实时离线一体化在资产租赁saas服务中使用
流水查询需求
- 需求第一期:
基于TB级的在线数据,支持缴费帐单明细在线查询。大家都知道,像银行帐单流水一样,查几年的流水是常有的事。
支持的维度查询:帐期、欠费状态、日期范围、费用科目类型、房屋分类、房屋所属项目、关联合同信息、统计列
什么是实时数据
实时可以分为:实时采集、实时计算、高性能,底延时的产出结果数据。实时数据指从源系统中实时采集的数据,以及对实时采集的数据进行实时计算直接产生的中间数据或结果数据。实时数据具有时间有效性,随着时间的推移,实时数据会失效。
即时查询系统
房屋租赁费用、水电费用、物业管理费用等数据的有效期,一般是不定的,比如办公租赁可能预交费用5年、10年。那么这种数据,对于业务来说,仍然属于线上数据,是不可归档的数据。 长时间无法归档数据,会造成数据越积越大,对于轻量级数据库MySQL来说,是个很大的挑战。就算做好分库分表的准备。条件复杂的查询在聚合的时候也一样容易搞爆内存。何况系统在dal层设计得有所欠缺。为满足流水查询而重构,太得不偿失。从需求来看,不涉及OLTP,只需实现OLAP的解决方案。为了不影响业务系统的改造、数据库重构等方面。决定引入了即时查询系统解决方案。

业务需求转化技术需求:
- 帐单明细查询可由七十多个条件的随机组合,不能使用类似kylin这样的预处理技术来解决。支持N年范围的在线查询
- 支持复杂条件查询,如:联合多表,嵌套多层left join
- 为减少业务侧的sql改动量,需要尽可能的支持标准SQL
- 频繁变更的业务数据需要实时同步更新
根据以上技术需求点和经过技术的筛选后,最终的技术架构是这样的:
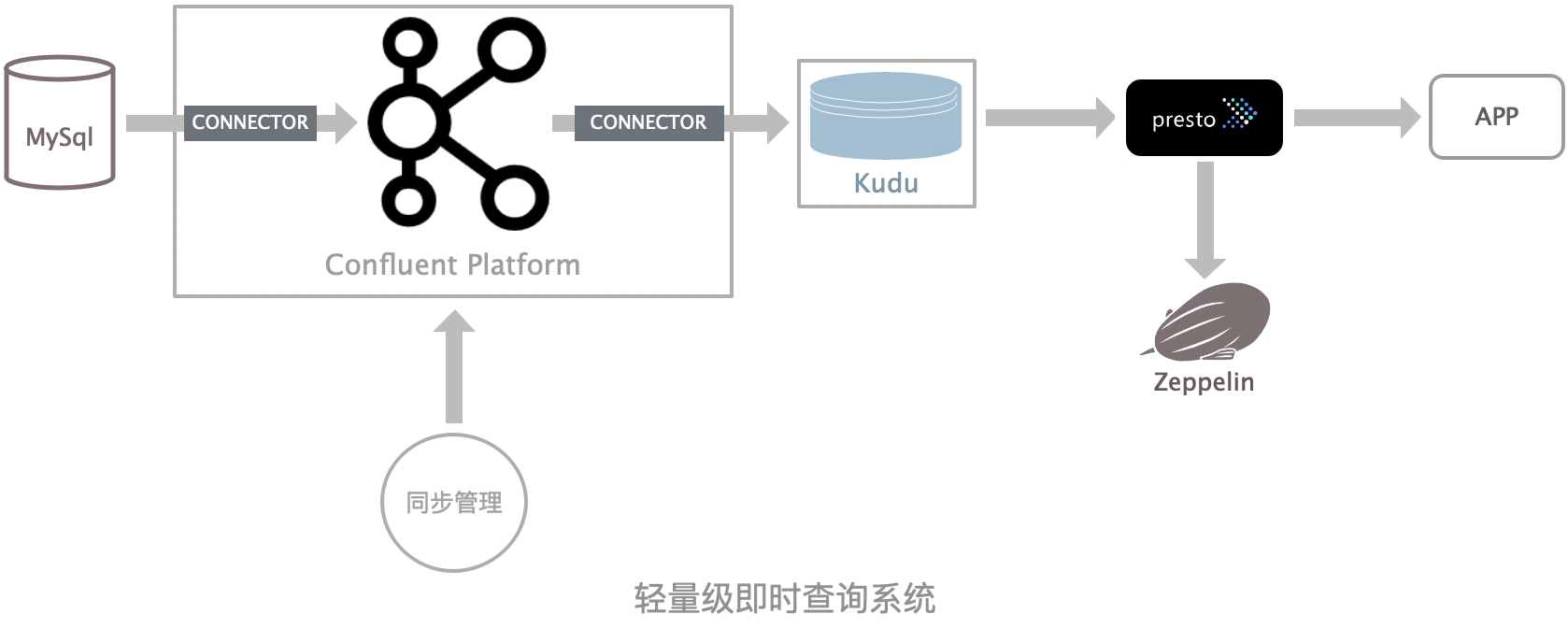
架构实现
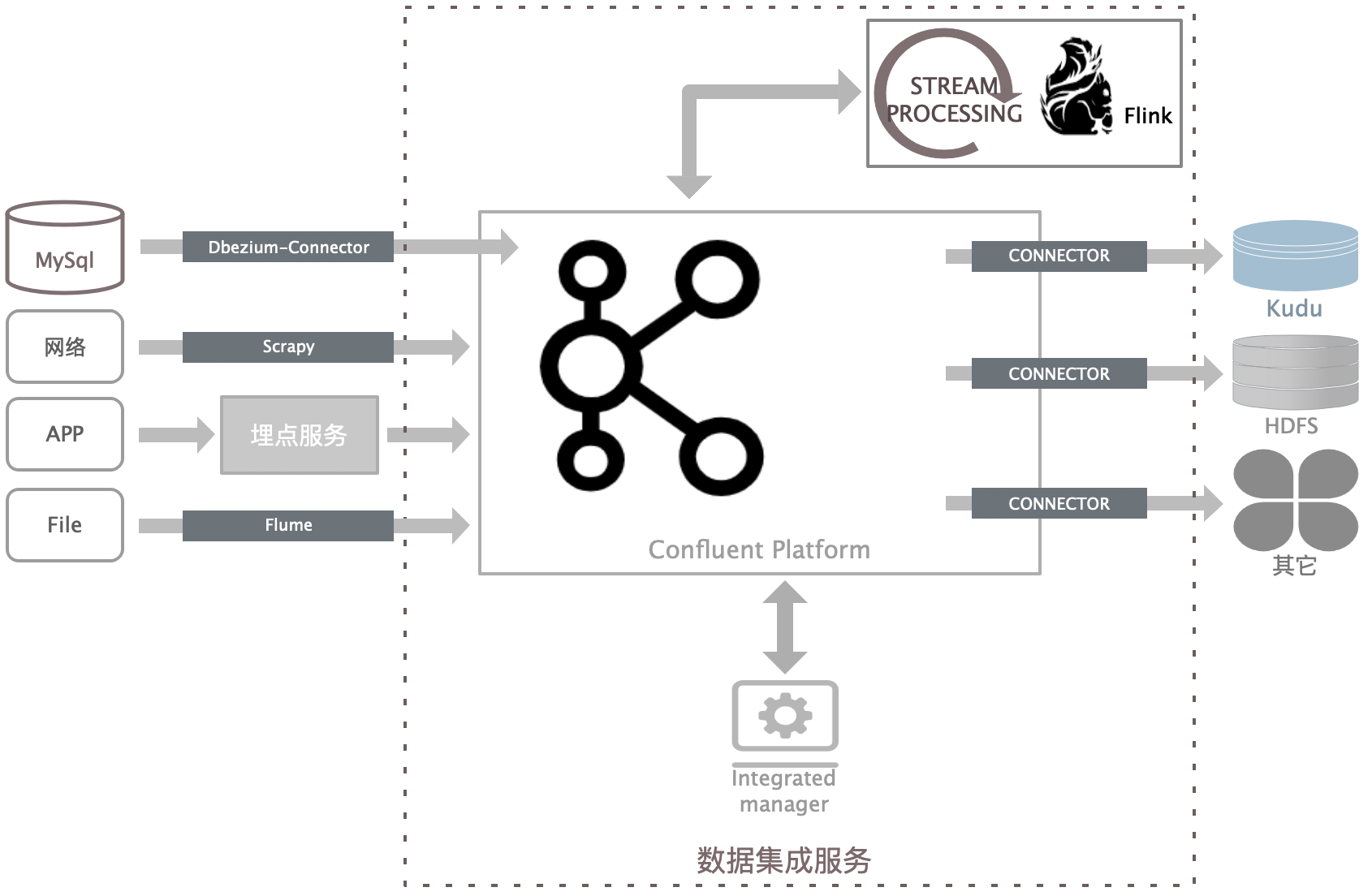
数据实时同步—Confluent Platform架构实现
debezuim:业务库使用的是MySql,如果在即时查询系统中查询到的结果与业务系统查询结果同等,需要实时同步业务数据,并实时提供查询能力。debezium是一个低延迟的流式处理工具,能够捕获数据库更改,并且利用Kafka和Kafka Connect记录到kafka中,实现了自己的持久性、可靠性和容错性。
