The Bip Buffer - The Circular Buffer with a Twist
Introduction
The Bip-Buffer is like a circular buffer, but slightly different. Instead of keeping one head and tail pointer to the data in the buffer, it maintains two revolving regions, allowing for fast data access without having to worry about wrapping at the end of the buffer. Buffer allocations are always maintained as contiguous blocks, allowing the buffer to be used in a highly efficient manner with API calls, and also reducing the amount of copying which needs to be performed to put data into the buffer. Finally, a two-phase allocation system allows the user to pessimistically reserve an area of buffer space, and then trim back the buffer to commit to only the space which was used..
Let's cover a little history first. If you don't already know why a circular buffer can be implemented really efficiently in hardware, or why that makes them the buffer of choice in most electronics, here's why.
Back in Days of Old...
Once upon a time, computers were much simpler. They didn't have 64 bit data buses. Heck, they didn't even have real 16 bit registers - although you could occasionally convince a pair of them to sub in for that purpose. These were simpler times, where Real Men programmed in assembly language, and laughed at anyone who didn't know how to use the carry flag for all kinds of nefarious purposes.
With simpler times came elegant hacks to eke the most power out of every instruction cycle available. Take, for example, a simple terminal communications program. Newer RS232 serial controllers had things like automatic handling of RTS and CTS signal lines to control the flow of data - but this came at a cost. Namely, the connection would be stopping and starting all the time, instead of streaming along. So in between the controller card and the system, would often be found a FIFO. This simple circular buffer was often no more than a couple of bytes long, but it meant that the system could run smoothly along without polling to see if data had arrived, or being hammered by constant interrupts from the serial controller.
Most FIFOs started out on-chip, but people also added their own in their code - the idea being that if you had some really gnarly dancing that you had to do on the incoming data, you may as well batch it all up into one lump and do it infrequently... giving spare time to the system to do other things. Like scroll the console, or decode GIFs.
As I said, a FIFO is a very simple circular buffer. Most are implemented very simply as well; they're typically 2n bytes in size, which allows the pointers to simply overflow to get back around to the other end of the buffer. The FIFO logic can tell if the FIFO is empty because the head and tail values are the same, and it's full if the head is one greater than the tail.
Implementing these in software was easy on the old 8 bit systems. Take a 16 bit register pair. Decide on a location in memory (a multiple of 256) to store the FIFO data in. Then, after setting the register to the start of the buffer, don't touch the high register - just increment the low register. This gives you a 256-byte long buffer which you can walk through in one (in the case of the Zilog Z80, 4 cycles - the smallest execution unit available on that system) instruction. You can never go out of the bounds of your buffer, because the low register acts as an index with a value from 0 to 255. When you hit what would have been index 256, the register overflows and clocks back over to zero.
The Modern Day
Unfortunately, there is no solution quite as elegant available to Windows programmers today as that simple old 8-bit solution. Sure, you can dive down into assembly language (provided you can work out how the compiler maps registers to values... something I've never seen a good enough explanation of to get my head around), but most people don't have time for assembly language any more. And besides, we're dealing with 32 bit registers now - incrementing just one low-order byte from inside that register isn't really all that kosher any more. It can lead to cache flushing, pipeline stalling, printer fires, rains of frog, etc.
If you can't just clock the low-order register to walk through the buffer, you have to start worrying about things like checking to see how much buffer you have filled before the end, making sure that you remember to copy the rest of the data from the start of the buffer, and all kinds of other bookkeeping headaches.
My first attempt at implementing something like this relied on the vague hope that the virtual memory system could be tricked into setting things up in such a way that you could set up a mirror of a section of memory right next to the original. The idea being that you could still use the rotating allocation of data; a copy operation could go at full speed without any checking to see if you'd walked off the end of the buffer - because as far as your process's address space is concerned, the end of your buffer is also the beginning of your buffer.
Now, this mirroring technique may actually work. Due to some restrictions, I decided not to implement it myself (yet - I'm sure I'll find a use for it some day). The idea behind it is that first one reserves two areas of virtual memory, side by side. One then maps the same temporary file into both virtual memory sections. Voila! Instant mirroring, and a nice large buffered expanse one can copy data from willy-nilly.
Unfortunately, while it should (again, I've not tried it) indeed work, there is another problem - namely, that files can only be mapped on 64kb boundaries (possibly larger on larger memory systems). This means that your buffer has to be a minimum of 64kb in size, and will take up 128kb of your virtual address space. Depending on your application, this may be a valid technique. However, I don't see writing a server application with 1000's of sockets being a valid prospect here.
