深入理解MySQL系列之索引
索引
查找一条数据的过程
先看下InnoDB的逻辑存储结构:
表空间:可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。默认有个共享表空间ibdata1。如果启用innodb_file_per_table参数,需要注意每张表的表空间内存放的只是数据、索引和插入缓冲Bitmap页,其他类的数据,如回滚信息、插入缓冲索引页、系统事务信息、二次写缓冲等还是存放在原来共享表空间中。
段:
表空间是由各个段组成,常见的段有数据段、索引段、回滚段等。数据段即为B+树叶子节点(Leaf node segment),索引段即为B+树非叶子节点(Non-leaf node segment)
区区:是由连续页组成的空间,在任何情况下每个区大小都为1MB。默认情况下,存储引擎页的大小为16KB,即一个区中一共有连续64个连续的页。而为保证页的连续性,InnoDB存储引擎一次从磁盘申请4-5个区。
页:
页(也可以称块),是InnoDB磁盘管理的最小单位。默认每个页大小16KB。1.2x版本后也可以通过参数innodb_page_size设置为4k、8k、16k
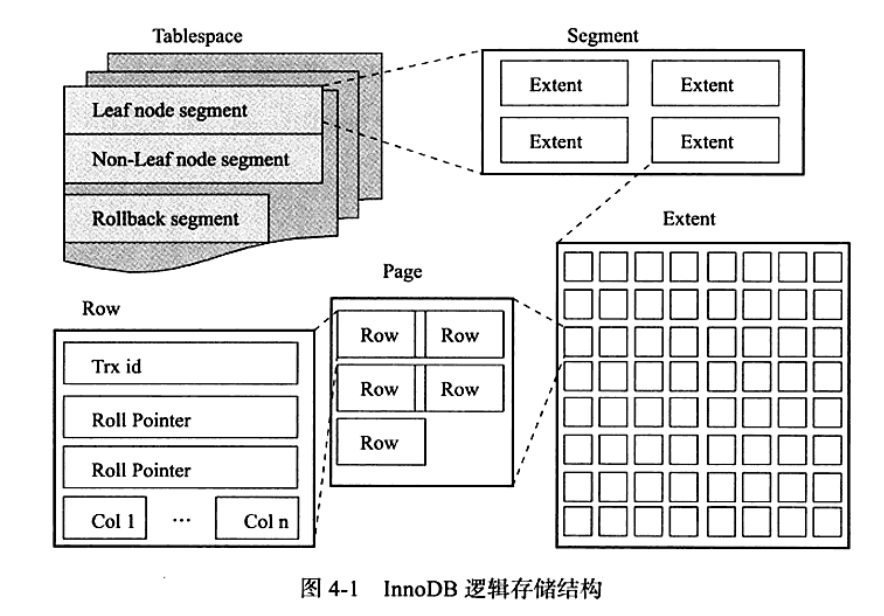
如查一条数据:select * from user where id=5;
这里id是主键,我们通过这棵B+树来查找,首先会去找到根页,每张表的根页位置在表空间文件中是固定的;找到根页后通过二分查找法,定位到id=5的数据应该在指针P5指向的页中,那么进一步去page number=5的页中查找,同样通过二分查询法即可找到id=5的记录:
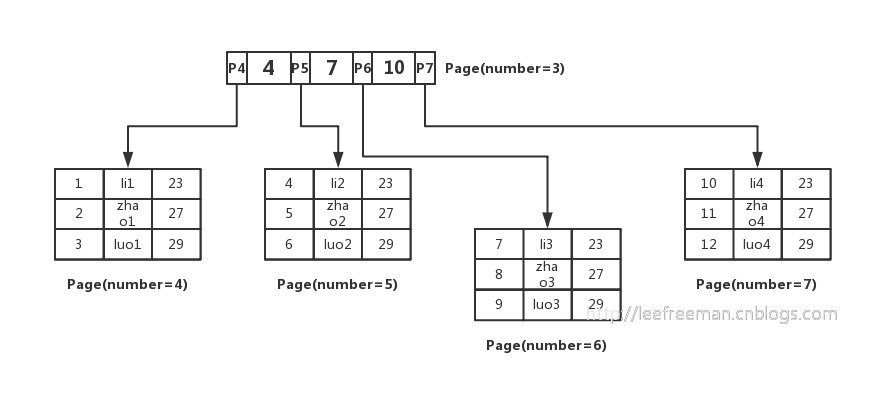
计算一棵B+树可以存放多少行数据
也可以通过命令查看InnoDB每页默认16KB:
show variables like 'innodb_page_size';
先计算非叶子节点, 假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节
而一个页中能存放多少这样的单元,其实就代表有多少指针,即16384/14=1170。
那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。
