CMU数据库(15-445)Lab1-BufferPoolManager
0. 关于环境搭建请看
https://www.cnblogs.com/JayL-zxl/p/14307260.html
1. Task1 LRU REPLACEMENT POLICY
0. 任务描述
这个任务要求我们实现在课堂上所描述的LRU算法最近最少使用算法。
你需要实现下面这些函数。请确保他们都是线程安全的。
Victim(T*): Remove the object that was accessed the least recently compared to all the elements being tracked by theReplacer, store its contents in the output parameter and returnTrue. If theReplaceris empty returnFalse.Pin(T): This method should be called after a page is pinned to a frame in theBufferPoolManager. It should remove the frame containing the pinned page from theLRUReplacer.Unpin(T): This method should be called when thepin_countof a page becomes 0. This method should add the frame containing the unpinned page to theLRUReplacer.Size(): This method returns the number of frames that are currently in theLRUReplacer.
关于Lock和Lathes的区别请看下文。
1. 实现
其实这个任务还是蛮简单的。你只需要清楚什么是最近最少使用算法即可。
LRU 算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
这个题我熟啊。leetcode上有原题。而且要求在o(1)的时间复杂度实现这一任务。
https://leetcode-cn.com/problems/lru-cache/
为了实现在O(1)时间内进行查找。因此我们可以用一个hash表。而且我们要记录一个时间戳来完成记录最近最少使用的块是谁。这里我们可以用list来实现。
如果我们访问了链表中的一个元素。就把这个元素放在链表头部。这样放在链表尾部的元素一定就是最近最少使用的元素。
为了让插入和删除均为O(1)我们可以用双向链表来实现。
这里对于pin和unpin操作实际上对于了task2。我们为什么需要pin。书上给了我们答案。下面我们也进行了分析
1.1 数据结构设计
struct Node{
Node(frame_id_t v) :value(v) {}
frame_id_t value;
std::shared_ptr<Node> left;
std::shared_ptr<Node> right;
};
这里我们用了双向链表。主要是为了删除和插入均为0(1)的时间复杂度
1.2 辅助函数设置
这里我们需要两个辅助函数remove和insert
这里的head和tail为头节点和尾节点。这样写能够减少对于边界条件判断。在构造函数内我们进行初始化
LRUReplacer::LRUReplacer(size_t num_pages) {
head.reset(new Node(-1));
tail.reset(new Node(-1));
capacity=num_pages;
head->right=tail;
tail->left=head;
}
关于头节点和尾节点的作用可以参考下文。
https://blog.csdn.net/qq_41809589/article/details/86550994
insert函数负责把一个节点插入到链表头部。
void LRUReplacer::insert(std::shared_ptr<Node> node) {
if (node == nullptr) {
return;
}
node->right = head->right;
node->left = head;
head->right->left=node;
head->right=node;
hash[node->value] = node;
size++;
}
remove函数负责把一个节点从链表中移除
bool LRUReplacer::remove(const frame_id_t &value) {
auto iter=hash.find(value);
if(iter==hash.end())return false;
auto node=iter->second;
node->right->left=node->left;
node->left->right=node->right;
