预训练模型——开创NLP新纪元
预训练模型——开创NLP新纪元
论文贡献

对如今自然语言处理研究中常用的预训练模型进行了全面的概述,包括背景知识、模型架构、预训练任务、预训练模型的各种扩展、预训练模型的适应方法、预训练模型相关资源和应用。
基于现有的对预训练模型分类方法,从四个不同的角度提出了一个新的分类方法,它从四个不同的角度对现有的原型系统进行分类:
- 表示类型
- 模型结构
- 预训练任务的类型
- 特定类型场景的扩展
收集了大量的预训练模型的资源,包括预训练模型的开源实现、可视化工具、语料库和论文列表
针对预训练模型,提出了几个可能的未来研究方向。
背景
语言表示学习
一个好的语言嵌入表示应该能够蕴含文本语料中隐含的语言规则和常识信息,例如词汇的含义、句法结构、语义角色、语用学等信息。分布式表示的核心在于用低维实值向量来描述一段文本的含义,该向量的每个维度上的值都没有对应的意义,但是向量整体代表了一个具体的概念。
与上下文无关的嵌入
将离散的语言符号映射到分布式嵌入空间中,具体来说,对于词汇表 \(\text{V}\) 中每个单词 \(x\) ,将其映射成一个 \(d\) 维的实值向量,由此得到一个由词汇表中全部单词的嵌入向量作为列向量的嵌入矩阵 \(\text{E}^{d × |\text{V}|}\),矩阵的列数就是词汇表 \(\text{V}\) 中单词的总数 \(|\text{V}|\),矩阵的行数就是嵌入向量的维度 \(d\)。因此,单词 \(x\) 的嵌入向量 \(e_{x}\) 也可以由其唯一的独热编码 \(h_{x}\)乘上嵌入矩阵得到,即
\]
问题
- 嵌入是静态的,即单词的嵌入与上下文无关。然而当遇到多义词时,不跟据上下文语境的话,无法判断其真实代表的含义。
- 词汇量不足。采用字符或者单词的子词作为基本表示单位。例如CharCNN、FastText和Byte-Pair Encoding等表示方法。
语境嵌入
为了解决与上下文无关嵌入存在的问题,需要区分单词在不同语境下代表的语义。
利用不同的神经上下文编码器 \(f_{\mathrm{enc}} \left(·\right)\) 对与上下文无关的嵌入 \(x_{t}\) 进行编码,得到蕴含上下文信息的语境嵌入 \(h_{t}\)。
\]
下图是展示了利用神经编码器对上下文无关嵌入向量进行编码后得到语境嵌入,然后将其用于下游的面向具体任务的模型。
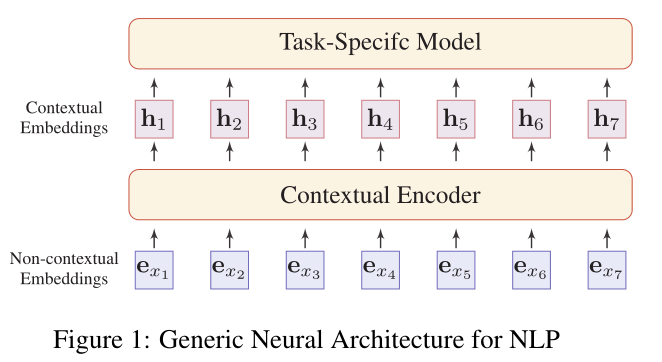
神经上下文编码器
大多数神经上下文编码器可以归结为两类:
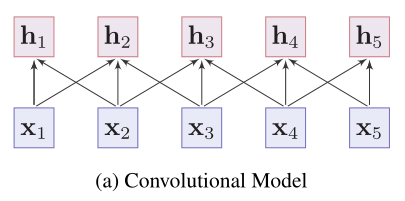
序列模型 —— 按照顺序捕捉单词的局部上下文信息
- 卷积模型 —— 将输入句子中单词的嵌入作为输入,通过卷积运算聚集某个单词来自其邻居的局部信息来获取该单词的含义
- 递归模型 —— 递归模型捕捉短记忆单词的上下文表示,如LSTMs 和GRUs。从一个词的两边收集信息,但递归模型的性能往往受到长句子语义依赖问题的影响。
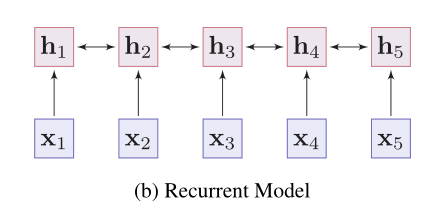
- 优点
- 易于训练
- 对于各种自然语言处理任务能获得良好的结果
- 缺点
- 学到的单词的上下文表示具有局部性偏差
- 难以捕捉单词之间的长期交互
非序列模型 —— 非序列模型通过预先定义的单词之间的树或图结构来学习上下文表示,例如句法结构或语义关系。经典的模型包括Recursive NN、TreeLSTM和图卷积网络GCN。
图模型存在的问题
- 如何建立一个好的图结构也是一个具有挑战性的问题
- 图结构严重依赖于专家知识或外部NLP工具。
全连接自注意力模型
- 为所有单词嵌入建立全连接图,让模型自行学习关系结构。
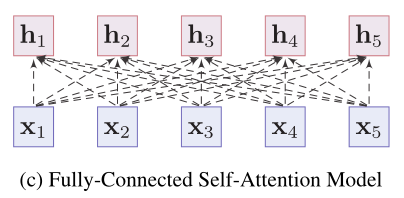
- 连接权重由自注意力机制动态计算得到
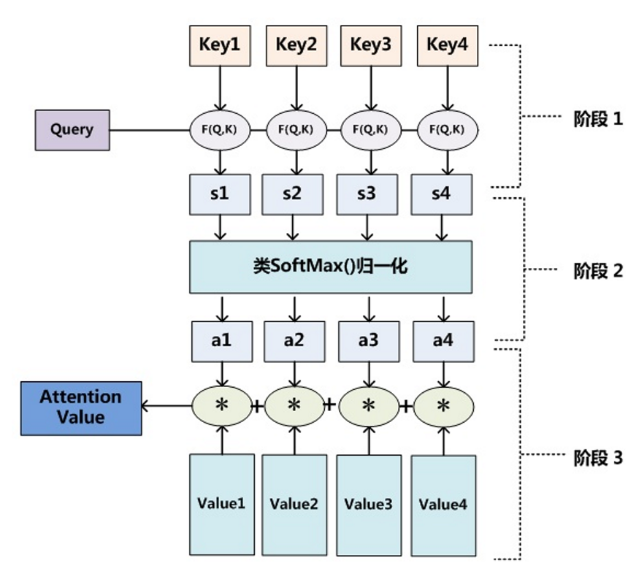
- Transformer
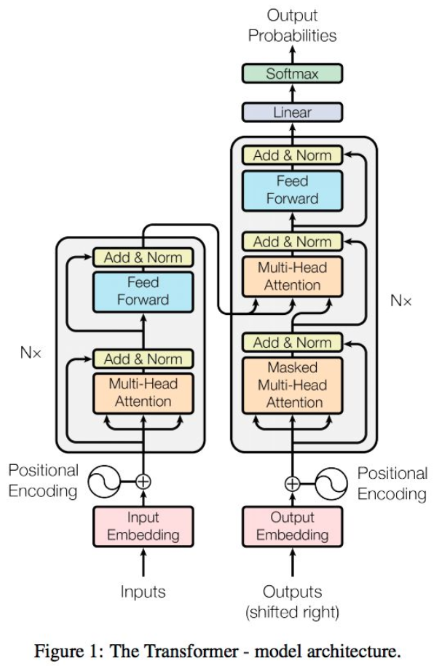
优点
- 直接对序列中每两个单词之间的依存关系进行建模,更强大,已成为当前预训练模型采用的主流架构
- 更适合对语言的长程依存关系进行建模
缺点
- 由于其复杂而又沉重的架构以及较小的模型偏差,Transformer通常需要一个大的训练语料库进行训练
- 训练时,容易在小的或中等大小的数据集上出现过拟合问题
