如何在Elasticsearch中解析未分配的分片(unassigned shards)
一、精确定位到有问题的shards
1、查看哪些分片未被分配
- curl -XGET localhost:9200/_cat/shards?h=index,shard,prirep,state,unassigned.reason| grep UNASSIGNED
2、如果您运行的是Elasticsearch的5+版本,您还可以使用群集分配说明API来尝试获取有关分片分配问题的更多信息:
- curl -XGET localhost:9200/_cluster/allocation/explain?pretty
生成的输出将提供有关群集中某些分片未分配的原因的有用详细信息:
- {
- "index" : "testing",
- "shard" : 0,
- "primary" : false,
- "current_state" : "unassigned",
- "unassigned_info" : {
- "reason" : "INDEX_CREATED",
- "at" : "2018-04-09T21:48:23.293Z",
- "last_allocation_status" : "no_attempt"
- },
- "can_allocate" : "no",
- "allocate_explanation" : "cannot allocate because allocation is not permitted to any of the nodes",
- "node_allocation_decisions" : [
- {
- "node_id" : "t_DVRrfNS12IMhWvlvcfCQ",
- "node_name" : "t_DVRrf",
- "transport_address" : "127.0.0.1:9300",
- "node_decision" : "no",
- "weight_ranking" : 1,
- "deciders" : [
- {
- "decider" : "same_shard",
- "decision" : "NO",
- "explanation" : "the shard cannot be allocated to the same node on which a copy of the shard already exists"
- }
- ]
- }
- ]
- }
二、Elasticsearch中解析未分配的各个原因解析
1、故意分配碎片分配
当节点离开集群时,主节点暂时延迟分片重新分配,以避免在原始节点能够在特定时间段(默认为一分钟)内恢复时不必要地在重新平衡分片上浪费资源。如果是这种情况,您的日志应如下所示:
- [TIMESTAMP][INFO][cluster.routing] [MASTER NODE NAME] delaying allocation for [54] unassigned shards, next check in [1m]
解决办法:动态修改延迟时间
- curl -XPUT 'localhost:9200/<INDEX_NAME>/_settings' -d
- '{
- "settings": {
- "index.unassigned.node_left.delayed_timeout": "30s"
- }
- }'
2、分片太多,节点不够
当节点加入和离开集群时,主节点会自动重新分配分片,确保分片的多个副本未分配给同一节点。换句话说,主节点不会将主分片分配给与其副本相同的节点,也不会将同一分片的两个副本分配给同一节点。如果没有足够的节点来相应地分配分片,则分片可能会停留在未分配状态。