hash.erase(value);
size--;
return true;
}
1.3 Victim 函数实现
注意这里必须要加锁,以防止并发错误。
- 如果没有可以牺牲的页直接返回false
- 如果有的话选择在链表尾部的页。remove它即可
bool LRUReplacer::Victim(frame_id_t *frame_id) {
std::scoped_lock lru_clk{lru_mutex};
if (hash.empty()) {
return false;
}
auto id = tail->left;
remove(id->value);
*frame_id = id->value;
return true;
}
1.4 pin 函数实现
注意这里必须要加锁,以防止并发错误。
- 如果这个页存在则直接remove(因为这个时候它的
pin_couter=0
void LRUReplacer::Pin(frame_id_t frame_id) {
std::scoped_lock lru_clk{lru_mutex};
if(hash.count(frame_id))remove(frame_id);
}
1.5 unpin 函数实现
注意这里必须要加锁,以防止并发错误。
- 先看一下这个页是否在可替换链表中
- 如果它不存在的话。则需要看一下当前链表是否还有空闲位置。如果有的话则直接加入
- 如果没有则需要移除链表尾部的节点知道有空余位置
void LRUReplacer::Unpin(frame_id_t frame_id) {
std::scoped_lock lru_clk{lru_mutex};
auto iter=hash.find(frame_id);
if(iter==hash.end()){
if (hash.size() >= capacity) {
// need to remove item
while (hash.size() >= capacity) {
auto p=tail->left;
remove(p->value);
}
}
auto newNode = std::make_shared<Node>(frame_id);
insert(newNode);
}
}
2. 测试
执行下面的语句即可
cd build
make lru_replacer_test
./test/lru_replacer_test

可以发现成功通过
Task2 BUFFER POOL MANAGER
0. 任务描述
接下来,您需要在系统中实现缓冲池管理器(BufferPoolManager)。BufferPoolManager负责从DiskManager获取数据库页面并将它们存储在内存中。BufferPoolManage还可以在有要求它这样做时,或者当它需要驱逐一个页以便为新页腾出空间时,将脏页写入磁盘。为了确保您的实现能够正确地与系统的其余部分一起工作,我们将为您提供一些已经填写好的功能。您也不需要实现实际读写数据到磁盘的代码(在我们的实现中称为DiskManager)。我们将为您提供这一功能。
系统中的所有内存页面均由Page对象表示。 BufferPoolManager不需要了解这些页面的内容。 但是,作为系统开发人员,重要的是要了解Page对象只是缓冲池中用于存储内存的容器,因此并不特定于唯一页面。 也就是说,每个Page对象都包含一块内存,DiskManager会将其用作复制从磁盘读取的物理页面内容的位置。 BufferPoolManager将在将其来回移动到磁盘时重用相同的Page对象来存储数据。 这意味着在系统的整个生命周期中,相同的Page对象可能包含不同的物理页面。Page对象的标识符(page_id)跟踪其包含的物理页面。 如果Page对象不包含物理页面,则必须将其page_id设置为INVALID_PAGE_ID。
每个Page对象还维护一个计数器,以显示“固定”该页面的线程数。BufferPoolManager不允许释放固定的页面。每个Page对象还跟踪它的脏标记。您的工作是判断页面在解绑定之前是否已经被修改(修改则把脏标记置为1)。BufferPoolManager必须将脏页的内容写回磁盘,然后才能重用该对象。
BufferPoolManager实现将使用在此分配的前面步骤中创建的LRUReplacer类。它将使用LRUReplacer来跟踪何时访问页对象,以便在必须释放一个帧以为从磁盘复制新的物理页腾出空间时,它可以决定取消哪个页对象
你需要实现在(src/buffer/buffer_pool_manager.cpp):的以下函数
FetchPageImpl(page_id)NewPageImpl(page_id)UnpinPageImpl(page_id, is_dirty)FlushPageImpl(page_id)DeletePageImpl(page_id)FlushAllPagesImpl()
1. 分析
**1.1 为什么需要pin **
其实大抵可以如下图。
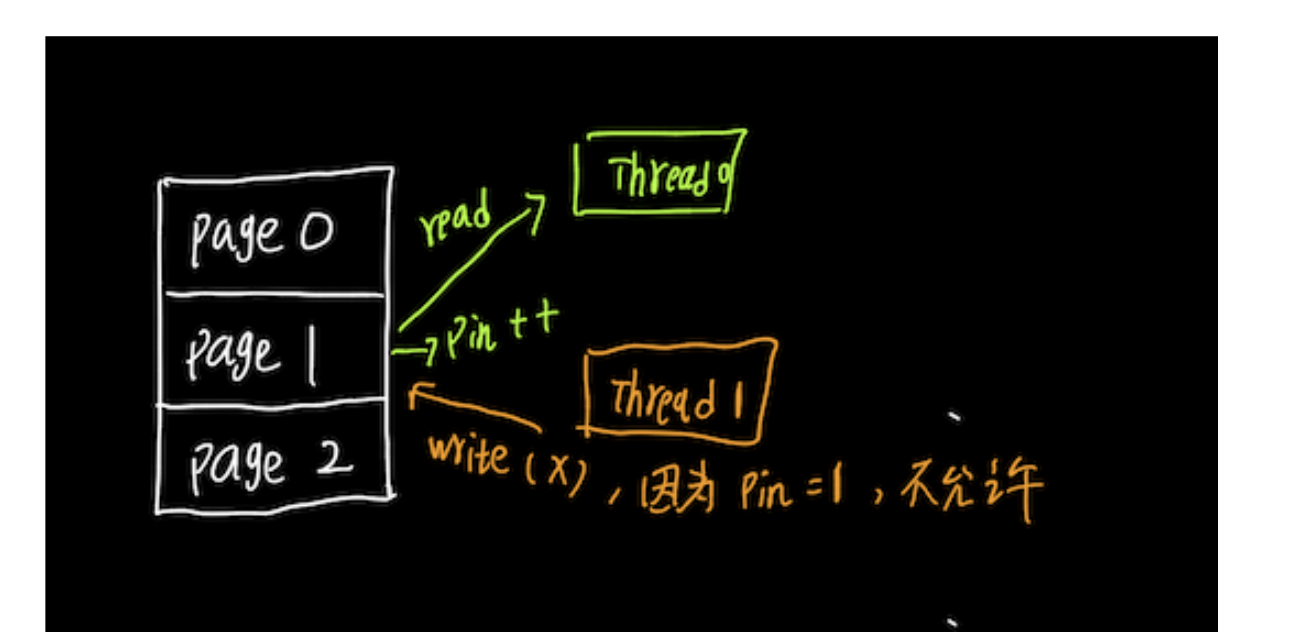