预训练模型诞生背景
随着深度学习的发展,模型参数的数量迅速增加。需要更大的数据集来充分训练模型参数并防止过度拟合。然而,对于大多数自然语言处理任务来说,构建大规模标注数据集是一个巨大的挑战,因为标注成本非常昂贵,尤其是对于语法和语义相关的任务。相比之下,大规模的无标签语料库相对容易构建。
为了利用大量未标记的文本数据,可以首先从它们那里学习一个好的表示,然后将这些表示用于其他任务。研究表明,借助于从大型未标注语料库的语料库中提取的表征,许多自然语言处理任务的性能有了显著提高。
预训练的优势有如下几点:
- 在大规模文本语料库中能学习到一般的语言表示以用于下游任务
- 使得下游任务采用的模型能更好地被初始化,并获得更好的泛化表现,加速下游任务模型的收敛
- 预训练可以看作一种正则化的方式,避免模型在小规模数据上过拟合
预训练模型的发展史
预训练一直是学习模型参数的一种有效策略,预训练完毕之后,利用标记数据对模型参数进行微调以适应下游任务。
第一代:预训练词嵌入
模型发展:
- NNLM
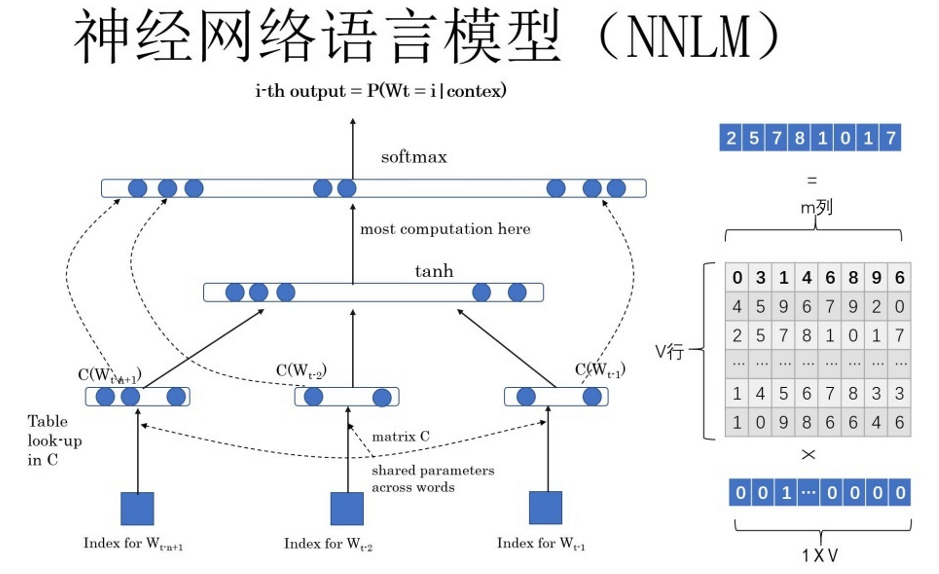
学习任务
输入某个句子中某个单词的前 \(t-1\) 个单词,要求NNLM网络最大化第 \(t\) 个位置出现该单词的概率,例如给定文本句子:”The most popular pre-train models is Bert",根据前6个单词,让模型预测单词"Bert"即最大化以下概率:
\]
其中 \(W_{i}\) 为单词的独热编码,它们作为模型的初始输入,\(W_{i}\) 乘上矩阵 \(Q\) 之后就得到对应单词的word embedding值 \(C\left(W_{i}\right)\)。将每个单词的word embdding拼接起来,上接隐层向量,然后经过一个 \(softmax\) 层预测后面紧跟着应该接哪个词。
事实上,矩阵 \(Q\) 的每一行代表着对应单词的word embedding值,只不过矩阵 \(Q\) 的内容也是模型参数,需要学习获得,\(Q\) 最初用随机值初始化。当模型训练完毕,矩阵 \(Q\) 就是NNLM模型在大规模文本语料库上完成语言模型的训练任务后得到的副产品,这个 \(Q\) 的每一行都是对应单词的嵌word embedding。
Word2Vec —— 基于预测的模型(两种不同训练方式)
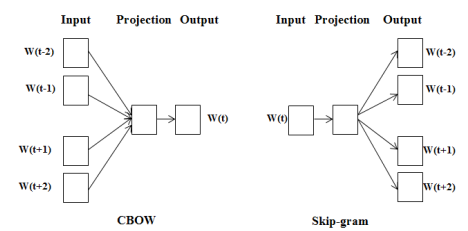
CBOW —— 从上下文预测中间词(完形填空)
Skip-Gram —— 从中间词预测上下文
Glove —— 基于统计的模型
基于全局语料库构建词的共现矩阵,矩阵的每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。通过对词的共现计数矩阵进行降维,来得到词向量;首先需要根据整个语料建立一个大型的体现词共现情况的矩阵,其目标是优化减小重建损失(reconstruction loss),即降维之后的向量能尽量表达原始向量的完整信息。
GloVe 相对于 Word2Vec 有一个优点是更容易并行化执行,可以更快,更容易地在大规模语料上训练。
第一代预训练词嵌入的优势:
- 尽管网络结构简单,但是仍然可以学习到高质量的单词嵌入来捕捉单词之间潜在的句法和语义相似性
不足之处:
- 得到的词嵌入向量与上下文无关,当词嵌入被应用于下游任务时,模型的其他参数需要重新训练。
第二代:预训练语境编码器
模型发展:
\]
由于大多数自然语言处理任务超出了单词层面,自然要在句子层面或更高层面对神经编码器进行预训练。神经编码器的输出向量也被称为上下文单词嵌入,因为它们根据单词的上下文来表示单词的语义。
研究者发现,序列模型Seq2Seq在做文本分类任务时,编码器和解码器的权重用两种语言模型的预训练权重初始化,然后用标记数据微调。模型的表现大大提升。
现如今,预训练模型通常使用更大规模的语料库、更复杂的神经网络模型结构(例如,Transformer)和新的预训练任务来训练。
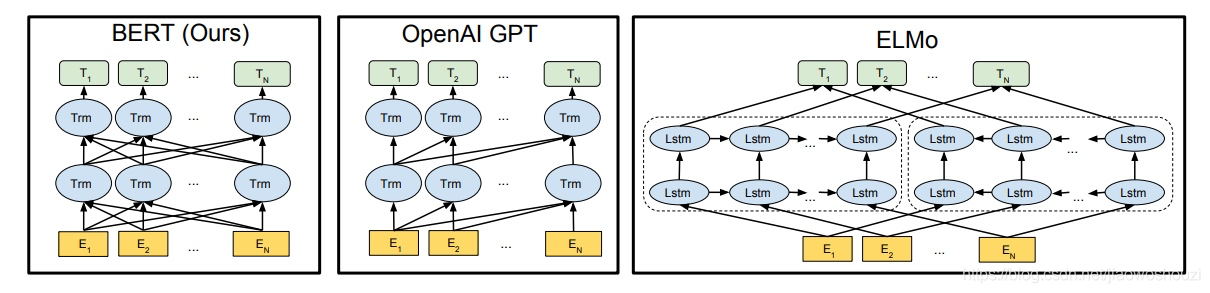
ELMo
预训练阶段
- 利用语言模型进行预训练,该语言模型的任务是根据单词的上下文序列正确预测该单词。
- ELMO网络结构采用了双层双向LSTM,左右两端分别是正反向的双层的LSTM编码器。
