Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程:
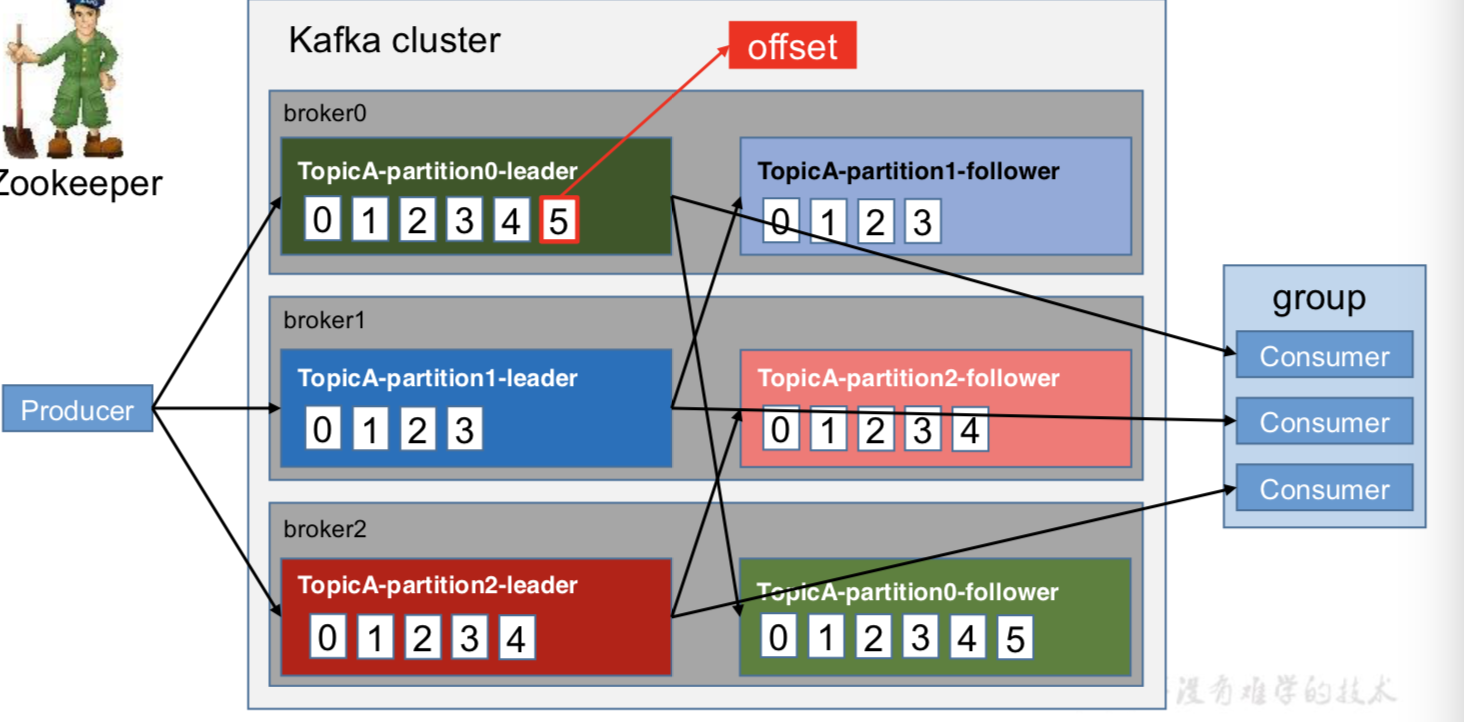
每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性。
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的。(文件topic_partition命名)
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文 件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该 log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己 消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
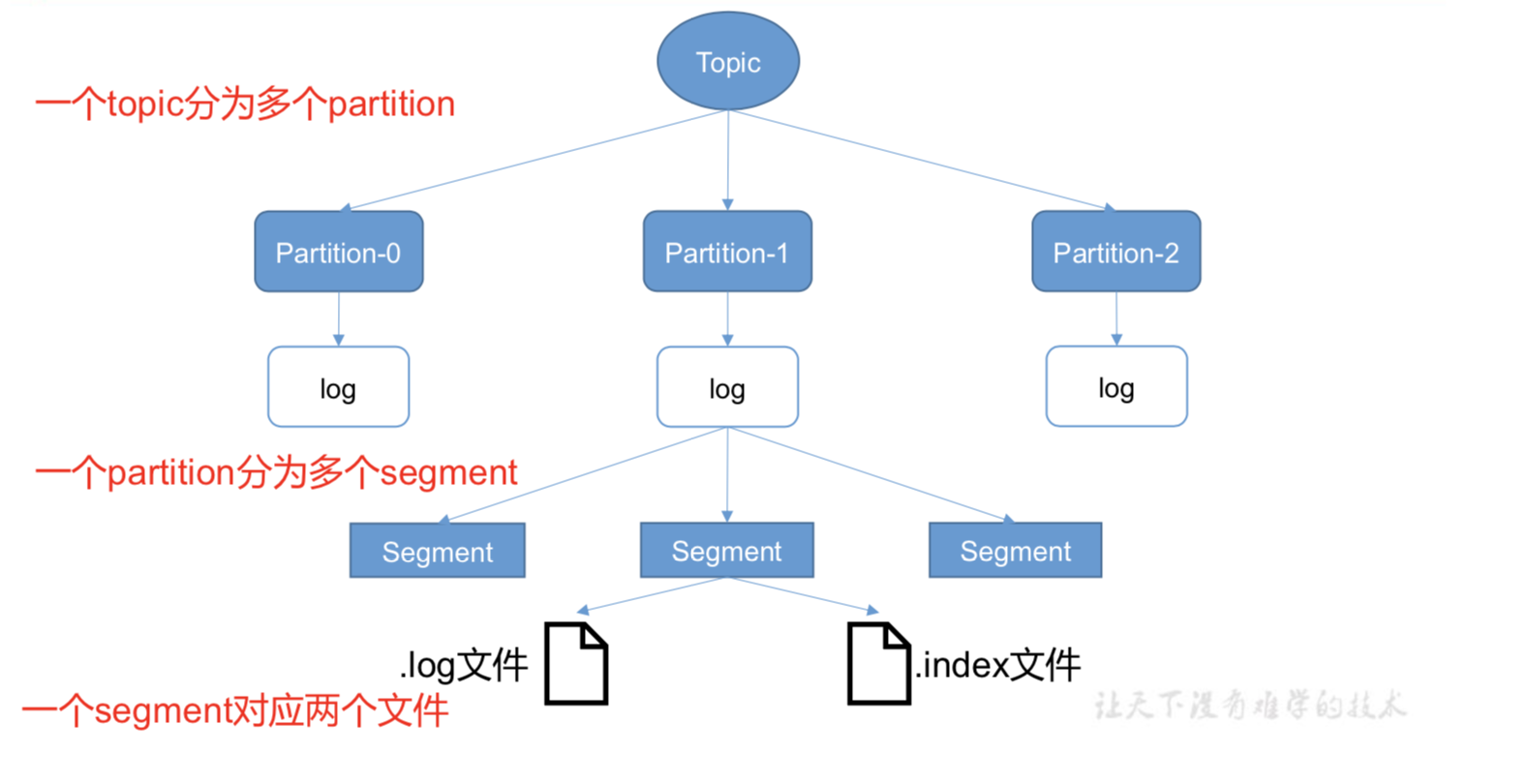
log中存的是实际数据,默认存储7天。
xxxxx.log文件
xxxxx.index文件
log.segment.bytes=1073741824 (1G)
1、当超过1G,会再建一个新的xxxxxxxxx.log数据文件。(一个segment)
2、如何在文件中快速定位到消费者需要的数据(xxxxx.index文件)
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位 效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment 对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名 规则为:topic 名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为 first- 0,first-1,first-2。
