需要新使用 put mapping api 先显示增加字段映射。
enabled
是否建立索引,默认情况下为 true,es 会尝试为你索引所有的字段,但有时候某些类型的字段,无需建立索引,只是用来存储数据即可。也就是说,
ELasticseaech默认会索引所有的字段,enabled设为 false的字段,elasicsearch 会跳过字段内容,该字段只能从_source 中获取,但是不可搜。只有映射类型(type)和object 类型的字段可以设置 enabled属性。
eager_global_ordinals
表示是否提前加载全局顺序号。Global ordinals 是一个建立在 doc values 和fielddata基础上的数据结构, 它为每一个精确词按照字母顺序维护递增的编号。每一个精确词都有一个独一无二的编号 并且 精确词 A 小于精确词 B 的编号.Global ordinals 只支持 keyword 和 text 型字段,在 keyword 字段中, 默认是启用的 而在 text 型字段中 只有 fielddata 和相关属性开启的状态下才是可用的。
fielddata
为了解决排序与聚合,elasticsearch 提供了 doc_values 属性来支持列式存储,但doc_values 不支持 text 字段类型。因为 text 字段是需要先分析(分词),会影响 doc_values 列式存储的性能。
es 为了支持 text字段高效排序与聚合,引入了一种新的数据结构(fielddata),使用内存进行存储。默认构建时机为第一次聚合查询、排序操作时构建,主要存储倒排索引中的词根与文档的映射关系,聚合,排序操作在内存中执行。因此fielddata需要消耗大量的 JVM 堆内存。一旦 fielddata加载到内存后,它将永久存在。
通常情况下,加载 fielddata 是一个昂贵的操作,故默认情况下,text 字段的字段默认是不开启 fielddata机制。在使用 fielddata 之前请慎重考虑为什么要开启fielddata。
format
在 JSON文档中,日期表示为字符串。Elasticsearch 使用一组预先配置的格式来识别和解析这些字符串,并将其解析为 long类型的数值(毫秒),支持自定义格式,也有内置格式。
比如:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}}}}}
elasticsearch为我们内置了大量的格式,如下:
epoch_millis
时间戳,单位,毫秒,范围受限于 Java Long.MIN_VALUE和 Long.MAX_VALUE。
epoch_second
时间戳,单位,秒,范围受限于 Java的限制 Long.MIN_VALUE 并 Long.
MAX_VALUE 除以 1000(一秒中的毫秒数)。
date_optional_time或者 strict_date_optional_time
日期必填,时间可选,其支持的格式如下:
date-opt-time = date-element ['T' [time-element] [offset]]
date-element = std-date-element | ord-date-element | week-date-element
std-date-element = yyyy ['-' MM ['-' dd]]
ord-date-element = yyyy ['-' DDD]
week-date-element = xxxx '-W' ww ['-' e]
time-element = HH [minute-element] | [fraction]
minute-element = ':' mm [second-element] | [fraction]
second-element = ':' ss [fraction]
比如"yyyy-MM-dd"、"yyyyMMdd"、"yyyyMMddHHmmss"、
"yyyy-MM-ddTHH:mm:ss"、"yyyy-MM-ddTHH:mm:ss.SSS"、
"yyyy-MM-ddTHH:mm:ss.SSSZ"格式,不支持常用的"yyyy-MM-dd HH:mm:ss"等格式。
注意,"T"和"Z"是固定的字符。
tips:如果看到“strict_”前缀的日期格式要求,表示 date_optional_time 的严格级别,这个严格指的是年份、月份、天必须分别以 4位、2 位、2 位表示,不足两位的话第一位需用 0补齐。
basic_date
其格式表达式为 :yyyyMMdd
basic_date_time
其格式表达式为:yyyyMMdd’T’HHmmss.SSSZ
basic_date_time_no_millis
其格式表达式为:yyyyMMdd’T’HHmmssZ
basic_ordinal_date
4位数的年 + 3 位(day of year),其格式字符串为 yyyyDDD
basic_ordinal_date_time
其格式字符串为 yyyyDDD’T’HHmmss.SSSZ
basic_ordinal_date_time_no_millis
其格式字符串为 yyyyDDD’T’HHmmssZ
basic_time
其格式字符串为 HHmmss.SSSZ
basic_time_no_millis
其格式字符串为 HHmmssZ
basic_t_time
其格式字符串为’T’HHmmss.SSSZ
basic_t_time_no_millis
其格式字符串为’T’HHmmssZ
basic_week_date
其格式字符串为 xxxx’W’wwe,4 为年 ,然后用’W’, 2 位 week of year(所在年里周序号)1位 day of week。
basic_week_date_time
其格式字符串为 xxxx’W’wwe’T’HH:mm:ss.SSSZ.
