GeoMesa,整体架构,创建Schema并导入数据
GeoMesa,整体架构,创建Schema并导入数据
一、GeoMesa-整体架构
GeoMea-utils提供了一些被广泛使用的工具类

主要模块的中文解释:
geomesa-accumulo:基于 Apache Accumulo的DataStore 实现
geomesa-archetypes: Maven构建模板
geomesa-arrow: 基于 Apache Arrow的DataStore 实现
geomesa-bigtable: 基于 Google BigTable的DataStore 实现
geomesa-blobstore: Accumulo-backed store designed for large files which have associated spatio-temporal data
geomesa-cassandra: 基于 Apache Cassandra的DataStore 实现
geomesa-convert: 实现arbitrary data 转换为 SimpleFeatures的工具库,支持自定义,可扩展
geomesa-features: SimpleFeatures的自定义实现与序列化工具
geomesa-filter: Library for manipulating and working with GeoTools Filters
geomesa-fs: 基于 Flat File的DataStore 实现
geomesa-geojson: 直接操作JSon数据的API and REST-ful web service接口
geomesa-hbase: 基于 Apache HBase的DataStore 实现
geomesa-index-api: 空间索引与DataStore的核心类库,最核心的类库,可以作为代码分析的入口。
geomesa-jobs: Map/reduce 集成
geomesa-jupyter: Jupyter notebook 集成
geomesa-kafka: DataStore 基于 Apache Kafka的DataStore 实现, 用于处理近实时流数据(near-real-time streaming data)
geomesa-lambda: 基于Lambda机构实现了Kafka与Accumulo无缝集成的DataStore实现,其中Kafka实时更新,Accumulo用于持久化存储
geomesa-memory: 内存中索引实现
geomesa-metrics: DropWizard metrics 集成
geomesa-native-api: Non-GeoTools API for persisting and querying data in Accumulo
geomesa-process: GeoMesa空间分析工具
geomesa-security: 用于安全与权限认证
geomesa-spark: Spark集成模块
geomesa-stream: DataStore implementation that reads features from arbitrary URLs
geomesa-test: 测试脚本
geomesa-tools: 用于数据导入、查询等操作的命令行工具类
geomesa-utils: 一般工具类
geomesa-web: 实现了REST-ful web services服务接口
geomesa-z3: Z3 空间填充曲线实现。
geomesa-zk-utils: Zookeeper工具代码
