Redis集群数据没法拆分时的搭建策略
在上一篇文章中,针对服务器单点、单例、单机存在的问题:
- 单点故障
- 容量有限
- 可支持的连接有限(性能不足)
提出了解决的办法:根据AKF原则搭建集群,大意是先X轴拆分,创建单机的镜像,组成主主、主备、主从模型,然后Y轴拆分,根据业务将不同的访问分配在不同的业务Redis上,对于同一业务的Redis,如果还不足以支撑并发访问,那么可以继续Z轴拆分,也就是根据数据拆分,详细情况参照:Redis集群拆分原则之AKF
结合上面提出一个新问题,如果一个服务,业务数据没法拆分,或者说不容易拆分呢?也就是没办法沿着Y-Z轴拆解,那么如何集群呢?
解决思路:
一致性Hash
哈希槽
一致性Hash
说到一致性Hash,就得先搞明白为什么要有一致性Hash,介绍一致性Hash算法之前,先简单回顾一下分布式以及Hash算法,便于理解为什么要有一致性Hash算法。
分布式
当我们也无需求很复杂时,单台机器IO以及带宽等都会成为瓶颈,所以对业务进行拆分,部署在不同的机器上,当有请求访问时,根据某些特点将这些请求分散到各个服务器上,这所有的服务器组成的网络,我们称之为集群,这能提高服务器的性能以及利用率。
如果有一个请求过来存数据,调度器将数据存在了A服务器上,下次客户端再来请求这份数据,该如何迅速判断数据存在哪台服务器呢?这时候引出了哈希的概念。
哈希函数
对于一个函数:
\]
如果两个哈希值是不相同的,那么这两个哈希值的原始输入也是不相同的。这个特性是哈希函数具有确定性的结果,具有这种性质的哈希函数称为单向哈希函数。
但另一方面,哈希函数的输入和输出不是唯一对应关系的,如果两个哈希值相同,两个输入值很可能是相同的,但也可能不同,如果值相同称为“哈希碰撞(collision)”,这通常是两个不同长度的输入值,刻意计算出相同的输出值。输入一些数据计算出哈希值,然后部分改变输入值,一个具有强混淆特性的哈希函数会产生一个完全不同的哈希值。哈希函数是不可逆的,也就是没法根据哈希值来反推输入值。
那么对于集群而言,每一个请求都有一个标识ID,如果构造标识到服务器的哈希函数,就可以让同一请求固定的达到服务器,因为ID是不变的:
\]
为了均匀分布在不同的服务器上,这是一个跟服务器数量N有关的哈希函数,常见的有取模运算,即:
\]
但是这时候有个问题,由于是集群,那么服务器数量可能会有变化,例如今天请求量非常大要增加服务器数量,N变大之后,原有的Hash值就失效了,需要重新对存储的请求值做哈希,由于请求值是一个庞大的数据集.这样造成了巨大的不便,需要改进我们的Hash算法。这时候引出了一致性Hash的思路。
一致性Hash
一致性哈希的思路是,将哈希函数与服务器数量解绑,如果我们用16个二进制标识哈希值,那么哈希值有一个范围区间\([0,65536]\),我们将这个区间65536平均分成N份,N是服务器数量,然后将这些服务器节点等距离安排在一个圆环上
假设服务器数量是4,那么对于所有请求,哈希值必定是介于\([0,65536]\)之间,当节点计算哈希后对应环上某一个点,这时候顺时针寻找离自己最近的服务节点作为存储节点,例如:当请求哈希值介于\([0,16384]\)之间时,将请求分配到Server 1,如果请求哈希值介于\((16384,32768]\)之间时,将请求分配到Server 2,后面同理,这样做有一个什么好处呢,如果这时候需要新增加一个服务器,假设是Server 5:

那么需要重新计算Hash值的仅仅为\([0,8192]\)这部分请求,将其分配到Server 5上。

这地方有两点要注意,很多博客都没有提到:
一是原有节点信息本应该归server 2 存储,新增加了Server 5 之后根据新的规则会映射到Server 5上,那么之前存储在Server 1 上的数据需要重新取出来放在Server 5 上吗?