So what to do? If mirroring won't work, how close can we get to using a circular buffer in our code? Heck, even if we can get close, why would we want to?
The Advantages of the Circular Buffer
There are a number of key advantages to using a circular buffer for the temporary storage of data.
When one puts data into a block of memory, one also has to take it out again to make use of it. (Or one can use it in place). It is useful to be able to make use of the data in the buffer while more data is being appended to the buffer. However, as one frees up space at the head of the buffer, that space is no longer usable, unless one copies all of the data in the buffer which has not yet been used to the beginning of the buffer. This frees up space at the end of the buffer, allowing more data to be appended.
There are a couple of ways around this; one can simply copy the data (which is a reasonably expensive proposition), or one can extend the buffer to allow more data to be appended (a massively expensive process).
With a circular buffer, the free space in the buffer is always available to have data appended into it; the data is copied, the pointer adjusted, and that's that. No copying, no reallocation, no worries. The buffer is allocated once, and then remains useful for its entire life.
A Fly In The Ointment
One could simply implement a circular buffer by allocating a chunk of memory, and maintaining pointers. When one walked off the end of the buffer, the pointer would be adjusted - and this operation would be reflected in every operation that is performed, whether copying data into the buffer or removing it. Length calculations are slightly more complicated than normal, but not overly so - simple inline functions take care of that problem with ease, sweeping it under the rug.
Unfortunately, most API calls don't believe in circular buffers. You have to pass them a single contiguous block of memory which they can access, and there is no way for you to modify their write behavior to adjust pointers when they cross the end of the buffer. So what to do? Well, this is where the Bip-Buffer comes in.
Enter The Bip-Buffer
If one cannot pass a circular buffer into an API function, then one needs an alternative that will work - preferably with many of the same advantages as the circular buffer. It is possible to build a circular buffer which is split into two regions - or which is bi-partite (and that's how you get the Bip in a Bip-Buffer). Each of the two regions move through the buffer, starting at the left and ending up at the right hand side. When one runs out of space for appending data, if there is only one region, a new one is created at the beginning (if possible). The diagram below shows how it works in more detail.
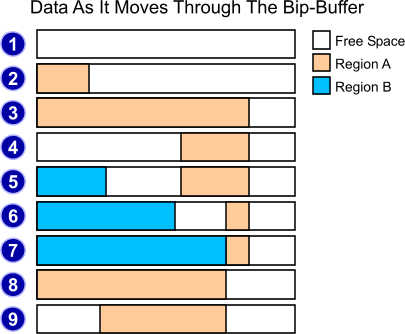
The buffer starts out empty, with no regions present (figure 1). (eg. immediately after calling AllocatedBuffer)
Then, when data is first put into the buffer, a single region (the 'A' region) is created (figure 2). (Say, by calling Reserve followed by Commit)
Data is added to the region, extending it to the right (figure 3).
For the first time now, we remove data from the buffer (figure 4). (see the DecommitBlock call described below)
This continues until the region reaches the end of the buffer (figure 4). Once more free space is available to the left of region A than to the right of it, a second region (comically named "region B") is created in that space. The choice to create a new region when more space is available on the left is made to maximize the potential free space available for use in the buffer. The upshot of all this leaves us with something which looks rather like figure 5.
If we now use up more of the buffer space, we end up with figure 6, with new space only being allocated from the end of region B. If we eventually allocate enough data to use up all of the free space between regions A and B (figure 7), we no longer have any usable space in the buffer, and no more reservations can be performed until we read some data out of it.
If we then read more data out of the buffer (say the entire remaining contents of region A), we exhaust it entirely. At the point, as region A is completely empty, we no longer need to track two separate regions, and all of region B's internal data is copied over region A's internal data, and region B is entirely cleared. (figure 8)
If we read a little more data out of the buffer, we now end up with something a lot like figure 4, and the cycle continues.
Characteristics of the Bip-Buffer
The upshot of all of this is that on average, the buffer always has the maximal amount of free space available to be used, while not requiring any data copying or reallocation to free up space at the end of the buffer.
The biggest difference from an implementation standpoint between a regular circular buffer and the Bip Buffer is the fact that it only returns contiguous blocks. With a circular buffer, you need to worry about wrapping at the end of the buffer area - which is why for example if you look at Larry Antram's Fast Ring Buffer implementation, you'll see that you pass data into the buffer as a pointer and a length, the data from which is then copied byte by byte into the buffer to take into account the wrapping at the edges.