要避免此问题,请确保使用以下公式初始化群集中的每个索引,每个主分片的副本数少于群集中的节点数:
- N >= R + 1
其中N是群集中的节点数,R是群集中所有索引的最大分片复制因子。
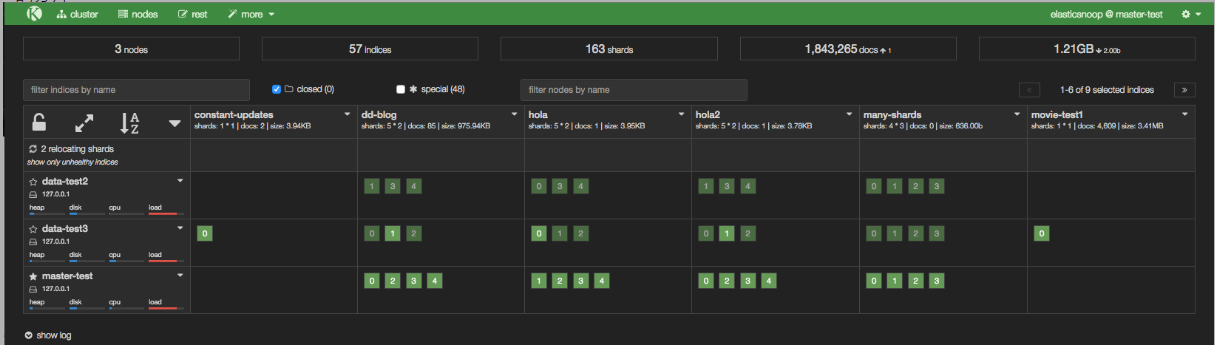
在下面的屏幕截图中,many-shards索引存储在四个主分片上,每个主分片有四个副本。索引的20个分片中有8个未分配,因为我们的群集只包含三个节点。尚未分配每个主分片的两个副本,因为三个节点中的每个节点都已包含该分片的副本。

解决办法:可以向群集添加更多数据节点或减少副本数。这里我们通过减少副本数的方式解决:
- curl -XPUT 'localhost:9200/<INDEX_NAME>/_settings' -d '{"number_of_replicas": 2}'
减少副本数量后,查看Kopf以查看是否已分配所有分片。
3、加入一个新的节点,需要重新启用分片分配
在下面的截屏中,一个节点刚加入集群,但尚未分片任何分片
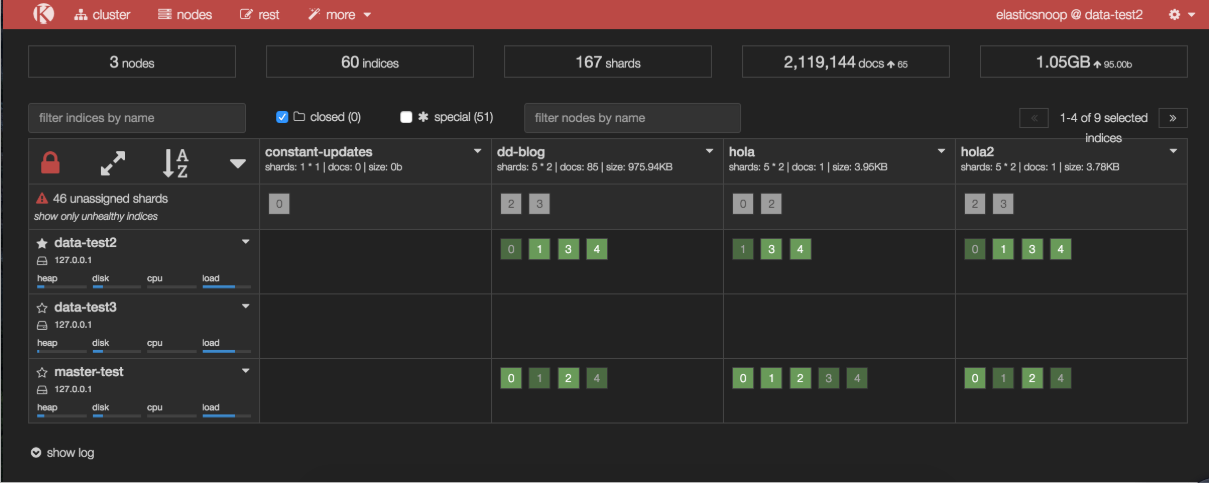
默认情况下,在所有节点上启用分片分配,但您可能在某些时候禁用了分片分配(例如,为了执行滚动重新启动),并且忘记重新启用它。
要启用分片分配,请更新群集设置API:
- curl -XPUT 'localhost:9200/_cluster/settings' -d
- '{ "transient":
- { "cluster.routing.allocation.enable" : "all"
- }
- }'
4、集群中不在存在分片数据
在这种情况下,constant-updates索引的主分片0 是未分配的。它可能是在没有任何副本的节点上创建的(一种用于加速初始索引过程的技术),并且节点在可以复制数据之前离开了集群。主服务器在其全局集群状态文件中检测分片,但无法在集群中找到分片的数据。
另一种可能性是节点在重新启动时可能遇到问题。通常,当节点恢复其与群集的连接时,它会将有关其磁盘分片的信息中继到主服务器,然后主服务器将这些分片从“未分配”转换为“已分配/已启动”。当此过程由于某种原因(例如,节点的存储已经以某种方式损坏)失败时,分片可能保持未分配状态。
在这种情况下,您必须决定如何继续:尝试让原始节点恢复并重新加入群集(并且不强制分配主分片),或者使用Reroute API强制分配分片并使用重新索引丢失的数据原始数据源,或来自备份。
如果您决定分配未分配的主分片,请确保将该"allow_primary": "true"标志添加到请求中:
- curl -XPOST 'localhost:9200/_cluster/reroute' -d
- '{ "commands" :
- [ { "allocate" :
- { "index" : "constant-updates", "shard" : 0, "node": "<NODE_NAME>", "allow_primary": "true" }
- }]
- }'
没有"allow_primary": "true"标志,我们会遇到以下错误:
- {"error":{"root_cause":[{"type":"remote_transport_exception","reason":"[NODE_NAME][127.0.0.1:9301][cluster:admin/reroute]"}],"type":"illegal_argument_exception","reason":"[allocate] trying to allocate a primary shard [constant-updates][0], which is disabled"},"status":400}