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。下图为 index 文件和 log 文件的结构示意图。
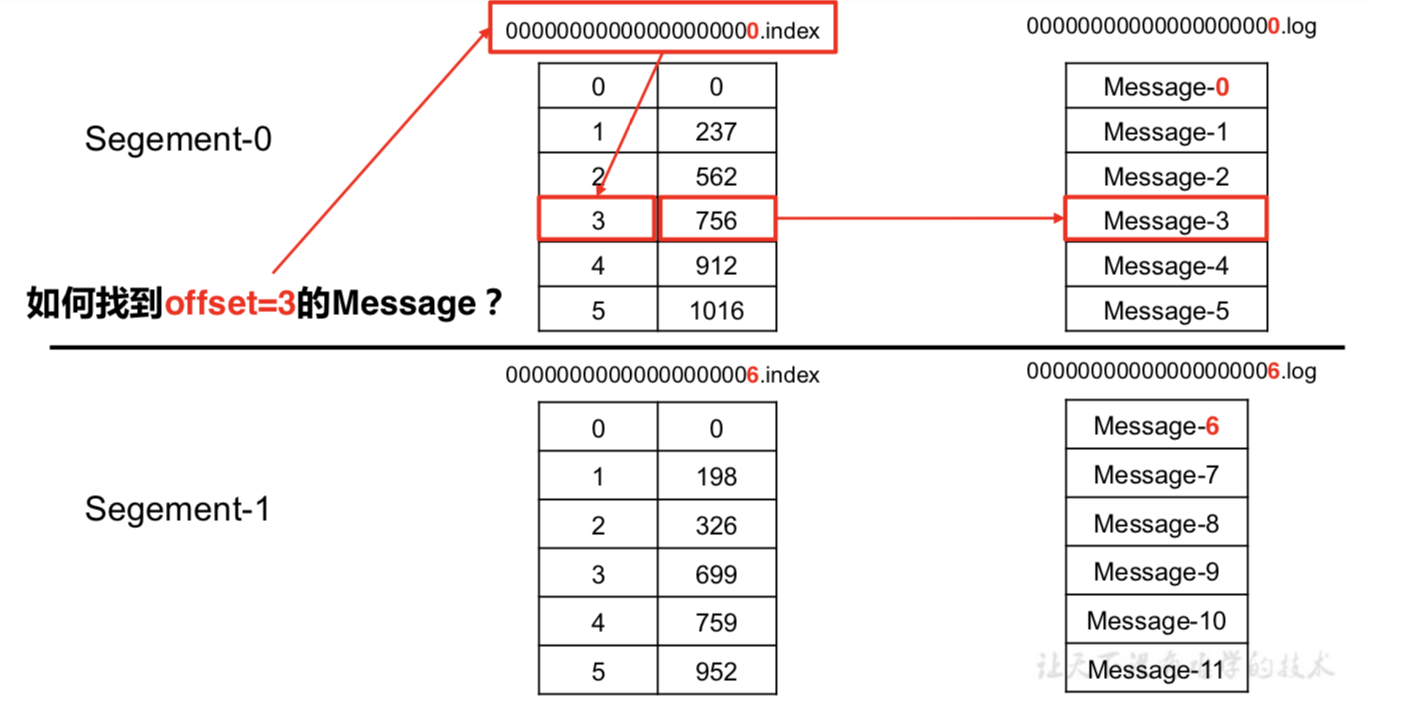
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元 数据指向对应数据文件中 message 的物理偏移地址。 (先通过二分查找,找到消息在某个xxxx.log文件,再去xxxx.index去找消息开头在log中的物理偏移地址)
index文件中每项数据大小一样,不仅存储了每条messge的起始位置,还有每条消息的大小:上图未画出。 利用起始位置+消息大小,读取整个消息
Kafka架构深入:Kafka 工作流程及文件存储机制的更多相关文章
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka与RocketMq文件存储机制对比
一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一. 开头问题 kafka文件结构和rocketMQ文件结构是什么样子?特点是什么? 一.目录结构 Kafk ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
随机推荐
- 多测师讲解 自动化测试理论(1)_高级讲师肖sir
自动化测试理论什么是自动化测试?广义的:通过工具或程序替代或辅助人工测试的行为叫自动化测试狭义的:通过工具录制或编写脚本模拟手工测试的过程,通过回放或运行脚本执行测试用例,从而代替人工对系统的功能验证 ...
- day02 Pyhton学习
1.昨日内容回顾 1.python是一门解释型,弱类型的高级编程语言 优点: 1.优雅简单明确 2.短小快,代码短,代码量小,开发效率高 缺点: 1.运行效率低(相对) 2.python解释器 Cpy ...
- day33 Pyhton 常用模块03