geomesa-index-core为最核心的模块,分析代码可以看到其主要包含两部分,空间索引GeoMesaFeatureIndex与数据库GeoMesaDataStore。空间索引主要是GeoMesa中定义的Z2/Z3,XZ2/XZ3的实现,用于将时空数据转换为可被列数据库存储一维键值形式。DataStore是基于Geotools数据接口(Geotools Data 模块)实现的用于数据访问的标准接口。
二、GeoMesa-创建Schema并导入数据
GeoMesa的定位其实是一个时空数据引擎,或者叫数据库中间件,目的在于使用户可以在分布式NoSQL数据库中存储和管理海量空间数据。
2.1 GeoTools Data 模块
GeoMesa的数据操作功能完全基于GeoTools 包中的类和接口进行构建。其中与数据操作有关的核心接口与类位于GeoTools Data模块中。GeoTools中进行矢量数据操作的最核心的接口是DataStore。DataStore接口继承了DataAccess<T,F>接口,T表示FeatureType, F代表Feature。
任何一个空间要素都可以用FeatureType与Feature来表示。
下图展示了接口之间的对应关系以及接口中定义的方法。一个DataStore可以理解为一个数据源,其中定义了所有与数据操作相关的方法,针对各种数据源(Shapefile,PostGIS,Oracle等)数据访问类都实现了DataStore接口。
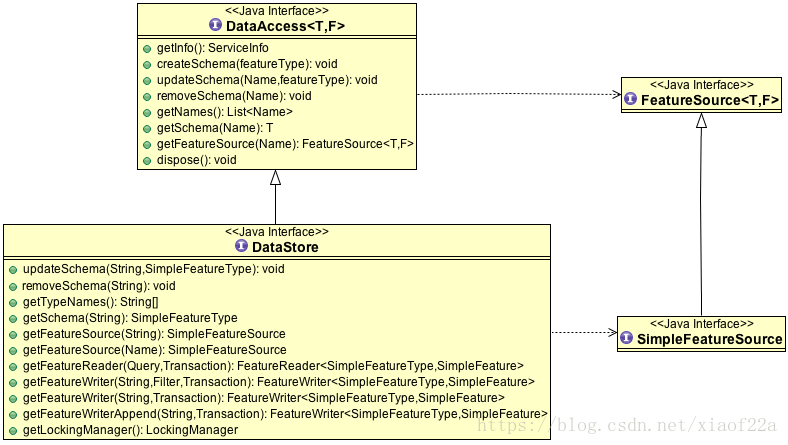
GeoMesa同样基于DataStore接口实现对空间数据的操作。然后大家可以在rg.locationtech.geomesa.index.geotools.GeoMesaDataStore类中找到具体实现。下图为GeoMesaDataStore所有接口信息,大家可以看到GeoMesaDataStore实现了DataStore中的方法
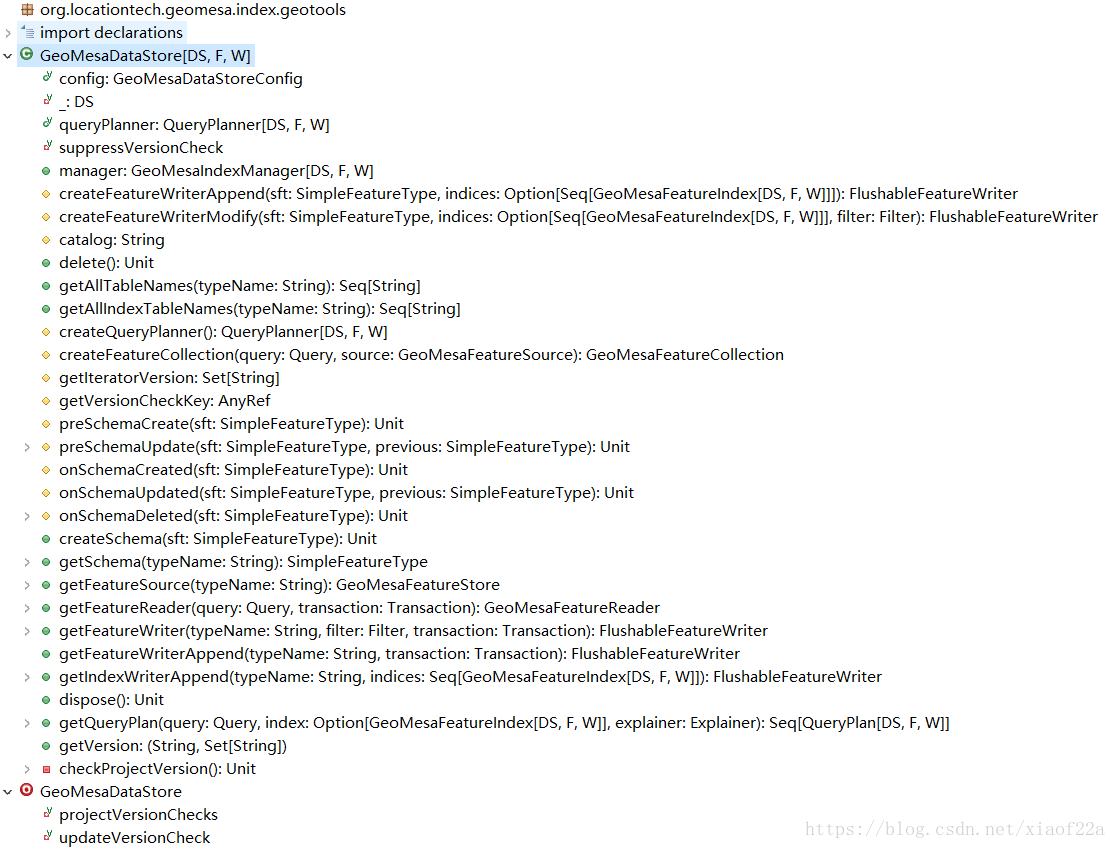