Another possibility which was brought up in the bulletin board (and the person who brought it up shall remain nameless, if just because they... erm... are nameless) was that of just splitting the calls across wraps. Well, this is one way of working around the wrapping problem, but it has the unfortunate side-effect that as your buffer fills, the amount of free space which you pass out to any calls always decreases to 1 byte at the minimum - even if you've got another 128kb of free space at the beginning of your buffer, at the end of it you're still going to have to deal with ever shrinking block sizes. The Bip-Buffer neatly sidesteps this issue by just leaving that space alone if the amount you request is larger than the remaining space at the end of the buffer. When writing networking code, this is very useful; you always want to try to receive as much data as possible, but you never can guarantee how much you're going to get. (For most optimal results, I'd recommend allocating a buffer which is some multiple of your MTU size).
Yes, you are going to lose some of what would have been free space at the end of the buffer. It's a small price to pay for playing nicely with the API.
Use of this buffer does require that one checks twice to see if the buffer has been emptied; as one has to deal with the possibility that there are two regions currently in use. However, the flexibility and performance gains outweigh this minor inconvenience.
The BipBuffer class (full source code provided in the link) has the following signature:
class BipBuffer
{
private:
BYTE* pBuffer;
int ixa, sza, ixb, szb, buflen, ixResrv, szResrv; public:
BipBuffer();
The constructor initializes the internal variables for tracking regions, and memory pointers to null; it does not allocate any memory for the buffer, in case one needs to use the class in an environment where exception handling cannot be used.
~BipBuffer();
The destructor simply frees any memory which has been allocated to the buffer.
bool AllocateBuffer(int buffersize = 4096);
AllocateBuffer allocates a buffer from virtual memory. The size of the buffer is rounded up to the nearest full page size. The function returns true if successful, or false if the buffer cannot be allocated.
void FreeBuffer();
FreeBuffer frees any memory allocated to the buffer by the call to AllocateBuffer, and releases any regions allocated within the Bip-Buffer.
bool IsInitialized() const;
IsInitialized returns true if the buffer has had memory allocated to it (by calling AllocateBuffer), or false if there is no memory allocated to the buffer.
int GetBufferSize() const;
GetBufferSize returns the total size (in bytes) of the buffer. This may be greater than the value passed into AllocateBuffer, if that value was not a multiple of the system's page size.
void Clear();
Clear ... well... clears the buffer. It does not free any memory allocated to the buffer; it merely resets the region pointers back to null, making the full buffer usable for new data again.
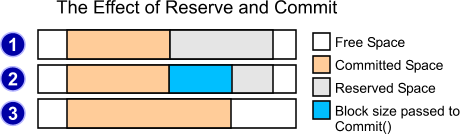
BYTE* Reserve(int size, OUT int& reserved);
Now to the nitty-gritty. Allocating data in the Bip-Buffer is a two-phase operation. First an area is reserved by calling the Reserve function; then, that area is Committed by calling the Commit function. This allows one to, say, reserve memory for an IO call, and when that IO call fails, pretend it never happened. Or alternatively, in a call to an overlapped WSARecv() function, it allows one to advertise how much memory is available to the network stack to use for incoming data, and then adjust the amount of space used based on how much data was actually read in (which may be less than the requested amount).
To use Reserve, pass in the size of block requested. The function will return the size of the largest free block available which is less than or equal to size in length in the reserved parameter you passed in. It will also return a BYTE* pointer to the area of the buffer which you have reserved.
In the case where the buffer has no space available, Reserve will return a NULL pointer, and reserved will be set to zero.
Note: you cannot nest calls to Reserve and Commit; after calling Reserve you must call Commit before calling Reserve again.
void Commit(int size);
Here's the other half of the allocation. Commit takes a size parameter, which is the number of bytes (starting at the BYTE* you were passed back from Reserve) which you have actually used and want to keep in the buffer. If you pass in zero for this size, the reservation will be completely released, as if you had never reserved any space at all. Alternatively, in a debug build, if one passes in a value greater than the original reservation, an assert will fire. (In a release build, the original reservation size will be used, and no one will be any the wiser). Committing data to the buffer makes it available for routines which take data back out of the buffer.
