养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧。
https://github.com/answershuto/Rental
欢迎指导交流。
效果图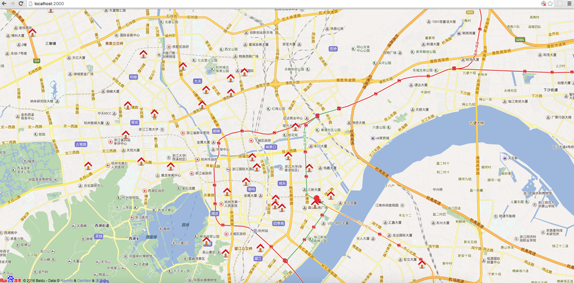
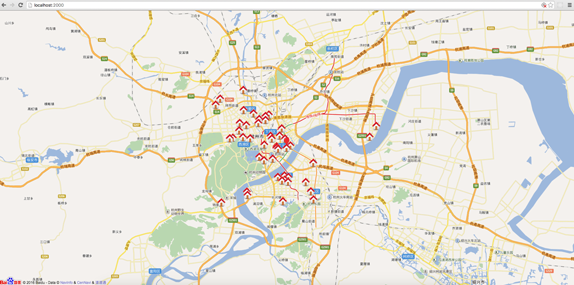
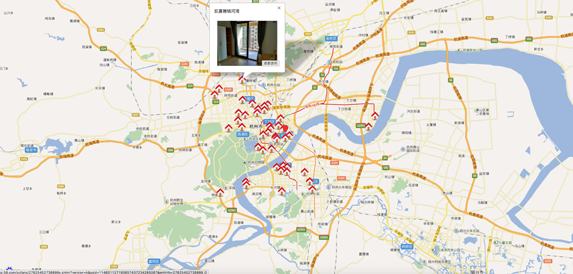
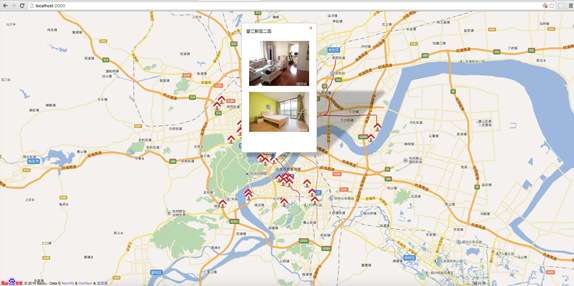
搭建Node.js环境及启动服务
安装node以及npm,用express模块启动服务,加入自己所需要的中间件即可,这个不是本文所要讨论的重点,可以参考网上的一些教程搭建环境。
获取导航页URL以及数据
打开58同城主页,我主要针对杭州的二手房进行了爬取分析,所以进入杭州租房。
http://hz.58.com/chuzu/pn1/?key=%E6%9D%AD%E5%B7%9E%E7%A7%9F%E6%88%BF%E5%AD%90&cmcskey=%E7%A7%9F%E6%88%BF%E5%AD%90&final=1&PGTID=0d3090a7-0004-f43c-ee04-95c2ea3d031f&ClickID=6
可以得到这一串URL,上下页查看后就不难发现,pn后面的数字就是页面的页码,?后面的是一些get请求带带参数。用一个函数即可通过页码得到正确的URL。
function getUrl(page = 1){ return ‘http://hz.58.com/chuzu/pn'+page+'/?key=%E6%9D%AD%E5%B7%9E%E7%A7%9F%E6%88%BF%E5%AD%90&cmcskey=%E7%A7%9F%E6%88%BF%E5%AD%90&final=1&PGTID=0d3090a7-0004-f43c-ee04-95c2ea3d031f&ClickID=6‘; }
根据上面的URL我们就可以访问到每一页的所有租房信息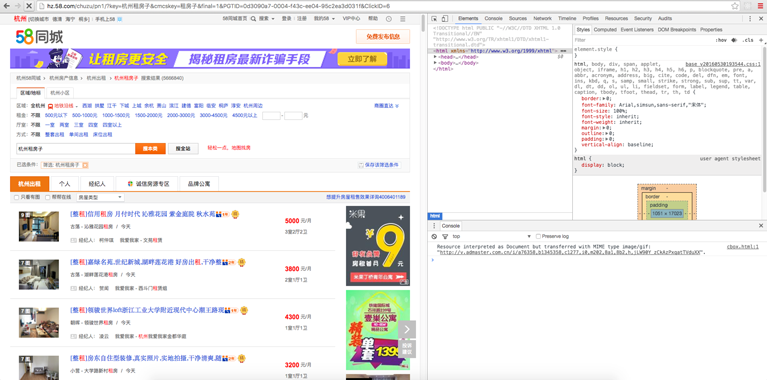
用cheerio模块解析dom
安装cheerio模块,使用cheerio模块解析dom,然后就可以类似jquery一样访问dom了。
var cheerio = require(‘cheerio’); let $ = cheerio.load(html);
获取每个租房信息的URL
打开开发者模式,osX(option + command + I),windows( F12 ),然后就可以在elements中看到文档结构了。(这里以chrome为例)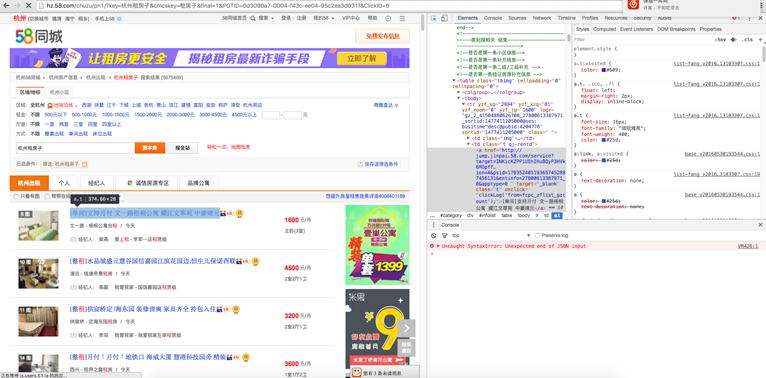
可以看到对应的a标签,我们只需要提取出该url即可,及对应的href,就是它点击跳转的URL。
该a标签的class为t,用$(‘a.t’)即可得到所有的a标签的对象,得到的是一个数组,遍历取出href属性即可。
for(let i = 0; i < (‘a.t’)[i].attribs.href) }
得到了这些URL,接下来就可以用这些URL访问具体的租房信息了,每个URL对应一个租房页面。
根据租房信息的URL访问相应页面,爬取数据
还是先进入页面打开开发者模式。