GeoMesaDataStore作为GeoMesa中所有数据源DataStore的基类,提供了一些业务流程基本实现,但具体到针对每种数据库的数据操作接口则由它的一些子类提供具体实现,如HbaseDataStore、CassandraDataStore等。
2.2 索引管理
GeoMesa最核心的部分就是索引系统。
GeoMesa提供了多种索引方法(z2/z3,xz2/zx3),这些索引方大统一在GeoMesaIndexManager类中管理,在GeoMesaDataStore中可以看到生成GeoMesaIndexManager的一个方法:
GeoMesaDataStore在进行数据表创建,数据导入,数据查询等操作都会通过GeoMesaIndexManager类获取空间索引,然后针对每一个空间要素都会生成一个索引值作为主键。

2.3 创建Schema
每一个矢量图层都对应一个schema,用于保存(空间参考,列属性)等元数据信息,DataStore接口中规定了createSchema方法,用于针对每一种数据库创建相应的schema信息,GeoMesaDataStore中createSchema方法的实现如下:
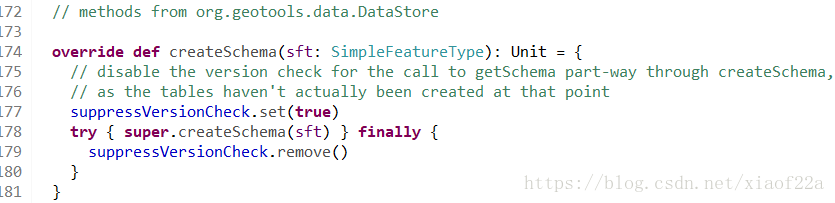
Schema指的就是与数据集有关的元数据信息(空间参考,列属性等)在数据库中的表示,比如OracledataStore中createSchema方法的作用是在数据库中创建一个表格专门用于保存空间数据的属性信息。createSchema方法会一些列辅助方法来创建读schema。

2.4 生成Writer
GeoTools中的数据导入功能是通过FeatureWriter接口实现的:
FeatureWriter接口定义了一系列方法来实现数据导入过程,如首先通过hasNext判断有没有要素,如果有则使用next获得要素,然后通过write方法将要素写入目标数据库。