答案是否定的,只需要查找数据,在最近的点没找到,往下(顺时针)再查找一个点就行了,也可以再查找两个点(防止插入了两台新的服务节点)
二是,删除某个服务器节点
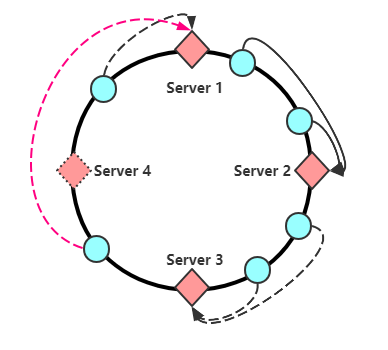
如图,删除服务器Server 4 之后,会将原有分布在Server4 上的请求全都压在Server1上,如果Server1 hold不住,那么可能挂掉,挂掉之后数据又转移给Server2,如此循环会造成所有节点崩溃,也就是雪崩的情况。这种雪崩可以靠下面的虚拟节点引入解决
虚拟节点的引入
我们已经知道,添加和删除节点都会影响缓存数据的分布。尽管hash算法具有分布均匀的特性,但是当集群中server数量很少时,他们可能在环中的分布并不是特别均匀,进而导致缓存数据不能均匀分布到所有的server上,例如都分配在某一个或几个哈希区间,那么有很多服务器可能就没在这个分布式系统中提供作用。
为解决这个问题,需要使用虚拟节点, 虚拟节点的思想:为每个物理节点(server)在环上分配100~200个点,这样环上的节点较多,就能抑制分布不均匀。当为cache定位目标server时,如果定位到虚拟节点上,就表示cache真正的存储位置是在该虚拟节点代表的实际物理server上。另外,如果每个实际server节点的负载能力不同,可以赋予不同的权重,根据权重分配不同数量的虚拟节点。定位算法不变,只是多了一步虚拟节点到真实节点映射的过程
为什么说这样能解决雪崩的发生呢,因为即使一台服务器挂了,他应对的虚拟节点也会消失,那也就是新来的数据依旧可在原区间内随机或者根据某种规律分配到其他节点上。
注意:真实节点不放置到哈希环上,只有虚拟节点才会放上去。
另外没法做数据库用(待补充)
哈希槽
了解哈希槽前景知识还是普通哈希,前面讲了哈希存在的问题是,当服务节点变化时,假如是增加到N+1,要对所有数据重新对服务器数量N+1取模,这在分布式中是难以接受的,太浪费时间。
那么,可不可以先假设我将来会有很多机器,例如一万台,对一万台取模,然后构建映射将取模值(哈希值)分区呢?Redis 集群的哈希槽就是这种思路:
用我们的Key值,对12取模,那么范围是在\([0,11]\)之间,这儿的\([0,11]\)就是我们所说的槽值,然后将这个范围区间切割成N份,N为服务器数量,如图:

之后如果新增了Redis服务器,只需要将映射的槽值对应的数据移动去新服务器就行了:
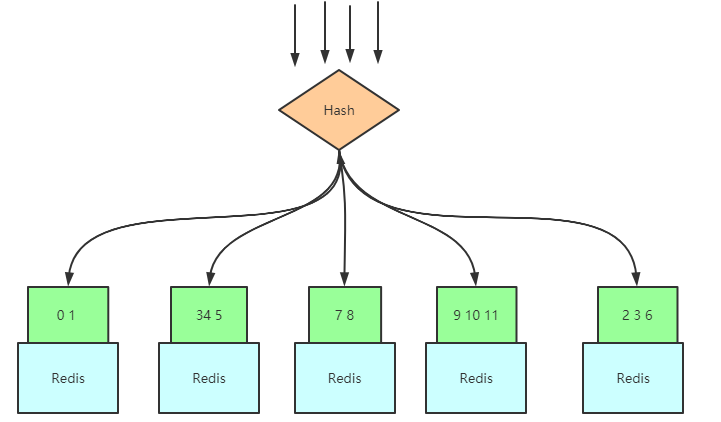
基于哈希槽的cluster集群
当客户端来获取数据时,随便连接到哪一个服务器上,服务器内置上面说的Hash算法,对请求Id进行Hash得到哈希值,每一个服务器内置一个表,这个表将哈希值对应的哈希槽与数据存储服务节点做一个映射,也就是请求压到任一台服务器,有数据的话会返回数据,没有的话会返回存储所需数据的服务器节点位置:

哈希槽与一致性哈希区别
它并不是闭合的,key的定位规则是根据CRC-16(key)%16384的值来判断属于哪个槽区,从而判断该key属于哪个节点,而一致性哈希是根据hash(key)的值来顺时针找第一个hash(ip)的节点,从而确定key存储在哪个节点。
一致性哈希是创建虚拟节点来实现节点宕机后的数据转移并保证数据的安全性和集群的可用性的。redis cluster是采用master节点有多个slave节点机制来保证数据的完整性的,master节点写入数据,slave节点同步数据。当master节点挂机后,slave节点会通过选举机制选举出一个节点变成master节点,实现高可用。但是这里有一点需要考虑,如果master节点存在热点缓存,某一个时刻某个key的访问急剧增高,这时该mater节点可能操劳过度而死,随后从节点选举为主节点后,同样宕机,一次类推,造成缓存雪崩。
Redis集群数据没法拆分时的搭建策略的更多相关文章
- redis集群数据迁移
redis集群数据备份迁移方案 n 迁移环境描述及分析 当前我们面临的数据迁移环境是:集群->集群. 源集群: 源集群为6节点,3主3备 主 备 192.168.112.33:8001 192 ...