basic_week_date_time_no_millis
其格式字符串为 xxxx’W’wwe’T’HH:mm:ssZ.
date
其格式字符串为 yyyy-MM-dd
date_hour
其格式字符串为 yyyy-MM-dd’T’HH
date_hour_minute
其格式字符串为 yyyy-MM-dd’T’HH:mm
date_hour_minute_second
其格式字符串为 yyyy-MM-dd’T’HH:mm:ss
date_hour_minute_second_fraction
其格式字符串为 yyyy-MM-dd’T’HH:mm:ss.SSS
date_hour_minute_second_millis
其格式字符串为 yyyy-MM-dd’T’HH:mm:ss.SSS
date_time
其格式字符串为 yyyy-MM-dd’T’HH:mm:ss.SSS
date_time_no_millis
其格式字符串为 yyyy-MM-dd’T’HH:mm:ss
hour
其格式字符串为 HH
hour_minute
其格式字符串为 HH:mm
hour_minute_second
其格式字符串为 HH:mm:ss
hour_minute_second_fraction
其格式字符串为 HH:mm:ss.SSS
hour_minute_second_millis
其格式字符串为 HH:mm:ss.SSS
ordinal_date
其格式字符串为 yyyy-DDD,其中 DDD为 day of year。
ordinal_date_time
其格式字符串为 yyyy-DDD‘T’HH:mm:ss.SSSZZ,其中 DDD为 day of year。
ordinal_date_time_no_millis
其格式字符串为 yyyy-DDD‘T’HH:mm:ssZZ
time
其格式字符串为 HH:mm:ss.SSSZZ
time_no_millis
其格式字符串为 HH:mm:ssZZ
t_time
其格式字符串为’T’HH:mm:ss.SSSZZ
t_time_no_millis
其格式字符串为’T’HH:mm:ssZZ
week_date
其格式字符串为 xxxx-'W’ww-e,4 位年份,ww 表示 week of year,e 表示 dayof week。
week_date_time
其格式字符串为 xxxx-'W’ww-e’T’HH:mm:ss.SSSZZ
week_date_time_no_millis
其格式字符串为 xxxx-'W’ww-e’T’HH:mm:ssZZ
weekyear
其格式字符串为 xxxx
weekyear_week
其格式字符串为 xxxx-'W’ww,其中 ww 为 week of year。
weekyear_week_day
其格式字符串为 xxxx-'W’ww-e,其中 ww 为 week of year,e为 day of week。
year
其格式字符串为 yyyy
year_month
其格式字符串为 yyyy-MM
year_month_day
其格式字符串为 yyyy-MM-dd
ignore_above
ignore_above用于指定字段索引和存储的长度最大值,超过最大值的会被忽略。
ignore_malformed
ignore_malformed可以忽略不规则数据,对于 login 字段,有人可能填写的是date类型,也有人填写的是邮件格式。给一个字段索引不合适的数据类型发生异常,导致整个文档索引失败。如果 ignore_malformed参数设为 true,异常会被忽
略,出异常的字段不会被索引,其它字段正常索引。
index
index 属性指定字段是否索引,不索引也就不可搜索,取值可以为 true 或者false,缺省为 true。
index_options
index_options 控制索引时存储哪些信息到倒排索引中,,用于搜索和突出显示目的。
docs 只存储文档编号
freqs 存储文档编号和词项频率。
positions 文档编号、词项频率、词项的位置被存储
offsets 文档编号、词项频率、词项的位置、词项开始和结束的字符位置都被存储。
fields
fields可以让同一文本有多种不同的索引方式,比如一个 String 类型的字段,可以使用 text类型做全文检索,使用 keyword 类型做聚合和排序。
norms
norms参数用于标准化文档,以便查询时计算文档的相关性。norms 虽然对评分有用,但是会消耗较多的磁盘空间,如果不需要对某个字段进行评分,最好不要开启 norms。
null_value
一般来说值为 null的字段不索引也不可以搜索,null_value参数可以让值为null的字段显式的可索引、可搜索。