对于写入要素通过getFeatureWriterAppend方法获得FeatureWriter,方法之间的引用关系如下图所示,GeoMesaDataStore通过抽象的createFeatureWriterAppend方法最终生成FeatureWriter对象的:
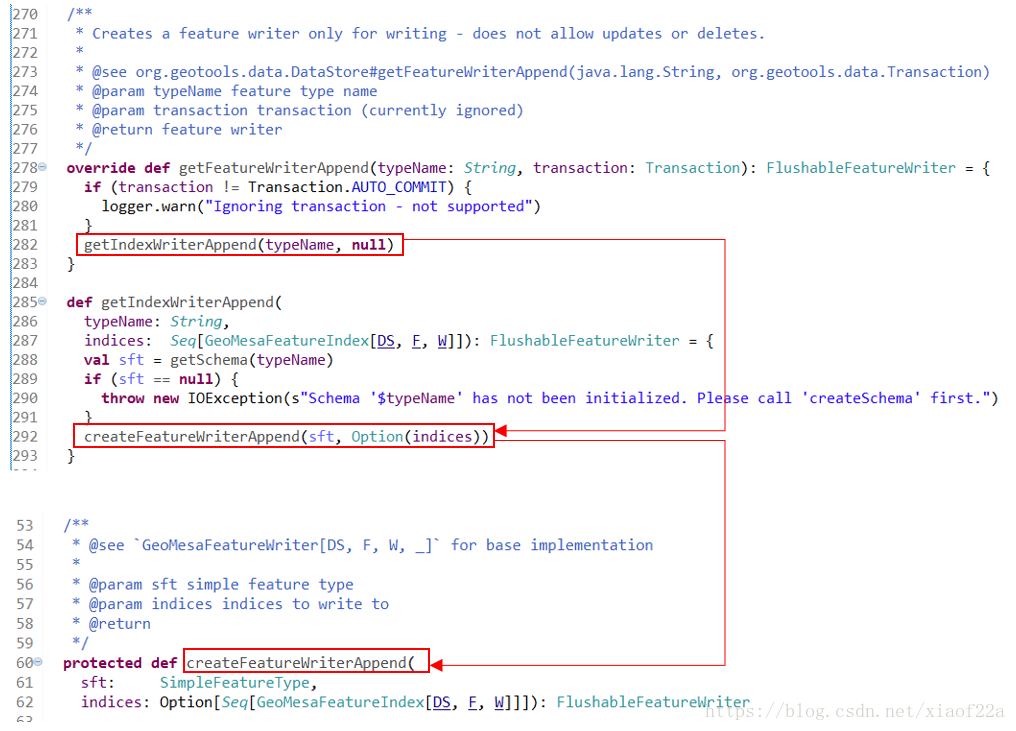
assandraDataStore和HBaseDataStore都提供个各自的createFeatureWriterAppend的实现:CassandraAppendFeatureWriter和HbaseAppendFeatureWriter,他们都继承了GeoMesaAppendFeatureWriter类。这里需要再强调一下,GeoMesaAppendFeatureWriter实现了org.geotools.data.FeatureWriter接口中的hasNext,next,write等方法,所以数据导入过程严格按照GeoTools定义的数据导入过程来执行。
如果要基于GeoMesa扩展对新的数据库支持,只需要对上面这几个方法进行重新,而把主要的业务逻辑交给GeoTools内部的基础类实现即可。来看一下GeoMesa-hbase的数据导入实现过程:
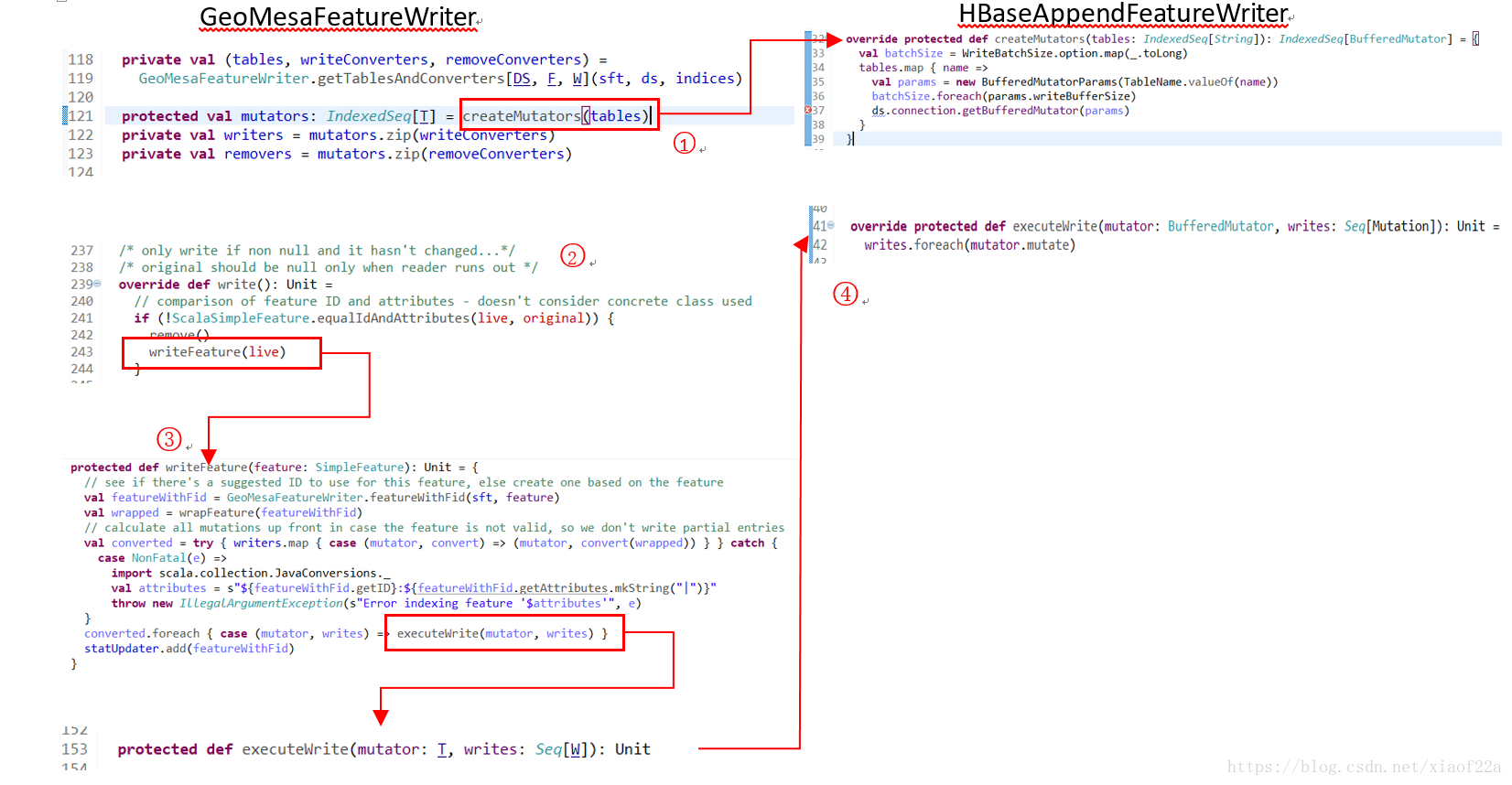
(1)GeoMesaFeatureWriter首先会调用createMutators方法,这个方法需要它的子类来实现,如右边HBaseAppendFeatureWriter中的实现。可以看到createMutator方法其实是获得了用于写入HBase的BufferedMutator类。org.apache.hadoop.hbase.client.BufferedMutator主要用来对HBase的单个表进行操作。