大话Spark(5)-三图详述Spark Standalone/Client/Cluster运行模式
之前在 大话Spark(2)里讲过Spark Yarn-Client的运行模式,有同学反馈与Cluster模式没有对比, 这里我重新整理了三张图分别看下Standalone,Yarn-Client 和 Yarn-Cluster的运行流程。
1、独立(Standalone)运行模式
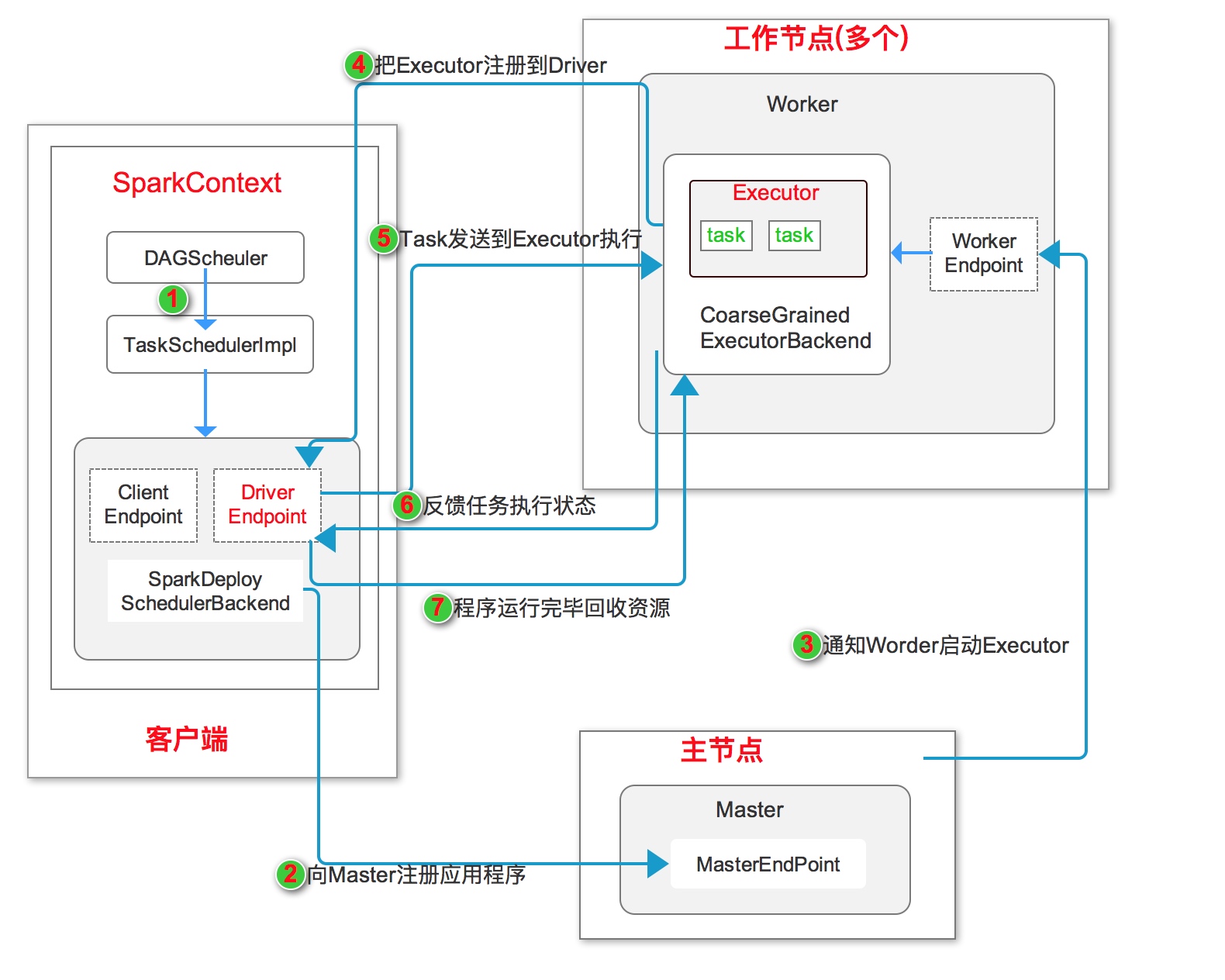 

独立运行模式是Spark自身实现的资源调度框架,由客户端、Master节点和多个Worker节点组成。其中SparkContext既可以运行在Master节点上,也可以运行在客户端。
Worker节点可以通过ExecutorRunner运行在当前节点上的CoarseGrainedExecutorBackend进程,每个Worker节点上存在一个或多个CoarseGrainedExecutorBackend进程,每个进程包含一个Executor对象。 该对象持有一个线程池,每个线程可以执行一个task。
如上图独立模式运行流程图所示:
- 启动应用程序,在SparkContext启动过程中,先初始化DAGScheduler 和 TaskSchedulerImpl两个调度器, 同时初始化SparkDeploySchedulerBackend,并在其内部启动DriverEndpoint 和 ClientEndpoint
- ClientEndpoint向Master注册应用程序。Master收到注册消息后把应用放到待运行应用列表,使用自己的