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"status_code": {
"type": "keyword",
"null_value": "NULL"
}
}
}
}
}
GET my_index/_search
{
"query": {
"term": {
"status_code": "NULL"
}
}
}
文档 1可以被搜索到,因为 status_code的值为 null,文档 2 不可以被搜索到,因为 status_code为空数组,但是不是 null。
position_increment_gap
文本数组元素之间位置信息添加的额外值。
举例,一个字段的值为数组类型:"names": [ "John Abraham", "Lincoln Smith"]为了区别第一个字段和第二个字段,Abraham和 Lincoln在索引中有一个间
距,默认是 100。例子如下,这是查询”Abraham Lincoln”是查不到的:
PUT my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
GET my_index/groups/_search
{
"query": {
"match_phrase": {
"names": {
"query": "Abraham Lincoln"
}}}}
指定间距大于 10 0 可以查询到:
GET my_index/groups/_search
{
"query": {
"match_phrase": {
"names": {
"query": "Abraham Lincoln",
"slop": 101
}}}}
想要调整这个值,在 mapping中通过 position_increment_gap 参数指定间距即可。
properties
Object或者 nested类型,下面还有嵌套类型,可以通过 properties 参数指定。
比如:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"manager": {
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}
},
"employees": {
"type": "nested",
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}}}}}}
对应的文档结构:
PUT my_index/my_type/1
{
"region": "US",
"manager": {
"name": "Alice White",
"age": 30
},
"employees": [
{
"name": "John Smith",
"age": 34
},
{
"name": "Peter Brown",
"age": 26
}
]
}
search_analyzer
通常,在索引时和搜索时应用相同的分析器,以确保查询中的术语与反向索引中的术语具有相同的格式,如果想要在搜索时使用与存储时不同的分词器,则使用 search_analyzer属性指定,通常用于 ES 实现即时搜索(edge_ngram)。
similarity
指定相似度算法,其可选值:
BM25
当前版本的默认值,使用 BM25算法。
classic
使用 TF/IDF算法,曾经是 es,lucene 的默认相似度算法。
boolean
一个简单的布尔相似度,当不需要全文排序时使用,并且分数应该只基于查询条件是否匹配。布尔相似度为术语提供了一个与它们的查询boost相等的分数。
store
默认情况下,字段值被索引以使其可搜索,但它们不存储。这意味着可以查询字段,但无法检索原始字段值。通常这并不重要。字段值已经是_source字段的一部分,该字段默认存储。如果您只想检索单个字段或几个字段的值,而不是整个_source,那么这可以通过字段过滤上下文 source filting context来实现。
在某些情况下,存储字段是有意义的。例如,如果您有一个包含标题、日期和非常大的内容字段的文档,您可能只想检索标题和日期,而不需要从大型_source字段中提取这些字段,可以将标题和日期字段的 store定义为 ture。
term_vector
Term vectors 包含分析过程产生的索引词信息,包括:
索引词列表
每个索引词的位置(或顺序)
索引词在原始字符串中的原始位置中的开始和结束位置的偏移量。
term vectors 会被存储,索引它可以作为一个特使的文档返回。
term_vector可取值:
不存储 term_vector信息,默认值。
yes
只存储字段中的值。
with_positions
存储字段中的值与位置信息。
with_offsets
