并发编程之synchronized(二)------jvm对synchronized的优化
一、锁的粗化
看如下代码
public class Test {
StringBuffer stb = new StringBuffer();
public void test1(){
//jvm的优化,锁的粗化
stb.append("1");
stb.append("2");
stb.append("3");
stb.append("4");
}
首先我们要清除StringBuffer是线程安全的,因为它在每一个方法上都加了synchronized锁,下图是StringBuffer的源码

按照正常的理解synchronized是对当前对象加锁,那么我们调用了四次append方法,那么jvm是将这把对象锁加了四次吗?如下图:

那这样的化,jvm就需要加四次锁,当然也要释放四次锁,频繁加解锁引起线程上下文的切换,非常消耗性能,所以jvm做了优化,只加一次锁,叫做锁的粗化,可以理解为将锁的颗粒度放大

二、锁的消除
如图看下面代码
public void test2(){
//jvm的优化,JVM不会对同步块进行加锁
synchronized (new Object()) {
//伪代码:很多逻辑
//jvm是否会加锁?
//jvm会进行逃逸分析
}
}
这个地方加锁等于没有加锁,因为每个线程都会new object,大家都不会用同一把锁,jvm分析优化后不会对这种代码加锁(逃逸分析),所以,我们平时加锁一定要注意,加锁要加同一把锁。
三、锁的膨胀升级
1、锁的升级
synchronized的锁的状态总共有四种,无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁,但是锁的升级是单向的,也就是说只能从低到高升级,锁状态的升级不可逆。
JDK1.6版本之后对synchronized的实现进行了各种优化,如自旋锁、偏向锁和轻量级锁 并默认开启偏向锁 开启偏向锁:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 关闭偏向锁:-XX:-UseBiasedLocking。如果直接上来就是重量级锁,那么实在是太消耗资源了。