资源调度算法分配Worker资源给应用程序。 - 应用程序获得Worker时,Master会通知Worker中的WorkerEndpoint创建CoarseGrainedExecutorBackend进程,在该进程中创建执行容器Executor。
- Executor创建完毕后发送消息到Master 和 DriverEndpoint。在SparkContext创建成功后, 等待Driver端发过来的任务。
- SparkContext分配任务给CoarseGrainedExecutorBackend执行,在Executor上按照一定调度执行任务(这些任务就是自己写的代码)
- CoarseGrainedExecutorBackend在处理任务的过程中把任务状态发送给SparkContext,SparkContext根据任务不同的结果进行处理。如果任务集处理完毕后,则继续发送其他任务集。
- 应用程序运行完成后,SparkContext会进行资源回收。
补充
- SparkContext对任务的划分:每个Action操作都会触发一个job,job给到DAGScheduler,DAGScheduler把job划分成多个Stage(
Stage划分算法),每个Stage创建一个Taskset, TaskSet提交给TaskScheduler,把这些task分配到之前注册来的executor上。 - task的类型分为ShuffleMapTask 和 ResultTask, 只有最后一个task是ResultTask。每一个task针对rdd的一个partition并行执行, 一个stage的task会连续执行一个后续算子。
2、Yarn-Client运行模式
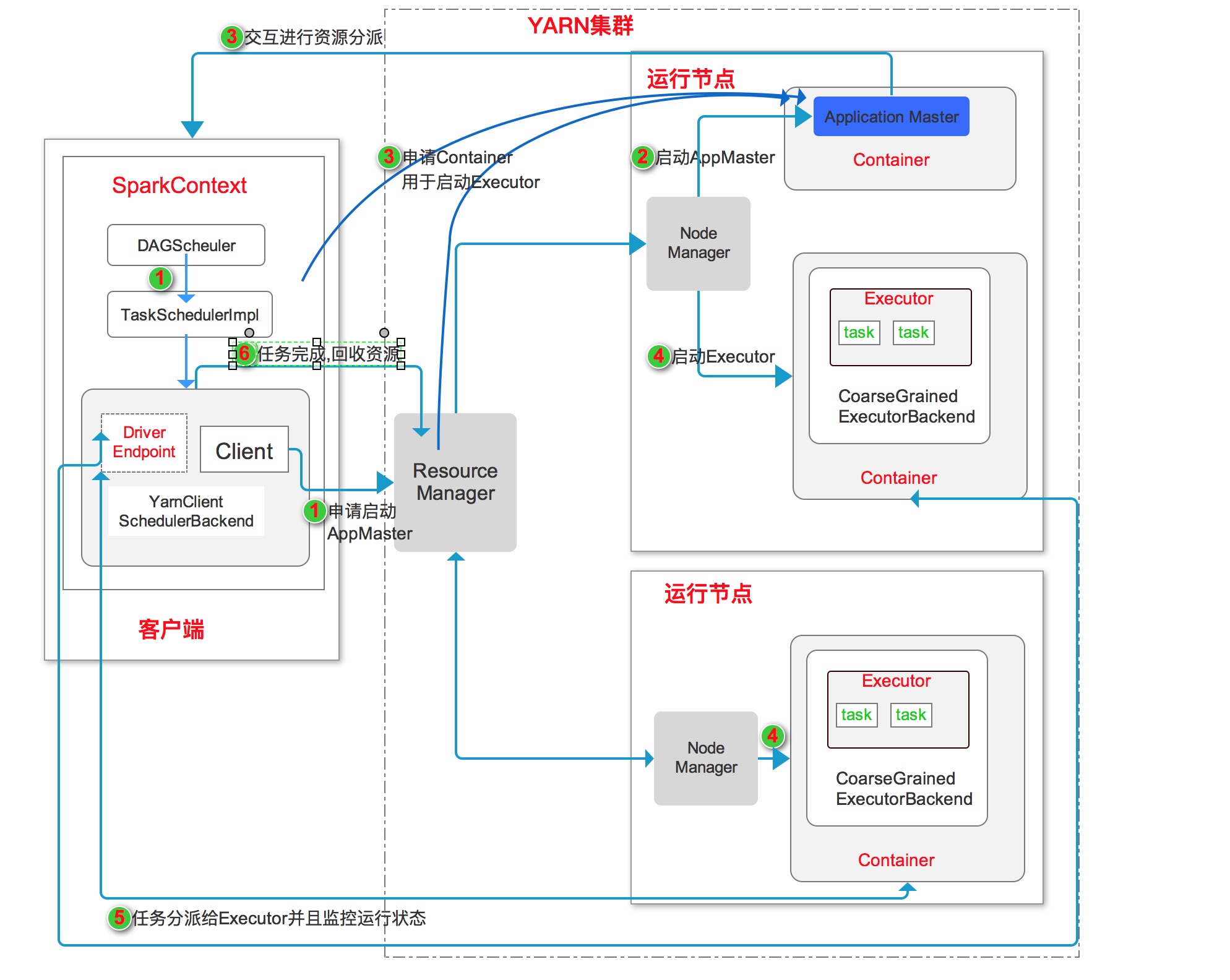 

Yarn-Client工作流程如上图所示:
- 启动应用程序,在SparkContext启动过程中, 初始化DAGScheduler调度器,使用反射方法初始化YarnScheduler 和 YarnClientSchedulerBackend。YarnClientSchedulerBackend内部启动DriverEndpoint 和 Client。Client向Yarn集群的ResourceManager申请启动Application Master。
- ResourceManager收到请求后,在集群中选一个NodeManger,为此应用申请一个Container, 并在其中启动Application Master。前面讲过,Client模式中的ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的派分。
- SparkContext启动完毕后,与Application Master通信,向Resource Manager注册, 根据任务信息申请Container资源。
- Application Master申请到资源后,与NodeManager通信,在Container中启动YarnClientSchedulerBackend,YarnClientSchedulerBackend向客户端中的SparkContext注册并申请taskset。