这次我们需要解析房屋所在地信息,用来可视化显示。
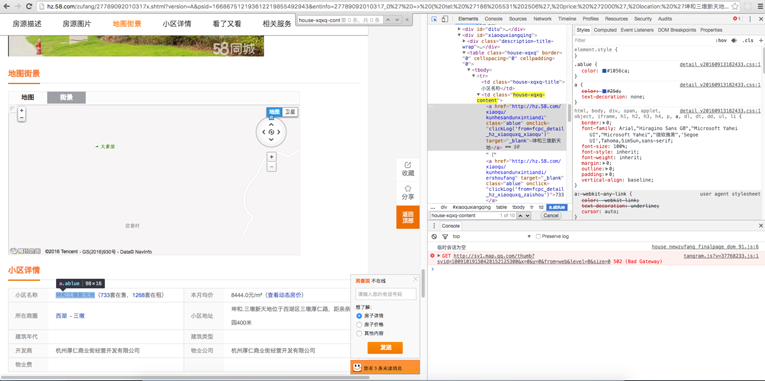
$('td.house-xqxq-content a.ablue')
加上父标签可以过滤出更有针对性的dom,此时过滤出的是小区名称、本月均价、所在商圈等信息的dom,我们现在只需要第一个dom里面的数据,所以访问数组的[0]即可。
除此之外为还需要页面里面的一张展示房屋信息的一张图片,找到对应dom可以发现id为smainPic。
$(‘#smainPic’)[‘0’].attribs.src
这样访问即可得到图片的URL。
其他我们还可以用同样的方法获取很多相关数据,比如(‘span.tel-num.tel-font’).text()可以得到房东的联系方式。
通过百度地图进行可视化展示
这里使用百度地图api
http://lbsyun.baidu.com/index.php?title=jspopular
var map = new BMap.Map(“container”); // 创建地图实例 map.centerAndZoom(“杭州”, 12); var localSearch = new BMap.LocalSearch(map); localSearch.setSearchCompleteCallback(function(searchResult){ var poi = searchResult.getPoi(0);/地理位置信息/ }) ocalSearch.search(params[url].location);
获取经纬度以后再掉用相应的api在地图上显示即可,显示后再做什么效果,可自行发挥想象了。
关于反爬虫
在爬取过程中发现58同城的反爬虫策略,快速访问会让你输入验证码来验证是人在操作而不是代码访问。只要是人可以正常访问并不影响用户正常体验的网站都有办法绕过反爬虫策略。
先采用较慢的方式发送http请求访问,此外每隔一段时间最好停一下,然后再继续访问。除此之外用User-Agent字段伪装成浏览器。最保险的方法就是购买代理,让代理用不同的ip地址去访问网站,即可绕过反爬虫机制。
具体做法可以参照相关反爬虫策略的文章。
关于
作者:染陌
Email:answershuto@gmail.com or answershuto@126.com
Github: https://github.com/answershuto
Blog:http://answershuto.github.io/
知乎专栏:https://zhuanlan.zhihu.com/ranmo
掘金: https://juejin.im/user/58f87ae844d9040069ca7507
osChina:https://my.oschina.net/u/3161824/blog
转载请注明出处,谢谢。
欢迎关注我的公众号
养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)的更多相关文章
- python爬虫:找房助手V1.0-爬取58同城租房信息
1.用于爬取58上的租房信息,限成都,其他地方的,可以把网址改改: 2.这个爬虫有一点问题,就是没用多线程,因为我用了之后总是会报: 'module' object has no attribute ...