根据同样的原理我们可以算出一个高度为3的B+树可以存放:1170117016=21902400条这样的记录。
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。
索引一些概念
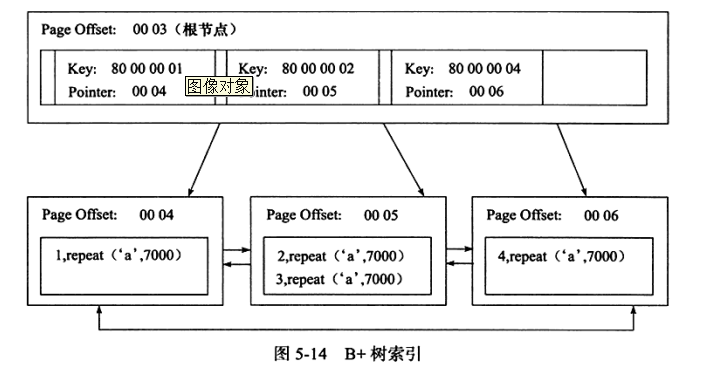
- 聚簇索引(clustered index): 就是将索引和数据放到一起,找到索引也就找到了数据;如下图叶子节点存放一行所有数据。
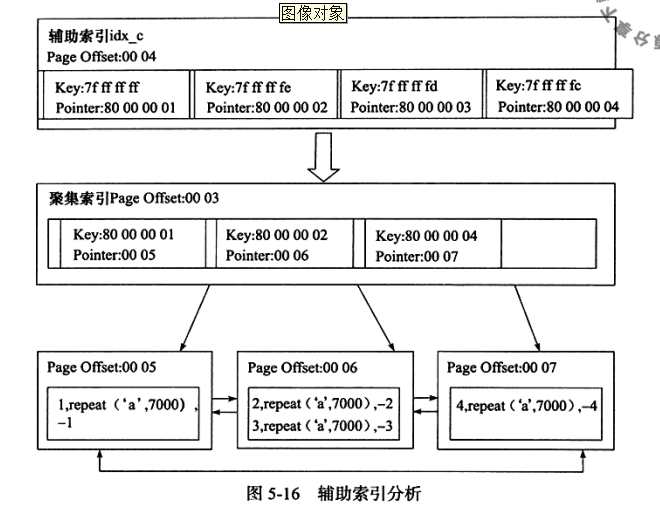
- 辅助索引(Secondary Index或非聚簇索引): 就是将数据和索引分开,查找时需要先查找到索引,然后通过索引回表找到相应的数据。
回表:先通过数据库索引扫描出数据所在的行,再通过行主键id取出索引中未提供的数据,即基于非主键索引的查询需要多扫描一棵索引树。
如下图,辅助索引查找后,会再回表到聚簇索引,最后找到数据。
InnoDB有且只有一个聚簇索引,而MyISAM中都是非聚簇索引。
- 联合索引:指对表上多个列进行索引。
联合索引的最左前缀匹配原则: 对多个字段同时建立的组合索引(有顺序,ABC,ACB是完全不同的两种联合索引) 以联合索引(a,b,c)为例,建立这样的索引相当于建立了索引a、ab、abc三个索引。另外组合索引实际还是一个索引,并非真的创建了多个索引,只是产生的效果等价于产生多个索引。
- 覆盖索引: 即从辅助索引中就可以得到查询的记录,而不需要查询聚簇索引中的记录。
使用覆盖好处:
- 辅助索引不包含整行记录的所有信息,故其大小要远小于聚簇索引,减少大量IO操作。
- 对某些统计(如count(id))并不会通过查询聚簇索引来进行统计,减少IO操作
唯一索引:以唯一列生成的索引,该列不允许有重复值,但允许有空值(NULL)
索引下推:MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表字数。
为什么选B+树,而不是B树
B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少
指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
为什么InnoDB只有一个聚簇索引,而不将所有索引都使用聚簇索引?