考虑这样一种情况。一个块被放入缓冲区,进程从缓冲区内存中读取块的内容。但是,当这个块被读取的时候,如果一个并发进程将这个块驱逐出来,并用一个不同的块替换它,读取旧块内容的进程(reader)将看到不正确的数据;如果块被驱逐时正在写入它,那么写入者最终会破坏替换块的内容。
因此,在进程从缓冲区块读取数据之前,确保该块不会被逐出是很重要的。为此,进程在块上执行一个pin操作;缓冲区管理器从不清除固定的块(pin值不为0的块)。当进程完成读取数据时,它应该执行一个unpin操作,允许在需要时将块取出。
因此我们需要一个pin_couter来记录pin的数量。其实也就是引用计数的思想。
1.2 如何管理页和访问页
一句话基地址+偏移量
page(基地值)+frame_id(偏移量) 实际上就是数组寻址
这里用了hash表来实现page_table来映射page_id和frame_id
2. 实现
2.1 FetchPageImpl 实现
Page *BufferPoolManager::FetchPageImpl(page_id_t page_id)
这个函数的作用就是我们要访问一个page。这个函数可以分为三种情况分析
- 如果该页在缓冲池中直接访问
- 如果该页不在缓冲池但是缓冲池中有空闲。从
disk中取出page然后放入缓冲池之后在访问 - 如果该页不在缓冲池并且缓冲池也非空闲
- 需要找到一个牺牲页。把它移出(判断脏位来决定是否要写会磁盘)
- 然后和情况2一样。
2.2 UnpinPageImpl 实现
bool BufferPoolManager::UnpinPageImpl(page_id_t page_id, bool is_dirty)
函数定义如上。这里的is_dirty主要是对于两种情况
- 情况一。对于读操作而言
is_dirty=false - 情况二。对于写操作而言
is_dirty=true
这个函数就是如果我们这个线程已经完成了对这个页的操作。我们需要unpin以下
如果这个页的
pin_couter>0我们直接--如果这个页的
pin _couter==0我们需要给它加到Lru_replacer中。因为没有人引用它。所以它可以成为被替换的候选人
2.3 FlushPageImpl 实现
bool BufferPoolManager::FlushPageImpl(page_id_t page_id)
这个函数是要把一个page写入磁盘。
- 首先找到这一个页在缓冲池之中的位置
- 写入磁盘
2.4 NewPageImpl 实现
Page *BufferPoolManager::NewPageImpl(page_id_t *page_id)
分配一个新的page。
- 如果缓冲池有空闲位置。则直接放进缓冲池
- 否则的话。如果有页可以被牺牲掉。则牺牲它,把我们的新页放进去
- 否则失败
2.5 DeletePageImpl 实现
bool BufferPoolManager::DeletePageImpl(page_id_t page_id)
这里是要我们把缓冲池中的page移出
- 如果这个page根本就不在缓冲池则直接返回
- 如果这个page 的引用计数大于0(pin_counter>0)表示我们不能返回
- 如果这个page被修改过则要写会磁盘
- 否则正常移除就好了。(在hash表中erase)
3. 源码解析
3.1 ResetMemory()
这个非常简单就是一个简单的内存分配。给我们的frame分配内存区域
3.2 ReadPage
void DiskManager::ReadPage(page_id_t page_id, char *page_data)
void DiskManager::ReadPage(page_id_t page_id, char *page_data) {
int offset = page_id * PAGE_SIZE; //PAGE_SIZE=4kb 先计算偏移。判断是否越界(因为文件大小有限制)
// check if read beyond file length
if (offset > GetFileSize(file_name_)) {
LOG_DEBUG("I/O error reading past end of file");
// std::cerr << "I/O error while reading" << std::endl;
} else {
// set read cursor to offset
db_io_.seekp(offset); //把读写位置移动到偏移位置处
db_io_.read(page_data, PAGE_SIZE); //把数据读到page_data中
if (db_io_.bad()) {
LOG_DEBUG("I/O error while reading");
return;
}
// if file ends before reading PAGE_SIZE
int read_count = db_io_.gcount();
if (read_count < PAGE_SIZE) {