- 模型输入的句子中每个单词都能得到对应的三个嵌入向量:最底层的(黄色部分)是词嵌入Word Embedding,第一层双向LSTM中对应单词位置的Embedding,蕴含单词的句法信息;然后第二层LSTM中对应单词位置的Embedding,蕴含单词的语义信息。
微调阶段
- 将下游任务模型的输入通过ELMO进行编码得到文本嵌入,集成三种Embedding,将整合后的Embedding用于下游任务模型网络结构中对应单词的输入。
特点
- 采用了典型的预训练-微调的两阶段过程
- 预训练过程中,不仅学会了单词的word embedding,还学到了一个双层双向的LSTM网络结构,这个双层双向的网络结构可以用来提取文本的句法信息、语义信息。
不足
- LSTM的特征抽取能力远比不上Transformer
- 双向拼接的融合特征的能力不够强
GPT
预训练阶段
- 预训练的过程其实和ELMO类似,仍然以语言模型为目标任务,但是语言模型改成单向的,即只根据上文正确预测当前位置的单词,而把单词的下文完全抛开。
- 特征抽取器换成了Transformer,特征抽取的能力大大提升
微调阶段
对于不同的下游任务,网络结构要向GPT的网络结构看齐。在做下游任务的时候,利用预训练好的参数初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到下游任务中。
模型参数初始化后,用下游任务去训练这个网络,对网络参数进行Fine-tuning,使得网络更适合解决下游问题。
改造下游任务
(1)对于分类问题,加上一个起始和终结符号即可;
(2)对于句子关系判断问题,比如Entailment NLI,两个句子中间再加个分隔符即可;
(3)对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
(4)对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可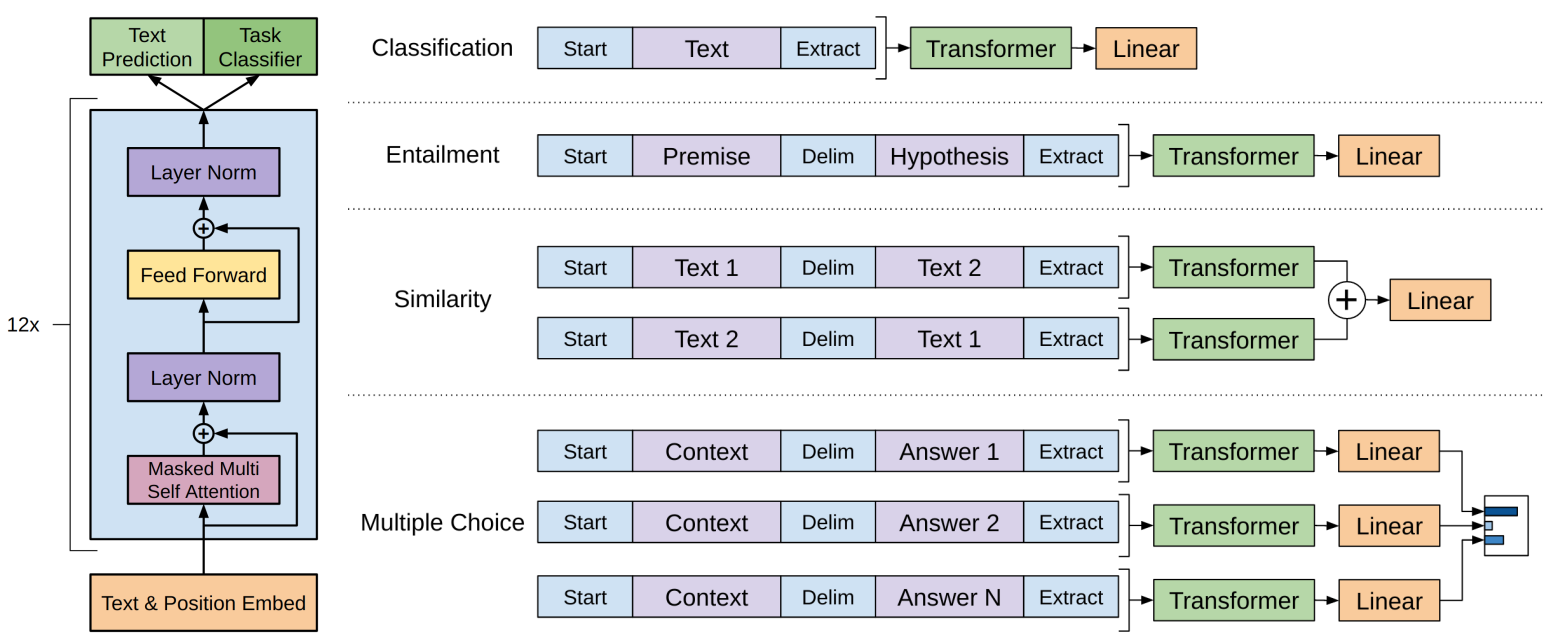
特点
- 训练的是单向语言模型
- 采用更强大的特征提取器Transformer
不足
- 单向语言模型改成双向就好了
BERT
预训练阶段
MLM(掩盖语言模型)
(1)MLM任务,即随机屏蔽(MASK)部分输入token,然后只预测那些被屏蔽的token。
(2)但是这么干之后,预训练阶段和finetuning阶段之间就不匹配了,因为在finetuning期间不会见到[MASK]。为了解决这个问题,BERT的做法是:不总是用实际的[MASK]替换被“masked”的词汇。相反,训练一个数据生成器随机选择15%的token,执行以下过程:
80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy.(3)缺陷:MLM模型下,一些单词会被随机替换,而Transformer的encoder部分不知道它将被要求预测的那些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。同时,由于训练MLM时,每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。这无疑增加了训练成本。
和GPT不同的地方在于,BERT采用和ELMO一样的双向语言模型任务作为预训练任务;
和ELMO不同的地方在于,BERT采用和GPT一样的特征提取器Transformer,集两家之所长。
微调阶段
和GPT一样,BERT也面临对下游任务进行改造的问题
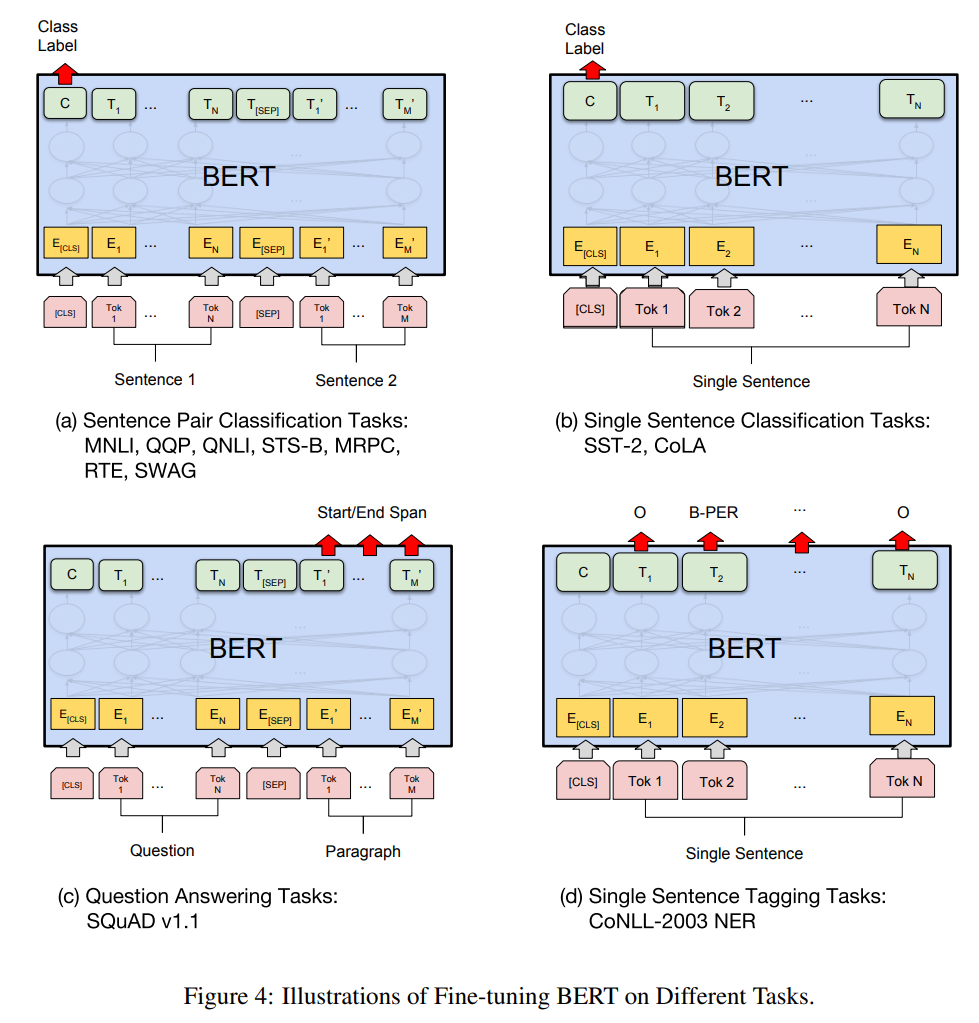
改造下游任务
(1)句子对分类 —— 在句子开头加上[CLS],后接单句的组成token,句子对之间用[SEP]分隔开,最后[CLS]对应位置输出的向量 \(C\) 由于不具备特别的语义特征,因此能更好地表示整个句对的语义信息。最后, 把第一个起始符号对应的Transformer最后一层位置上的输出 \(C\) 串接一个 \(\mathbf{softmax}\) 分类层对句对关系进行分类
(2)单句分类 —— [CLS]作为句子开头,后接单句的组成token,同样[CLS]对应位置输出的向量 \(C\) 后接上一个 \(\mathbf{softmax}\)分类器对句子进行分类