因为聚簇索引是将索引和数据都存放在叶子节点中,如果所有的索引都用聚簇索引,则每一个索引都将保存一份数据,会造成数据的冗余,在数据量很大的情况下,这种数据冗余是很消耗资源的。
什么情况下会发生明明创建了索引,但是执行的时候并没有通过索引呢?
查询优化器。
一条SQL语句的查询,可以有不同的执行方案,至于最终选择哪种方案,需要通过优化器进行选择,选择执行成本最低的方案。
优化过程大致如下:
- 1、根据搜索条件,找出所有可能使用的索引
- 2、计算全表扫描的代价
- 3、计算使用不同索引执行查询的代价
- 4、对比各种执行方案的代价,找出成本最低的那一个 。
索引的优缺点
索引的优点如下:
- 1、唯一索引可以保证每一行数据的唯一性
- 2、提高查询速度
- 3、加速表与表的连接
- 4、显著的减少查询中分组和排序的时间
- 5、通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点如下:
- 创建索引时,需要对表加锁,在锁表的同时,可能会影响到其他的数据操作
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、UPDATE 和 DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存索引文件。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不算严重,但如果你在一个大表上创建了多种组合索引,且伴随大量数据量插入,索引文件大小也会快速膨胀。
- 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- 对于非常小的表,大部分情况下简单的全表扫描更高效。
使用索引时的注意事项
原则:
不应该
1、索引不是越多越好。索引太多,维护索引需要时间跟空间
2、 频繁更新的数据,不宜建索引。
3、数据量小的表没必要建立索引。
应该
1、重复率小的列建议生成索引。因为重复数据少,索引树查询更有效率,等价基数越大越好。
2、数据具有唯一性,建议生成唯一性索引。在数据库的层面,保证数据正确性
3、频繁group by、order by的列建议生成索引。可以大幅提高分组和排序效率
4、经常用于查询条件的字段建议生成索引。通过索引查询,速度更快
索引失效的场景
1、模糊搜索:左模糊或全模糊都会导致索引失效,比如'%a'和'%a%'。但是右模糊是可以利用索引的,比如'a%'
2、隐式类型转换:比如select * from t where name = xxx , name是字符串类型,但是没有加引号,所以是由MySQL隐式转换的,所以会让索引失效
3、当语句中带有or的时候:比如select * from t where name=‘sw’ or age=14
4、不符合联合索引的最左前缀匹配:(A,B,C)的联合索引,你只where了C或B或只有B,C
其他注意事项:
- 索引不会包含有 null 值的列,只要列中包含有 null值都将不会被包含在索引中。
- 使用短索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和 I/O 操作
- 索引列排序。查询只使用一个索引,因此如果 where 子句中已经使用了索引的话,那么 order by 中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
- 不要在列上进行运算,这将导致索引失效而进行全表扫描
- 不使用 not in 和 <> 操作,这不属于支持的范围查询条件,不会使用索引。
《MySQL技术内幕》
https://mp.weixin.qq.com/s/6j64s9W6ogs5Y8BbhhkgnA
https://mp.weixin.qq.com/s/KB73550tKpNccW-WKxT7-A
https://mp.weixin.qq.com/s/ovMx9Dv9NCFxSsFM98uYFw
深入理解MySQL系列之索引的更多相关文章
- 深入理解MySQL系列之锁
按锁思想分类 悲观锁 优点:适合在写多读少的并发环境中使用,虽然无法维持非常高的性能,但是在乐观锁无法提更好的性能前提下,可以做到数据的安全性 缺点:加锁会增加系统开销,虽然能保证数据的安全,但数据处 ...
- MySQL系列(六)--索引优化
在进行数据库查询的时候,索引是非常重要的,当然前提是达到一定的数据量.索引就像字典一样,通过偏旁部首来快速定位,而不是一页页 的慢慢找. 索引依赖存储引擎层实现,所以支持的索引类型和存储引擎相关,同一 ...