Confluent Platform:Mysql到Kudu,需要稳定高效、可弹性伸缩、在异构数据源之间高速稳定同步能力的数据集成解决方案。基于红火的kafka之上,Kafka Connect是首选。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。当在distributed的工作模式下,具有高扩展性,和自动容错机制。confluent platform支持了很多Kafka connect的实现,为后续扩展数据集成服务提供了便利,debezium-connector就是其中之一。除此之外,confluent platform使用Kafka Schema Registry提供Avro序列化支持,为序列化提高了性能。但是Confluent平台的社区版本提供的功能还是比较有限的,比如提供监控界面化管理的confluent center是属于商业版的。为此,我们自研了含有监控运维功能的《数据集成服务》,后续文章将详细介绍并提供在线体验。
Kudu-connector:confluent platform中虽然提供了Kudu Connector (Source and Sink),但是需要依赖Impala和Hive。而从需求和架构上看,并不需要这些东西,为遵守轻量原则、为避免太多依赖,我们自己实现了轻量级的Kudu-connector(源码地址:https://github.com/dengbp/big-well)。Kudu-Connector需要借助同步管理配置好需要同步的表、同步规则,并创建好目标表,最后创建连接器同步数据。Kudu-Connector暂时没有自动创建目标表能力。下个版本实现。

(网络图)
实时数仓—kudu
