Spider--动态网页抓取--审查元素
# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,我们需要使用动态网页抓取技术。# Ajax: Asynchronous Javascript And XML,异步JvvaScript和 XML; 在不重新加载整个网页的情况下对网页的某部分进行更新,节省流量,速度快。# 加大了 爬虫的难度。为解决这个问题,可以采用两种技术: 1)通过浏览器审查元素解析真实网页的地址。2)使用 Selenium模拟浏览器的方法。
# 1--通过浏览器审查元素解析真实网页的地址:
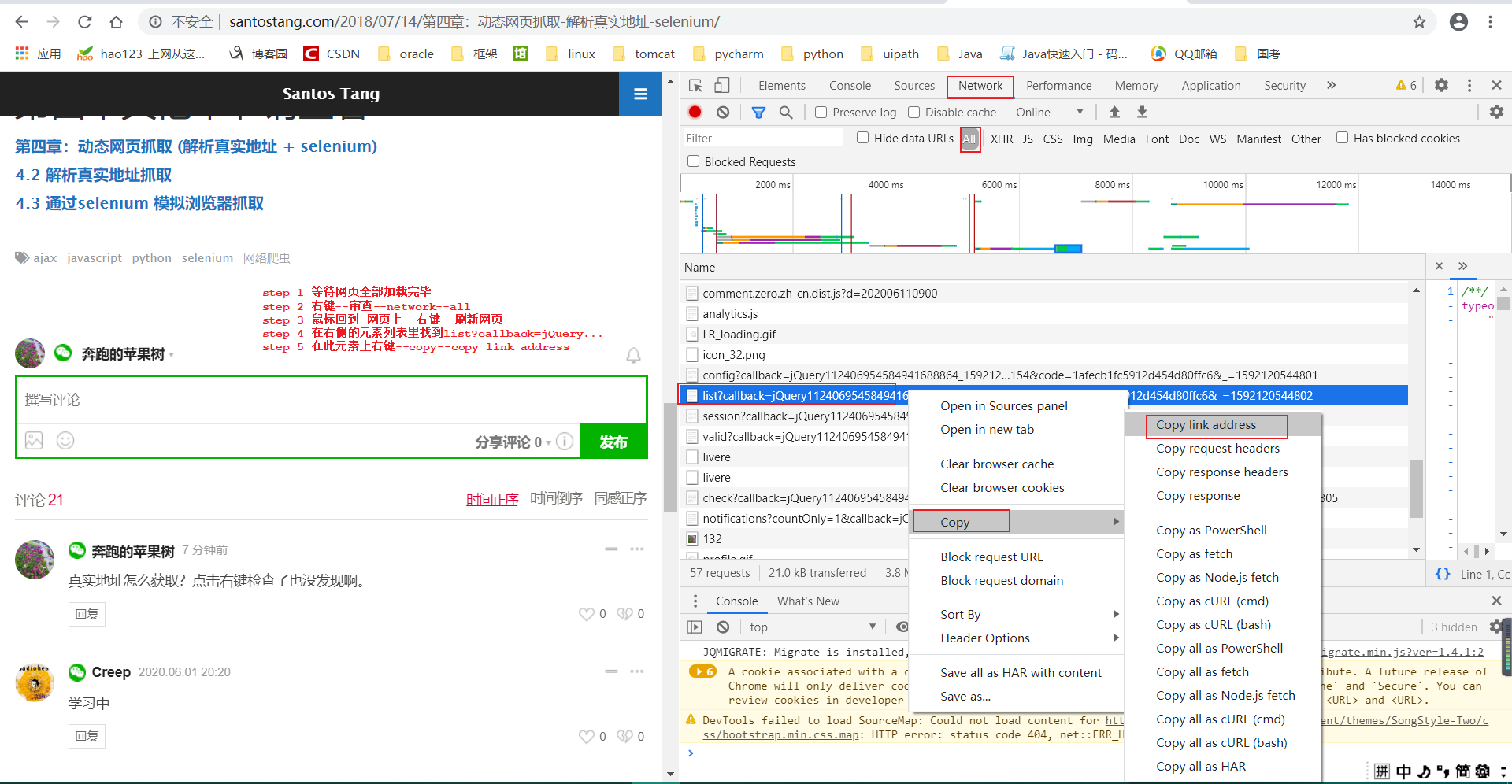
第一页和第二页最明显的区别在于 offset (虽然有其他地方也不一样,但不影响,只有 offset起决定作用),所以可以通过控制 offset来翻页。
请求头:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362
# 根据上面信息,我们将代码设计为:import requestsurl = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}r = requests.get(url, headers= headers)print (r.text)

# 只获取第一页评论:# 解析得到的字符串r.text(即 json字符串)可以使用json库来完成解析:import jsonimport requestsurl = """https://api-zero.livere.com/v1/comments/list?callback=jQuery112406954584941688864_1592120544800&limit=10&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592120544802"""headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}r = requests.get(url, headers= headers)json_data_dict=json.loads(r.text[r.text.find('{'):-2]) # 将从左大括号开始至倒数第三个字符(即将字符串末尾的括号和分号去除掉)load反序列化成字典。# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。comments_list=json_data_dict['results']['parents']for comment_dict in comments_list:print(comment_dict['content'])# 真实地址怎么获取?点击右键检查了也没发现啊。# 学习中# 一起学习# 一句话,给我爬!!!!# 为什么不多放几个回帖# 哎,还要多少啊。# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗# 我要疯了。作者拜托你能不能改一下啊# 一页到底能装多少回帖啊?