它和Put类的作用差不多,但是主要用来实现批量的异步写操作。BufferedMutator替换了HTable的setAutoFlush(false)的作用。可以从Connection的实例中获取BufferedMutator的实例。在使用完成后需要调用close()方法关闭连接。对BufferedMutator进行配置需要通过BufferedMutatorParams完成。
(2)当数据写入类初始化完成之后,就可以调用write方法写入数据了,这里write方法调用了writeFeature方法。
(3)writeFeature继续调用了executeWrite方法(具体实现由子类提供)。这里笔者的理解是,mutator作为写入工具,writes就是等待写入的要素,covert的的作用就是对不同的索引表格进行转换,也就是生成对应的索引值,然后才能写入不同的索引表格中。
(4)子类中实现具体的写入流程
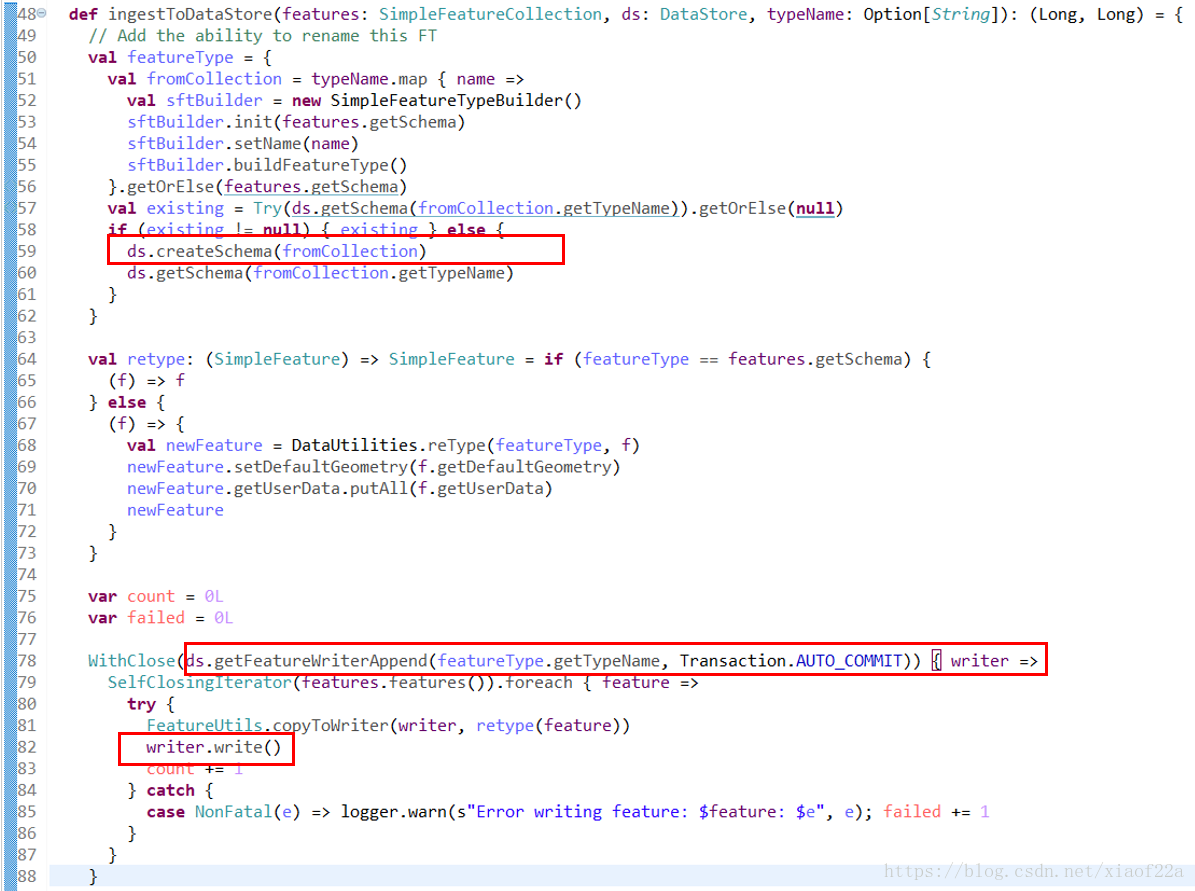
2.5 导入数据
GeoMesa自带的入库工具导入了shapefile文件,这个工具可以在org.locationtech.geomesa.tools.ingest.ShapefileIngest中找到,ShapefileIngest中使用了GeneralShapefileIngest中的方法进行入库操作:
作者:萧博士
原文:https://blog.csdn.net/xiaof22a/article/details/80303161
GeoMesa,整体架构,创建Schema并导入数据的更多相关文章
- mysql 批处理文件--- 创建 用户 以及 导入数据
在window下,通过批处理文件(.bat),进行开启MYSQL服务,导入数据文件(.sql) 1)新建一个txt文件,写入以下内容 rem 启动mysql56服务 mysql56是我的mysql服 ...