分布式列式存储,支持行级更新,在OLAP场景下,能快速处理,跟其它大数据框架紧密集成(下文会与Hive Metastore集成,为上层开发访问下层数据的提供统一入口),本身既具有高可用性,又是Cloudera家族的大数据生态圈成员,为系统自身扩展提供了极大空间。本次需求,主要是同步帐单表数据,和帐单查询信息用到的关联表数据,如:租赁合同数据、项目数据、房屋数据、帐单类型等数据。从业务数据特点分析,需要对帐单表ID和帐单类型做哈希分区,对帐单创建时间做范围分区来创建帐单目标表,这样既可以实现数据分布均匀,又可以在每个分片中保留指定的数据,同时对时间分区继续扩展。其它关联的数据表,根据查询关联特点,同样使用哈希分区和范围分区组合。
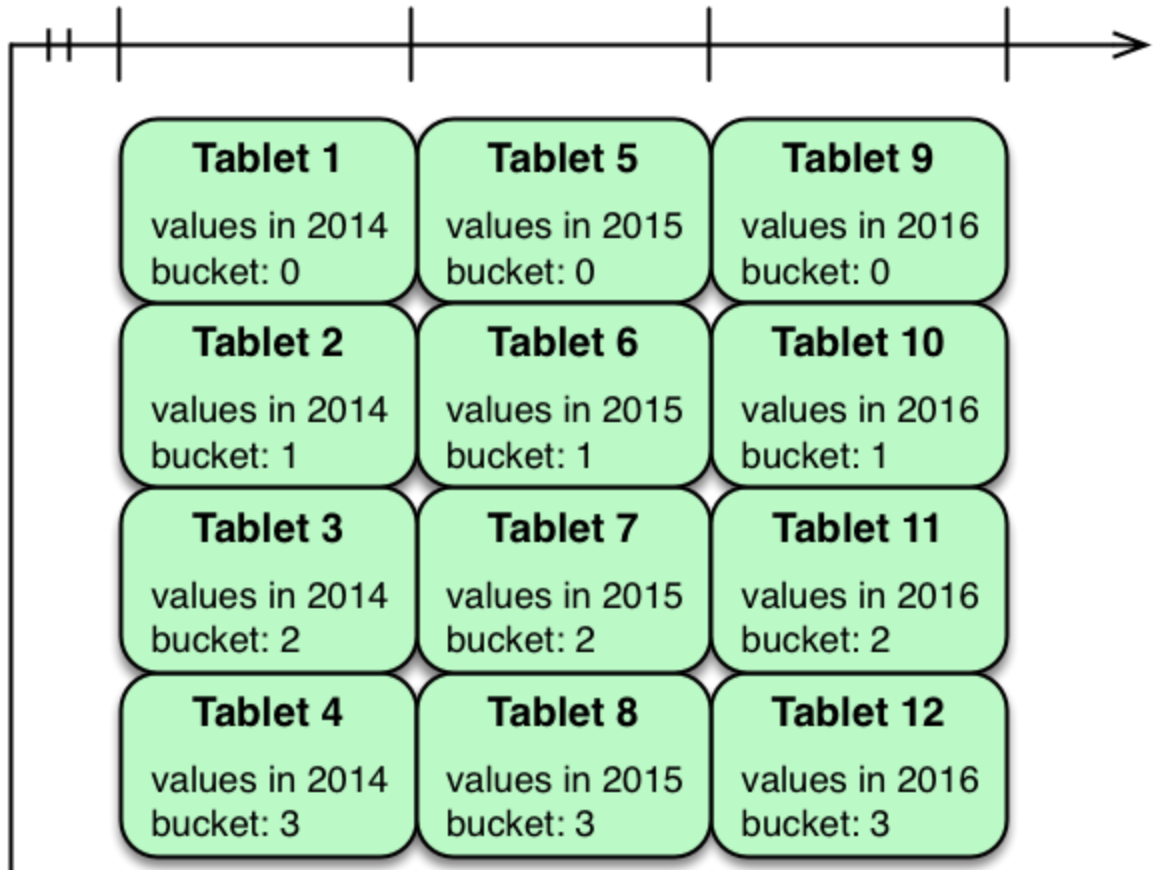
(网络图)
查询引擎—实现秒级响应—Presto
不依赖hive元数据服务,部署简单。在sql语法方面,虽然存在小部分与标准相违背(如:分页需要 ORDER BY、时间比较需要用TIMESTAMP先转换等),但整体支持标准sql度极高。这对于当前业务系统改动成本小。业务接入时,除了部分sql在性能上需要做优化外,只需要配置多个JDBC数据源即可。这只是理想状态,由于整个业务系统使用的是msyql数据库,所以慢长的开发过程中,难免会用到mysql特有的语法,这就造成更麻烦的sql兼容问题。在这方面,我们选择对官方提供的presto-jdbc做二开,使其尽可能多的支持mysql语法,如group by、时间大小比较等。

扩大业务覆盖率
由最初的帐单明细查询,发展成整个平台通用的即时查询系统。所有涉及OLAP查询,TB级以上的数据都接入了即时查询系统。服务部署也由原来的十几个节点,发展到了三十多个节点。
| 部署配置 | ||
| 服务名称 | 节点数 | 配置 |
| Confluent Platform | 7 | 32核64g |
| Kudu | 11 | 32核64g |
| Presto | 15 | 32核64g |
| Zeppelin | 1 | 6核32g |
大数据需求
- 需求第二期:
在资产租赁管理服务中,除了要了解客户投诉情况、满意度调查、水电使用情况、设备故障等统计分析之外,还需要帮客户做租赁业务的精准营销,网络爬取提供竞品分析数据,指导客户业务决策。
实时离线一体化系统之技术架构