2、锁的状态记录在哪里

3、对锁的理解:
4、锁的膨胀升级过程
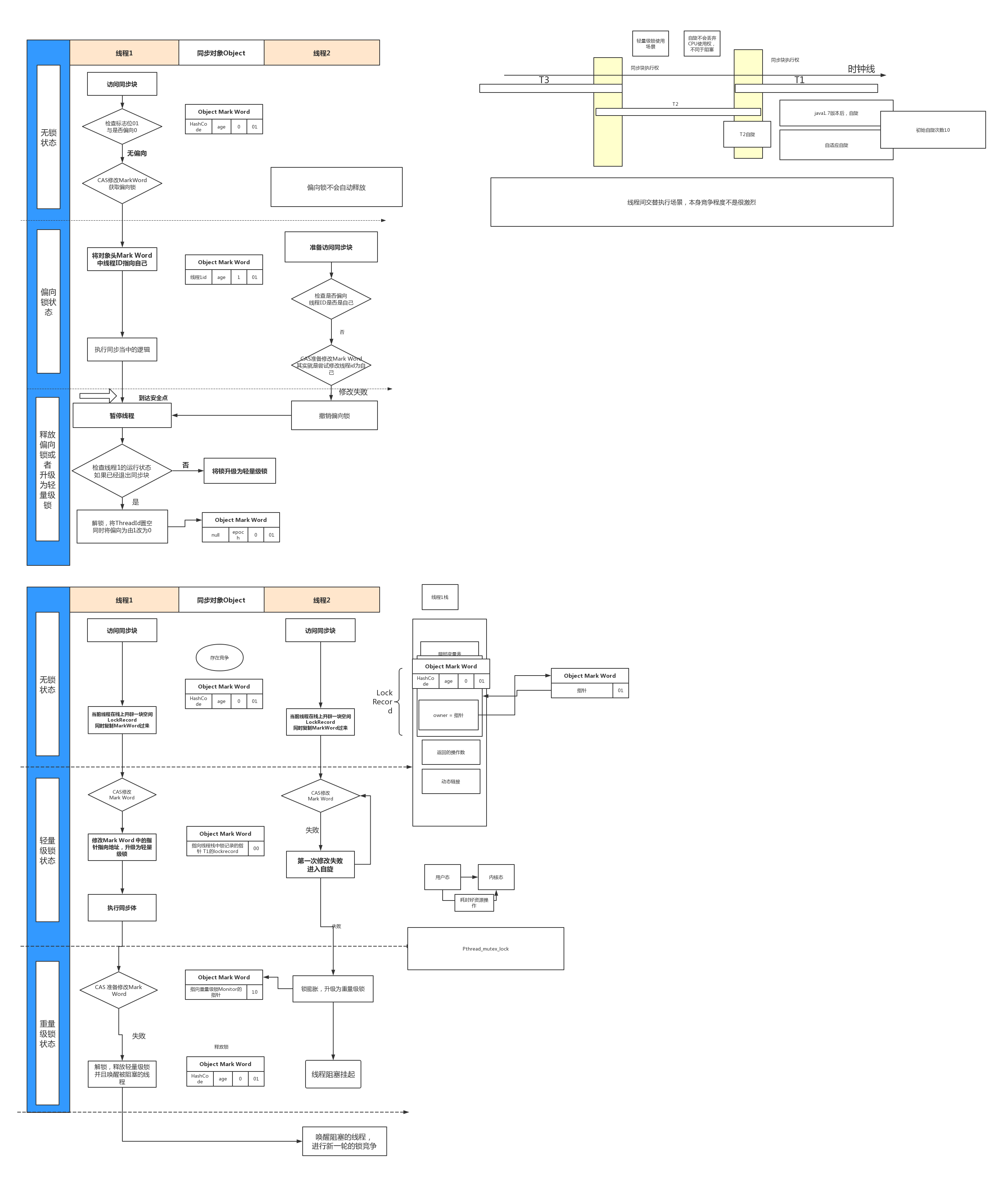
注意一下几点:
线程1获取轻量级锁后会将Object Mark Word 复制自己的一份到自己的栈空间,然后在自己的栈空间开辟一个指针lockerecord 指向Object Mark Word,同时Object Mark Word也会指向lockerecord,当线程1执行完代码块释放轻量级锁之后,发现Object Mark Word不在指向自己,说明当前锁已经改为重量级锁,那么它会唤醒阻塞队列中所有线程重新竞争锁。
总结:偏向锁,轻量级锁都是基于Object Mark Word的标记实现,java尽可能避免使用重量级锁。
并发编程之synchronized(二)------jvm对synchronized的优化的更多相关文章
- Java并发编程之CAS二源码追根溯源
Java并发编程之CAS二源码追根溯源 在上一篇文章中,我们知道了什么是CAS以及CAS的执行流程,在本篇文章中,我们将跟着源码一步一步的查看CAS最底层实现原理. 本篇是<凯哥(凯哥Java: ...
- 并发编程之ThreadLocal、Volatile、synchronized、Atomic关键字扫盲
前言 对于ThreadLocal.Volatile.synchronized.Atomic这四个关键字,我想一提及到大家肯定都想到的是解决在多线程并发环境下资源的共享问题,但是要细说每一个的特点.区别 ...
- Java并发编程之CAS第三篇-CAS的缺点及解决办法
Java并发编程之CAS第三篇-CAS的缺点 通过前两篇的文章介绍,我们知道了CAS是什么以及查看源码了解CAS原理.那么在多线程并发环境中,的缺点是什么呢?这篇文章我们就来讨论讨论 本篇是<凯 ...
- python并发编程之multiprocessing进程(二)
python的multiprocessing模块是用来创建多进程的,下面对multiprocessing总结一下使用记录. 系列文章 python并发编程之threading线程(一) python并 ...