强制分配主分片的警告是你将分配一个“空”分片。如果包含原始主分片数据的节点稍后将重新加入群集,则其数据将被新创建的(空)主分片覆盖,因为它将被视为数据的“较新”版本。
您现在需要重新索引丢失的数据,或使用快照和还原API从备份快照中尽可能多地还原。
5、磁盘水印低(Low disk watermark)
如果没有足够的磁盘空间节点,主节点可能无法分配分片(它不会将分片分配给使用率超过85%的磁盘的节点)。一旦节点达到此磁盘使用级别,或Elasticsearch称为“低磁盘水印”,将不会为其分配更多分片。
您可以通过查询cat API来检查群集中每个节点上的磁盘空间(并查看每个节点上存储的分片):
- curl -s 'localhost:9200/_cat/allocation?v'
如果任何特定节点的磁盘空间不足(删除过时的数据并将其存储在群集外,添加更多节点,升级硬件等),请参阅此文章以获取有关如何操作的选项。
如果您的节点具有大磁盘容量,则85%的低水印可能太低。您可以使用群集更新设置API进行更改cluster.routing.allocation.disk.watermark.low和/或cluster.routing.allocation.disk.watermark.high。例如,此Stack Overflow线程指出,如果您的节点具有5TB磁盘容量,则可以安全地将低磁盘水印增加到90%:
- curl -XPUT 'localhost:9200/_cluster/settings' -d
- '{
- "transient": {
- "cluster.routing.allocation.disk.watermark.low": "90%"
- }
- }'
如果希望在群集重新启动时保持配置更改,请将“transient”替换为“persistent”,或者在配置文件中更新这些值。您可以选择使用字节或百分比值来更新这些设置,但请务必记住Elasticsearch文档中的这一重要说明:“百分比值是指已用磁盘空间,而字节值是指可用磁盘空间。”
如何在Elasticsearch中解析未分配的分片(unassigned shards)的更多相关文章
- Elasticsearch强制重置未分配的分片(unassigned)
强制重置未分片的分片,这个问题源自于Elasticsearch维护中,Node意外退出的场景. 意外退出后Elasticsearch由于网络原因或者jvm性能压力,未能短时间内分配分片. 看一下分片的 ...
- 为何在查询中索引未被使用 (Doc ID 1549181.1)
To Bottom * 为何在查询中索引未被使用 (Doc ID 1549181.1) To Bottom 文档内容 用途 排错步骤 高速检查 表上是否存在索引? 索引是否应该 ...
- 面试官问我:如何在 Python 中解析和修改 XML
摘要:我们经常需要解析用不同语言编写的数据.Python提供了许多库来解析或拆分用其他语言编写的数据.在此 Python XML 解析器教程中,您将学习如何使用 Python 解析 XML. 本文分享 ...
- 如何在Elasticsearch中安装中文分词器(IK+pinyin)
如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题--中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组. ...