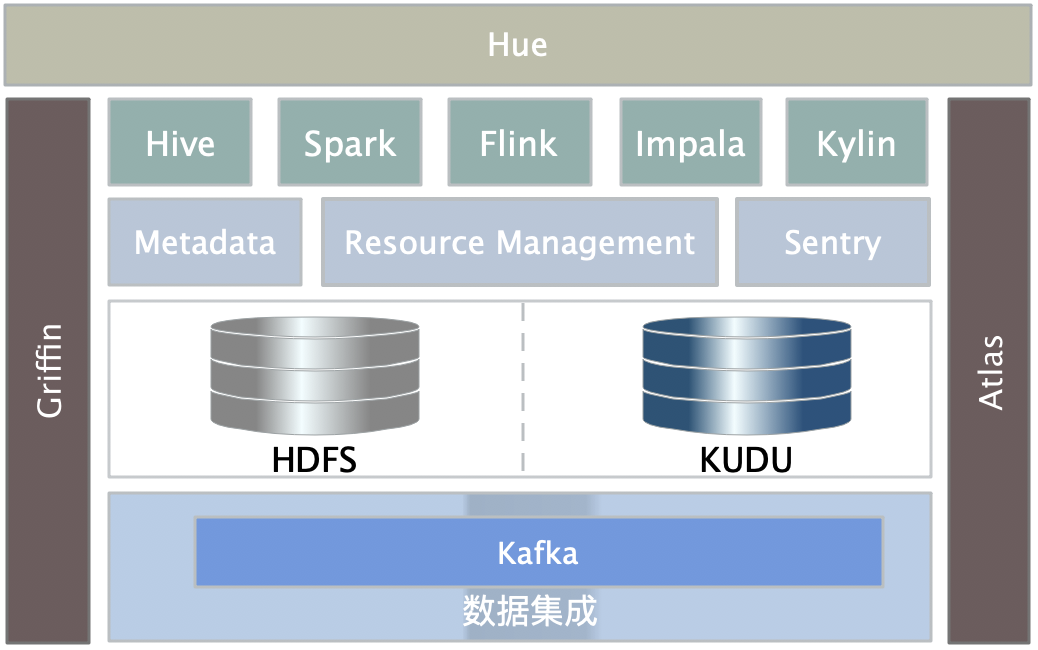
实时离线一体化系统之数据流
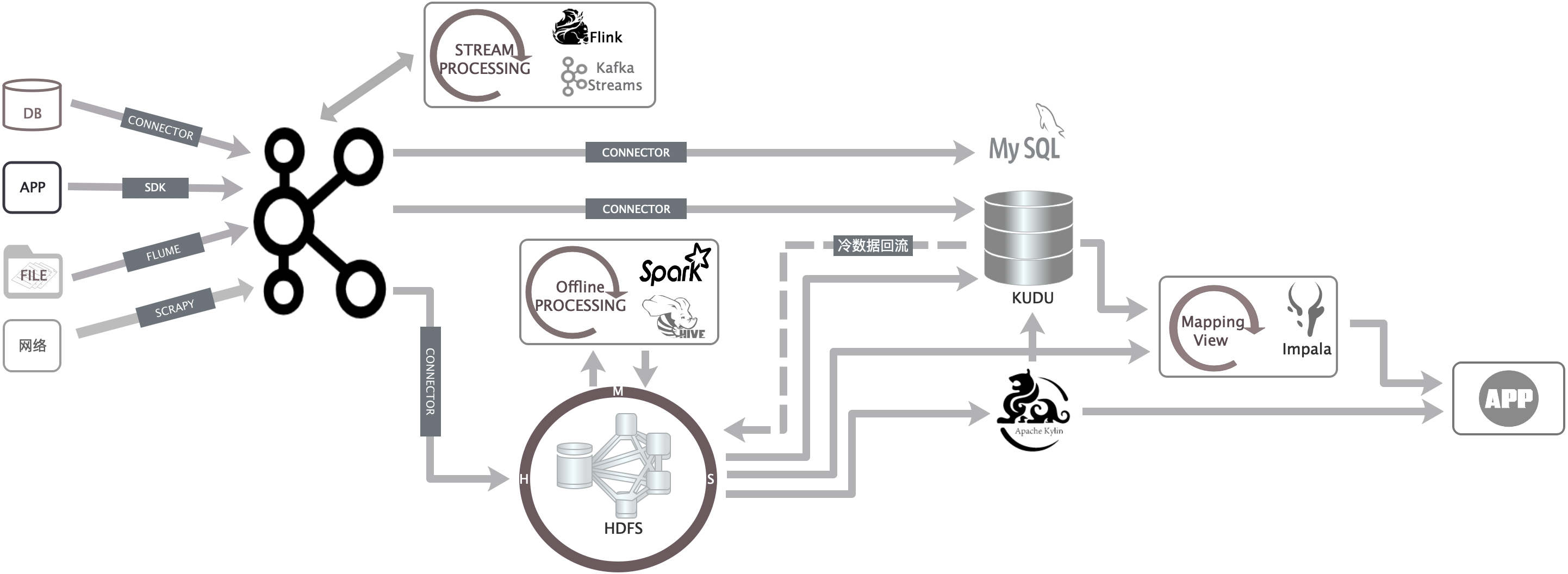
实时离线一体化接入
大数据的来源主要分为三个:
- 第一个来源是内部系统的Mysql数据库(业务分析)
- 第二个来源是应用App(用户轨迹)
- 第三个来源是外部系统网络采集(同行数据,用于竞品分析,行业分析)
- 日志文件(业务访问、打印在日志文件上的业务数据)
有些实时数据,只需简单的清洗就可以产出,比如:异构数据同步、上面讲到的即时查询系统等这类数据是不需要进入ODS层的。为了能跟即时查询系统的接入统一化。所有来源数据统一由集成服务实时接入ODS层(hdfs)或APP层(Kudu)。
数据仓库分层规范化
数据分层大家都流行以四层划分(关于数仓分层,不了解的同学需要自己去找文章补脑),这里也不例外,只是我们每层的存储和访问需要解决整合问题,原因跟我们用的技术架构有关系。接下来我们讲下每种数据流进来以后和经过层层分析后怎么存储。先上个直观图:

对于要求实时的数据,进入到kafka后,经过ETL直接输出应用数据到Kudu或Mysql,提供给应用使用。相当于在先前的即时查询系统中加入了ETL功能,不再是之前简单的kafka Connector了。需要做离线分析、定制查询或实时性要求不高的数据分析,通过数据集成通道后通过Hive进入到ODS。然后再由已开发好的程序经过预计算出的结果往数据上层上放(DW和APP层),我们的原则是:越往上层的数据,越往实时仓Kudu上放。对于离线计算,可以固化的查询,如果随着数据量和计算复杂度的增长,即使我们用了上面的即时查询系统,在响应时间上也不能得到保证(就算可以增加计算节点,如果查询树无法再拆分的情况下),所以我们选择预计算方案
预计算方案
大家都知道,企业中的查询一般分为即席查询和定制查询两种。对于即时查询需求我们用presto和Impala做为引擎(为什么会用到两个?这个问题跟我们的需求演化和公司系统架构有关系,presto从支持标准的sql上看,可以减轻业务侧对现有的功能sql改造,简单来说就是为了兼容现状。