- [转]Visual Studio 2008中如何比较二个数据库的架构【Schema】和数据【Data】并同步
使用场景: 在团队开发中,每一个人都有可能随时更新数据库,这时候数据库中数据和架构等信息都会发生变化.如果更新不及时,就会发生数据错误或数据丢失的风险,影响团队的开发效率和 项目进度,这时候我们该怎么 ...
- hive 创建表和导入数据实例
//创建数据库create datebase hive;//创建表create table t_emp(id int,name string,age int,dept_name string,like ...
- Spring的整体架构的认识
Spring的整体架构的认识 一).spring是用来做什么的? spirng使用基本的JavaBean来完成以前EJB所完成的事. 二).EJB EJB: Enterprise JavaBean, ...
- 一起学Hive——详解四种导入数据的方式
在使用Hive的过程中,导入数据是必不可少的步骤,不同的数据导入方式效率也不一样,本文总结Hive四种不同的数据导入方式: 从本地文件系统导入数据 从HDFS中导入数据 从其他的Hive表中导入数据 ...
- hive 导入数据
1.load data load data local inpath "/home/hadoop/userinfo.txt" into table userinfo; " ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- solr7.4创建core,导入MySQL数据,中文分词
#solr版本:7.4.0 一.新建Core 进入安装目录下得server/solr/,创建一个文件夹,如:new_core 拷贝server/solr/configsets/_default/con ...
随机推荐
- 分布式零基础之--分布式CAP理论
研究到分布式系统CAP理论,记录下来下回详细分析它: CAP是指三个单词的简称 C: 一致性(Consistence) 所有节点访问的都是同一份最新的数据副本. A: 可用性(Availability ...
- TCP实现网络通讯
Tcp server的流程:1.创建套接字:2.bind绑定ip和port3.listen使套接字变为可以被动链接:4.accept等待客户端的链接(返回为服务器分配的客户端的句柄和地址)5.reci ...
- Hive数据导入Hbase
方案一:Hive关联HBase表方式 适用场景:数据量不大4T以下(走hbase的api导入数据) 一.hbase表不存在的情况 创建hive表hive_hbase_table映射hbase表hbas ...
- 风炫安全web安全学习第三十四节课 文件包含漏洞防御
风炫安全web安全学习第三十四节课 文件包含漏洞防御 文件包含防御 在功能设计上不要把文件包含的对应文件放到前台去操作 过滤各种../,https://, http:// 配置php.ini文件 al ...
- 并发编程--锁--volatile
在讲volatile关键字之前我们先了解Java的内存模型,Java内存模型规定所有的变量都是存在主存当中,每个线程都有自己的工作内存.线程对变量的所有操作都必须在自己的工作内存中进行,而不能直接对主 ...
- Dota游戏匹配的所有组合
在Dota游戏中有一种匹配玩法,任意5人以下玩家组队,加入匹配系统,由系统组合出5人 vs 5人的组合进行游戏,比如2人+3人 vs 1人+4人.抽象出这个问题,就变成两边各有m个玩家,最多允许n个 ...
- 【Spring】Spring JdbcTemplate
Spring JdbcTemplate 文章源码 JdbcTemplate 概述 它是 Spring 框架中提供的一个对象,是对原始 Jdbc API 对象的简单封装.Spring 框架提供了很多的操 ...
- zabbix_agent items not supported状态
不记得自己究竟更改了什么东西,然后突然发现所有的有关mysql的监控items都变成了not supported,怎么做不行,最后在web主页把主机删除,又重新添加一下,重新添加了一下模版就好了.这究 ...
- P1140 相似基因(字符串距离,递推)
题目链接: https://www.luogu.org/problemnew/show/P1140 题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了44种核苷酸,简记作A,C,G,TA,C, ...
- three.js cannon.js物理引擎之约束
今天郭先生继续说cannon.js,主演内容就是点对点约束和2D坐标转3D坐标.仍然以一个案例为例,场景由一个地面.若干网格组成的约束体和一些拥有初速度的球体组成,如下图.线案例请点击博客原文. 下面 ...