# 好累啊
# 获取两页评论:import jsonimport requestsdef get_comments(page_num):global comments_listheaders = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}url='https://api-zero.livere.com/v1/comments/list?callback=jQuery1124042695935490813275_1592128347126&limit=10&offset='\+page_num+\'&repSeq=4547710&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=1afecb1fc5912d454d80ffc6&_=1592128347133'r = requests.get(url, headers= headers)json_data_dict=json.loads(r.text[r.text.find('{'):-2]) # 将从左大括号开始至倒数第三个字符(即将字符串末尾的 ');'括号和分号去除掉)load反序列化成字典。# json_data_dict是一个字典嵌套字典的数据结构(字典的value是字典)。# 其中外部字典的results键对应一个字典,该字典的parents键对应一个值是列表(列表的元素又是字典)。comments_list.extend(json_data_dict['results']['parents']) # 列表if __name__=='__main__':comments_list=[]for page_num in range(1,3):get_comments(str(page_num))for comment_dict in comments_list:print(comment_dict['content'])真实地址怎么获取?点击右键检查了也没发现啊。# 学习中# 一起学习# 一句话,给我爬!!!!# 为什么不多放几个回帖# 哎,还要多少啊。# 我不知道要多少帖子才能翻篇啊,你们没有买他的书吗# 我要疯了。作者拜托你能不能改一下啊# 一页到底能装多少回帖啊?# 好累啊# 还不够哦# 如果这样违反了你的规定,请原谅,我也是没有办法,只能帮你把水灌上# 不然好多代码我没有办法去按照你书上的内容操作。很郁闷# 主人可能忘记爬虫的跟帖必须要翻过两页才能测试啊# 是不是要10页才翻篇# 我要追加多少评论才够两页呢# 为什么我能看到评论呢??# 学习# 不是# 我是第一个来的吗?
# 回顾:# 1)--代码在 IDE里的换行:a='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\ggggg'print(a) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccgggggb='aaaaaaaaaaaaaaaaaaaaabbbbbbccc'\+\'ggggg'print(b) # aaaaaaaaaaaaaaaaaaaaabbbbbbcccggggg# 2)--在输出里换行,换行符是字符串本身的一部分:c='aaaaaaaaaaaaaaaaaaaaabbbbbbccc\nggggg'print(c)# aaaaaaaaaaaaaaaaaaaaabbbbbbccc# gggggi=Trueif\i==True:print('haha')
Spider--动态网页抓取--审查元素的更多相关文章
- python网络爬虫-动态网页抓取(五)
动态抓取的实例 在开始爬虫之前,我们需要了解一下Ajax(异步请求).它的价值在于在与后台进行少量的数据交换就可以使网页实现异步更新. 如果使用Ajax加载的动态网页抓取,有两种方法: 通过浏览器审查 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- 面向初学者的Python爬虫程序教程之动态网页抓取
目的是对所有注释进行爬网. 下面列出了已爬网链接.如果您使用AJAX加载动态网页,则有两种方式对其进行爬网. 分别介绍了两种方法:(如果对代码有任何疑问,请提出改进建议)解析真实地址爬网示例是参考链接 ...