- 用C、python手写redis客户端,兼容redis集群 (-MOVED和-ASK),快速搭建redis集群
想没想过,自己写一个redis客户端,是不是很难呢? 其实,并不是特别难. 首先,要知道redis服务端用的通信协议,建议直接去官网看,博客啥的其实也是从官网摘抄的,或者从其他博客抄的(忽略). 协议 ...
- redis集群数据迁移txt版
./redis-trib.rb create --replicas 1 192.168.112.33:8001 192.168.112.33:8002 192.168.112.33:8003 192. ...
- Redis集群方案之使用豌豆荚Codis搭建(待实践)
Codis的模式类似Twemproxy,不过这东西引入了ZooKeeper做为Redis的注册与发现来实现高可用. 部署时需要额外增加应用的部署,请根据业务需求来衡量. 部署图类似如下: 当然,上面的 ...
- 用redis-dump工具对redis集群所有数据进行导出导入
安装redis-dump redis-dump是基于ruby开发,需要ruby环境,而且新版本的redis-dump要求2.2.2以上的ruby版本,centos中yum只能安装2.0版本的ruby. ...
- Linux 下redis 集群搭建练习
Redis集群 学习参考:https://blog.csdn.net/jeffleo/article/details/54848428https://my.oschina.net/iyinghui/b ...
- [个人翻译]Redis 集群教程(上)
官方原文地址:https://redis.io/topics/cluster-tutorial 水平有限,如果您在阅读过程中发现有翻译的不合理的地方,请留言,我会尽快修改,谢谢. 这是 ...
- Redis集群搭建1
wget .168.0.201:6379 192.168.0.201:6380 192.168.0.201:6381 192.168.0.202:16379 192.168.0.202:16380 1 ...
- Redis集群教程(Redis cluster tutorial)
本博文翻译自Redis官网:http://redis.io/topics/cluster-tutorial 本文档以温和的方式介绍Redis集群,不使用复杂的方式来理解分布式系统的概念. ...
随机推荐
- 【Linux】中默认文本编辑器 vim 的入门与进阶
Linux 基本操作 vim 篇 vim 简介 vim 是 Linux 上最基本的文本编辑工具,其地位像是 Windows 自带的记事本工具,还要少数的 Linux 系统自带 leafpad 编辑器, ...
- .net通过iTextSharp.pdf操作pdf文件实现查找关键字签字盖章
之前这个事情都CA公司去做的,现在给客户做demo,要模拟一下签字盖章了,我们的业务PDF文件是动态生成的所以没法通过坐标定位,只能通过关键字查找定位了. 之前在网上看了许多通多通过查询关键字,然后图 ...
- ES6+Webpack+Babel基本环境搭建
### 本文基本是流水文,记录学习中步骤,希望对看到的你有用,蟹蟹. 基本环境搭建 技术栈 Webpack ES6 Babel 开发环境 VS Code Node 搭建环境过程 新建项目文件夹
- r5 5600H 怎么样 相当于什么水平
Ryzen 5 5600H是基于Zen 3架构的6核12线程处理器.它具有3.30 GHz的默认频率和4.25GHz的加速频率,带有16MB的L3缓存和3 MB的L2缓存,显卡部分,AMD搭配的Veg ...
- #2020征文-开发板# 用鸿蒙开发AI应用(二)系统篇
目录: 前言 安装虚拟机 安装 Ubuntu 设置共享文件夹 前言上回说到,我们在一块 HarmonyOS HiSpark AI Camera 开发板,并将其硬件做了一下解读和组装.要在其上编译鸿蒙系 ...
- oracle 19C 静默安装(单机版)
一.前期环境准备 1.硬件信息 (1)主机版本 [root@localhost ~]# cat /etc/redhat-release Red Hat Enterprise Linux Server ...
- Django中一种常见的setting与账密保存/读取方式
前言 在查看别人Django代码的时候,发现很多的manager文件都是类似于 #!/usr/bin/env python import os import sys if __name__ == '_ ...
- VRay for SketchUp渲染图黑原因及解决方案
很多人都遇到用Vray for SketchUp云渲染的时候,渲染出来的图片是全黑或者是局部是黑色, 这是什么原因呢? 1.有一种情况是,SketchUp的文件储存机制和其他的软件有些不同,它是把模型 ...
- selenium自动化 | 借助百度AI开放平台识别验证码登录职教云
#通过借助百度AI开放平台识别验证码登录职教云 from PIL import Image from aip import AipOcr import unittest # driver.get(zj ...
- Springboot之文件监控
背景:在实际环境部署构成中,由于特殊网络环境因素,有很多服务器之间的网络都是单向的,不能互相访问的,只有通过特定技术手段做到文件的单项摆渡,这就需要在两台服务器上分别写序列化程序和反序列化程序,这里不 ...