- SparkContext和运行中的任务保持通信,获取任务的状态和进度,随时掌握各个任务的运行状况,可以在任务失败时重启任务。
- 应用程序运行完成后,SparkContext向ResourceManager申请注销并关闭自己。
3、Yarn-Cluster运行模式
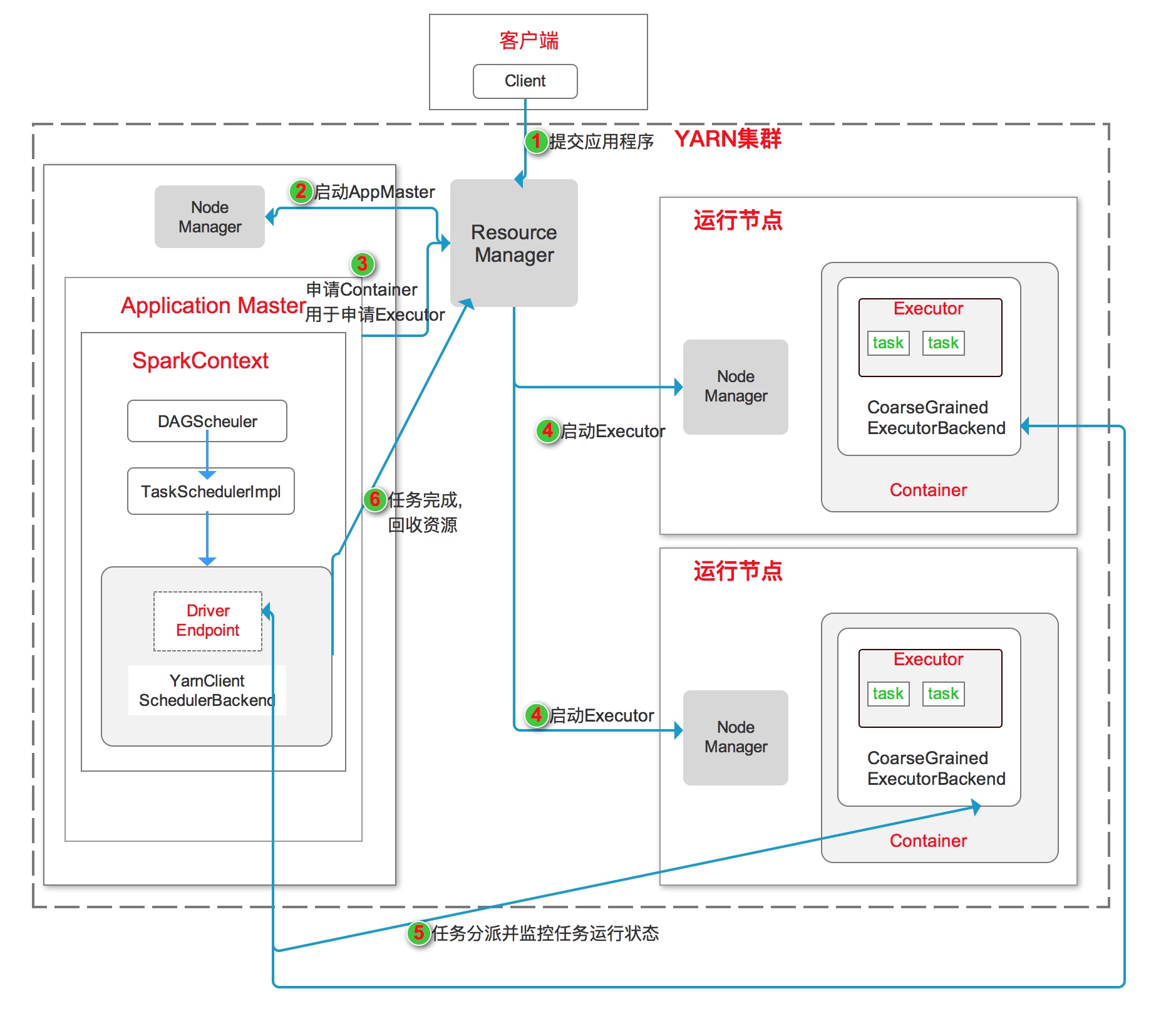 

Yarn-Cluster工作流程如上图所示:
- 客户端启动Client项YARN集群提交应用程序。
- ResourceManager收到请求后,再集群中选一个NodeManger,为此应用申请一个Container, 并在其中启动Application Master。在Application Master中进行SparkContext的初始化操作
- Application Master向ResourceManager注册,为各个任务申请资源,并监控任务的运行状态直到结束
- Application Master申请到资源后,与NodeManager通信,在Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend向客户端中的SparkContext注册并申请taskset。
- CoarseGrainedExecutorBackend运行任务并向Application Master汇报运行的状态和进度.