部署的环境依赖也比较简单,方便部署;而Impala主要是用在大数据需求新功能上,又方便检索冷热数据的聚合)。而定制查询,它的场景多数是对用户的操作或是对下线的业务数据做出实时分析,如果用Hive或SparkSQL作为查询引擎,估计要花上数分钟甚至数十分钟的时间才能响应,显然是不能满足需求的。在很长一段时间里,企业只能对数据仓库中的数据进行提前计算,再将算好后的结果存储在APP层或DW层上,再提供给用户进行查询。但是上面我们也说了,当业务复杂度和数据量逐渐升高后,使用这套方案的开发成本和维护成本都显著上升。因此,对于已经固化下来的查询进行亚秒级返回的解决办法。我们使用了Apache Kylin,我们只需要提前定义好查询维度,Kylin就能帮助我们进行计算,并将结果存储到结果表中。这样不仅很好地解决了海量数据快速查询的问题,也减少了手动开发和维护提前计算程序的成本。
但是Kylin默认将计算结果放入到Hbase中,从上图看,没有看到Hbase,而是Kudu。因为我们自己实现了Kylin与Kudu的整合。
Kylin使用Kudu存储引擎
存储引擎,我们引入自研的storage-kudu模块替代默认的storage-hbase。Kylin依赖的三大模块:数据源、构建引擎、存储引擎。数据源我们还是使用Hive, 至于在kudu中的数据,因为上面已经解决了Hive支持kudu的方案,所以Kylin通过Hive也可以加载到Kudu中的数据。构建引擎我们使用了Kylin支持的spark计算引擎。而spark同时也是支持与Kudu整合的。从源码上看,Kylin架构要求扩展存储引擎需要实现IStorage接口,这接口有两个函数一个是指定构建Cube引擎接口adaptToBuildEngine和能够查询Cube的createQuery接口,剩下的数据在Kudu的存取细节基本都直接使用spark支持Kudu的api。
实时离线开发统一访问数据入口

部分分析数据,比如用户的满意度调查、水电费使用统计等,在即时查询系统中已经存在,不就需要再同步一份数据到hdfs当中。为了减少存储空间成本,避免数据多份存储,那么就至少需要解决在Kudu中的数据能让hive能访问到。但是我们使用的hive版本中,hive并不支持Kudu表的操作,预告最新的hive4.0版本中,也未开发完成。