- java+phantomjs实现动态网页抓取
1.下载地址:http://phantomjs.org/download.html 2.java代码 public void getHtml(String url) { HTML="&quo ...
- Spider_基础总结5--动态网页抓取--元素审查--json--字典
# 静态网页在浏览器中展示的内容都在HTML的源码中,但主流网页使用 Javascript时,很多内容不出现在HTML的源代码中,此时仍然使用 # requests+beautifulsoup是不能够 ...
- 动态网页爬取例子(WebCollector+selenium+phantomjs)
目标:动态网页爬取 说明:这里的动态网页指几种可能:1)需要用户交互,如常见的登录操作:2)网页通过JS / AJAX动态生成,如一个html里有<div id="test" ...
- Python爬虫之三种网页抓取方法性能比较
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块. 1. 正则表达式 如果你对正则表达式还不熟悉,或是需要一些提 ...
- 网页抓取小工具(IE法)
网页抓取小工具(IE法)—— 吴姐 http://club.excelhome.net/thread-1095707-1-1.html 用IE提取网页资料的好处在于:所见即所得,网页上能看到的信息一般 ...
- find_elements后点击不了抓取的元素
1.莫名其妙抓不到元素,要去看句柄,是不是没有切换 h=driver.current_window_handle nh=driver.window_handles for i in nh: if i! ...
随机推荐
- DM9000时序设置
想了解一下DM9000的移植修改原理,所以分析了一下时序图和引脚连接 首先看一下DM9000的引脚和MINI2440的引脚连接 DM9000 MINI2440 功能描述 SD0 DA ...
- 极简 Node.js 入门 - 5.2 url & querystring
极简 Node.js 入门系列教程:https://www.yuque.com/sunluyong/node 本文更佳阅读体验:https://www.yuque.com/sunluyong/node ...
- 【C/C++编程入门学习】同样是数据类型,链表对比数组?哪一个更香?
说起链表,第一反应:链表是一种数据类型!它可以用来存储同种类型多个批量数据. 有了这种认知,很容易去联想到数组,它也是一种数据类型,也可以用来存储同种类型的批量数据.初学者往往对数组的印象比较好, ...
- k8s 命令创建pod
[root@master kubernetes]# kubectl create deploy ngx-dep --image=nginx:1.14-alpine deployment.apps/ng ...
- python+selenium 爬取中国工业园网
import math import re import requests from lxml import etree type = "https://www.cnrepark.com/g ...
- 解释器( interpreter ) 与 编译器( compiler ) 的对比
什么是解释器与编译器 1.解释器 解释器是一种计算机程序,它将每个高级程序语句转换成机器代码. 2.编译器 把高级语言编写的程序转换成机器码,将人可读的代码转换成计算机可读的代码(0和1). 3.机器 ...
- MySQL历史
MySQL历史 马云生气了 去IOE活动 1979年 研发一个引擎 1996年 发布MySQL1.0 1999年 瑞典注册AB公司 2003年 MySQL 5.0版本 提供试图.存储过程 具有了一些企 ...
- Linux运维学习第三周记
日落狐狸眠冢上 夜归儿女笑灯前 人生有酒须当醉 一滴何曾到九泉 愿醉卧沙场可未有匹夫之勇. 第三周学记 第三周主要学习正则表达式和Shell编程 1.正则表达式基本字符 2.扩展正则表达式 3.gre ...
- Go 包管理历史以及 Go mod 使用
之前也写过 Go 管理依赖工具 godep 的使用,当时看 godep 使用起来还是挺方便,其原因主要在于有总比没有强.关于依赖管理工具其实还是想从头聊聊这个需求以及大家做这个功能的各种出发点. GO ...
- docker在win7下的使用
1,安装 win7下需要安装docker-toolbox,然后通过Docker Quickstart Terminal运行 2,加速 直接pull的话是拉取的docker hub上的镜像,速度非常慢, ...