LOG_DEBUG("Read less than a page");
db_io_.clear();
// std::cerr << "Read less than a page" << std::endl;
memset(page_data + read_count, 0, PAGE_SIZE - read_count); //如果读取的数据小于4kb剩下的补0
}
}
}
3.3 WritePage
void DiskManager::WritePage(page_id_t page_id, const char *page_data) {
size_t offset = static_cast<size_t>(page_id) * PAGE_SIZE; //先计算偏移
// set write cursor to offset
num_writes_ += 1; //记录写的次数
db_io_.seekp(offset);
db_io_.write(page_data, PAGE_SIZE); //向offset处写data
// check for I/O error
if (db_io_.bad()) {
LOG_DEBUG("I/O error while writing");
return;
}
// needs to flush to keep disk file in sync
db_io_.flush(); //刷新缓冲区
}
3.4 DiskManager 构造函数
就是获取文件指针
DiskManager::DiskManager(const std::string &db_file)
: file_name_(db_file), next_page_id_(0), num_flushes_(0), num_writes_(0), flush_log_(false), flush_log_f_(nullptr) {
std::string::size_type n = file_name_.rfind('.');
if (n == std::string::npos) {
LOG_DEBUG("wrong file format");
return;
}
log_name_ = file_name_.substr(0, n) + ".log";
log_io_.open(log_name_, std::ios::binary | std::ios::in | std::ios::app | std::ios::out);
// directory or file does not exist
if (!log_io_.is_open()) {
log_io_.clear();
// create a new file
log_io_.open(log_name_, std::ios::binary | std::ios::trunc | std::ios::app | std::ios::out);
log_io_.close();
// reopen with original mode
log_io_.open(log_name_, std::ios::binary | std::ios::in | std::ios::app | std::ios::out);
if (!log_io_.is_open()) {
throw Exception("can't open dblog file");
}
}
db_io_.open(db_file, std::ios::binary | std::ios::in | std::ios::out); //获取文件指针。并且打开输入输出流
// directory or file does not exist
if (!db_io_.is_open()) {
db_io_.clear();
// create a new file
db_io_.open(db_file, std::ios::binary | std::ios::trunc | std::ios::out);
db_io_.close();
// reopen with original mode
db_io_.open(db_file, std::ios::binary | std::ios::in | std::ios::out);
if (!db_io_.is_open()) {
throw Exception("can't open db file");
}
}
buffer_used = nullptr;
}
4. 测试
cd build
make buffer_pool_manager_test
./test/buffer_pool_manager_test
CMU数据库(15-445)Lab1-BufferPoolManager的更多相关文章
- CMU数据库(15-445)Lab0-环境搭建
0.写在前面 从这篇文章开始.开一个新坑,记录以下自己做cmu数据库实验的过程,同时会分析一下除了要求我们实现的代码之外的实验自带的一些代码.争取能够对实现一个数据库比较了解.也希望能写进简历.让自己 ...