The diagram above shows how Reserve and Commit work. When you call Reserve, it will return a pointer to the beginning of the gray area above (fig. 1). Say you then only use as much of that buffer as the blue section (fig 2). It'd be a shame to leave this area allocated and going to waste, so you can call Commit with only as much data as you used, which gives you fig. 3 - namely, the committed space extends to fill just the part you needed, leaving the rest free.
int GetReservationSize() const;
If at any time you need to find out if you have a pending reservation, or need to find out that reservation's size, you can call GetReservationSize to find the amount reserved. No reservation? You'll get a zero back.
BYTE* GetContiguousBlock(OUT int& size);
Well, after all this work to put stuff into the buffer, we'd better have a way of getting it out again.
First of all, what if you need to work out how much data (total) is available to be read from the buffer?
int GetCommittedSize() const;
One method is to call GetCommittedSize, which will return the total length of data in the buffer - that's the total size of both regions combined. I would not recommend relying on this number, because it's very easy to forget that you have two regions in the Bip-Buffer if you do. And that would be a bad thing (as several weeks of painful debugging experience has proved to me). As an alternative, you can call:
BYTE* GetContiguousBlock(OUT int& size);
... which will return a BYTE* pointer to the first (as in FIFO, not left-most) contiguous region of committed data in the buffer. The size parameter is also updated with the length of the block. If no data is available, the function returns NULL (and the size parameter is set to zero).
In order to fully empty the buffer, you may wish to loop around, calling GetContiguousBlock until it returns NULL. If you're feeling miserly, you can call it only twice. However, I'd recommend the former; it means you can forget that there's two regions, and just remember that there's more than one.
void DecommitBlock(int size);
So what do you do after you've consumed data from the buffer? Well, in keeping with the spirit of the aforementioned Reserve and Commit calls, you then call DecommitBlock to release data from it. Data is released in FIFO order, from the first contiguous block only - so if you're going to call DecommitBlock, you should do it pretty shortly after calling GetContiguousBlock. If you pass in a size of greater than the length of the contiguous block, then the entire block is released - but none of the other block (if present) is released at all. This is a deliberate design choice to remind you that there is more than one block and you should act accordingly. (If you really need to be able to discard data from blocks you've not read yet, it's not too difficult to copy the DecommitBlock function and modify it so that it operates on both blocks; just unwrap the if statement, and adjust the size parameter after the first clause. Implementation of this is left as the dreaded youknowwhat).
And that's the Bip-Buffer implementation done. A short example of how to use it is provided below.
#include "BipBuffer.h" BipBuffer buffer;
SOCKET s;
bool read_EOF; bool StartUp
{
// Allocate a buffer 8192 bytes in length
if (!buffer.AllocateBuffer(8192)) return false;
readEOF = false; s = socket(... ... do something else ...
} void Foo()
{
_ASSERTE(buffer.IsValid()); // Reserve as much space as possible in the buffer:
int space;
BYTE* pData = buffer.Reserve(GetBufferSize(), space); // We now have *space* amount of room to play with. if (pData == NULL) return; // Obviously we've not emptied the buffer recently
// because there isn't any room in it if we return. // Let's use the buffer!
int recvcount = recv(s, (char*)pData, space, 0); if (recvcount == SOCKET_ERROR) return;
// heh... that's some kind of error handling... // We now have data in the buffer (or, if the
// connection was gracefully closed, we don't have any) buffer.Commit(recvcount); if (recvcount == 0) read_EOF = true; } void Bar()
{
_ASSERTE(buffer.IsValid()); // Let's empty the buffer. int allocated;
BYTE* pData; while (pData = buffer.GetContiguousBlock(allocated)
!= NULL)
{
// Let's do something with the data. fwrite(pData, allocated, 1, outputfile); // (again, lousy error handling) buffer.DecommitBlock(allocated);
}
}
Adieu
And so we reach the end. I hope that you find this code and way of managing data useful; I've certainly found that it comes in very handy for writing networking code. If you do find it useful, or use it in any of your code, all that I ask in return is that you drop me an email and let me know how the code is being used (what kind of project, what company, etc). Be vague if NDAs would get in the way - it's nice to know that it's out there, alive, and doing cool things.
Version History
- 10 May 2003
Updated source code to fix the bug PeterChen noticed, fixed spelling,
added abstract + more info based on comments. Changed diagram. Just a
general tidy up. - 06 January 2003
First published.