- Elasticsearch之如何合理分配索引分片
大多数ElasticSearch用户在创建索引时通用会问的一个重要问题是:我需要创建多少个分片? 在本文中, 我将介绍在分片分配时的一些权衡以及不同设置带来的性能影响. 如果想搞清晰你的分片策略以及如 ...
- Elasticsearch节点下线(退役)and unassigned shards
一.节点退役当集群中个别节点出现故障预警等情况,需要进行退役工作,即让所有位于该退役节点上的分片的数据分配到其他节点上后,再将此节点关闭并从集群中移除. 1.ES提供了让某个节点上所有数据都移走的功能 ...
- 如何在FineReport中解析数据库内XML文件
在数据库表中,其中字段XML所存的为xml格式数据在表xmltest中.那么在使用该表进行报表制作时,需要将存于xml字段中的值读取出来作为报表数据源. XML每条记录数据格式如下: <Fiel ...
- 数组如何在ElasticSearch中索引
一.简介 在ElasticSearch里没有专门的数组类型,任何一个字段都可以有零个和多个值.当字段值的个数大于1时,字段类型就变成了数组. 下面以视频数据为例,介绍ElasticSearch如何索引 ...
- 如何在elasticsearch中查看Logstash打到elasticsearch的数据
# cat syslog02.conf #filename:syslog02.conf #注意这个是要用#号注释掉 input{ file{ path => ["/var/log/*. ...
随机推荐
- 手机APP测试(测试点、测试流程、功能测试)
1.功能测试 1.1 启动 APP安装完成后,是否可以正常打开,稳定运行 APP的速度是可以让人接受,切换是否流畅 网络异常时,应用是否会崩溃:在请求超时的情况下,如果程序逻辑处理的不好,就有可能发生 ...
- 公司只提供签名服务,不提供证书文件,如何打包Electron应用
需求 稍微正规点的公司,都要为自己开发的软件做代码签名,如下图所示 代码签名的主要目的是为了确保软件的来源(这个软件是由谁生产的)和软件的内容不被篡改 一个软件公司可能有很多团队,很多开发者,开发不同 ...
- cglib、orika、spring等bean copy工具性能测试和原理分析
简介 在实际项目中,考虑到不同的数据使用者,我们经常要处理 VO.DTO.Entity.DO 等对象的转换,如果手动编写 setter/getter 方法一个个赋值,将非常繁琐且难维护.通常情况下,这 ...
- 题解 CF1437G Death DBMS
这题感觉不是很难,但是既然放在 \(\texttt{EDU}\) 的 \(\texttt{G}\) 题,那么还是写写题解吧. \(\texttt{Solution}\) 首先看到 "子串&q ...
- 题解-FJOI2018 领导集团问题
题面 FJOI2018 领导集团问题 给一棵树 \(T(|T|=n)\),每个点有个权值 \(w_i\),从中选出一个子点集 \(P=\{x\in {\rm node}|x\in T\}\),使得 \ ...
- 算法——K 个一组翻转链表
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表. k 是一个正整数,它的值小于或等于链表的长度. 如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序. 示例: 给你这个 ...
- redis学习之——redis.conf配置(基本)文件学习
# Redis configuration file example # Note on units: when memory size is needed, it is possible to sp ...
- KafkaMirrorMaker 的不足以及一些改进
背景 某系统使用 Kafka 存储实时的行情数据,为了保证数据的实时性,需要在多地机房维护多个 Kafka 集群,并将行情数据同步到这些集群上. 一个常用的方案就是官方提供的 KafkaMirrorM ...
- Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=Mypc, access=WRITE, inode="/":fan:supergroup:drwxr-xr-x
在window上编程提示没有写Hadoop的权限 Exception in thread "main" org.apache.hadoop.security.AccessContr ...
- Python-自动化测试面试
1.以你做过的项目,举例来说一下你的自动化测试是怎么做的? 参考答案:就拿简历上的ecshop项目来说吧,在编写脚本前,我们会对系统进行评估,确认这个系统可不可以实现UI自动化,如果可以的话,就筛选出 ...