需要解决的问题:
- 即时系统中存在Kudu表数据,需要通过Hive能访问,这点仿照Impala,创建外部表 ,将kudu的表映射到Hive上
- Hive能像Impala一样,能创建表、查询、更新、删除操作
- Kylin能使用Kudu表
- 保证数据结构和元数据信息的一致性
Hive、Kudu元数据整合:
从Hive官网公布信息和源码分析来看,核心类KuduStorageHandler、KuduSerDe、KuduInputFormat、KuduOutputFormat已经实现一分部功能,KuduMetaHook还没有,保证 meta 的一致性需要必须实现HiveMetaHook。从源码上看KuduStorageHandler已经继承了DefaultStorageHandler和实现了HiveStoragePredicateHandler,再实现与HMS的交互就可以对 Kudu meta 的相关操作和可以发现Kudu的表并进行操作了(与《CDH6.3.2升级Hive到4.0.0》文章中使用同个版本)。

其中即时系统实时同步到Kudu的表数据,也需要创建Hive外部表,把kudu表映射到Hive来,也是在KuduStorageHandler中实现,包括数据的查询、修改、删除。通过在数据集成服务的《同步管理》模块中,每次创建数据同步任务时,都会去连接Hive并创建Kudu的外部映射表。
如此一来,不管上层使用的SparkSQL、Kylin还是HQL访问hdfs或kudu的表,对开发者或对数据使用者来说都是统一的入口。
透明的数据分层存储
整个系统架构里,有两个地方可以存储数据,一个是Kudu,另一个是HDFS。而Kudu存储的数据大多是即时查询系统数据和经过业务处理分析后的APP层、DWS层数据。实时数据当不在有变更时,就可以刷到HDFS上;APP层等这些数据随着时间的推移,也是逐渐变成冷数据。那么等变冷的数据,就需要迁移到HDFS上。而数据迁移后将面临查询数据不完整性、如何实现数据的平滑迁移,又不影响查询其完整性呢?