- CMU数据库(15-445)实验2-b+树索引实现(上)
Lab2 在做实验2之前请确保实验1结果的正确性.不然你的实验2将无法正常进行 环境搭建地址如下 https://www.cnblogs.com/JayL-zxl/p/14307260.html 实验 ...
- CMU数据库(15-445)-实验2-B+树索引实现(中)删除
3. Delete 实现 附上实验2的第一部分 https://www.cnblogs.com/JayL-zxl/p/14324297.html 3. 1 删除算法原理 如果叶子结点中没有相应的key ...
- CMU数据库(15-445)实验2-B+树索引实现(下+课上笔记)
4. Index_Iterator实现 这里就是需要实现迭代器的一些操作,比如begin.end.isend等等 下面是对于IndexIterator的构造函数 template <typena ...
- [已完结]CMU数据库(15-445)实验2-B+树索引实现(下)
4. Index_Iterator实现 这里就是需要实现迭代器的一些操作,比如begin.end.isend等等 下面是对于IndexIterator的构造函数 template <typena ...
- CMU数据库(15-445)Lab3- QUERY EXECUTION
Lab3 - QUERY EXECUTION 实验三是添加对在数据库系统中执行查询的支持.您将实现负责获取查询计划节点并执行它们的executor.您将创建执行下列操作的executor Access ...
- CMU数据库(15-445) Lab4-CONCURRENCY CONTROL
Lab4- CONCURRENCY CONTROL 拖了很久终于开始做实验4了.lab4有三个大任务1. Lock Manager.2. DEADLOCK DETECTION .3. CONCURRE ...
- CMU 15-445 数据库课程第四课文字版 - 存储2
熟肉视频地址: CMU数据库管理系统课程[熟肉]4.数据库存储结构2(上) CMU数据库管理系统课程[熟肉]4.数据库存储结构2(下) 1. 面向日志的存储 上节课我们讲完了面向元组的存储,这节课从面 ...
- linux操作mysql数据库常用简单步骤
连接mysql数据库: 主要看mysql安装在哪一个目录下: mysql -h主机地址 -u用户名 -p用户密码 或者mysql -h ip地址 -u zaiai -p zaiai 或者/v ...
随机推荐
- Maven项目中配置jdk版本
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> ...
- css3选择器归类整理---基本选择器和属性选择器
css3选择器分类 CSS3选择器分类如下图所示 选择器的语法 1.基本选择器 类型 代码 功能描述 通配选择器 *{ margin: 0; padding: 0; border: none; } 选 ...
- C# 如何查询字符串前面有几个0
有几个0 string t = "0001203"; int tLen = t.Length - t.TrimStart('0').Length; charAt方法 using S ...
- 怎么同步fork原git项目
如何实现 有时候,我们看到有价值的git项目,通常,我们会选择把原项目fork过来,然后自己去把玩研究.然而,原项目进行了更新,fork过来的代码却还是原来的版本,那有没有什么做法,能同时更新到我自己 ...
- 《改善python程序的91个建议》读书笔记
推荐 <改善Pthon程序的91个建议>是从基本原则.惯用方法.语法.库.设计模式.内部机制.开发工具和性能优化8个方面深入探讨编写高质量python代码的技巧.禁忌和最佳实践. 读书就如 ...
- JPA 缓存
JPA有两种类型的缓存: EntityManager自身就是一种缓存.事务中从数据库获取的和写入到数据库的数据会被缓存(什么样的数据会被缓存,在后面有介绍).在一个程序中也许会有很多个不同的Entit ...
- FaaS,未来的后端服务开发之道
说 FaaS 先要说说 PaaS 平台即服务(Platform as a Service)是一种云计算服务,提供运算平台与解决方案堆栈即服务.在云计算的典型层级中,平台即服务层介于软件即服务与基础设施 ...
- C语言测一个浮点数的位数长度
测浮点数的位数牵扯到一个精度的问题,用普通的测整形数值的方法不能实现,于是我自己写了一个测浮点数的函数. #include <stdio.h> //for printf int lengt ...
- Java学习日报7.26
package leijia;import java.util.*;public class Sum { public static void main(String[] args) { // TOD ...
- VS使用过程中可能会遇到的问题
Q:某个类无法引用命名空间 A:可能是类名与文件夹名重复了