存储字段中的值、偏移量
with_positions_offsets
存储字段中的值、位置、偏移量信息。
元字段 meta-fields
一个文档根据我们定义的业务字段保存有数据之外,它还包含了元数据字段
(meta-fields)。元字段不需要用户定义,在任一文档中都存在,有点类似于数据库的表结构数据。在名称上有个显著的特征,都是以下划线“_”开头。
我们可以看看:get /open-soft/_doc/1
大体分为五种类型:身份(标识)元数据、索引元数据、文档元数据、路由元数据以及其他类型的元数据,当然不是每个文档这些元字段都有的。
身份(标识)元数据
_index:文档所属索引 , 自动被索引,可被查询,聚合,排序使用,或者脚本里访问
_type:文档所属类型,自动被索引,可被查询,聚合,排序使用,或者脚本里访问
_id:文档的唯一标识,建索引时候传入 ,不被索引,可通过_uid被查询,脚本里使用,不能参与聚合或排序
_uid:由_type和_id字段组成,自动被索引 ,可被查询,聚合,排序使用,或者脚本里访问,6.0.0版本后已废止。
索引元数据
_all:自动组合所有的字段值,以空格分割,可以指定分器词索引,但是整个值不被存储,所以此字段仅仅能被搜索,不能获取到具体的值。6.0.0版本后已废止。
_field_names:索引了每个字段的名字,可以包含 null值,可以通过 exists查询或 missing查询方法来校验特定的字段
文档元数据
_source : 一个 doc的原生的 json 数据,不会被索引,用于获取提取字段值,启动此字段,索引体积会变大,如果既想使用此字段又想兼顾索引体积,可以开启索引压缩。
_source是可以被禁用的,不过禁用之后部分功能不再支持,这些功能包括:部分 update api、运行时高亮搜索结果
索引重建、修改 mapping以及分词、索引升级
debug查询或者聚合语句
索引自动修复
_size:整个_source 字段的字节数大小,需要单独安装一个 mapper-size插件才能展示。
路由元数据
_routing:一个 doc可以被路由到指定的 shard上。
_meta:一般用来存储应用相关的元信息。
其他
例如:
put /open-soft/_mapping
{
"_meta": {
"class": "cn.enjoyedu.User",
"version": {"min": "1.0", "max": "1.3"}
}
}
管理 Elasticsearch 索引和文档
在 es 中,索引和文档是 REST 接口操作的最基本资源,所以对索引和文档的管理也是我们必须要知道的。索引一般是以索引名称出现在 REST请求操作的资源路径上,而文档是以文档 ID 为标识出现在资源路径上。映射类型_doc 也可以认为是一种资源,但在 es7 中废除了映射类型,所以可以_doc 也视为一种接口。
索引的管理
在前面的学习中我们已经知道,GET 用来获取资源,PUT 用来更新资源,DELETE用来删除资源。所以对索引,GET用来查看索引,PUT用来创建索引,DELETE用来删除索引,还有一个 HEAD 请求,用来检验索引是否存在。除此之外,对索引的管理还有
列出所有索引
GET /_cat/indices?v
关闭索引和打开
POST /open-soft/_close、、
除了删除索引,还可以选择关闭它们。如果关闭了一个索引,就无法通过Elasticsearch来读取和写人其中的数据,直到再次打开它。
在现实世界中,最好永久地保存应用日志,以防要查看很久之前的信息。另一方面,在 Elasticsearch 中存放大量数据需要增加资源。对于这种使用案例,关闭旧的索引非常有意义。你可能并不需要那些数据,但是也不想删除它们。
一旦索引被关闭,它在 Elasticsearch 内存中唯-的痕迹是其元数据,如名字
以及分片的位置。如果有足够的磁盘空间,而且也不确定是否需要在那个数据中再次搜索,关闭索引要比删除索引更好。关闭它们会让你非常安心,永远可以重新打开被关闭的索引,然后在其中再次搜索。
重新打开 POST /open-soft/_open
配置索引
通过 settings参数配置索引,索引的所有配置项都以“index”开头。索引的管理分为静态设置和动态设置两种。
静态设置
只能在索引创建时或在状态为 closed index(闭合索引)上设置,主要配置索引主分片、压缩编码、路由等相关信息
index.number_of_shards主分片数,默认为 5.只能在创建索引时设置,不能修改
index.shard.check_on_startup 是否应在索引打开前检查分片是否损坏,当检查到分片损坏将禁止分片被打开。false:默认值;checksum:检查物理损坏;true:检查物理和逻辑损坏,这将消耗大量内存和 CPU;fix:检查物理和逻辑损坏。