一部分数据在Kudu,一部分数据在HDFS,解决查询的完整性,主要通过View实现。
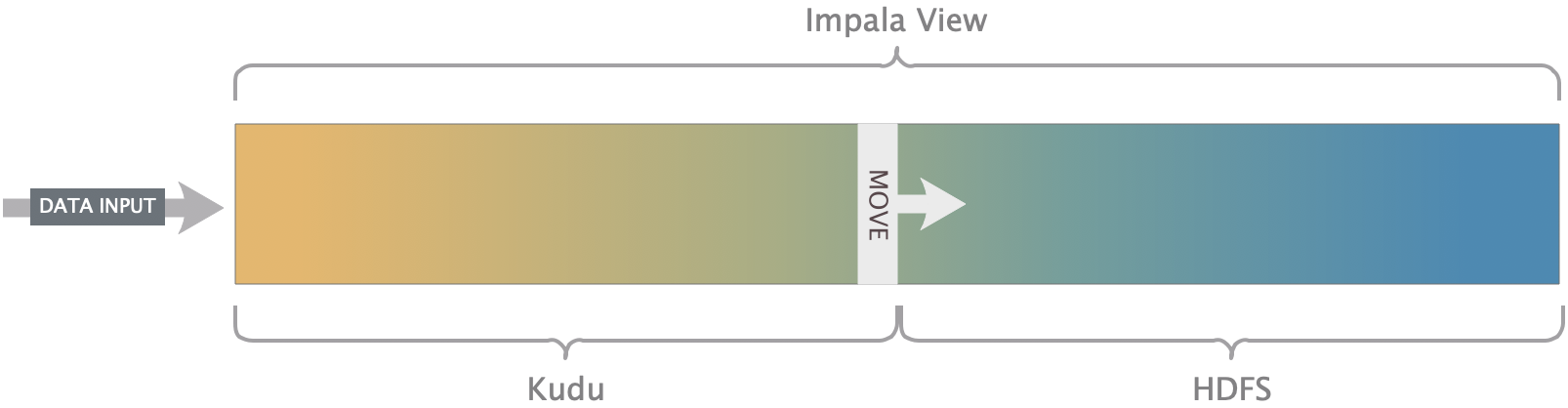
每天把Kudu里的冷数据迁移到HDFS上,如何识别哪些是冷数据,由业务提供,根据业务情况,业务侧自行为每个表提供一个冷热数据的时间周期。当超过时间周期的数据将被程序迁移进HDFS。每次迁移完成后都需要创建或修改View。不然数据就查不到了。View需要定义好Kudu和HDFS上的查询时间范围。如:
create view tb_uhome_acct_item_view as
SELECT COMMUNITY_ID,STAGE_ID,NAME,UNIT,HOUSE_NAME,BILL_AREA,PAY_USERID,BILLING_CYCLE,FEE_ITEM_TYPE_ID,RULE_NAME,RES_INST_NAME,HOUSE_STATUS_TYPE,HOUSE_STATUS,REAL_CYCLE,CONCAT( BILL_DATE_START, BILL_DATE_END ),LEASE_POSITION,OBJ_CODE
FROM tb_uhome_acct_item
WHERE create_date >= "2015-01-01"
UNION ALL
SELECT COMMUNITY_ID,STAGE_ID,NAME,UNIT,HOUSE_NAME,BILL_AREA,PAY_USERID,BILLING_CYCLE,FEE_ITEM_TYPE_ID,RULE_NAME,RES_INST_NAME,HOUSE_STATUS_TYPE,HOUSE_STATUS,REAL_CYCLE,CONCAT( BILL_DATE_START, BILL_DATE_END ),LEASE_POSITION,OBJ_CODE
FROM tb_uhome_acct_item_hdfs
WHERE create_date < "2015-01-01"
每一边的数据都有表字段create_date做了范围限制,然后等迁移成功后再修改View,这样无何什么时候查数据,都不会出现部分数据检索不到。
再补充一点,先前的即时查询系统中,通过连接器同步过来的Kudu表数据,在同步的时候,在数据集成系统中,要创建Impala的外部表,将kudu的表映射到impala上,这样Impala才能查到。
展望未来
1、基于整合后的架构,未来我们可以提供更多的能力,让更多的存储引擎支持Hive Metastore,使HMS的元数据服务支持丰富化。
2、数据延迟监控,对kafka每个topic消息的延迟、lag监控,做到整个数据链路的延迟监控。
3、Hive支持Kudu继续优化。通过Hive查询部分数据在Kudu和部分在hdfs中的数据view实现还未完善,还有部分ddl需要完善。
4、Kylin继续二开,根据数据集成服务中采集到用户的维度和度量需求,使用Spark 动态构建Cube。
实时离线一体化在资产租赁saas服务中使用的更多相关文章
- 10.2.2移动产品离线功能等具体解释----暨4月8日移动《在离线一体化》公开课Q&A
4月8日<离,或者不离,ArcGIS移动的"在离线一体化"就在那里!>移动公开课已经结束,针对公开课上粉丝们重点关注的问题,本博客进行了具体的解答.答疑主要环绕最新的R ...
- 一文了解腾讯云数据库SaaS服务
本文由云+社区发表 作者:邵宗文,2009年加入腾讯,现为腾讯云数据库专家产品经理.之前曾负责为OMG事业群构建数据库平台,部署,规划及运维支持,为腾讯网,新闻客户端,快报,视频,财经,体育等提供了稳 ...