一.正则表达式: 1.元字符 . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 \b 匹配一个单词的结尾 ...
- pytest文档43-元数据使用(pytest-metadata)
前言 什么是元数据?元数据是关于数据的描述,存储着关于数据的信息,为人们更方便地检索信息提供了帮助. pytest 框架里面的元数据可以使用 pytest-metadata 插件实现.文档地址http ...
- 深入理解RabbitMQ中的prefetch_count参数
前提 在某一次用户标签服务中大量用到异步流程,使用了RabbitMQ进行解耦.其中,为了提高消费者的处理效率针对了不同节点任务的消费者线程数和prefetch_count参数都做了调整和测试,得到一个 ...
- centos8平台使用ab做压力测试
一,安装ab [root@blog ~]# yum install httpd-tools 说明:刘宏缔的架构森林是一个专注架构的博客,地址:https://www.cnblogs.com/archi ...
- sql查询:部门工资前三高的员工和部门工资最高的员工
创建表:Create table If Not Exists Employee (Id int, Name varchar(255), Salary int, DepartmentId int);Cr ...
- js读取xml,javascript读取XML
IE下示例代码: var xmlDoc = "<root><AlleyWay><Code>1103</Code><Name>胡同2 ...
- <article>
今天介绍的是html中<article>标签的用法,如果有兴趣的朋友可以看一下! <article> 标签规定独立的自包含内容. 一篇文章应有其自身的意义,应该有可能独立于站点 ...
- Dubbo系列之 (七)网络层那些事(2)
辅助链接 Dubbo系列之 (一)SPI扩展 Dubbo系列之 (二)Registry注册中心-注册(1) Dubbo系列之 (三)Registry注册中心-注册(2) Dubbo系列之 (四)服务订 ...