有损坏的分片将被集群自动删除,这可能导致数据丢失
index.routing_partition_size 自定义路由值可以转发的目的分片数。默认为 1,只能在索引创建时设置。此值必须小于 index.number_of_shards
index.codec 默认使用 LZ4压缩方式存储数据,也可以设置为
best_compression,它使用 DEFLATE 方式以牺牲字段存储性能为代价来获得更高的压缩比例。
如:
put test1{
"settings":{
"index.number_of_shards":3,
"index.codec":"best_compression"
}
}
动态设置
通过接口“_settings”进行,同时查询配置也通过这个接口进行,比如:get _settings
get /open-soft/_settings
get /open-soft,test1/_settings
配置索引则通过:
put test1/_settings
{
"refresh_interval":"2s"
}
常用的配置参数如下:
index.number_of_replicas 每个主分片的副本数。默认为 1
index.auto_expand_replicas 基于可用节点的数量自动分配副本数量,默认为false(即禁用此功能)
index.refresh_interval 执行刷新操作的频率。默认为 1s。可以设置为 -1 以禁用刷新。
index.max_result_window 用于索引搜索的 from+size 的最大值。默认为10000
index.blocks.read_only 设置为 true 使索引和索引元数据为只读,false 为允许写入和元数据更改。
index.blocks.read 设置为 true 可禁用对索引的读取操作
index.blocks.write 设置为 true 可禁用对索引的写入操作
index.blocks.metadata 设置为 true 可禁用索引元数据的读取和写入
index.max_refresh_listeners 索引的每个分片上可用的最大刷新侦听器数index.max_docvalue_fields_search 一次查询最多包含开启 doc_values 字段
的个数,默认为 100
index.max_script_fields 查询中允许的最大 script_fields数量。默认为 32。
index.max_terms_count 可以在 terms 查询中使用的术语的最大数量。默认为65536。
index.routing.allocation.enable 控制索引分片分配。All(所有分片)、primaries(主分片)、new_primaries(新创建分片)、none(不分片)
index.routing.rebalance.enable 索引的分片重新平衡机制。all、primaries、replicas、none
index.gc_deletes 文档删除后(删除后版本号)还可以存活的周期,默认
为 60s
index.max_regex_length用于正在表达式查询(regex query)正在表达式长度,默认为 1000
配置映射
通过_mapping 接口进行,在我们前面的章节中,已经展示过了。
get /open-soft/_mapping
或者只看某个字段的属性:
get /open-soft/_mapping/field/lang
修改映射,当然就是通过 put或者 post方法了。但是要注意,已经存在的映射只能添加字段或者字段的多类型。但是字段创建后就不能删除,大多数参数也不能修改,可以改的是 ignore_above。所以设计索引时要做好规划,至少初始时的必要字段要规划好。
增加文档
增加文档,我们在前面的章节已经知道了,比如:
put /open-soft/_doc/1
{
"name": "Apache Hadoop",
"lang": "Java",
"corp": "Apache",
"stars":200
}
如果增加文档时,在 Elasticsearch中如果有相同 ID的文档存在,则更新此文档,比如执行
put /open-soft/_doc/1
{
"name": "Apache Hadoop2",
"lang": "Java8",
"corp": "Apache",
"stars":300
}
则会发现已有文档的内容被更新了
文档的 id
当创建文档的时候,如果不指定 ID,系统会自动创建 ID。自动生成的 ID 是一个不会重复的随机数。使用 GUID 算法,可以保证在分布式环境下,不同节点同一时间创建的_id一定是不冲突的。比如:
post /open-soft/_doc