- 实时营销引擎在vivo营销自动化中的实践 | 引擎篇04
作者:vivo 互联网服务器团队 本文是<vivo营销自动化技术解密>的第5篇文章,重点分析介绍在营销自动化业务中实时营销场景的背景价值.实时营销引擎架构以及项目开发过程中如何利用动态队列 ...
- 将数据库中的表注册到K2服务中,并封装为Smart Object
转:http://www.cnblogs.com/dannyli/archive/2011/08/15/2139550.html K2 blackpearl项目中经常需要将其他数据中的表注册到K2服务 ...
- log4j2自定义Appender(输出到文件/RPC服务中)
1.背景 虽然log4j很强大,可以将日志输出到文件.DB.ES等.但是有时候确难免完全适合自己,此时我们就需要自定义Appender,使日志输出到指定的位置上. 本文,将通过两个例子说明自定义APP ...
- Spring Cloud 微服务中搭建 OAuth2.0 认证授权服务
在使用 Spring Cloud 体系来构建微服务的过程中,用户请求是通过网关(ZUUL 或 Spring APIGateway)以 HTTP 协议来传输信息,API 网关将自己注册为 Eureka ...
- 下一个亿万市场:企业级SaaS服务谁能独领风骚
注:SaaS是Software-as-a-Service(软件即服务)的简称,一种完全创新的软件应用模式,简单来说SaaS即为提供商基于互联网为企业提供软件服务. 对中小型企业来说:SaaS是采用先 ...
- saas服务提供商
这段时间接触了不少行业的东西,这里谈几点肤浅的看法.从市场行情上讲,SaaS风口还在,不过热度明显向大数据.物联网.人工智能.区块链等转移. 做得比较好的有这些SaaS提供商,每个领域的都有那么几家的 ...
- Traefik 控制面板 SaaS 服务 Pilot
文章转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247485572&idx=1&sn=8ffa2bc7 ...
随机推荐
- 微信开发者工具集成GitHub,多人协调开发,上传拉取等
一,准备环境 1,提前安装git环境和GitHub做集成,不做多解释: 1,准备微信项目代码: 2,创建GitHub仓库: 二,创建GitHub仓库 1,创建一个空的GitHub仓库,不要任何文件和不 ...
- canvas绘制图片drawImage学习
不得不说,html5中的canvas真的非常强大,从图片处理,到视频处理,再到游戏开发,都能见到canvas的身影,然而,就这一个<canvas>标签,功能居然如此强大,这主要归功于can ...
- wsl 修改默认安装路径
如果已经装了,先删除 mklink /j C:\Users\XXXX\AppData\Local\Packages\CanonicalGroupLimited.UbuntuonWindows_79rh ...
- [IDEA]Java:“程序包XXX不存在”问题的三种解决方案
###三种方案 ####01 出现jar包找不到的问题,首先有可能是项目依赖中有些jar没有下载完整 而mvn idea:idea这个命令可以检查并继续下载未下载完整的依赖jar. 在命令行输入mvn ...
- Vue入门到精通
Vue.js - Day1 课程介绍 前5天: 都在学习Vue基本的语法和概念:打包工具 Webpack , Gulp 后5天: 以项目驱动教学: 什么是Vue.js Vue.js 是目前最火的一个前 ...
- 本周 GitHub 速览:您的代码有声儿吗?(Vol.38)
作者:HelloGitHub-小鱼干 摘要:还记得花式夸赞程序员的彩虹屁插件 vscode-rainbow-fart 吗?它后续有人啦!JazzIt 同它的前辈 vscode-rainbow-fart ...
- 容器云平台No.2~kubeadm创建高可用集群v1.19.1
通过kubernetes构建容器云平台第二篇,最近刚好官方发布了V1.19.0,本文就以最新版来介绍通过kubeadm安装高可用的kubernetes集群. 市面上安装k8s的工具很多,但是用于学习的 ...
- 分布式服务(RPC)+分布式消息队列(MQ)面试题精选
分布式系统(distributed system)是建立在网络之上的软件系统.正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性.因此,网络和分布式系统之间的区别更多的在于高层软件(特别是 ...
- Appium 用途和特点
Appium 是一个移动 App (手机应用)自动化工具. 手机APP 自动化有什么用? 自动化完成一些重复性的任务 比如微信客服机器人 爬虫 就是通过手机自动化爬取信息. 为什么不通过网页.HTTP ...
- vs code的使用与常用插件和技巧大全总结
vs code的使用与常用插件和技巧大全总结 Author:3# 一个专注于web技术的80后 我不用拼过聪明人,我只需要拼过那些懒人 我就一定会超越大部分人! CSDN@ 极客小俊,CSDN官方首发 ...