- 正确理解Mysql的列索引和多列索引
MySQL数据库提供两种类型的索引,如果没正确设置,索引的利用效率会大打折扣却完全不知问题出在这. CREATE TABLE test ( id INT NOT NULL, last_ ...
- 理解MySQL数据库覆盖索引
话说有这么一个表: CREATE TABLE `user_group` ( `id` int(11) NOT NULL auto_increment, `uid` int(11) NOT NULL, ...
- MySQL系列:索引基本操作(4)
1. 索引简介 索引是一种特殊的数据库结构,可以用来快速查询数据中的特定记录. MySQL中索引包括:普通索引.唯一性索引.全文索引.单列索引.多列索引和空间索引等. 1.1 索引定义 索引由数据库表 ...
- 理解MySQL数据库覆盖索引 (转)
http://www.cnblogs.com/zl0372/articles/mysql_32.html 话说有这么一个表: CREATE TABLE `user_group` ( `id` int( ...
- 深入理解MySQL系列之redo log、undo log和binlog
事务的实现 redo log保证事务的持久性,undo log用来帮助事务回滚及MVCC的功能. InnoDB存储引擎体系结构 redo log Write Ahead Log策略 事务提交时,先写重 ...
- MySQL系列(九)--InnoDB索引原理
InnoDB在MySQL5.6版本后作为默认存储引擎,也是我们大部分场景要使用的,而InnoDB索引通过B+树实现,叫做B-tree索引.我们默认创建的 索引就是B-tree索引,所以理解B-tree ...
- Mysql高手系列 - 第22篇:深入理解mysql索引原理,连载中
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 欢迎大家加我微信itsoku一起交流java.算法.数据库相关技术. 这是Mysql系列第22篇. 背景 使用mys ...
随机推荐
- centos8 yum 升级nginx
原文地址:https://blog.csdn.net/lpwmm/article/details/105627476 CentOS8的Yum仓库中内置的nginx版本是1.14.1,最近漏扫提示需要升 ...
- C语言讲义——冒泡排序(bubble sort)
冒泡排序三步走: 循环 交换 回一手 一个数和其它数比较(循环) 每个数都要做这种比较(再一层循环) 准备工作 #include <stdio.h> void sort(int arr[] ...
- Java基础教程——类和对象
视屏讲解:https://www.bilibili.com/video/av48272174 面向过程 VS 面向对象 面向过程:强调步骤. 面向对象:强调对象. 面向对象的特点就是:隐藏具体实现的细 ...
- Java多线程中的wait/notify通信模式
前言 最近在看一些JUC下的源码,更加意识到想要学好Java多线程,基础是关键,比如想要学好ReentranLock源码,就得掌握好AQS源码,而AQS源码中又有很多Java多线程经典的一些应用:再比 ...
- ubuntu安装vmware
安装过程: 首先直接将光盘文件中的tar.gz复制到桌面,解压过程如下 中间遇到的问题: 在执行的过程中一直在回车,需要输入的全为yes,还有一个是what is the location of th ...
- java.util.UnknownFormatConversionException: Conversion = 'j' || Conversion = 'D' || Conversion = 'Y'
执行内容: String a = "select * from j_question j where j.status = %s and j.title like '%java%'" ...
- Robot Framework接口自动化案例分享⑦——Jenkins持续集成
一.RobotFramework插件安装 1.Jenkins首页->系统管理->插件管理->可选插件-> 2.搜索robot,点击直接安装 二.任务参数配置 1.新建任务 Je ...
- dubbo源码学习(二)dubbo容器启动流程简略分析
dubbo版本2.6.3 继续之前的dubbo源码阅读,从com.alibaba.dubbo.container.Main.main(String[] args)作为入口 简单的数据一下启动的流程 1 ...
- 记一次MacPro风扇一直转的问题排查
1.查看CPU占用最高的进程 借助活动监视器,查看CPU占用最高的进程,可以观察到是Chrome浏览器 2.打开Chrome的任务管理器 2.1.查看CPU占用最高的chrome进程 3.分析和结束进 ...
- CSS基础-链接
链接的状态 link 没有访问过的 visited 访问过的 hover 用户鼠标刚好停留在这个链接上时 focus 通过TAB键或者编程方法将一个链接选中时 active 链接被激活时 默认的链 ...