{
"message":"Hello"
}
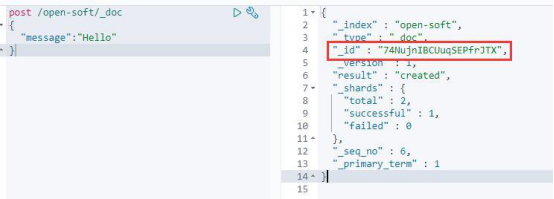
查询文档
get /open-soft/_doc/
更新文档
前面我们用 put方法更新了已经存在的文档,但是可以看见他是整体更新文档,如果我们要更新文档中的某个字段怎么办?需要使用_update接口。
post /open-soft/_update/1/
{
"doc":{
"year": 2016
}
}
如果文档中存在 year字段,更新 year 字段的值,如果不存在 year 字段,则会新增 year字段,并将值设为 2016。
update 接口在文档不存在时提示错误,如果希望在文档不存在时创建文档,则可以在请求中添加 upsert参数或 doc_as_upsert 参数,例如:
POST /open-soft/_update/5
{
"doc": {
"year": "2020"
},
"upsert":{
"name" : "Enjoyedu Framework",
"corp" : "enjoyedu "
}
}
或
POST /open-soft/_update/6
{
"doc": {
"year": "2020"
},
"doc_as_upsert" : true
}
upsert参数定义了创建新文档使用的文档内容,而 doc_as_upsert 参数的含义是直接使用 doc参数中的内容作为创建文档时使用的文档内容。
删除文档
delete /open-soft/_doc/1
数据检索和分析
为了方便我们学习,我们导入 kibana 为我们提供的范例数据。
目前为止,我们已经探索了如何将数据放入 Elasticsearch,现在来讨论下如何将数据从 Elasticsearch中拿出来,那就是通过搜索。毕竟,如果不能搜索数据,那么将其放入搜索引擎的意义又何在呢?幸运的是,Elasticsearch 提供了丰富的接口来搜索数据,涵盖了 Lucene 所有的搜索功能。因为 Elasticsearch允许构建搜索请求的格式很灵活,请求的构建有无限的可能性。要了解哪些查询和过滤器的组合适用于你的数据,最佳的方式就是进行实验,因此不要害怕在项目的数据上尝试这些组合,这样才能弄清哪些更适合你的需求。
_search 接口
所有的 REST搜索请求使用_search 接口,既可以是 GET请求,也可以是 POST请求,也可以通过在搜索 URL 中指定索引来限制范围。
_search 接口有两种请求方法,一种是基于 URI 的请求方式,另一种是基于请求体的方式,无论哪种,他们执行的语法都是基于 DSL(ES 为我们定义的查询语言,基于 JSON的查询语言),只是形式上不同。我们会基于请求体的方式来学习。比如说:
get kibana_sample_data_flights/_search
{
"query":{
"match_all":{}
}
}
或
get kibana_sample_data_flights/_search
{
"query":{
"match_none":{}
}
}
当然上面的查询没什么太多的用处,因为他们分别代表匹配所有和全不匹配。
所以我们经常要使用各种语法来进行查询,一旦选择了要搜索的索引,就需要配置搜索请求中最为重要的模块。这些模块涉及文档返回的数量,选择最佳的文档返回,以及配置不希望哪些文档出现在结果中等等。
■ query-这是搜索请求中最重要的组成部分,它配置了基于评分返回的最佳文档,也包括了你不希望返回哪些文档。
■ size-代表了返回文档的数量。
■ from-和 size 一起使用,from 用于分页操作。需要注意的是,为了确定第2页的 10 项结果,Elasticsearch 必须要计算前 20 个结果。如果结果集合不断增加,获取某些靠后的翻页将会成为代价高昂的操作。
■ _source指定_ source 字段如何返回。默认是返回完整的_ source字段。
通过配置_ source,将过滤返回的字段。如果索引的文档很大,而且无须结果中的全部内容,就使用这个功能。请注意,如果想使用它,就不能在索引映射中关闭_source 字段。
■ sort默认的排序是基于文档的得分。如果并不关心得分,或者期望许多文档的得分相同,添加额外的 sort将帮助你控制哪些文档被返回。
结果起始和页面大小
命名适宜的 from和 size字段,用于指定结果的开始点,以及每“页"结果的数量。举个例子,如果发送的 from 值是 7,size值是 5,那么 Elasticsearch 将返回第8、9、10、11 和 12项结果(由于 from 参数是从 0开始,指定 7 就是从第 8项结果开始)。如果没有发送这两个参数,Elasticsearch 默认从第一项结果开始(第 0 项结果),在回复中返回 10项结果。