- 并发编程之J.U.C的第二篇
并发编程之J.U.C的第二篇 3.2 StampedLock 4. Semaphore Semaphore原理 5. CountdownLatch 6. CyclicBarrier 7.线程安全集合类 ...
- 并发编程之:CountDownLatch
大家好,我是小黑,一个在互联网苟且偷生的农民工. 先问大家一个问题,在主线程中创建多个线程,在这多个线程被启动之后,主线程需要等子线程执行完之后才能接着执行自己的代码,应该怎么实现呢? Thread. ...
- Java并发编程之CAS
CAS(Compare and swap)比较和替换是设计并发算法时用到的一种技术.简单来说,比较和替换是使用一个期望值和一个变量的当前值进行比较,如果当前变量的值与我们期望的值相等,就使用一个新值替 ...
- 并发编程之wait()、notify()
前面的并发编程之volatile中我们用程序模拟了一个场景:在main方法中开启两个线程,其中一个线程t1往list里循环添加元素,另一个线程t2监听list中的size,当size等于5时,t2线程 ...
- 并发编程之:JMM
并发编程之:JMM 大家好,我是小黑,一个在互联网苟且偷生的农民工. 上一期给大家分享了关于Java中线程相关的一些基础知识.在关于线程终止的例子中,第一个方法讲到要想终止一个线程,可以使用标志位的方 ...
- 并发编程之:ThreadLocal
大家好,我是小黑,一个在互联网苟且偷生的农民工. 从前上一期[并发编程之:synchronized] 我们学到要保证在并发情况下对于共享资源的安全访问,就需要用到锁. 但是,加锁通常情况下会让运行效率 ...
随机推荐
- 【环境安装】Docker安装
[环境安装]Docker安装 CentoOS-7 安装步骤: 1.卸载已经安装的Docker sudo yum remove docker \ docker-client \ docker-clien ...
- c++. Run-Time Check Failure #2 - Stack around the variable 'cc' was corrupted.
Run-Time Check Failure #2 - Stack around the variable 'cc' was corrupted. char cc[1024]; //此处如果索引值 ...
- Quartz.Net系列(六):Quartz五大构件Trigger之TriggerBuilder解析
所有方法图: 1.Create.Build Create:创建一个TriggerBuilder Build:生成Trigger var trigger = TriggerBuilder.Create( ...
- 总结下c/c++的一些调试经验
工作2年,干了一年ARM平台嵌入式,一年后台,总结下这两年开发中调试的经验.我把调试手段分成2种:打印日志和用工具分析.因为平时主要开发在Linux平台,就以GDB为例 一.打印日志 1. 合理设置日 ...
- git常用代码合集
git常用代码合集 1. Git init:初始化一个仓库 2. Git add 文件名称:添加文件到Git暂存区 3. Git commit -m “message”:将Git暂存区的代码提交到Gi ...
- linux网络编程-socket(37)
在编程的时候需要加上对应pthread开头的头文件,gcc编译的时候需要加了-lpthread选项 第三个参数是线程的入口参数,函数的参数是void*,返回值是void*,第四个参数传递给线程函数的参 ...
- python list遍历方法汇总
list=['a','b','c','d','e'] #方法1: print('#方法1:') #i值为列表的item,list为列表名,因此i值即为列表元素 for i in list: #list ...
- 状态机模式 与 ajax 的结合运用
太神奇了,昨晚做了个梦,梦中我悟出一个道理:凡是涉及到异步操作而且需要返回值的函数,一定要封装成 Promise 的形式,假如返回值取决于多个异步操作的结果,那么需要对每个异步操作进行状态的设计,而且 ...
- Pikachu靶场SQL注入刷题记录
数字型注入 0x01 burp抓包,发送至repeater 后面加and 1=1,and 1=2 可判断存在注入 0x02 通过order by判断字段数,order by 2 和order by 3 ...
- Python实用笔记 (18)面向对象编程——类和实例
类和实例 面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Student类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各 ...