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- Node.js/Python爬取网上漫画
某个周日晚上偶然发现了<火星异种>这部漫画,便在网上在线看了起来.在看的过程中图片加载很慢,而且有时候还不小心点到广告,大大延缓了我看的进度.后来想到能不能把先把漫画全部抓取到本地再去看. ...
- python3爬虫-爬取58同城上所有城市的租房信息
from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, dat ...
- python爬虫项目(scrapy-redis分布式爬取房天下租房信息)
python爬虫scrapy项目(二) 爬取目标:房天下全国租房信息网站(起始url:http://zu.fang.com/cities.aspx) 爬取内容:城市:名字:出租方式:价格:户型:面积: ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- 使用node.js如何爬取网站数据
数据库又不会弄,只能扒扒别人的数据了. 搭建环境: (1).创建一个文件夹,进入并初始化一个package.json文件. npm init -y (2).安装相关依赖: npm install ...
- 用Python写爬虫爬取58同城二手交易数据
爬了14W数据,存入Mongodb,用Charts库展示统计结果,这里展示一个示意 模块1 获取分类url列表 from bs4 import BeautifulSoup import request ...
- Python爬虫(一)——开封市58同城租房信息
代码: # coding=utf-8 import sys import csv import requests from bs4 import BeautifulSoup reload(sys) s ...
随机推荐
- QImage 图像格式小结
原地址:http://tracey2076.blog.51cto.com/1623739/539690 嗯,这个QImage的问题研究好久了,有段时间没用,忘了,已经被两次问到了,突然有点解释不清楚, ...
- C#通过RFC调用SAP
using System;using System.Collections.Generic;using SAP.Middleware.Connector;using System.Data;using ...
- JAVA多线程编程之生产者消费者模式
Java中有一个BlockingQueue可以用来充当堵塞队列,下面是一个桌面搜索的设计 package net.jcip.examples; import java.io.File; import ...
- netty 学习
示例 : wikit http://netty.io/wiki/index.html 书 : netty in action http://blog.csdn.net/abc_key/article/ ...
- 【Android】Activity生命周期(亲测)
测试手机:Nexus 5 系统:4.4 一.测试 测试代码: package com.example.androidalarm; import android.app.Activity; impo ...
- struts2 using kindeditor upload pictures (including jmagic compressed images)
Project uses a kindeditor3.4 UploadContentImgAction @SuppressWarnings("serial") @ParentPac ...
- 在server 2008/2003中 取消对网站的安全检查/去除添加信任网站
新安装好Windows Server 2003操作系统后,打开浏览器来查询网上信息时,发现IE总是“不厌其烦”地提示我们,是否需要将当前访问的网站添加到自己信任的站点中去:要是不信任的话,就无 ...
- tomcat6 使用comet衍生出的两个额外问题
开发了一个轮询推送功能,网上也有很多文章讲这个就不说怎么做的了.现在发现两个问题: 一:就是登录进主页面后,由于浏览器在不停轮询,导致后端认为前端一直在操作,而正常设定的session超时就跳转到登录 ...
- JavaScript面试库
1.将一段字符串转成驼峰命名法. var str = "web-kit-index"; function to(str){ var j = str.split("-&qu ...
- 手机浏览器JS识别
识别方法:采用Fiddler 抓包工具 侦测手机http链接,抓取http头 查看 工具:Fiddler 1:Fiddler配置 允许远程设备连接,配置端口为默认8888(确保8888端口没有被其他进 ...