例如
get kibana_sample_data_flights/_search
{
"from":100,
"size":20,
"query":{
"term":{
"DestCountry":"CN"
}
}
}
但是注意,from与 size 的和不能超过 index. max_result_window 这个索引配置项设置的值。默认情况下这个配置项的值为 10000,所以如果要查询 10000 条以后的文档,就必须要增加这个配置值。例如,要检索第 10000 条开始的 200条数据,这个参数的值必须要大于 10200,否则将会抛出类似“Result window is toolarge'的异常。
由此可见,Elasticsearch 在使用 from 和 size处理分页问题时会将所有数据全部取出来,然后再截取用户指定范围的数据返回。所以在查询非常靠后的数据时,即使使用了 from和 size定义的分页机制依然有内存溢出的可能,而 max_result_ window设置的 10000条则是对 Elastiesearch 的一.种保护机制。
那么 Elasticsearch 为什么要这么设计呢?首先,在互联网时代的数据检索应该通过相似度算法,提高检索结果与用户期望的附和度,而不应该让用户在检索结果中自己挑选满意的数据。以互联网搜索为例,用户在浏览搜索结果时很少会看到第 3页以后的内容。假如用户在翻到第 10000 条数据时还没有找到需要的结果,那么他对这个搜索引擎一定会非常失望。
_source 参数
元字段_source 中存储了文档的原始数据。如果请求中没有指定_source,Elasticsearch 默认返回整个_ source,或者如果_ source没有存储,那么就只返回匹配文档的元数据:_ id、_type、_index 和_score。
例如:
get kibana_sample_data_flights/_search
{
"query":{
"match_all":{}
},
"_source":["OriginCountry","DestCountry"]
}
你不仅可以返回字段列表,还可以指定通配符。例如,如果想同时返回"
DestCountry "和" DestWeather "字段,可以这样配置_ source: "Dest*"。也可以使用通配字符串的数组来指定多个通配符,例如_ source:[" Origin*", "* Weather "]。
get kibana_sample_data_flights/_search
{
"query":{
"match_all":{}
},
"_source":["Origin*","*Weather"]
}
不仅可以指定哪些字段需要返回,还可以指定哪些字段无须返回。比如:get kibana_sample_data_flights/_search
{
"_source":{
"includes":["*.lon","*.lat"],
"excludes":"DestLocation.*"
}
}
排序
大多搜索最后涉及的元素都是结果的排序( sort )。如果没有指定 sort 排序选项,Elasticsearch返回匹配的文档的时候,按照_ score 取值的降序来排列,这样最为相关的(得分最高的)文档就会排名在前。为了对字段进行升序或降序排列,
指定映射的数组,而不是字段的数组。通过在 sort 中指定字段列表或者是字段映射,可以在任意数量的字段上进行排序。
例如:
get kibana_sample_data_flights/_search
{
"from":100,
"size":20,
"query":{
"match_all":{}
},
"_source":["Origin*","*Weather"],
"sort":[{"DistanceKilometers":"asc"},{"FlightNum":"desc"}]
}
ELK入门及基本使用的更多相关文章
- ELK入门使用-与springboot集成
前言 ELK官方的中文文档写的已经挺好了,为啥还要记录本文?因为我发现,我如果不写下来,过几天就忘记了,而再次捡起来必然还要经历资料查找筛选测试的过程.虽然这个过程很有意义,但并不总是有那么多时间去做 ...
- 1.elk 入门示例
zjtest7-frontend:/usr/local/logstash-2.3.4/bin# ./logstash -e 'input{stdin{}} output{stdout{codec=&g ...
- ELK入门以及常见指令
ES的资源: https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started.htmlhttps://w ...