(3)问答 —— [CLS]作为句子开头,问题句的组成token和背景文本句的组成token用[SEP]隔开,将每个属于背景句子的token所在对应位置的输出向量与Start向量做点积算得分,根据得分确定答案在背景文本中的起始位置,结束位置的确定也是一样。最后在背景文本中,起始位置和结束位置之间对应的这段文本就当作问题的最终回答。
(4)序列标注 —— [CLS]作为句子开头,后接单句的组成token,将每个token对应位置输出的向量输入到一个多分类器中,输出每个token的标注分类预测。
特点
MLM双向语言模型
Transformer做特征提取器
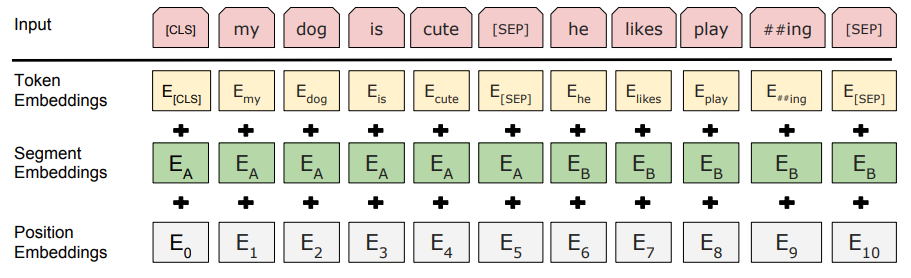
BERT输入部分的处理
输入部分是个线性序列,两个句子通过分隔符分割,最前面和最后增加两个标识符号。每个单词有三个embedding
(1)单词embedding
预训练后得到的单词Embedding。
(2)位置embedding
自注意力机制没有位置概念,每个位置等同看待,为了弄清楚token所在位置,需要引入位置嵌入,告诉模型当前的token处于句子的什么位置。
(3)句子embedding
整个句子的Embedding代表了整个句子的语义信息,句子嵌入需要给到那个句子中每个token。
把单词对应的三个embedding叠加,就形成了Bert的输入。
不足
- 同预训练阶段MLM模型的缺陷
预训练模型概览
预训练任务
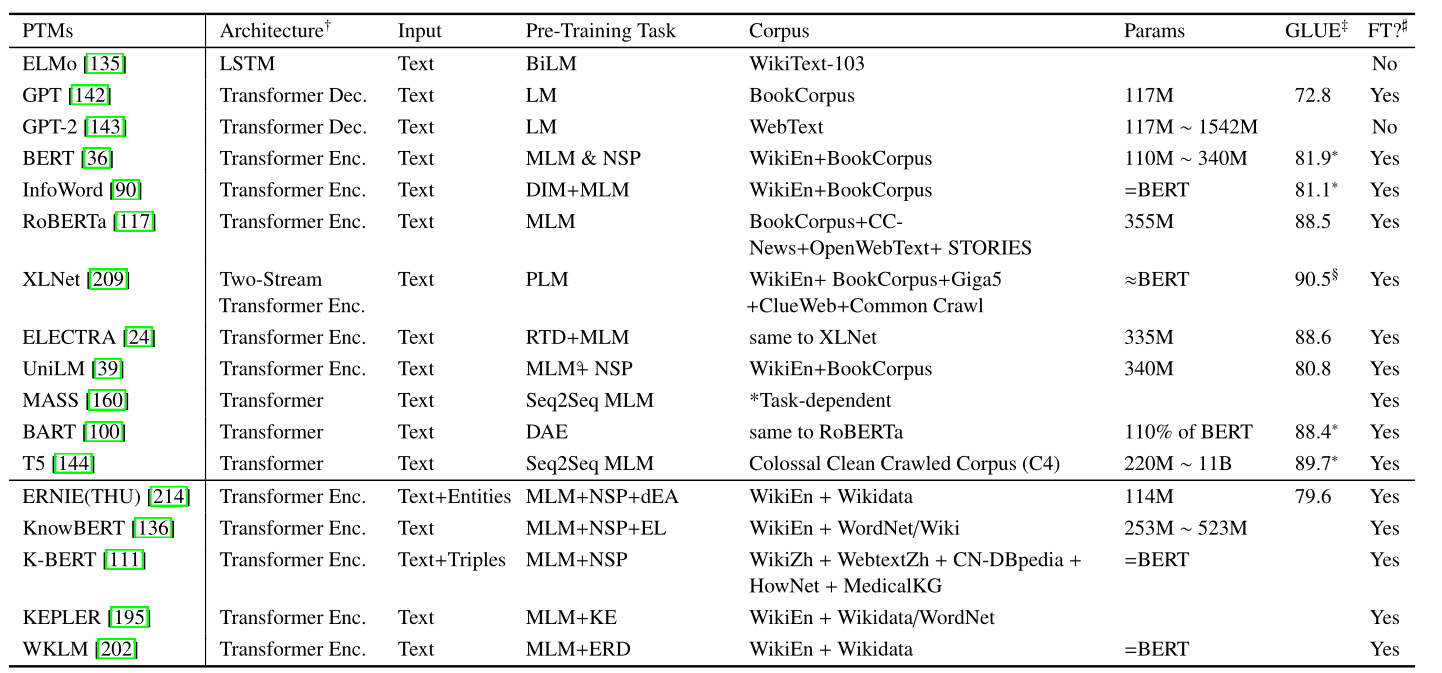
语言模型(LM)
语言模型通常特指自回归语言模型或者单向语言模型。
- 任务 —— 给定上文,根据紧接着的下一词汇在词汇表中的概率分布输出更可能的下文,即最大化句子出现的概率。给定一串文本序列 $ x_{1:T} = \left[ x_{1},x_{2}, \dots, x_{T} \right]$,其联合分布概率可以表示为如下条件概率的乘积:
\]
其中,$ x_{0} $ 为起始标记 \([Start]\) 对应的token。上述条件概率 $ p\left(x_{t} \mid \mathbf{x}{0: t-1}\right)$ 可以通过计算给定语境下(即上文\(x_{0:t-1}\)) 词汇表中所有词的概率分布来建模,其中,语境上文又可以通过神经编码器 $ f{enc}(·)$ 来进行编码,利用一个预测层 $g_{LM}(·) $ 输出词汇表中所有词在当前位置出现的概率分布。
\]
当给定一个巨大的语料库时,可以用最大似然估计来训练整个网络。
- 缺点 —— 每个token的表示只编码了上文的token和它自己。然而,更好的文本语境表示应该编码来自上文和下文两个方向的上下文信息。
- 改进 —— 考虑单向LM的缺陷,用两个单向LM组合起来构成双向LM(BiLM)。BiLM由两个单向LM组成:一个向前的从左到右LM和一个向后的从右到左LM。
- 代表模型
- 单向 —— GPT、GPT2、GPT3
- 双向 —— ELMO
掩盖语言模型(MLM)
- 任务 —— 完形填空(cloze task),从文本中的其他词预测当前被掩盖位置最可能出现的词。由于是同时考虑文本的上文和下文对掩盖词进行预测,因此MLM很好地克服了标准单向线性模型语境编码不完全的缺点。
- 缺点 —— 由于MLM首先会从输入文本中随机掩盖掉一些token,然后用其余的token来预测掩盖掉的token。因此,这种预训练方法会在预训练阶段和微调阶段之间造成不匹配,因为 $[MASK] $ 不会在微调阶段出现。
- 改进 —— 不总是用 \([MASK]\) 进行替换,训练一个数据生成器
- 在80%的时间内使用特殊的\([MASK]\)进行替换
- 在10%的时间内使用随机的token执行替换
- 在10%的时间内使用原始token来执行替换
- 代表模型 —— BERT及其庞大的BERT家族
排列语言模型(PLM)
虽然MLM效果惊人,但是不能忽视的是,MLM在预训练中使用的一些特殊标记(如[MASK])在模型应用于下游任务时并不存在,这导致预训练和微调之间存在差距。为了克服这个问题,提出了排列语言模型PLM。
- 任务 —— 基于输入序列的随机排列的语言建模。简单来说,就是从所有可能的排列中随机抽样一个排列。然后,将排列序列中的一些token作为目标,然后训练模型来预测这些目标。需要注意的是,这种随机排列不会影响序列的自然位置,仅会定义token预测的顺序。
- 代表模型 —— XLNet
去噪自编码器(DAE)
- 任务 —— 输入部分损坏的文本,重建原始的未失真的文本。
破坏文本的方式有:
- token掩盖:从输入中随机采样token,并用[MASK]替换它们。
- token删除:从输入中随机删除token。与掩盖token不同,模型需要确定缺失输入的位置。
- 文本填充:像SpanBERT一样,许多文本跨度被采样并用单个[MASK]标记替换。每个跨度长度由泊松分布(λ = 3)得出。该模型需要预测一个跨度中缺少多少个token。
- 句子排列:根据句号将文档分成句子,并以随机顺序排列这些句子。
- 文档翻转:随机均匀地选择一个token,并翻转文档,使其从该token开始。模型需要识别文档的真正开始位置
比较学习(CL)
- 总体任务 —— 假设一些观察到的文本对在语义上比随机抽样的文本更相似。学习文本对 \((x,y)\) 的得分函数 \(s(x,y)\) 以最小化目标函数:
\]
其中,\((x, y^{+})\) 是更相似的一对,\(y^{+}\) 和 \(y^{-}\) 分别为正样本和负样本。文本对的得分函数 \(s(x,y)\) 通常通过训练神经网络来学习。
训练的方式有两种:
- \(s(x, y)=f_{\mathrm{enc}(x)}^{\mathrm{T}} f_{\mathrm{enc}(y)}\)
- \(s(x, y)=f_{\text {enc }}(x \oplus y)\)
- 代表任务
- 下一句预测(NSP) —— NSP训练模型来区分两个输入句子是否是来自训练语料库的连续片段。具体来说,在为每个预训练例子选择句子对时,50%的时候,第二句是第一句的实际下一句,50%的时候,是从语料库中随机抽取的一句。通过这样做,它能够教模型理解两个输入句子之间的关系,从而有利于对该信息敏感的下游任务,例如问答和自然语言推理。 但是NSP任务的有效性和必要性备受质疑。
- 句子顺序预测(SOP) —— 和NSP不同,SOP使用同一文档中的两个连续片段作为正面示例,使用相同的两个连续片段,但它们的顺序交换作为反面示例。
模型分类
为了阐明自然语言处理中现有预训练模型之间的关系,可以从四个不同的角度对现有预训练模型进行分类:
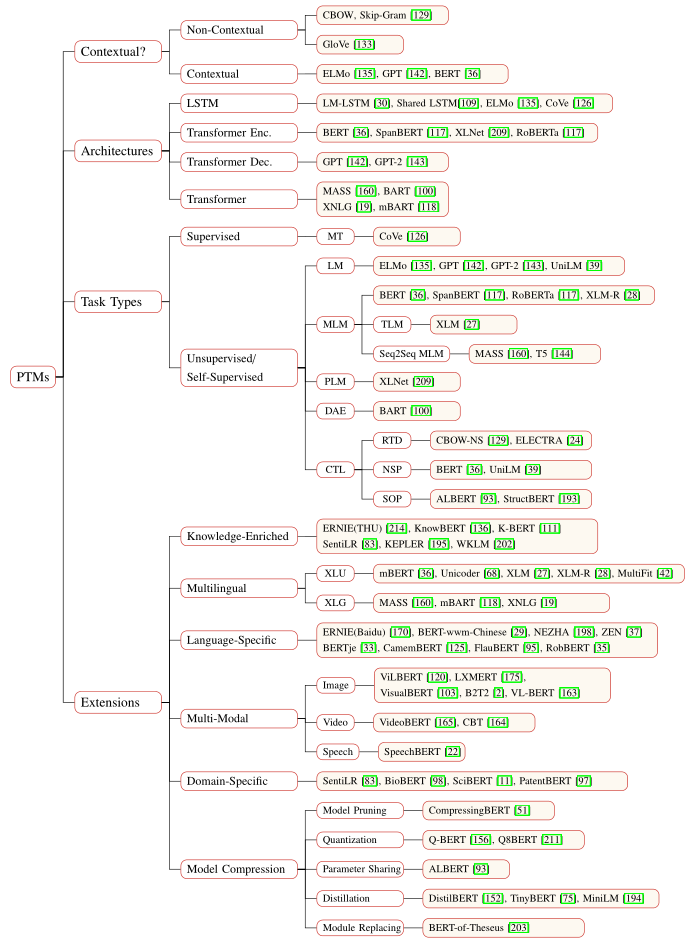
表示类型
- 与上下文独立的表示 —— Word2Vec、Glove等
- 与上下文相关的表示 —— ELMO、GPT、BERT等
架构(基础网络)
- LSTM —— ELMO
- Transformer
- encoder —— BERT
- decoder —— GPT(使用了三角矩阵实现了掩盖自注意力机制,即不允许模型在预测的时候看到下文)
- full
预训练任务
- 监督学习 —— 学习一个函数,该函数基于由输入输出对组成的训练数据将输入映射到输出。
- 无监督 —— 从未标记的数据中发现一些内在的知识,如LM。
- 自监督 —— 监督学习和非监督学习的结合,学习范式和监督学习完全一样,只是训练数据的标签是自动生成的。关键思想是从其他部分以某种形式预测输入的任何部分。如MLM。
扩展:特定场景下的预训练模型,包括知识丰富的预训练模型、多语言或特定语言的预训练模型、多模型预训练模型、特定领域的预训练模型等
模型分析
非上下文词嵌入
- 思想 —— 通过神经网络语言模型学习的单词表示能够捕捉语言中的语言规律,单词之间的关系可以通过特定关系的向量偏移来表征。例如,\(vec(“China”) − vec(“Beijing”) ≈ vec(“Japan”) −vec(“Tokyo”)\) ,另外,经过神经语言模型训练得到的词向量还具有组合性,\(vec(“Germany”) + vec(“capital”) ≈ vec(“Berlin”)\)。
- 缺点 —— 这种分布式单词表示擅长预测分类属性(例如,狗是一种动物),但不能真正学习属性(例如,天是蓝的)。而且,考虑到多义词需要结合上下文语境进行词义的判断,而这种与上下文无关的分布式词表示往往无法代表词的正确意思。
上下文词嵌入
- 思想 —— 在做语言模型任务时,把上下文语境文本融合进词表示向量,使得词表示向量能够蕴含除词本义之外的上下文语义知识信息和语言学信息。
- 语言学信息 —— 研究人员从BERT中提取依赖树和支持树,证明了BERT对语法结构进行编码的能力。
- 语言特征似乎表现在单独的语义和句法子空间中
- 注意矩阵包含语法表征
- BERT非常精细地区分词义。