- 应用程序运行完成后,SparkContext向ResourceManager申请注销并关闭。
小结
Spark虽然有多种运行模式,但是其运行架构基本上由三部分组成,
- SparkContext
- ClusterManager(集群资源管理器)
- Executor(任务执行进程)
SparkContext用于负责与ClusterManager通信,进行资源的申请、任务的分配和监控等,负责作业执行的全生命周期管理。
ClusterManager提供了资源的分配和管理,不同模式下角色有所不同。Standalone模式下由Master提供,Yarn模式下由ResourceManager担任。
原文链接:
大话Spark(5)-三图详述Spark Standalone/Client/Cluster运行模式
大话Spark(5)-三图详述Spark Standalone/Client/Cluster运行模式的更多相关文章
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- Tomcat 的三种(bio,nio.apr) 高级 Connector 运行模式及apr配置
转: http://www.oschina.net/question/54100_16195omcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或者启动日志. ...
- Spark 学习(三) maven 编译spark 源码
spark 源码编译 scala 版本2.11.4 os:ubuntu 14.04 64位 memery 3G spark :1.1.0 下载源码后解压 1 准备环境,安装jdk和scala,具体参考 ...
- Spark思维导图之Spark SQL
- Spark思维导图之Spark Streaming
- Spark思维导图之Spark RDD
- Spark思维导图之Spark Core
- 【转】Tomcat 的三种(bio,nio.apr) 高级 Connector 运行模式
转载地址:http://www.oschina.net/question/54100_16195 tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或 ...
- Tomcat 的三种(bio,nio.apr) 高级 Connector 运行模式
tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或者启动日志.或者登录他们的默认页面http://localhost:8080/查看其中的服务器状态. ...
随机推荐
- 【bzoj 2163】复杂的大门(算法效率--拆点+贪心)
题目:你去找某bm玩,到了门口才发现要打开他家的大门不是一件容易的事-- 他家的大门外有n个站台,用1到n的正整数编号.你需要对每个站台访问一定次数以后大门才能开启.站台之间有m个单向的传送门,通过传 ...
- 【2020杭电多校】 Lead of Wisdom、The Oculus
题目链接:Lead of Wisdom 题意:有n个物品,这些物品有k种类型.每种物品有对应的类型ti,其他值ai,bi,ci,di 你可以选择一些物品,但是这些物品要保证它们任意两者之间类型不能相同 ...
- xml——dom&sax解析、DTD&schema约束
dom解析实例: 优点:增删改查一些元素等东西方便 缺点:内存消耗太大,如果文档太大,可能会导致内存溢出 sax解析: 优点:内存压力小 缺点:增删改比较复杂 当我们运行的java程序需要的内存比较大 ...
- Educational Codeforces Round 94 (Rated for Div. 2) A. String Similarity (构造水题)
题意:给你一个长度为\(2*n-1\)的字符串\(s\),让你构造一个长度为\(n\)的字符串,使得构造的字符串中有相同位置的字符等于\(s[1..n],s[2..n+1],...,s[n,2n-1] ...
- tkinter 实现爬虫的UI界面
使用python的内置模块tkinter编写了爬取51Ape网站(无损音乐的百度云链接)的UI界面 tkinter入门简单, 但同时在编写的过程中因为文档的缺少很不方便. 下面是UI界面模块的编写,由 ...
- sort排序使用以及lower_bound( )和upper_bound( )
sort()原型: sort(first_pointer,first_pointer+n,cmp) 排序区间是[first_pointer,first_pointer+n) 左闭右开 参数1 ...
- Zabbix 监控项更多用法
监控服务端口状态 配置 Zabbix 提供的检测器 配置自定义值映射 查看监控项数据状态 触发器配置 自定义监控项 TCP 11 种状态 TCP 11 种状态 LISTEN - 侦听来自远方TCP端口 ...
- leetcode 周赛 205 1576-5508-5509-5510
第四题比较难,看题解用并查集做比较简单,但是我觉得难度在想到用并查集,可能是最近做题少所以想不到吧. 1 替换所有的问号 class Solution { public: string modifyS ...
- 对于kmp求next数组的理解
首先附上代码 1 void GetNext(char* p,int next[]) 2 { 3 int pLen = strlen(p); 4 next[0] = -1; 5 int k = -1; ...
- Adobe DreamWeaver CC 快捷键
1 1 ADOBE DREAMWEAVER CC Shortcuts: DREAMWEAVER CC DOCUMENT EDITING SHORTCUTS Select Dreamweaver > ...