- elk 入门 - 分析nginx日志 + json格式 + 有调试的意识 + elk7.2.0
1.本次采用的一台主机,将所有的软件安装一台上进行测试工作. 2.安装部署:https://blog.51cto.com/hwg1227/2299995 3.简单调试 输出rubydebug inpu ...
- ELK系列(1) - Elasticsearch + Logstash + Kibana + Log4j2快速入门与搭建用例
前言 最近公司分了个ELK相关的任务给我,在一边学习一边工作之余,总结下这些天来的学习历程和踩坑记录. 首先介绍下使用ELK的项目背景:在项目的数据库里有个表用来存储消息队列的消费日志,这些日志用于开 ...
- ELK安装文档
ELK安装文档: http://cuidehua.blog.51cto.com/5449828/1769525 如何将客户端日志通过ogstash-forwarder发送给服务端的logstash h ...
- ElasticSearch基础入门学习笔记
前言 本笔记的内容主要是在从0开始学习ElasticSearch中,按照官方文档以及自己的一些测试的过程. 安装 由于是初学者,按照官方文档安装即可.前面ELK入门使用主要就是讲述了安装过程,这里不再 ...
- SpringCloud学习5-如何创建一个服务提供者provider
前几篇主要集中在注册中心eureka的使用上,接下来可以创建服务提供者provider来注册到eureka. demo源码见: https://github.com/Ryan-Miao/spring- ...
- SpringCloud如何创建一个服务提供者provider
SpringCloud如何创建一个服务提供者provider 创建子moudle provider-demo 创建一个子module,项目名叫provider-demo. 填充springboot和s ...
随机推荐
- Unity 笔记
摄像机 Main Camera 跟随主角移动,不看 UI 剧情摄像机 当进入剧情时,可以关闭 main camera,启用剧情摄像机,不看 UI UI 摄像机 看 UI Unity编辑器常用的sett ...
- 在 .NetCore 项目中使用 SkyWalkingAPM 踩坑排坑日记
SkyWalking 概述 SkyWalking 是观察性分析平台和应用性能管理系统.提供分布式追踪.服务网格遥测分析.度量聚合和可视化一体化解决方案.支持Java, .Net Core, PHP, ...
- Deep learning-based personality recognition from text posts of online social networks 阅读笔记
文章目录 一.摘要 二.模型过程 1.文本预处理 1.1 文本切分 1.2 文本统一 2. 基于统计的特征提取 2.1 提取特殊的语言统计特征 2.2 提取基于字典的语言特征 3. 基于深度学习的文本 ...
- day7 地址 名片管理系统
1 无限循环 (while True) break 退出 人为设计的 ,并且有退除的出口 死循环 bug 错误 2.引用 数字型
- IE9知识点汇总
1.首先ie9不支持flex布局,只能使用float,要想支持ie低版本,两者要同时使用. 2.input框不支持placeholder属性,只能自己加span标签模拟出来,调整样式. 3.单个css ...
- 初学Linux (Linux_note)
根目录:/ /root: 存放root用户相关文件 /home: 存放不同用户的相关文件 /bin: 存放常用命令的目录 /sbin: 要具有一定权限才可以使用的命令 /mnt: 默认挂载光驱和软驱的 ...
- 【测试技术分享】Liunx常用操作命令集合
Linux命令 ls 查看文件目录内容 ls -lha l:详细信息 h:人性化显示 a:查看隐藏目录 ls -目录名 查看指定目录 d rwx rwx rwx d:文件夹 -:文件 rwx:拥有 ...
- 数据隐私和GDPR
近十几年来,随着大数据给各行各业带来的变化,以及数据时代不断强调的数据就是燃料,谁掌握数据谁就掌握未来的各种论调,大家纷纷开始收集数据,挖掘数据,转卖数据.而个人,作为数据真正拥有者的利益早就在商业利 ...
- MongoDB联表查询
表A: id name --------------------------- 1 Tom 2 Roger 3 Mars 4 Brent 表B: id result ----------------- ...
- Python 抓包程序(pypcap)
#/usr/bin/env python #-*-coding:utf8-*- #抓包脚本 """ This script is used to Capture and ...