- 语义知识信息 —— 除了语言知识,预训练模型还可以存储训练数据中呈现的世界知识。探索世界知识的一个简单方法是用“填空”完形填空语句来查询BERT,例如,“但丁诞生于[MASK]”。研究人员通过从几个知识来源手动创建单标记完形填空语句(查询)来构建LAMA(语言模型分析)任务。他们的实验表明BERT包含的世界知识比传统的信息抽取方法更有竞争力。
- 语言学信息 —— 研究人员从BERT中提取依赖树和支持树,证明了BERT对语法结构进行编码的能力。
预训练模型拓展
基于知识增强
- 思想 —— 将外部知识纳入预训练模型
- 代表模型
- LIBERT —— 通过额外的语言限制任务整合语言知识
- SentiLR —— 集成每个词的情感极性,将MLM扩展为具有标签感知能力的MLM(LA-MLM)
- SenseBERT —— 经过预先训练,不仅可以预测掩码标记,还可以预测它们在WordNet中的超集。
- ERNIE —— 将预先在知识图上训练的实体嵌入与文本中相应的实体提及相结合,以增强文本表示。
- KnowBERT —— 将BERT与实体链接模型结合起来,以端到端的方式整合实体表示。
- K-BERT —— 允许在对下游任务进行微调的过程中注入事实知识。
- 知识-文本融合模型 —— 机器阅读理解中获取相关语言和事实知识。
基于多语言和特定语言
- 多语言
- 跨语言理解
- 跨语言生成
- 特定语言
基于多模态
这些多模态模型中的绝大多数是为一般的视觉和语言特征编码而设计的。这些模型是在大量跨模态数据的基础上进行预训练的(如带有口语词的视频或带有字幕的图像),并结合扩展的预训练任务来充分利用多模态特征。
视频-文本(Video-Text)
视频分别由基于CNN的编码器和现成的语音识别技术进行预处理。使用一个单独的Transformer编码器在处理过的数据上进行训练,学习视频字幕等下游任务的视觉语言表示。代表模型有,VideoBERT和CBT。
图像-文本(Image-Text)
引入图像-文本对,旨在微调下游任务,如视觉问题回答(VQA)和视觉常识推理(VCR)。
分类:
- 采用两个独立的编码器来独立地表示图像和文本, 例如ViLBERT和LXMERT。
- 使用single-stream unified Transformer,虽然这些模型体系结构不同,但是在这些方法中引入了类似的预训练任务,例如MLM和图像-文本匹配。例如,VisualBERT,B2T2,VLBERT, Unicoder-VL和UNITER。
音频-文本(Audio-Text)
SpeechBERT模型试图用一个Transformer编码器编码音频和文本以建立一个端到端的语音问答(SQA)模型。
基于特定领域与任务
大多数预训练模型都是在维基百科等通用领域语料库上进行预训练的,这限制了它们在特定领域或任务上的应用。
- 训练特定领域预训练模型
- 生物医学 —— BioBERT
- 科学 —— SciBERT
- 临床医学 —— ClinicalBERT
- 利用通用领域预训练模型适应具体任务
- 情感分析 —— 感知情感标签的MLM
- 文本摘要 —— 间歇句生成
- 不流畅检测 —— 噪声词检测
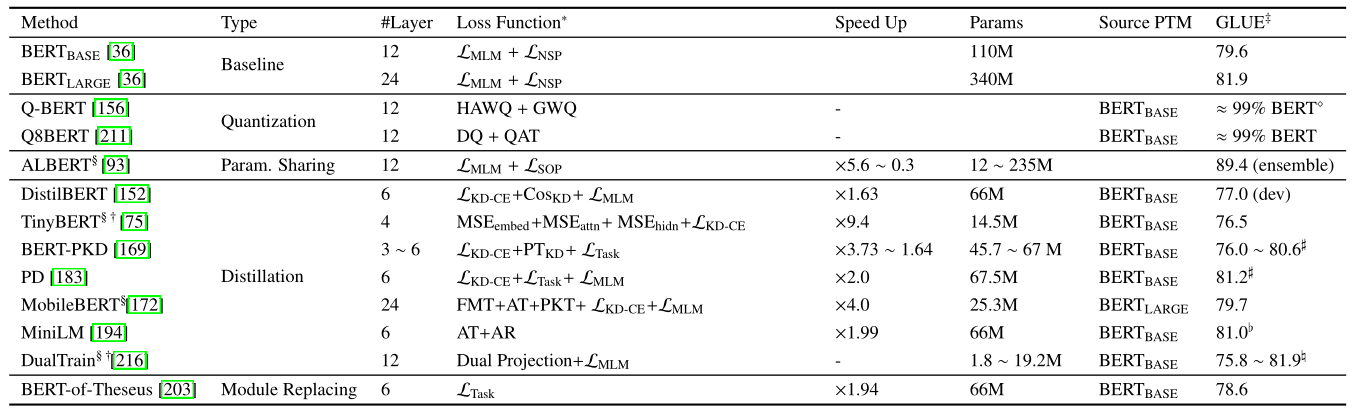
模型压缩
- 动机 —— 预训练模型参数量过于庞大,很难在现实应用和资源受限的设备上进行部署,因此,如何压缩模型也成为了研究的一个热点。
- 模型压缩方法 —— 一种减小模型尺寸和提高计算效率的潜在方法
- 模型修剪 —— 去除不重要的参数,具体来说,就是去除部分神经网络(如权值、神经元、层、通道、注意头),从而达到减小模型规模、加快推理时间的效果。修剪选择和修剪时机的把握有待研究。
- 连接权重量化 —— 用较少的比特表示参数,将精度较高的参数压缩到较低的精度。
- 参数共享 —— 对于那些相似的模型单元,共享它们的参数。这种方法广泛应用于CNNs、RNNs和Transformer。例如,ALBERT使用跨层参数共享和因子化嵌入参数化来减少模型的参数。虽然参数数量大大减少,但是ALBERT的训练和推理时间甚至比标准的BERT还要长。通常,参数共享不会提高推理阶段的计算效率。
- 知识提取 —— 在原模型的基础上,根据原模型的中间结果学习一个更小的模型
- 模块替换 —— 用更紧凑的模块替换原模型具有相似功能的模块。例如使用Theseus-Compress,压缩模型的同时保持98%的模型性能,速度是原来的1.4倍。
预训练模型应用于下游任务
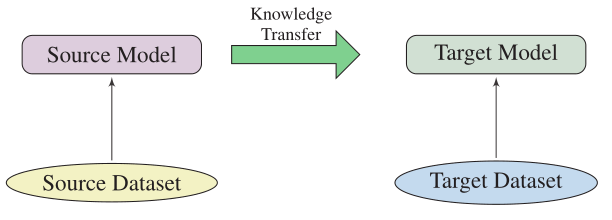