License
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
The Bip Buffer - The Circular Buffer with a Twist的更多相关文章
- Circular Buffer
From:http://bradforj287.blogspot.com/2010/11/efficient-circular-buffer-in-java.html import java.util ...
- [Algorithm] Circular buffer
You run an e-commerce website and want to record the last N order ids in a log. Implement a data str ...
- boost::Circular Buffer
boost.circular_buffer简介 很多时候,我们需要在内存中记录最近一段时间的数据,如操作记录等.由于这部分数据记录在内存中,因此并不能无限递增,一般有容量限制,超过后就将最开始的数据移 ...
- linux网络编程--Circular Buffer(Ring Buffer) 环形缓冲区的设计与实现【转】
转自:https://blog.csdn.net/yusiguyuan/article/details/18368095 1. 应用场景 网络编程中有这样一种场景:需要应用程序代码一边从TCP/IP协 ...
- NIO中的heap Buffer和direct Buffer区别
在Java的NIO中,我们一般采用ByteBuffer缓冲区来传输数据,一般情况下我们创建Buffer对象是通过ByteBuffer的两个静态方法: ByteBuffer.allocate(int c ...
- 每天3分钟操作系统修炼秘籍(13):两个缓冲空间Kernel Buffer和IO Buffer
两个缓冲空间:kernel buffer和io buffer 先看一张图,稍后将围绕这张图展开描述.图中的fd table.open file table以及两个inode table都可以不用理解, ...
- 全网最清楚的:MySQL的insert buffer和change buffer 串讲
目录 一.前言 二.问题引入 2.1.聚簇索引 2.2.普通索引 三.change buffer存在的意义 四.再看change buffer 五.change buffer 的限制 六.change ...
- boost circular buffer环形缓冲类
Boost.Circular_buffer维护了一块连续内存块作为缓存区,当缓存区内的数据存满时,继续存入数据就覆盖掉旧的数据. 它是一个与STL兼容的容器,类似于 std::list或std::de ...
- directx12中vetex buffer、index buffer和constant buffer绑定piple line的时机
类别 时机 函数 建Heap vetex buffer 在Draw函数中 ID3D12GraphicsCommandList::IASetVertexBuffer 否 index buffer 在Dr ...
随机推荐
- redis AND memcache
memcache文章索引 MEMCACHE问题集锦[转] MEMCACHED 高可用方案 REPCACHED NOSQL之[MEMCACHED]学习 当 MySQL 和 Memcached 遇到尾部空 ...
- hiho 毁灭者问题
描述 在 Warcraft III 之冰封王座中,毁灭者是不死族打三本后期时的一个魔法飞行单位. 毁灭者的核心技能之一,叫做魔法吸收(Absorb Mana): 现在让我们来考虑下面的问题: 假设你拥 ...
- 提升 web 应用程序的性能(二)
最佳实践 本章将略述能帮助您提升 web 应用程序性能的最佳实践. 减少 HTTP 请求数 每个 HTTP 请求都有开销,包括查找 DNS.创建连接及等待响应,因此削减不必要的请求数可减少不必要的开销 ...
- Js操作Select大全
判断select选项中 是否存在Value="paraValue"的Item 向select选项中 加入一个Item 从select选项中 删除一个Item 删除select中选中 ...
- Html - 瀑布流
瀑布流,又称瀑布流式布局.是比较流行的一种网站页面布局,视觉表现为参差不齐的多栏布局,随着页面滚动条向下滚动,这种布局还会不断加载数据块并附加至当前尾部.最早采用此布局的网站是Pinterest,逐渐 ...
- php如何把文件上传到服务器上
conn.php: <?php $id=mysql_connect('localhost','root','root'); mysql_select_db("db_database12 ...
- NV OIT algorithm : Depth peeling is a fragment-level depth sorting technique
https://developer.nvidia.com/content/interactive-order-independent-transparency Correctly rendering ...
- Ubuntu安装Tcpdump
参考:ubuntu下安装Tcpdump并使用 请先安装libpcap等,可以参照上文链接. 安装: 网址:http://www.tcpdump.org/ 解压: tar -zxvf tcpdump-4 ...
- 40. 特殊a串数列求和
特殊a串数列求和 #include <stdio.h> int main() { int i, a, n, item, sum, temp; while (scanf("%d % ...
- mybatis sql in 查询(mybatis sql语句传入参数是list)mybatis中使用in查询时in怎么接收值
1.in查询条件是list时 <select id="getMultiMomentsCommentsCounts" resultType="int"> ...