迁移学习
迁移学习是将知识从源任务(或领域)调整到目标任务(或领域)。
如何迁移
选择合适的预训练任务、模型架构和语料库
- 不同的预训练任务有各自的偏向,对不同的任务有不同的效果。例如,NSP任务使预训练模型学习了两句话之间的关系。因此,训练后的预训练模型可以受益于问答和自然语言推理(NLI)等下游任务。
- BERT虽然能很好地解决自然语言推理任务,但是很难用于生成式的任务。
- 下游任务的数据分布应该接近预训练模型。
选择合适的层
给定一个预先训练的深度模型,不同的层应该捕获不同种类的信息,例如词性标注、解析、长期依赖、语义角色、共指。对于基于RNN的模型,研究表明,多层LSTM编码器的不同层学习到的表示有益于不同的任务。
有三种方法可以选择表示:
- 只选择预先训练的静态嵌入表示,而模型的其余部分仍然需要为新的目标任务从头开始训练。这些部分无法获取更高级别的信息,而这些信息可能更有用。
- 顶层表示。最简单有效的方法是将顶层的表示馈入特定任务模型。
- 所有层。更灵活的方法是自动选择最佳层:
\[\mathbf{r}_{t}=\gamma \sum_{l=1}^{L} \alpha_{l} \mathbf{h}_{t}^{(l)}
\] 其中,$ \alpha $ 表示 \(l\) 层的软最大归一化权重,$ \gamma $是缩放预训练模型输出的向量的标量。混合表示 $ r_{t} $ 被输入到特定任务模型中。
微调策略
- 两阶段微调 —— 在第一阶段,预训练模型被转换成一个由中间任务或语料库微调的模型。在第二阶段,转移的模型被微调到目标任务。
- 多任务微调 —— 多任务学习框架下的微调BERT,多任务学习和预训练是互补的技术。
- 使用额外的自适应模块进行微调 —— 微调的主要缺点是参数效率低,每个下游任务都有自己的微调参数。因此,更好的解决方案是在原始参数固定的情况下,往预训练模型中注入一些可微调的自适应模块。
预训练模型资源
- 预训练模型的开源实现
- 语料库
未来方向
- 预训练模型还未到达上限 —— 模型可以通过更多的训练步骤和更大的语料库来进一步改进。
- 预训练模型架构优化 —— 为预训练模型寻找更有效的模型架构对于获取更大范围的上下文信息非常重要。深度架构的设计具有挑战性,可能会寻求一些自动化方法的帮助,比如神经架构搜索。
- 面向任务的预训练和模型压缩
- 实现超越微调的知识转移
- 提高预训练模型的可解释性和可靠性
参考资料
[1] Qiu X, Sun T, Xu Y, et al. Pre-trained models for natural language processing: A survey[J]. arXiv preprint arXiv:2003.08271, 2020.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[4] Yang Z, Dai Z, Yang Y, et al. Xlnet: Generalized autoregressive pretraining for language understanding[C]//Advances in neural information processing systems. 2019: 5753-5763.
[5] 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 by 张俊林
预训练模型——开创NLP新纪元的更多相关文章
- 【转载】最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
本文介绍了一种新的语言表征模型 BERT--来自 Transformer 的双向编码器表征.与最近的语言表征模型不同,BERT 旨在基于所有层的左.右语境来预训练深度双向表征.BERT 是首个在大批句 ...
- 最强中文NLP预训练模型艾尼ERNIE官方揭秘【附视频】
“最近刚好在用ERNIE写毕业论文” “感觉还挺厉害的” “为什么叫ERNIE啊,这名字有什么深意吗?” “我想让艾尼帮我写作业” 看了上面火热的讨论,你一定很好奇“艾尼”.“ERNIE”到底是个啥? ...
- 百度NLP预训练模型ERNIE2.0最强实操课程来袭!【附教程】
2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨.经过短短几个月时间,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基 ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- NLP与深度学习(五)BERT预训练模型
1. BERT简介 Transformer架构的出现,是NLP界的一个重要的里程碑.它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT. BERT的全称是Bidirectional En ...
- NLP预训练模型-百度ERNIE2.0的效果到底有多好【附用户点评】
ERNIE是百度自研的持续学习语义理解框架,该框架支持增量引入词汇(lexical).语法 (syntactic) .语义(semantic)等3个层次的自定义预训练任务,能够全面捕捉训练语料中的词法 ...
- BERT预训练模型的演进过程!(附代码)
1. 什么是BERT BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双向Tr ...
- XLNet预训练模型,看这篇就够了!(代码实现)
1. 什么是XLNet XLNet 是一个类似 BERT 的模型,而不是完全不同的模型.总之,XLNet是一种通用的自回归预训练方法.它是CMU和Google Brain团队在2019年6月份发布的模 ...
- 中文预训练模型ERNIE2.0模型下载及安装
2019年7月,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基于此框架的ERNIE 2.0预训练模型, 它利用百度海量数据和飞桨(PaddlePaddle)多机多卡高效训练优 ...
随机推荐
- git克隆指定分支到本地
我们每次使用命令 git clone https://xxx.com/android-app.git 默认 clone 的是这个仓库的 master 分支. 使用Git下载指定分支命令为:git cl ...
- CSS精灵图与字体图标
CSS精灵图与字体图标 1. 精灵图 当用户访问一个网站时,需要向服务器发送请求,网页上的每张图像都要经过一次请求才能展现给用户.然而,一个网页中往往会应用很多小的背景图像作为修饰,当网页中的图像过多 ...
- 氵0x a
从今天开始记录这些东西,希望以后自己不出现在这上
- filebeat7.5 日志
百度网盘 提取码: 6cvu 解压 tar -zxvf filebeat-7.5.0-linux-x86_64.tar.gz mv filebeat-7.5.0-linux-x86_64 /usr/l ...
- centos8平台使用pidstat监控cpu/内存/io
一,安装pidstat: 1,安装 [root@localhost yum.repos.d]# yum install sysstat 2,查看版本: [root@localhost ~]# pids ...
- 实现LNMP架构
LNMP简介 WEB资源类型: 静态资源:服务器端和客户端看到的是一样的 动态资源:服务器端放的是程序,客户端看到的是结果,并不是程序本身 和页面的静或者动没有关系 WEB相关语言 HTML JAVA ...
- MySQL数据库基础-3
SQL语言 结构化的查询云烟 有国际标准. 非常容易学习的,关注数据本身,类似于shell SQL解释器 命令行效率比较高 应用编程接口 ODBC:Open Database Connectivity ...
- 《Kafka笔记》4、Kafka架构,与其他组件集成
目录 1 kafka架构进阶 1.1 Kafka底层数据的同步机制(面试常问) 1.1.1 高水位截断的同步方式可能带来数据丢失(Kafka 0.11版本前的问题) 1.1.2 解决高水位截断数据丢失 ...
- vue 组件传值,(太久不用就会忘记,留在博客里,方便自己查看)
一 :父组件 传值给 子组件 方法: props //父组件 <template lang="html"> <div> <h3>我是父亲< ...
- Zookeeper(2)---节点属性、监听和权限
之前通过客户端连接之后我们已经知道了zk相关的很多命令(Zookeeper(1)---初识). 节点属性: 现在我们就通过stat指令来看看节点都有哪些属性,或者使用get 指令和-s参数来查看节点数 ...